AIGC 012-Video LDM-Stable Video diffusion前身,将LDM扩展到视频生成任务!
文章目录
0 论文工作
Video LDM作者也是Stable diffusion的作者,作者在SD的架构上进行扩展,实现了视频的生成。后续在Video LDM上继续微调有了前几个月很火爆Sora同赛道的Stable video diffusion模型,而且开源了。这是一件很酷的事情。
潜在扩散模型(LDMs)通过在压缩的低维潜在空间中训练扩散模型,避免了过度的计算需求,从而实现了高质量的图像合成。Video LDM作者将LDM范式应用于高分辨率视频生成,这是一个特别资源密集的任务。为了实现这个任务,作者做了以下调整:
首先仅在图像上预训练LDM,然后通过在潜在空间扩散模型中引入时间维度,并在编码的图像序列(即视频)上进行微调,将图像生成器转变为视频生成器。
同时,还对扩散模型的上采样器进行时间对齐,使其变成具有时间一致性的视频超分辨率模型。
整体上来说,作者主要多Unet中的注意力蹭做了扩展,让信息在时间维度上也进行交换,然后解码器也加入了时间信息。整体架构与SD保持一致。
作者展示了以这种方式训练的时间层能够推广到不同的精调文本到图像LDM。利用这一特性,在未来的内容创作会有更多可能性。后续希望自己抽出更多时间来分享更详细的代码部分的实现。
论文链接
Page
github
1论文方法
如下图的简图所示,网络的主体结构还是SD的unet结构。不过为了关注时间上的变化,增加了时间维度的注意力。
信息注入方式有三种:
第一种通过交叉注意力进行,比如CLIP信息。
第二种通过拼接的方式,对应的VAE的图像特征。
第三种就是用vector形式融入,比如motion,fps这两个表征视频变化的参数跟数据增强,他们是通过跟时间相加的形式注入到模型中。
与原始的SD不同的就是视频比图像多了运动变化个帧间变化。这些区别在论文中通过第三种方式注入mooing。

关于时间注意力的注入如下,信息从(B,T, C, H, W)形状变形成(BT, C, H, W)这样输入流就可以复用SD的空间注意力模块。时间注意力模块(B T, C, H, W)变形为(BH W, T, C)通过维度的调整,信息在时间维度上进行交互。
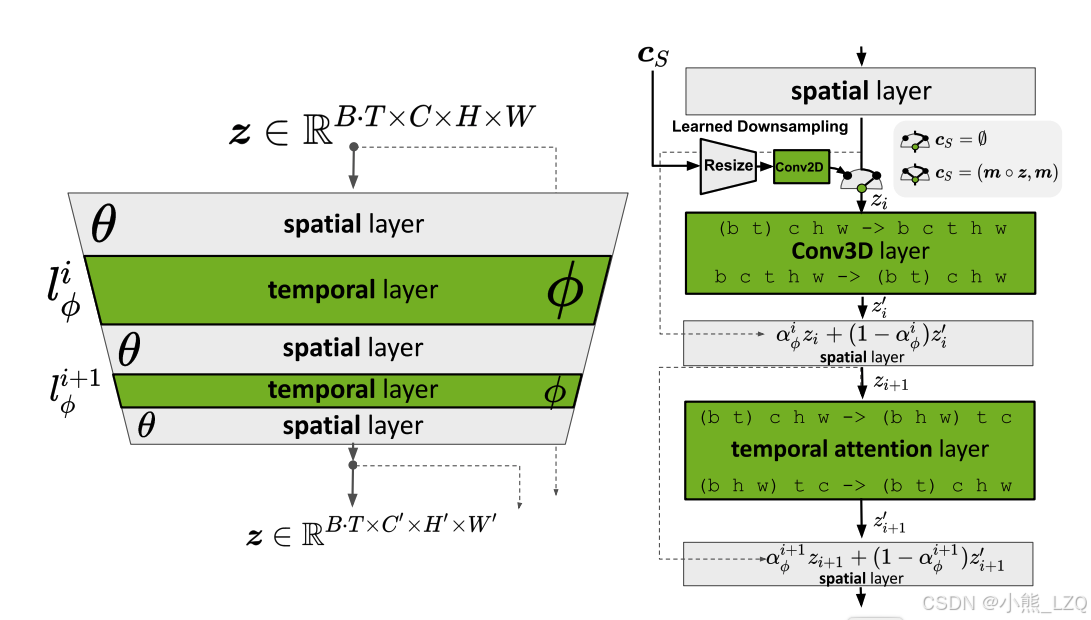
以上是论文的主要工作,但是需要额外强调的是,视频生成任务前期对数据集的筛选处理这些工作可能比算法本身更加重要。
实验结果
视频结果可以在Page中看到。