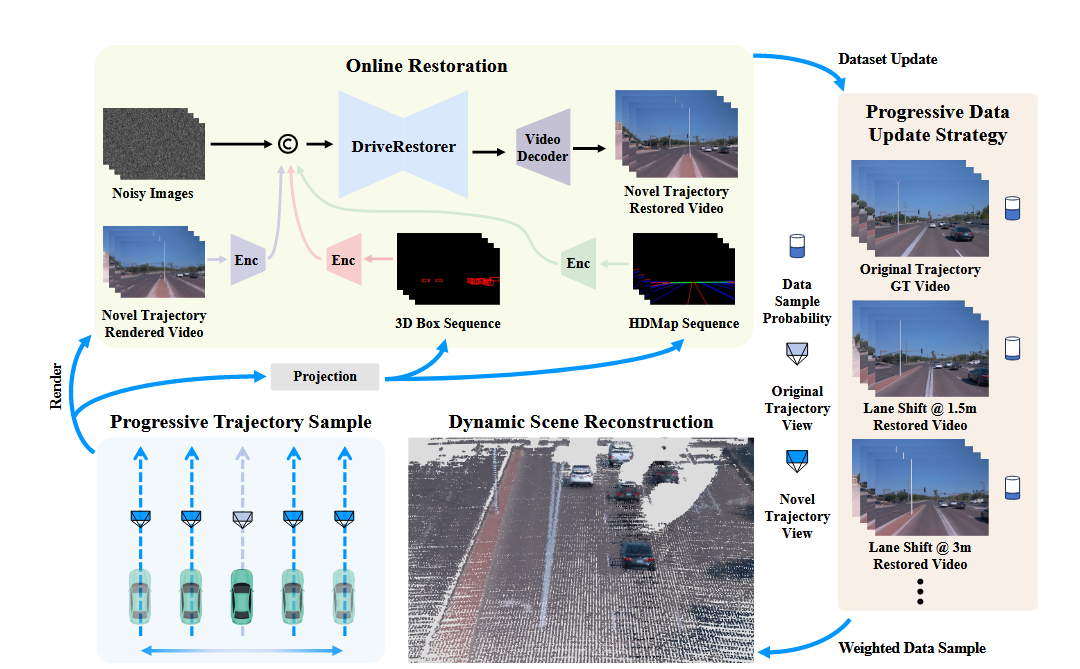
在 DriveDreamer4D 的基础上,通过渐进式数据更新,解决大范围机动(多车道连续变道、紧急避障)的问题。同时 DriveDreamer4D生成轨迹后直接渲染,而 ReconDreamer 会实时通过 DriveRestorer 检测渲染结果与物理规则的冲突,并反向调整高斯参数。
总结来看,ReconDreamer 是 DriveDreamer4D 的增强版,核心创新在于将「静态世界模型调用」升级为「动态渐进式知识融合」,从而解决大机动场景的渲染难题。
DriveRestorer
先利用原始数据训练一遍重建模型,然后沿原始轨迹生成渲染视频 V o r i ^ = G ( τ o r i ) \hat{V_{ori}}=\mathcal{G}(\tau_{ori}) Vori^=G(τori) 。
由于重建模型的欠拟合,会产生重影伪影,从不同训练阶段采样渲染视频,构成数据集 { V ^ o r i k , V o r i } \{\hat{V}{ori}^k,V{ori}\} {V^orik,Vori} 其中 V ^ o r i k \hat{V}{ori}^k V^orik 表示第 k 训练阶段采样的渲染视频。(模仿 DriveDreamer4D)对 V ^ o r i k \hat{V}{ori}^k V^orik 施加 mask,重点修复远景和天空等易失真的区域,通过 ϵ ( V ^ m a s k ) = ϵ ( V ^ o r i ⨀ M ) \epsilon(\hat{V}{mask})=\epsilon(\hat{V}ori\bigodot M) ϵ(V^mask)=ϵ(V^ori⨀M) 基于扩散模型的渐进式优化:
L R = E z , ϵ ∼ N ( 0 , 1 ) , t ∥ ϵ t − ϵ θ ( z t , t , c ) ∥ 2 2 \mathcal{L}{\mathcal{R}}=\mathbb{E}{\boldsymbol{z},\epsilon\sim\mathcal{N}(0,1),t}\left\\left\\\|\\epsilon_t-\\epsilon_\\theta\\left(\\boldsymbol{z}_t,t,\\boldsymbol{c}\\right)\\right\\\|_2\^2\\right LR=Ez,ϵ∼N(0,1),t∥ϵt−ϵθ(zt,t,c)∥22
控制条件 c 为 V ^ m a s k \hat{V}_{mask} V^mask,3D 边界框与高清地图。
推理时,冻住 DriveRestorer 参数用于新轨迹渲染修复:
V n o v e l = R ( V ^ n o v e l , P ( s , T n o v e l k ) ) , V_{\mathrm{novel}}=\mathcal{R}(\hat{V}{\mathrm{novel}},\mathcal{P}(s,\mathcal{T}{\mathrm{novel}}^k)), Vnovel=R(V^novel,P(s,Tnovelk)),
其中 s 为 3D 边界框和高清地图, P ( ⋅ ) \mathcal{P}(·) P(⋅) 表示将 s 对齐到 τ n o v e l k \tau_{novel}^k τnovelk 的投影变换。'

- 轨迹扩展 :第k次更新时,新轨迹 τ n o v e l \tau_{novel} τnovel 扩展 y = k Δ y y=k\Delta y y=kΔy 米( Δ y \Delta y Δy 为预设值,从 1.5m 开始,逐步生成 3m,6m)
- 数据生成 :通过重建模型 G \mathcal{G} G 渲染扩展轨迹视频 V ^ n o v e l \hat{V}{novel} V^novel,经 DriveRestorer 修复得 V n o v e l V{novel} Vnovel
- 加权更新 :按采样概率 w = k ∑ j = 1 k j w=\frac{k}{\sum_{j=1}^kj} w=∑j=1kjk 更新数据集:高伪影区域:70%修复数据+30%原始数据;低伪影区域:30%修复数据+70%原始数据。通过 KL 散度监控,保证数据分布不发生漂移。 D n o v e l = ( 1 − w ) ⋅ D n o v e l ∪ w ⋅ V n o v e l D_{\mathrm{novel}}=(1-w)\cdot D_{\mathrm{novel}}\cup w\cdot V_{\mathrm{novel}} Dnovel=(1−w)⋅Dnovel∪w⋅Vnovel
原始数据: L o r i ( ϕ ) = λ 1 L o r i R G B + λ 2 L o r i D e p t h + λ 3 L o r i S S I M \mathcal{L}{\mathrm{ori}}(\phi)=\lambda{1}\mathcal{L}{\mathrm{ori}}^{\mathrm{RGB}}+\lambda{2}\mathcal{L}{\mathrm{ori}}^{\mathrm{Depth}}+\lambda{3}\mathcal{L}{\mathrm{ori}}^{\mathrm{SSIM}} Lori(ϕ)=λ1LoriRGB+λ2LoriDepth+λ3LoriSSIM
新数据: L n o v e l ( ϕ ) = λ 1 L n o v e l R G B + λ 3 L n o v e l S S I M \mathcal{L}{\mathrm{novel}}(\phi)=\lambda_1\mathcal{L}{\mathrm{novel}}^{\mathrm{RGB}}+\lambda_3\mathcal{L}{\mathrm{novel}}^{\mathrm{SSIM}} Lnovel(ϕ)=λ1LnovelRGB+λ3LnovelSSIM
联合训练: L ( ϕ ) = L o r i + L n o v e l . \mathcal{L}(\phi)=\mathcal{L}{\mathrm{ori}}+\mathcal{L}{\mathrm{novel}}. L(ϕ)=Lori+Lnovel.