在机器翻译任务中常用评价指标:BLEU、ROGUE、METEOR、PPL。
这些指标的缺点:只能反应模型输出是否类似于测试文本。
BLUE (Bilingual Evaluation Understudy):是用于评估模型生成的句子(candidate)和实际句子(reference) 的差异的指标。该指标由IBM于2002年提出。该指标还适用于NLP的其他场景,如:语言生成、图像标题生成、文本生成、语音识别。

Python使用NLTK库实现BLEU的计算。

**ROGUE:**指标是在机器翻译、自动摘要、问答生成等领域常见的评估指标。ROUGE 通过将模型生成的摘要或者回答与参考答案(一般是人工生成的)进行比较计算,得到对应的得分。

Python使用rouge库实现。

METEOR:

PPL(Perplexity):困惑度

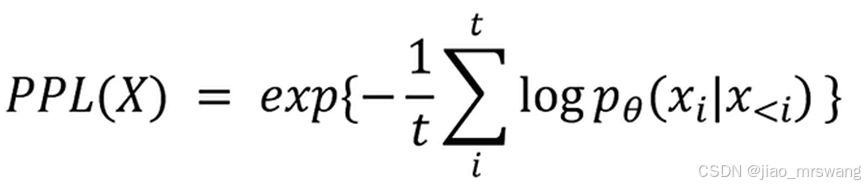
参考文章: