【NLP高频面题 - LLM架构篇】LLM对Transformer都有哪些优化?
⚠︎ 重要性:★★★ 💯
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
目前主流的大模型架构都是基于LLaMa架构的改造,LLaMa(Large Language Model Meta AI)是由Meta AI开发的一种大语言模型,其核心架构是基于Transformer模型,这是一种由多层自注意力机制和前馈神经网络组成的深度学习结构。
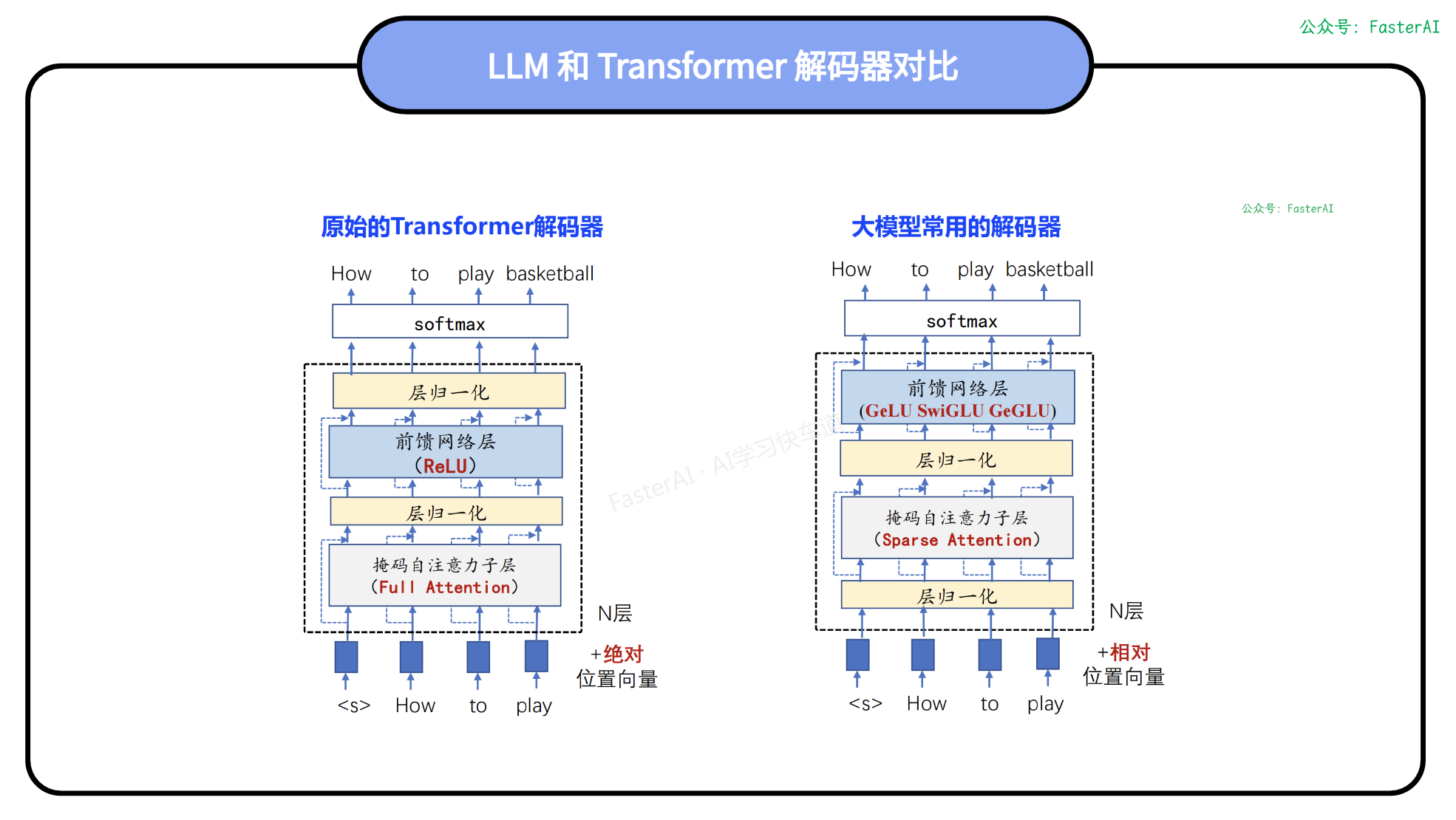
具体来说,LLaMa模型主要由Attention和MLP层堆叠而成,并采用了前置层归一化、RMSNorm归一化函数、SwiGLU激活函数、分组查询注意力机制和旋转位置编码等技术进行改进。
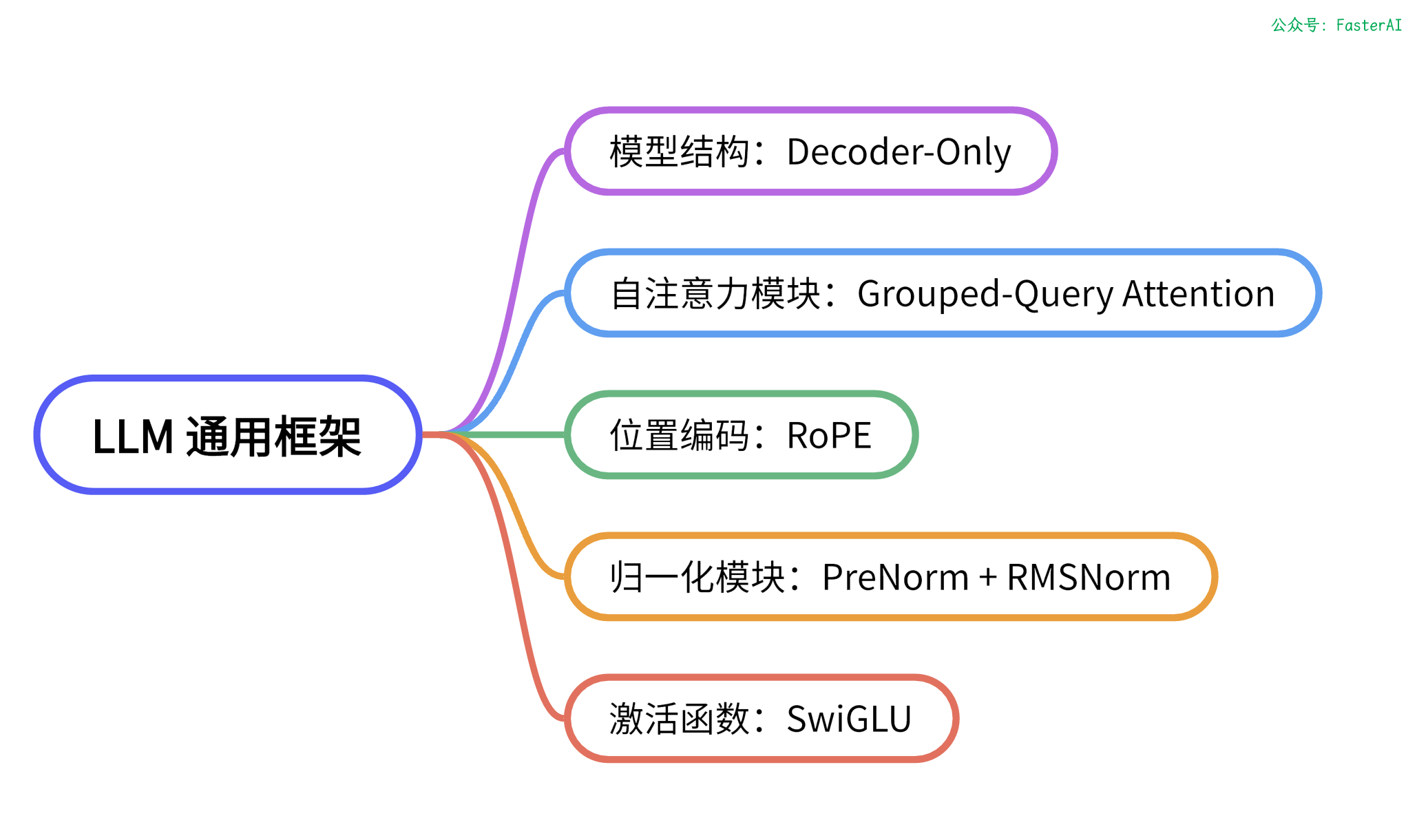

LLaMa模型具有多种参数规模版本,包括7B、13B、33B和65B等多种不同的参数量,这是目前语言领域领先模型中的主流架构。