概念 :并行任务执行引擎
- ✅ 优点:提升吞吐量,充分利用多核资源
- ❌ 缺点:复杂度高,存在竞态条件风险

python
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, START, END
from typing import TypedDict
import os
# 初始化模型
client = ChatOpenAI(
model="deepseek-r1",
openai_api_key=os.environ["BAILIAN_API_KEY"],
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",
streaming=False # 禁用流式传输
)
# 定义实体类
class PhilosophyState(TypedDict):
topic: str
part0: str
part1: str
part2: str
combined_output: str
meta_prompt = """
针对如下问题进行思考,并得出结论。
问题如下:{topic}
你分析的角度如下:{aspect}
"""
# 道家观点解释
def part0_interpreter(state: PhilosophyState):
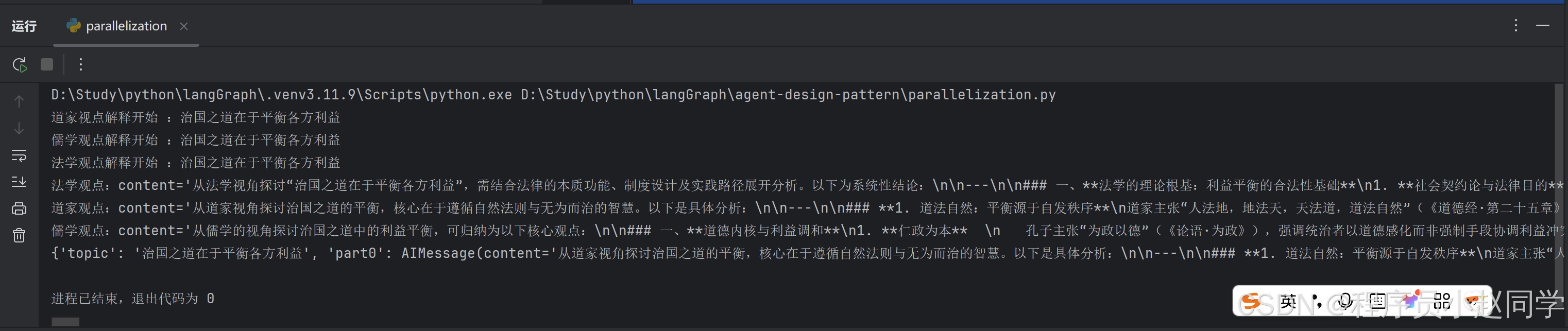
print(f"道家视点解释开始 :{state['topic']}")
prompt = meta_prompt.format(topic = state['topic'], aspect = "道家")
response = client.invoke(prompt)
print(f"道家观点:{response}")
return {'part0': response}
# 儒学观点解释
def part1_interpreter(state: PhilosophyState):
print(f"儒学观点解释开始 :{state['topic']}")
prompt = meta_prompt.format(topic=state['topic'], aspect="儒学")
response = client.invoke(prompt)
print(f"儒学观点:{response}")
return {'part1': response}
# 法学观点解释
def part2_interpreter(state: PhilosophyState):
print(f"法学观点解释开始 :{state['topic']}")
prompt = meta_prompt.format(topic=state['topic'], aspect="法学")
response = client.invoke(prompt)
print(f"法学观点:{response}")
return {'part2': response}
def aggregate_results(state: PhilosophyState):
combined = f"{state['part0']}\n{state['part1']}\n{state['part2']}"
return {'combined_output': combined }
# 创建工作流
workflow = StateGraph(PhilosophyState)
# 添加节点
workflow.add_node("part0_interpreter", part0_interpreter)
workflow.add_node("part1_interpreter", part1_interpreter)
workflow.add_node("part2_interpreter", part2_interpreter)
workflow.add_node("aggregate_results", aggregate_results)
# 添加节点边
workflow.add_edge(START, "part0_interpreter")
workflow.add_edge(START, "part1_interpreter")
workflow.add_edge(START, "part2_interpreter")
workflow.add_edge("part0_interpreter", "aggregate_results")
workflow.add_edge("part1_interpreter", "aggregate_results")
workflow.add_edge("part2_interpreter", "aggregate_results")
workflow.add_edge("aggregate_results", END)
# 编译工作流
app = workflow.compile()
result = app.invoke({"topic": "治国之道在于平衡各方利益"})
print(result)执行结果