1、简介
随机变量的分布研究的是随机变量在某些离散点或某个区间取值时的概率,即概率分布或分布律,主要包括正态分布、二项分布、泊松分布、均匀分布、卡方分布、Beta 分布等。
1.1、正态分布
正态分布概念最早由德国数学家莫弗提出,但由于德国数学家高斯率先开展了正态分布的研究和应用,故正态分布又叫高斯分布。许多统计量在样本量很大时,其极限分布都是正态分布,生活中大量的随机变量都服从正态分布。
定义:若随机变量服从位置参数为μ、尺度参数为σ的正态分布,则这个随机变量就称为正态随机变量,正态随机变量的分布称为正态分布,记为X~(N,σ),其概率密度函数如下:
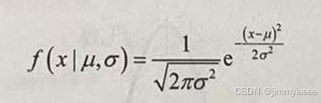
参数μ是随机变量的数学期望,决定了正态分布的位置;参数σ是随机变量的标准差,决定了正态分布的幅度。当μ=0,σ=1时的正态分布是标准正态分布,其概率密度函数如下:
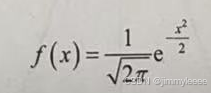
标准正态分布提供了正态分布的标准形式,具有一定的代表性。一般的正态分布X~N(μ,σ)总是可以通过一个简单的变量线性变换,将其化成标准的正态分布。
生成正态分布数据的Python代码如下:
python
from scipy.stats import norm
np.random.seed(1)
data = norm.rvs(size=10)
print(data)1.2、二项 分布
二项分布是n次独立的"成功/失败"试验中成功次数的离散概率分布即n重伯努利试验的概率分布。二项分布有如下属性。
(1)二项分布中的每个试验都是独立的。
(2)在试验中只有两个可能的结果:成功或失败。
(3)总共进行了n次试验。
(4)所有试验成功或失败的概率是相同的,即试验是一样的。
若随机变量X的概率分布为:
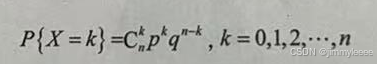
其中 0<p<l,q=1-p,则称X服从参数为n,p的二项分布,记作X~B(n,p)。上式中,p表示单次试验成功的概率,q表示单次试验失败的概率,满足p+q=1;n表示试验次数,当n=1时,二项分布就还原为(0-1)分布。
上述公式表示了离散随机变量X在取k值时的概率,这种表示离散随机变量在各个特定值的概率的函数称为概率质量函数(ProbabilityMassFunction,PMF)。对于二项分布,概率质量函数的均值实际上就是n·P。
对应连续型随机变量,二项分布也有累积概率密度函数(Cumulative Distribution Function,CDF)的概念。如下这个公式可以作为二项分布的累计概率密度函数的计算公式。
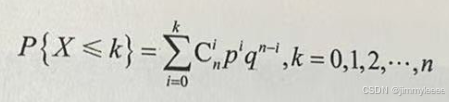
对于二项分布,当试验次数n很大时,会逼近正态分布。因此二项分布的函数曲线和正态分布战比较接近。
生成二项分布数据的Python代码如下:
python
import numpy as np
from scipy.stats import binom
np.random.seed(1)
data = binom.rvs(p=0.3,n=10,size=10)
print(data)1.3、泊松 分布
泊松分布是另外一种非常常见的随机事件概率分布。生活中有一类事件,总是以固定的平均频率随机且独立地出现,例如某电话交换台收到的呼叫、来到某公共汽车站的乘客数量、一天内来医院急诊科就诊的病人的数量、某地区一天内报告的失窃案的数量、书中某些打印错误的数量、某放射性物质发射出的粒子、显微镜下某区域中的白细胞等。这些事件都有如下特点:
(1)已经出现的事件都不影响下一个事件出现的概率。
(2)事件出现的平均频率总是固定的,出现的概率与时间或空间范围成正比
(3)时间间隔很小时,在给定时间间隔内事件出现的概率趋向于0。
满足上述条件的随机事件,在单位时间(空间)内出现的次数或个数就近似地服从泊松(Poisson)分布。按照上述条件,如果将每个时间间隔随机事件的发生,都作为一次伯努利试验则某一范围内的随机事件可以看作n重伯努利试验,实际上就是二项分布。当n值很大时(即时间间隔很小时),二项分布可以进一步简化,这种形式就称为泊松分布。
定义:若随机变量 X所有可能取的值为0,1,2,...,而取各个值的概率满足以下公式,则称X服从参数为入的泊松分布,记为X~π(2),其中是常数且λ>0。
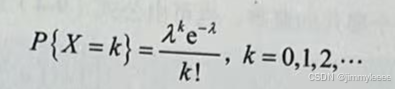
泊松分布中,λ是单位时间(空间)内事件发生的平均次数或个数。与二项分布类似,公式(9表示离散随机变量X在取k值时的概率,又称为泊松随机变量的概率质量函数(PMF),对应的均值为λ。同样,也可以定义泊松随机变量的累积概率密度函数(CDF)如下:
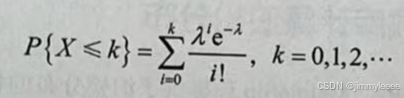
泊松分布表示单位时间内随机事件发生的次数的概率,并且假定随机事件发生的频率是固定的,所以利用泊松分布,可以对未来一段时间内随机事件的发生次数进行估计。
生成泊松分布数据的Python代码如下:
python
import numpy as np
from scipy.stats import poisson
np.random.seed(1)
data = poisson.rvs(mu=10,size=10)
print(data)1.4、均匀 分布
均匀分布是生活中常见的一种简单的随机变量分布。例如很多游戏中用到的骰子,一个骰子有6个面,每个面一个数字,分别是从1到6。游戏开始时,随机抛出骰子,骰子落地后,哪个面朝上,即记下对应的数字。骰子一般是均匀材质,得到任何一个数字的概率都是相等的,这就是均匀分布。均匀分布一般用连续型随机变量来定义。
定义:设连续型随机变量概率密度满足下式,则称在区间(a,b)上服从均匀分布,记做X~U(a,b)。
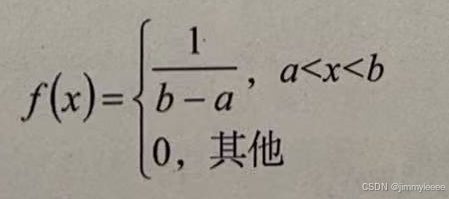
均匀分布的概率密度曲线如下图所示:
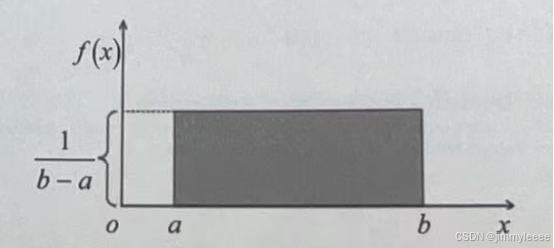
可以看出均匀分布的概率密度曲线形状是一个矩形,因此均匀分布有时又称为矩形分布。a和b是均匀分布的参数。
1.5、卡方分布
χ分布(卡方分布)是统计学中的一种重要分布。应用卡方分布可以通过小数量的样本容量去预估总体容量的分布情况。
定义:若n个相互独立的随机变量点ζ1,ζ2,...ζn,均服从标准正态分布N(0,1)(也称布的数学定义。ζ1,ζ2,...ζn是来自总体 N(0,1)的样本),则这"个独立随机变量的平方和公式如下:
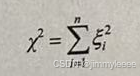
这n个独立随机变量的平方和构成一个新的随机变量(统计量),服从自由度为n的分布(chi-square distribution,卡方分布),记为χ2~χ2(n),可以表示为
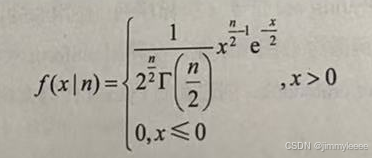
上式中自由度n是指公式中包含的独立变量的个数,来自总体的n个样本相互独立,所以自由度为 n。
在上面公式中,Г表示伽马函数,是为了解决阶乘在延拓上的问题而建立的函数,实数域上的伽马函数定义如下:

当x取整数值n时,就变成了阶乘公式:
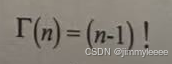
卡方分布的自由度与样本数量及样本统计量的限制条件有关。如果卡方分布中包含个独立的样本或变量,则自由度为n;如果这些样本或变量并不完全独立,其中有k个变量依赖于其他的变量或样本,则其自由度为n-k。例如ζ1,ζ2,...ζn这n个变量,其中ζ1-ζn-1相互独立,ζn为前n-1个变量的平均值,则其自由度为n-1。
生成卡方分布数据的Python代码如下:
python
import numpy as np
from scipy.stats import chi2
np.random.seed(1)
data = chi2.rvs(df=4,size=10)
print(data)1.6、 Beta 分布
Beta分布可以看作一个概率的概率分布。在很多时候,我们不知道一个随机事件的发生概率时,可以根据已经发生的事件频率来估计随机事件的概率。例如网上购物时,我们会通过查阅客户的评论来评估商家产品的质量。如果商家一共有 900条好评,100条差评,那商家4的产品质量是否就是 900/(100+900)=0.9呢?实际上我们得到的0.9这个数据,是产品质量好的频次,并不是产品质量的概率。产品的概率是根据这个数据进行的推断,这个推断实际上是一个后验概率,可以用贝叶斯公式转换成先验概率的计算,公式如下:
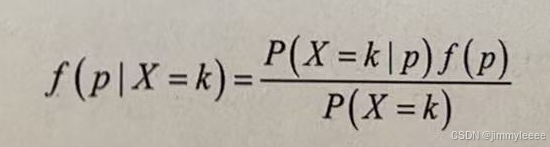
X表示好评次数,可以看作满足二项分布的随机事件,套用二项分布概率函数进行简化,最终可以得到概率p的分布,这就是Beta分布。
定义 :给定参数α>0和 β>0,取值范围为0,1的随机变量x的概率密度函数为:
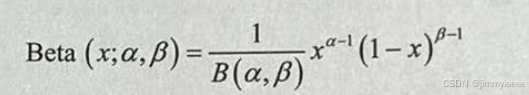
其中 B(α,β)称为 Beta 函数,可以表示为:

Beta 分布有以下特点。
(1)Beta(1,1)等价于均匀分布 U(0,1)。
(2)作为概率的概率分布,Beta(x;α,β)在(0,1)上对x的积分必定为1。
(3)X实际上是对某个随机事件发生的概率估计,α-1和β-1实际上描述了随机事件发生或不发生的次数。
(4)Beta分布是一种后验分布和先验分布的分布律相同的分布,不同的只是参数发生了变化。
Beta分布可以看作多次进行二项分布实验所得到的分布,可以对随机事件发生的概率的分布进行计算。
生成Beta分布数据的Python代码如下:
python
from scipy.stats import beta
np.random.seed(1)
data = beta.rvs(a=2,b=2,size=10)
print(data)传人参数a,b(相当于 Beta分布的α和β, size表示生成的数据的数量。