B树
B 树是一种多路平衡搜索树 (Multiway Balanced Search Tree),其设计目标在于减少磁盘读写次数 ,从而提高大规模数据处理时的性能 。不同于二叉树,B 树的每个节点可以存储多个关键字和多个子节点指针,这使得它能在较少的层数中容纳更多数据。正因为这种结构,B 树常常用于外部存储系统,比如数据库索引和文件系统。
1. B树的结构特点
- 根节点至少有两个孩子。
- 每个分支节点 包含
k-1个关键字和k个孩子,且k满足 ceil ( m / 2 ) ≤ k ≤ m \text {ceil}(m/2) \le k \le m ceil(m/2)≤k≤m (m为 B 树的阶数,ceil()表示向上取整函数)。 - 每个叶子节点 包含
k-1个关键字,且k满足 ceil ( m / 2 ) ≤ k ≤ m \text {ceil}(m/2) \le k \le m ceil(m/2)≤k≤m 。 - 所有的叶子节点都在同一层。
- 若一个节点有 k − 1 k-1 k−1 个关键字: a 1 , a 2 , ... , a k − 1 a_1,a_2, \dots ,a_{k-1} a1,a2,...,ak−1 。 k k k 个子节点: c 1 , c 2 , ... , c k c_1,c_2, \dots ,c_k c1,c2,...,ck 。则所有在子节点 c 1 c_1 c1 中的关键字都小于 a 1 a_1 a1 ,在子节点 c i ( 2 ≤ i ≤ k − 1 ) c_i \space (2 \le i \le k-1) ci (2≤i≤k−1) 中的所有关键字都介于 a i − 1 a_{i-1} ai−1 和 a i a_i ai 之间,而子节点 c k c_k ck 中的关键字均大于 a k − 1 a_{k-1} ak−1 。
2. B树的插入
B 树也是一种左孩子小于自身,右孩子大于自身的搜索树结构。B 树在插入时,是在叶子节点上插入新的值,但若某个叶子节点的关键字满了,就会发生分裂。
插入过程:
-
寻找合适的叶子节点
从根节点开始,按左小右大的顺序比较,沿着对应的子节点指针一路向下,直到找到目标叶子节点。
-
在叶子节点中插入关键字
在 B 树中,叶子节点会包含
k-1个关键字,在叶子节点上也要按左小右大的规则排序,所以在叶子节点上关键字可能会发生挪动。 -
节点溢出处理(分裂)
如果在插入关键字后,该叶子节点的关键字满了,就要进行节点分裂:
- 找到该叶子节点的中间关键字,即找到中位数。
- 叶子节点保留中位数左侧的所有的所有关键字。
- 中位数提升到父结点中,作为父结点的关键字。
- 中位数右侧的所有关键字插入到新的节点中,并作为左侧关键字节点的兄弟节点。
-
向上递归分裂
如果中位数提升到父结点后,父结点的关键字也满了,则父结点也进行相同的分裂操作。如果向上递归分裂一直递归到根节点 ,且根节点也要进行分裂,此时树的高度会增加一层,新创建的根节点只包含刚提升的中位数和两个子节点指针。
2.1 示例
-
假设有一颗 4 阶段 B 树(每个分支节点有 4 个孩子和 3 个关键字),插入 20:

-
现在再分别插入 10 和 30,插入 10 时, 10 < 20,故 20 要向右挪动,30 插入在 20 的右侧,20 变成中位数:

-
现在由于根节点满了,需要进行节点溢出处理:20 作为新的根节点的中位数;原节点保留 10,并变为新根节点的左孩子;30 插入到新分支节点中,并作为原节点的兄弟节点:
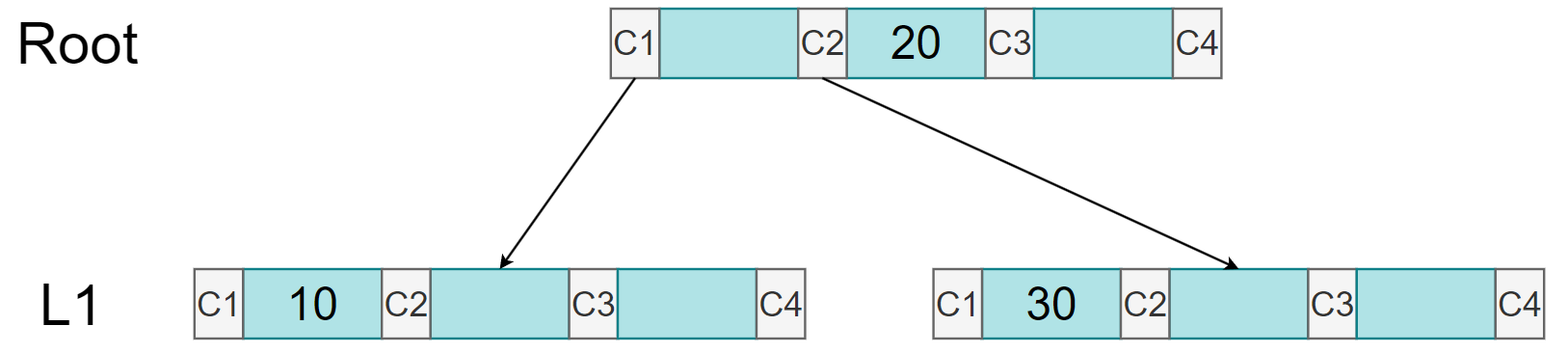
可以看到此时根节点发生分裂,树的高度增加 1,此后的插入操作,都是在 L1 层中插入,当左右孩子发生节点溢出处理时,才会有数据插入到根节点,根节点再次满后,树的高度又会增加 1。
-
现在再插入 7 和 15,由于 7 和 15 比 20 小,插入到左孩子中:
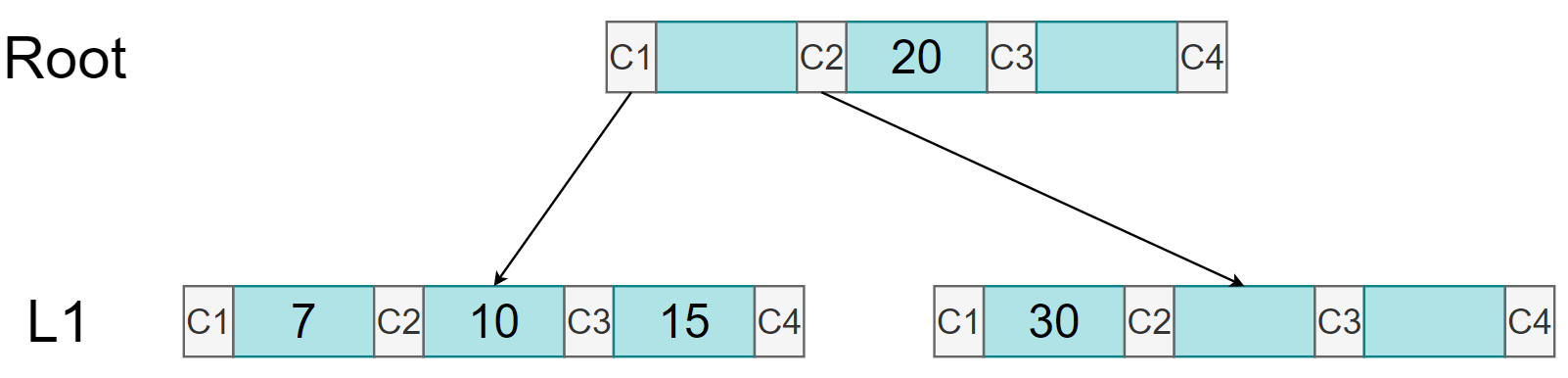
-
现在根节点的左孩子满了,需要进行节点溢出处理:10 作为中位数提升到父结点中;原节点保留 7;15 插入到新分支节点中,并作为原节点的兄弟节点:

2.2 代码实现
cpp
#include <iostream>
#include <vector>
using namespace std;
template<class K, int M = 4>
class BTreeNode
{
public:
K _keys[M - 1]; //关键字宿主
BTreeNode<K, M>* _subs[M];//孩子节点数组
BTreeNode<K, M>* _parent; //指向父结点
size_t _size; //节点中有效元素的个数
BTreeNode() :_parent(nullptr), _size(0)
{
for (size_t i = 0; i < M; i++)
{
_subs[i] = nullptr;
}
}
};
template<class K, int M>
class BTree
{
public:
typedef BTreeNode<K, M> Node;
BTree() :_root(nullptr) {}
pair<Node*, int> Find(const K& key)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
//在当前节点的关键字宿主中匹配
size_t i = 0;
while (i < cur->_size)
{
if (key < cur->_keys[i])
{
break;
}
else if (key > cur->_keys[i])
{
i++;
}
else
{
return make_pair(cur, i);
}
}
parent = cur;
//若key在该节点孩子节点中,它必是比_key[i-1]大,比_key[i]小
cur = cur->_subs[i];
}
//若key不能存在,返回应插入key的位置的父结点
return make_pair(parent, -1);
}
void InsertKey(Node* node, const K& key, Node* child)
{
int end = node->_size - 1;
while (end >= 0)
{
//为方便挪动数据,从后往前比较
if (key < node->_keys[end])
{
//挪动数据
node->_keys[end + 1] = node->_keys[end];
node->_subs[end + 2] = node->_subs[end + 1];
end--;
}
else
{
break;
}
}
node->_keys[end + 1] = key;
node->_subs[end + 2] = child;
if (child)
{
child->_parent = node;
}
node->_size++;
}
pair<Node*, bool> Insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node;
_root->_keys[0] = key;
_root->_size++;
return make_pair(_root, true);
}
//Find查询要插入的key是否已经存在,如果不能存在顺便将要插入的位置带回
pair<Node*, int> ret = Find(key);
if (ret.second >= 0)
{
return make_pair(ret.first, false);
}
Node* parent = ret.first;
Node* retNode = parent; //作为返回值返回
K newKey = key;
Node* child = nullptr;
while (1)
{
InsertKey(parent, newKey, child);
if (parent->_size < M-1)
{
return make_pair(retNode, true);
}
else
{
//将中位数的右边分给兄弟节点
size_t mid = (M - 1) / 2;
Node* brother = new Node;
size_t j = 0;
size_t i = mid + 1;
for (; i < M-1; i++)
{
brother->_keys[j] = parent->_keys[i];
brother->_subs[j] = parent->_subs[i];
//注意这里的parent和brother是兄弟关系
if (parent->_subs[i])
{
parent->_subs[i]->_parent = brother;
}
j++;
parent->_keys[i] = INT_MIN;
parent->_subs[i] = nullptr;
}
//因为关键字比孩子少一个,所以走完循环还有一个孩子需要赋值
brother->_subs[j] = parent->_subs[i];
if (parent->_subs[i])
{
parent->_subs[i]->_parent = brother;
}
parent->_keys[i] = INT_MIN;
parent->_subs[i] = nullptr;
brother->_size = j;
//parent->_size -= (brother->_size + 1);
parent->_size = mid;
//中位数提升到父结点中
K midKey = parent->_keys[mid];
parent->_keys[mid] = INT_MIN;
//如果溢出处理的是根节点
if (parent->_parent == nullptr)
{
_root = new Node;
_root->_keys[0] = midKey;
_root->_subs[0] = parent;
_root->_subs[1] = brother;
_root->_size = 1;
parent->_parent = _root;
brother->_parent = _root;
break;
}
else
{
//向上调整
newKey = midKey;
child = brother;
parent = parent->_parent;
}
}
}
return make_pair(retNode, true);
}
void _InOrder(Node* cur)
{
if (cur == nullptr)
{
return;
}
size_t i = 0;
for (; i < cur->_size; i++)
{
_InOrder(cur->_subs[i]);
cout << cur->_keys[i] << " ";
}
_InOrder(cur->_subs[i]);
}
void InOrder()
{
_InOrder(_root);
}
private:
Node* _root;
};
int main()
{
int a[] = { 53, 139, 75, 49, 145, 36, 101 };
BTree<int, 4> t;
for (auto e : a)
{
t.Insert(e);
}
t.InOrder();
return 0;
}3. B+树
B+ 树是 B 树的优化版本,B 树的结构相对比较复杂,比如一颗 4 阶的 B 树,它的结构为每个节点拥有 4 个孩子指针, 3 个关键字索引,在平衡状态下每个节点最多存有 2 个关键字,这样复杂的结构让其在代码处理上更麻烦。所以 B+ 树简化了它的结构,并专门在数据存储上做了新的优化。
3.1 B+树的结构
B+ 树规定:
- 非叶子节点只存储数据的索引,叶子节点存放关键字内容。
- 分支节点的索引和孩子指针数量相等,叶子节点存储更多的关键字并且含有一个指向兄弟节点的指针。
- 分支节点的索引 A i A_i Ai 是其对应孩子节点 C i C_i Ci 的最小关键字, C i C_i Ci 的关键字范围不会大于父结点的索引 A i + 1 A_{i+1} Ai+1 。
- 除了根节点外,每个节点至少有 m / 2 m/2 m/2 个孩子, m m m 为 B+ 树的阶数。
- 当分支节点溢出时,需要进行节点分裂处理,需要分为叶子节点和分支节点两种情况处理。
注意,B+ 树的叶子节点能存储多少个关键字并没有明确的规定。
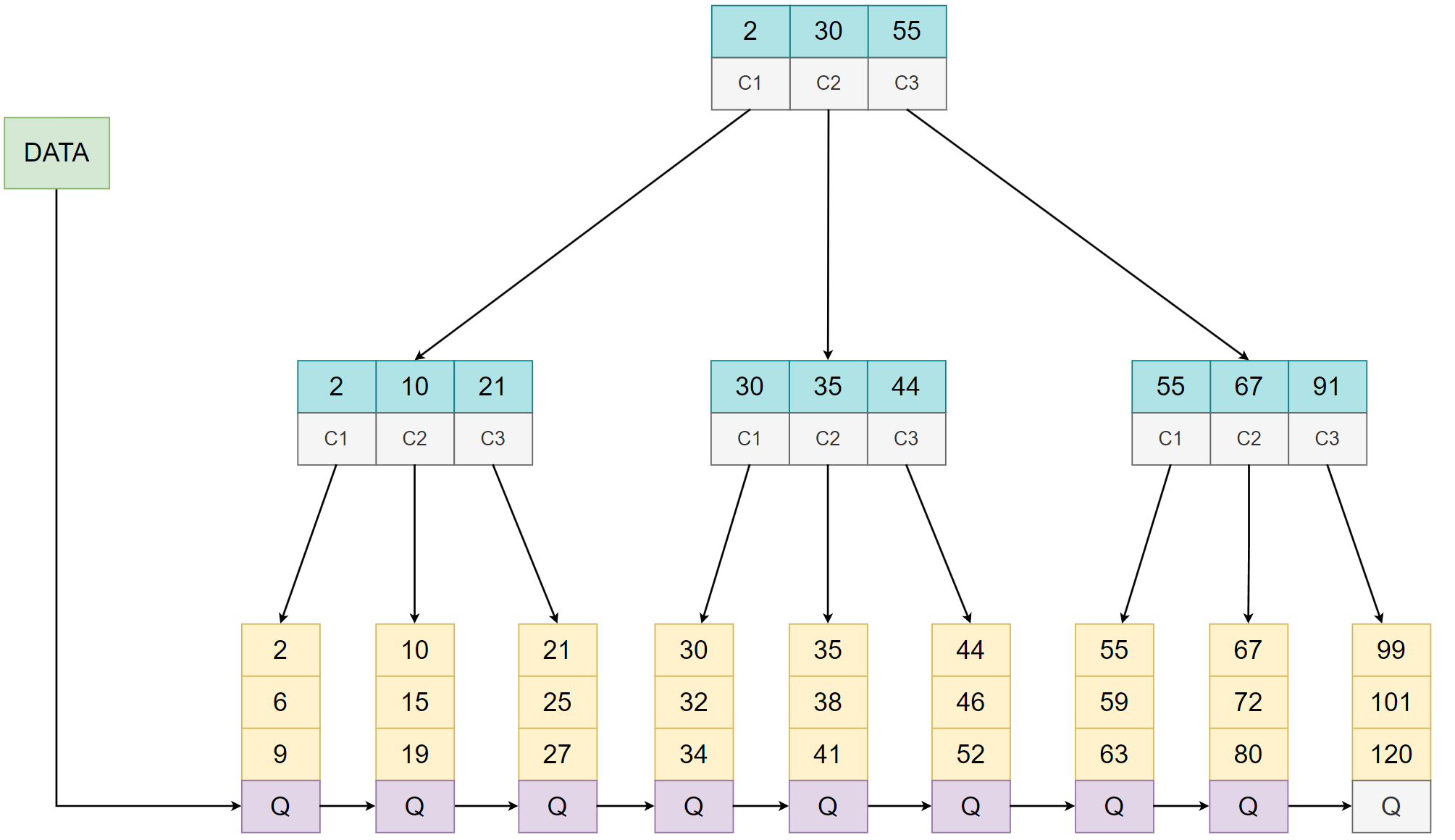
3.2 B+树的节点分裂
3.2.1 叶子节点分裂
设定叶子节点中的关键字容量为 L L L 。
- 将叶子节点中前 L / 2 L/2 L/2 个关键字保留在原节点,其他关键字放入新叶子节点中。
- 新分裂的节点作为原节点的兄弟节点,更新叶子节点中指向兄弟节点的指针。
- 将新节点的最小关键字插入到父结点的索引中,若父结点因此溢出,则需要进行分支节点溢出处理。
3.2.2 分支节点分裂
分支节点的分裂与 B 树相同。
- 找到该叶子节点的中间关键字,即找到中位数。
- 叶子节点保留中位数左侧的所有的所有关键字。
- 中位数提升到父结点中,作为父结点的关键字。
- 中位数右侧的所有关键字插入到新的节点中,并作为左侧关键字节点的兄弟节点。
- 向上递归分裂处理,若根节点需要进行分裂,则整棵树的高度增加 1。