目录
- 0 专栏介绍
- 1 从DQN到优先级DQN
- 2 优先级经验池的实现
- 3 Pytorch算法实现
-
- 3.1 算法流程图
- 3.2 求和树实现
- 3.3 Priority DQN实现
0 专栏介绍
本专栏以贝尔曼最优方程等数学原理为根基,结合PyTorch框架逐层拆解DRL的核心算法(如DQN、PPO、SAC)逻辑。针对机器人运动规划场景,深入探讨如何将DRL与路径规划、动态避障等任务结合,包含仿真环境搭建、状态空间设计、奖励函数工程化调优等技术细节,旨在帮助读者掌握深度强化学习技术在机器人运动规划中的实战应用
1 从DQN到优先级DQN
深度Q网络(DQN)通过结合深度神经网络与Q-learning,在Atari游戏等领域取得了突破性进展。然而,传统DQN的均匀采样经验回放机制存在效率瓶颈:并非所有经验对学习同等重要,随机均匀采样经验忽略了不同经验对训练的贡献差异,关键经验(如高TD误差的样本)可能被淹没在大量普通样本中,导致收敛缓慢。
**优先级深度Q网络(Prioritized Replay DQN)**的核心思想是通过赋予高价值经验更高的采样概率,加速模型收敛并提升性能。注意到DQN中经验回放池里不同样本的时序差分误差
δ i = y i − Q ( s i , a i ; θ ) \delta _i=y_i-Q\left( \boldsymbol{s}_i,\boldsymbol{a}_i;\boldsymbol{\theta } \right) δi=yi−Q(si,ai;θ)
不同, ∣ δ i ∣ \left| \delta _i \right| ∣δi∣越大的样本对模型优化的作用越大。优先级深度Q网络正是基于通过时序差分误差 ∣ δ i ∣ \left| \delta _i \right| ∣δi∣将样本均匀分布改为带优先级的加权分布, ∣ δ i ∣ \left| \delta _i \right| ∣δi∣越大则样本优先级越高,被采样的概率也越大,加快模型收敛。具体地,定义优先级
p i = ∣ δ i ∣ + ϵ o r p i = 1 / r a n k ( i ) p_i=\left| \delta _i \right|+\epsilon \,\, \mathrm{or} p_i={{1}/{\mathrm{rank}\left( i \right)}} pi=∣δi∣+ϵorpi=1/rank(i)
其中 r a n k ( i ) \mathrm{rank}\left( i \right) rank(i)是样本 i i i的 ∣ δ i ∣ \left| \delta _i \right| ∣δi∣在全体样本中的排序位次, ∣ δ i ∣ \left| \delta _i \right| ∣δi∣越大 r a n k ( i ) \mathrm{rank}\left( i \right) rank(i)越小。
2 优先级经验池的实现
优先级经验池采用**求和树(sum-tree)**结构组织数据,并实现基于优先级的采样。
如图所示,假设存在一个四层求和树结构,其根节点值为42,对应全部叶子节点的优先级总和。第二层节点29和13分别表示左右子树的优先级累计值,第三层节点进一步细分为13、16、3、10,直至底层叶子节点存储具体优先级值3、10、12、4、1、2、8、2。在物理实现中,该树结构通过数组存储,索引0为根节点,索引1-2对应第二层,索引3-6对应第三层,索引7-14对应8个叶子节点。这种存储方式使得树结构的遍历和更新操作具备 O ( l o g N ) O(log N) O(logN)的时间复杂度。
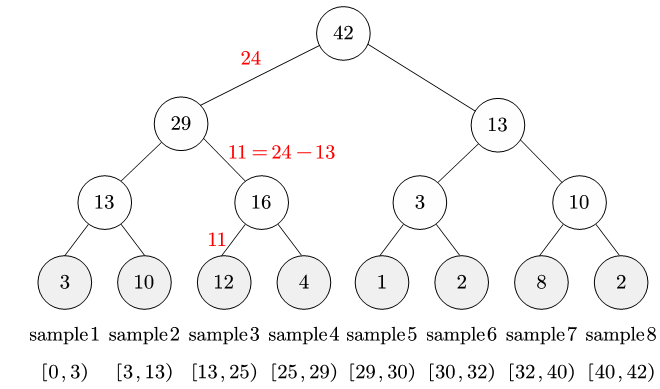
-
采样阶段
系统首先生成区间
(0,42)内的随机数s。从根节点开始,通过二分搜索定位目标叶子节点:若s小于当前节点左子节点值,则进入左子树;否则进入右子树并将s减去左子节点值。例如当s=24时,根节点左子节点值为29,因24 < 29进入索引1的节点;其左子节点值为13,此时24 > 13,转向右子树并将s更新为24 - 13 = 11;在索引4的节点中,左子节点值为12,因此最终定位到索引9的叶子节点(优先级12)。这一过程仅需3次比较即可完成采样,充分体现树形结构的高效性。直观地,在求和树作用下,样本优先级越大采样区间越长,越容易被采样------类似轮盘赌算法 。特别地,优先级经验池设置了权重参数
w i = ( 1 m ⋅ 1 P ( i ) ) β / max i w i w_i={{\left( \frac{1}{m}\cdot \frac{1}{P\left( i \right)} \right) ^{\beta}}/{\max _iw_i}} wi=(m1⋅P(i)1)β/imaxwi优先级越大、越容易被采样的样本其权重越小,因为网络会多次访问该样本,适当降权可以防止过度估计
-
更新阶段
当叶子节点的优先级发生改变时,需沿路径回溯更新父节点值。假设索引
7的叶子节点优先级从3调整为5,则第三层父节点(索引3)值更新为5 + 10 = 15,第二层父节点(索引1)值变为15 + 16=31,根节点(索引0)同步更新为31 + 13 = 44。
3 Pytorch算法实现
3.1 算法流程图

3.2 求和树实现
完整求和树结构如下所示:
python
class SumTree:
'''
* @breif: 求和树
* @attention: 容量只能为偶数
'''
def __init__(self, capacity):
# 求和树容量
self.capacity = capacity
# 树结构
self.tree = np.zeros(2 * capacity - 1)
# 树叶节点
self.data = np.zeros(capacity, dtype=object)
# 指向当前树叶节点的指针
self.write = 0
# 求和树缓存的数据量
self.size = 0
'''
* @breif: 递归更新树的优先级
* @param[in]: idx -> 索引
* @param[in]: change-> 优先级增量
* @example: 六节点求和树的索引
* 0
* / \
* 1 2
* / \ / \
* 3 4 5 6
* / \ / \
* 7 8 9 10
'''
def _propagate(self, idx, change):
parent = (idx - 1) // 2
self.tree[parent] += change
if parent != 0:
self._propagate(parent, change)
'''
* @breif: 递归求叶节点(s落在某个节点区间内)
* @param[in]: idx -> 子树根节点索引
* @param[in]: s -> 采样优先级
'''
def _retrieve(self, idx, s):
left = 2 * idx + 1
right = left + 1
if left >= len(self.tree):
return idx
if s <= self.tree[left]:
return self._retrieve(left, s)
else:
return self._retrieve(right, s - self.tree[left])
'''
* @breif: 返回根节点, 即总优先级权重
'''
def total(self):
return self.tree[0]
'''
* @breif: 添加带优先级的数据到求和树
* @param[in]: p -> 优先级
* @param[in]: data-> 数据
'''
def add(self, p, data):
idx = self.write + self.capacity - 1
self.data[self.write] = data
self.update(idx, p)
self.write += 1
self.size = min(self.capacity, self.size + 1)
if self.write >= self.capacity:
self.write = 0
'''
* @breif: 更新求和树数据
* @param[in]: idx -> 索引
* @param[in]: p -> 优先级
'''
def update(self, idx, p):
change = p - self.tree[idx]
self.tree[idx] = p
self._propagate(idx, change)
'''
* @breif: 根据采样值求叶节点数据
* @param[in]: s -> 采样优先级
'''
def get(self, s):
idx = self._retrieve(0, s)
dataIdx = idx - self.capacity + 1
return (idx, self.tree[idx], self.data[dataIdx])3.3 Priority DQN实现
核心代码如下所示:
python
class PriorityDQNAgent(DoubleDQNAgent):
'''
* @breif: 优先级双深度Q网络智能体
'''
def __init__(self, env, learning_rate=0.0003, reward_decay=0.99, e_greedy=[0.0, 0.99, 5e-4],
tau=0.005, buffer_size=10000):
super().__init__(env, learning_rate, reward_decay, e_greedy, tau, buffer_size)
self.replay_buffer = PrioritizedBuffer(buffer_size)
'''
* @breif: 计算一个batch的时序差分误差
'''
def _computeTDerror(self, batch_size):
transitions, idxs, weights = self.replay_buffer.sample(batch_size)
states, actions, rewards, next_states, dones = transitions
states = torch.FloatTensor(states).to(self.device)
actions = torch.LongTensor(actions).to(self.device)
rewards = torch.FloatTensor(rewards).to(self.device)
next_states = torch.FloatTensor(next_states).to(self.device)
dones = (1 - torch.FloatTensor(dones)).to(self.device)
weights = torch.FloatTensor(weights).to(self.device)
curr_Q = self.model.forward(states).gather(1, actions.unsqueeze(1)).squeeze(1)
next_a = torch.argmax(self.model.forward(next_states), dim=1)
next_Q = self.target_model.forward(next_states).gather(1, next_a.unsqueeze(1)).squeeze(1)
expected_Q = rewards.squeeze(1) + self.gamma * next_Q * dones
td_errors = torch.abs(curr_Q - expected_Q)
loss = self.criterion(curr_Q, expected_Q) * weights
return loss.mean(), td_errors, idxs
def update(self, batch_size):
loss, td_errors, idxs = self._computeTDerror(batch_size)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 更新target网络
for target_param, param in zip(self.target_model.parameters(), self.model.parameters()):
target_param.data.copy_(self.tau * param + (1 - self.tau) * target_param)
# 退火
self.epsilon = self.epsilon + self.epsilon_delta \
if self.epsilon < self.epsilon_max else self.epsilon_max
# 根据时序差分更新优先级
for idx, td_error in zip(idxs, td_errors.cpu().detach().numpy()):
self.replay_buffer.updatePriority(idx, td_error)效果如下所示

完整代码联系下方博主名片获取
🔥 更多精彩专栏:
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇