根据上一节,我们已经安装完成hadoop伪分布式环境
hadoop集群环境配置_jdk1.8 441-CSDN博客
还没安装的小伙伴可以看看这个帖子
这一节我们要实现使用vscode进行远程连接,并且完成java配置与测试
目录
vscode
上官网下载vscode(这里默认你已经安装)
然后配置插件
Remote-SSH
配置远程
点卡开之后会出现SSH(下面的图是已经使用过后的结果)

会弹出远程连接的提示
直接输入虚拟机的ip即可
安装java插件
连接完后,需要在远程机子上安装java插件
在vscode插件页面搜索
Extension Pack for Java
新建java项目
你可以新建文件夹后在文件夹下面新建项目
新建文件夹
打开终端
Ctrl+~
mkdir ~/workplace
调出命令框
ctrl+shift+p
然后输入java
点击

-
选择 no bulid tools
-
选择刚才创建的 workplace 文件夹
命名

然后就会给你创建一个默认简单java项目
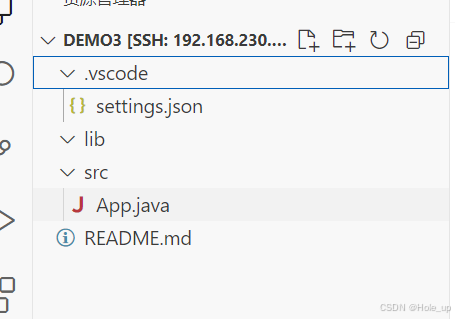
包括这些
配置依赖
打开settings.json文件
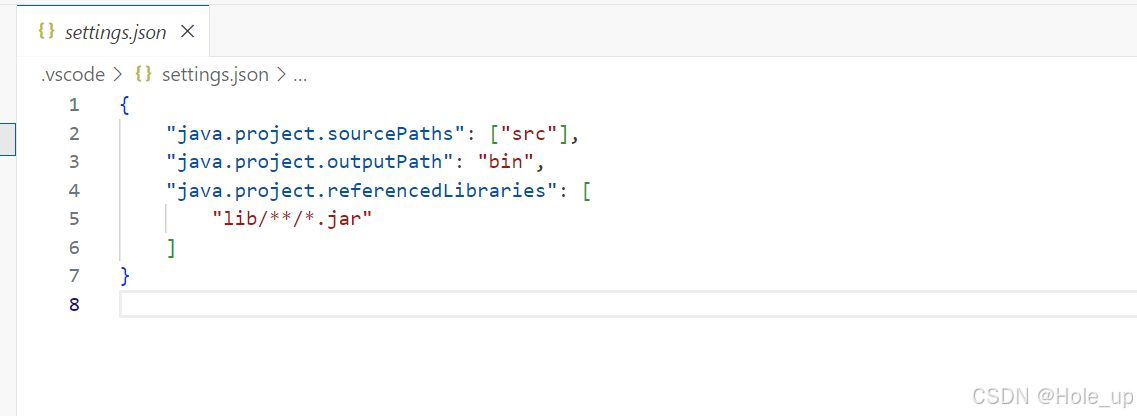
根据具体位置配置,以下图片中包括文件查找,根据查找的路径进行更改
最终

Java项目编译,打包,运行
目录结构
HelloWorld/
├── src/
│ └── com/
│ └── demo/
│ └── hello/
│ └── HelloWorld.java
└── bin/
package com.demo.hello;public class HelloWorld {
public static void main(String\[\] args) throws Exception {
System.out.println("Hello, World!");
}
}
vscode会自动创建编译的bin目录
咱们直接运行就行
javac -d bin src/com/demo/hello/HelloWorld.java
打包为可执行JAR
jar cvfe hello-demo.jar com.demo.hello.HelloWorld -C bin .

验证结构
jar tf hello-demo.jar
输出应包含
META-INF/MANIFEST.MF
com/demo/hello/HelloWorld.class
运行JAR程序
java -jar hello-demo.jar
Hadoop集群运行程序
注意,这里要先启动hadoop集群
不然会出现如下错误

在终端运行

然后,准备hadoop环境
hdfs dfs -mkdir -p /input
hdfs dfs -put LICENSE.txt /input
会报错

检查文件(在常见位置)
ls /usr/share/doc/*/LICENSE.txt ls ~/Downloads/LICENSE.txt
查找Hadoop安装目录下的LICENSE文件(可能需要root权限)
find $HADOOP_HOME -name "LICENSE*" 2>/dev/null
上传
cp $HADOOP_HOME/LICENSE.txt .
继续运行
hdfs dfs -put LICENSE.txt /input
解决
继续
hdfs dfs -rm -r /output/res # 确保输出目录不存在
提交作业
hadoop jar hello-demo.jar MR_Sample.WordCount.WordCountMain /input/LICENSE.txt /output/res
 ok!
ok!