前面我们学习了机器学习任务之序列到类别模式:循环神经网络 - 机器学习任务之序列到类别模式-CSDN博客
本文我们来学习循环神经网络应用中的另一种模式:同步的序列到序列模式!
这种模式适用于输入和输出长度相同且时序对应的任务,如金融数据预测、传感器数据监控、音频信号处理(例如去噪、增强)等。在这些场景中,同步的模型能够捕捉局部时序变化,减少不必要的信息压缩和解码步骤,从而提高预测或恢复精度。
同步的序列到序列模式主要用于序列标注(Sequence Labeling)任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同。比如在词性标注(Part-of-Speech Tagging)中,每一个单词都需要标注其对应的词性标签。
在同步的序列到序列模式中,输入为一个长度为 𝑇 的序列 𝒙1∶𝑇 = (𝒙1, ⋯ , 𝒙𝑇 ),输出为序列 𝑦1∶𝑇 = (𝑦1, ⋯ , 𝑦𝑇 )。样本 𝒙 按不同时刻输入到 循环神经网络中,并得到不同时刻的隐状态 𝒉1 , ⋯ , 𝒉𝑇 .每个时刻的隐状态 𝒉𝑡 代表了当前时刻和历史的信息,并输入给分类器 𝑔(⋅) 得到当前时刻的标签 𝑦̂ ,即
𝑦̂ = 𝑔(𝒉 ), ∀𝑡 ∈ 1,𝑇.
同步的序列到序列模式的示意图如下:
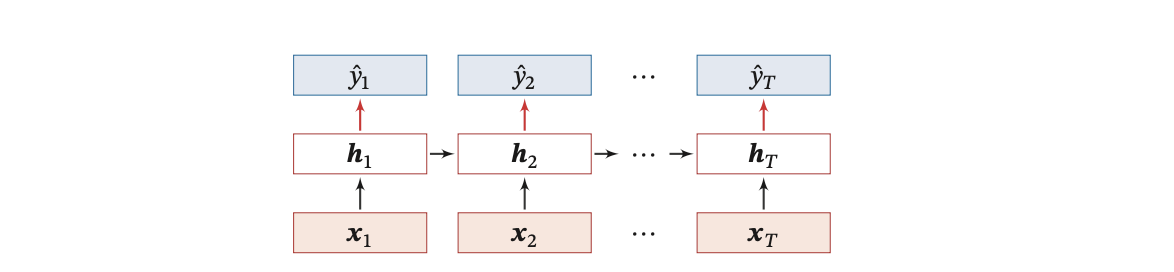
同步的序列到序列模式解析
在 RNN 应用中,"序列到序列"(Sequence-to-Sequence)模式通常指模型把一个序列映射到另一个序列。同步(synchronous) 的 Seq2Seq 模式强调输入序列和输出序列在时间步上严格对齐,即每个时间步对应一个输出。与传统机器翻译中那种"编码---解码"架构不同,同步 Seq2Seq 模型在每个时刻都直接利用当前输入与之前累积的上下文信息生成对应的输出。
这种模式的主要特点包括:
-
时间步对齐:输入和输出长度一致,每个时间步的输出不仅依赖当前输入,还受前面时间步隐藏状态影响。
-
模型设计:常见的设计是利用 RNN(例如 LSTM 或 GRU)逐步更新状态,同时在每个时间步通过一个输出层生成预测。这样可以在序列中捕捉短期和长期依赖。
-
优势与适用场景:由于每个时间步都有对应输出,该模式适合需要逐步处理、细粒度预测的任务,如时间序列分析、信号增强等。同时,由于时刻对齐,其训练与推理可以并行化一定程度上提高效率。
例子 1:时间序列预测------股票价格预测
任务描述
设想利用过去一段时间内的股票价格数据(如开盘价、最高价、最低价、收盘价)预测未来相同时间步的股票走势。这种任务中输入序列和输出序列在时间步上严格对应。
模型流程
-
输入序列构建
-
输入:过去 NN 天的股票数据构成序列
X={x1,x2,...,xN}
-
每个 xt 包含当天的多个特征。
-
-
RNN 模型处理
-
使用 LSTM/GRU 层依次处理每个时间步。模型在时间步 tt 根据当前输入 xtx_t 和前面时间步的隐藏状态 h_{t-1} 生成新状态 h_t。
-
在每个时间步通过全连接层输出预测值 y_t,形成与输入对齐的预测序列。
-
-
输出序列构建
-
输出:预测未来 NN 天的股票价格数据
Y={y1,y2,...,yN}
-
每个 y_t 与对应时间步 x_t 对应。
-
特点
-
时序对齐:每天都有一个对应的预测值,便于监控和调整预测误差。
-
依赖历史信息:当前预测结合了当前输入和过去累积信息,能够捕捉趋势和周期性变化。
(类似应用在金融时序数据预测中的设计被广泛讨论)
例子 2:语音信号处理------语音增强
任务描述
在噪声环境下录制的语音通常包含背景噪音。语音增强任务旨在从带噪语音信号中恢复出更清晰的语音。此任务中,输入为带噪声的语音频谱帧,输出为对应时刻的去噪后频谱帧,二者在时间上是一一对应的。
模型流程
-
输入序列构建
-
输入:将带噪语音信号通过短时傅里叶变换(STFT)得到一系列频谱帧
X={x1,x2,...,xN}
-
每个 xt 表示第 t 帧的频谱特征。
-
-
RNN 模型处理
-
模型使用 LSTM/GRU 网络逐步处理输入频谱帧,在每个时间步利用当前帧和前面帧的信息生成对应的干净频谱估计 yt。
-
这种连续的估计方式能够利用语音在时间上连续的平稳性来抑制噪声。
-
-
输出序列构建及后处理
-
输出:生成与输入对齐的去噪后频谱帧序列
Y={y1,y2,...,yN}
-
最后通过逆 STFT(ISTFT)重构为时域的清晰语音信号。
-
特点
-
精细逐帧预测:每个时间步都直接对应一个去噪预测,便于实时处理和在线增强。
-
连续性保证:利用前后帧的信息提高了语音信号的连续性和自然性。
(这种技术已在语音降噪和听力辅助等领域有实际应用)
同步的序列到序列模式在 RNN 中主要是指输入与输出在时间步上对齐,即每一时刻都对应一个输出。这种方法适用于如时间序列预测(例如股票价格预测)和语音信号处理(例如语音增强)等任务,在这些任务中,每个时间步的输出直接依赖于当时的输入和之前累积的上下文信息。这种结构设计不仅提高了模型的训练效率,也更适合需要精细逐步处理的应用场景。
附加:音频/视频的「帧」
为了更好的理解循环神经网络,我们经常会遇到拿音频和视频来举例子,因此我们来认识一下音频和视频的帧,以及大模型如何处理音频和视频。
在音频领域,"帧"通常指的是一段固定数量的采样数据,例如AAC编码中常用的1024个采样点,这一段数据代表了该时间段内的声音信息;而在视频领域,"帧"则是指视频中每一张静止的图像,这些连续的图像构成了完整的视频播放。大模型在处理这两种数据时,通常会先将连续信号分解成离散的"帧"或"片段",以便捕捉局部时序信息和减少数据冗余。
对于视频,大模型往往不会对每一帧都进行处理,而是采用抽帧或关键帧提取技术(例如降低采样率或利用视觉相似性过滤)来选取具有代表性的帧,从而减少计算量,同时保留时序变化的重要信息。
而在音频处理中,常见的方法是将原始波形分割成短时窗口(通过短时傅里叶变换等方法),转换为时频谱或梅尔谱,每个窗口可视为一"帧",这样既能捕捉局部频率变化,又便于模型学习。
无论是视频还是音频,大模型的处理过程通常会先对数据进行"分帧"操作,这一步骤有助于将连续信息转化为易于建模的离散单元。不过,具体的处理方式可能因模型架构和任务需求不同而有所差异,有的端到端系统可能在内部隐式地完成了这一分解过程。
下面进行朴素简单的理解。
一、视频帧:像翻页动画书
1. 什么是视频帧?
-
视频其实就是快速翻动的图片,每一张图片就是一「帧」。
-
例如:电影每秒播放24张图片(24帧/秒),当翻动速度够快时,静止的图片就「动」起来了。
例子 :
想象一本手翻书,每页画着小人跑步的不同姿势。快速翻动书页时,小人就像在跑步------每页纸就是「一帧视频」。
2. 大模型如何处理视频?
-
看连续动作:模型会同时看多张连续的图片(比如每秒的24张),分析动作变化。
-
找关键信息:比如先识别第一帧有只猫,第二帧猫的位置右移了,就知道「猫在向右跑」。
例子 :
假设你让AI看一个「人挥手」的视频,模型会:
-
第1帧:发现画面中有个人,手在左侧。
-
第5帧:手移到中间。
-
第10帧:手移到右侧。
→ 综合所有帧得出结论:「这个人在挥手」。
二、音频帧:像切香肠的片段
1. 什么是音频帧?
-
声音是连续的波形(比如说话时的声波),无法直接处理,所以被切成小段,每段叫一「帧」。
-
例如:一段1秒的音频,如果切成20毫秒的小段,就会有50个音频帧。
例子 :
把一段语音「你好」想象成一根香肠。用刀每隔1厘米切一刀,每一小段香肠就是一个「音频帧」。
2. 大模型如何处理音频?
-
听声音特征:模型会分析每小段声音的高低、强弱,甚至转换成「声音图像」(频谱图)。
-
连起来理解:比如前几帧是「你」,后几帧是「好」,连起来就知道是「你好」。
例子 :
假设你让AI识别歌曲中的歌词:
-
第1帧:检测到高频声波 → 可能是女声。
-
第5帧:声音出现「ni」的发音 → 可能是「你」。
-
第10帧:声音出现「hao」的发音 → 可能是「好」。
→ 综合所有帧得出结论:歌词是「你好」。
三、大模型如何处理音视频?(简单总结)
| 处理方式 | 视频 | 音频 |
|---|---|---|
| 输入形式 | 多张图片(帧序列) | 多段声音(波形片段) |
| 典型操作 | 分析物体移动、颜色变化 | 分析音调、节奏、文字 |
| 常用技术 | 同时看多帧(3D卷积) | 转成频谱图(像看声波照片) |
| 例子 | 检测视频中的人是否在跳舞 | 把语音转成文字 |
四、为什么要切成帧?
-
电脑记不住全部:一段1分钟的视频可能有1440张图片,直接处理会卡死。
-
找规律更容易:比如「猫向右跑」只需对比相邻几帧的位置变化,不用看完整视频。
-
和人眼/耳朵类似:我们看视频听声音时,大脑其实也在处理连续的片段信息。
生活化类比
-
视频帧:像快速翻动的照片墙,AI像管理员一页页检查照片变化。
-
音频帧:像把一首歌切成无数个0.1秒的片段,AI像侦探逐个片段分析歌词。
这样处理虽然不完美(可能漏掉极快的动作或细微的声音),但平衡了准确性和效率,是目前最有效的方法!