目录
注意:以下内容都属于DDL
库的增删查改
查看数据库
格式
cpp
SHOW DATABASES;使用
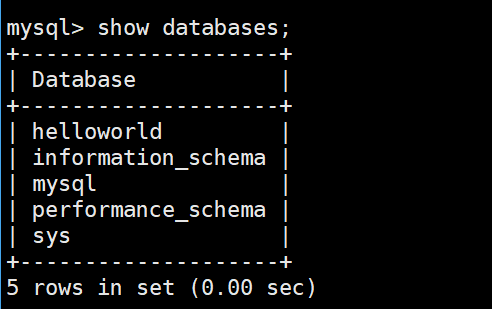
查看当前使用的数据库
格式
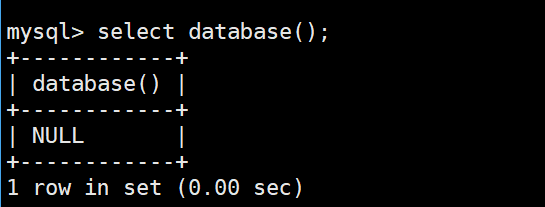
cpp
SELECT DATABASE();使用
显示数据库的创建语句
格式
cpp
SHOW CREATE TABLE 表名;使用
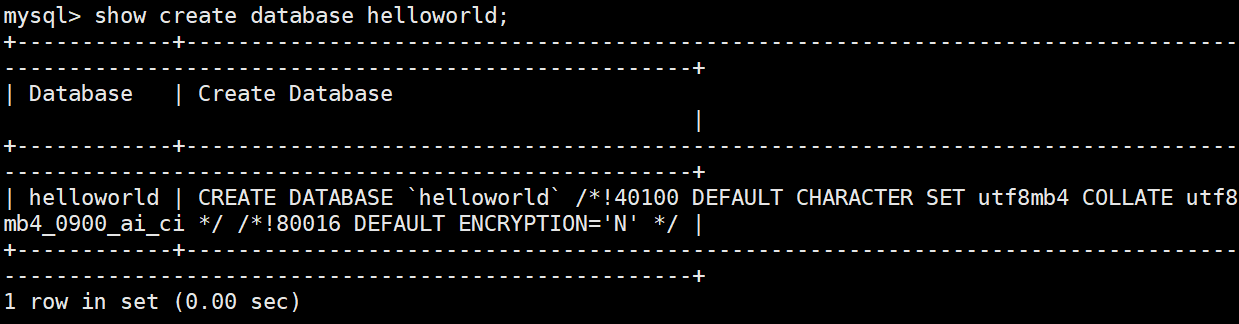 MySQL 建议我们关键字使用大写,但是不是必须的。
MySQL 建议我们关键字使用大写,但是不是必须的。
数据库名字的反引号**``,是为了防止使用的数据库名刚好是关键字**
**/*!40100 default.... */**这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话
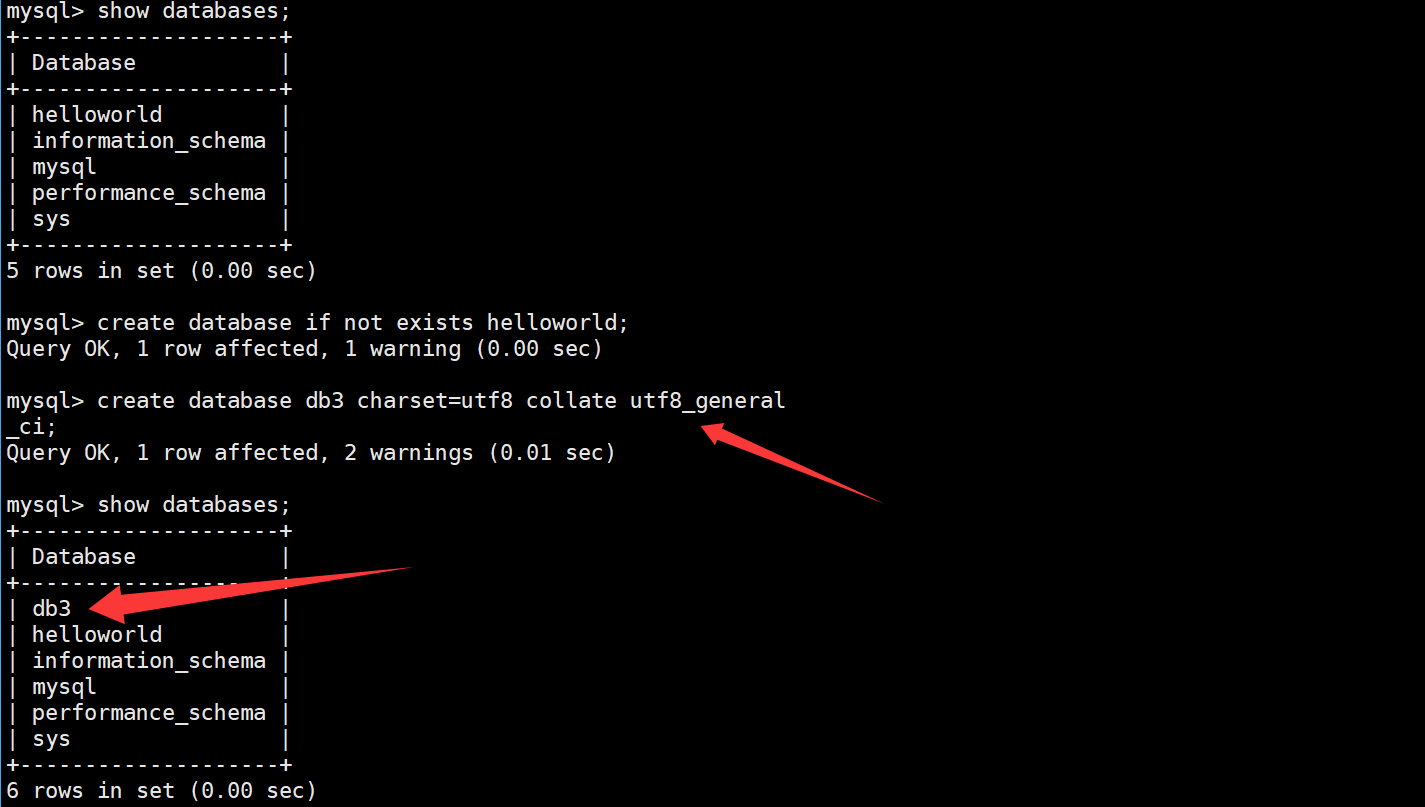
创建数据库
本质:在/var/lib/mysql 创建一个目录
cpp
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name解释:
- 大写的表示关键字
- **\[\]**是可选项
- 数据库创建的时候有两个编码集:
**CHARACTER SET:**指定数据库采用的字符集 - 数据库未来存储数据的编码方式
**COLLATE:**指定数据库字符集的校验规则 - 支持数据库,进行字段比较使用的编码,本质上也是一种读取数据库中数据采用的编码格式
数据库无论对数据做任何操作,都必须保证操作和编码必须是编码一致的!!
在当我们创建数据库没有指定字符集和校验规则时, MySQL 8.0 及以上版本默认使用 utf8mb4_0900_ai_ci 作为默认排序规则。 其他的版本默认使用的是utf8mb4_general_ci;
使用案例
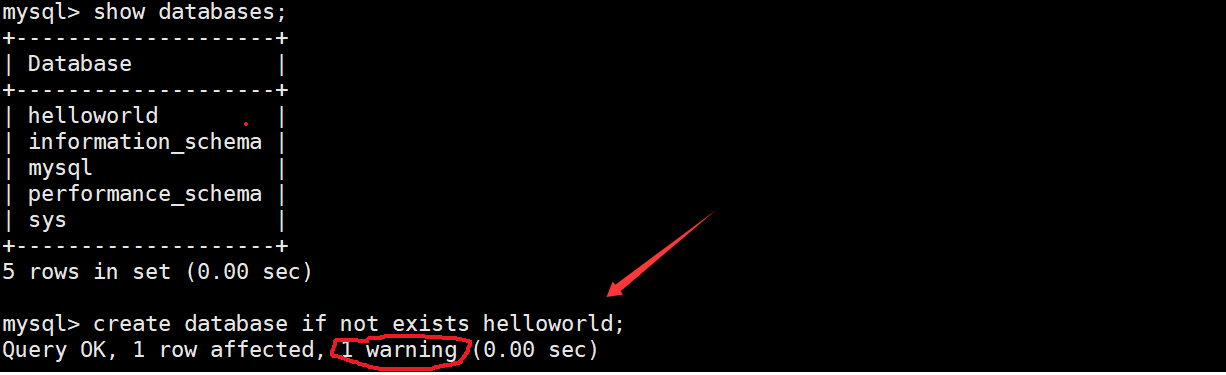
用if not exitsts选项 创建一个已经存在的数据库(我们会发现他报告warning)
创建一个使用utf字符集,并带校对规则的 db3 数据库。
删除数据库
格式
cpp
DROP DATABASE [IF EXISTS] db_ name; 执行删除之后的结果:
1、数据库内部看不到对应的数据库
2、对应的数据库文件夹被删除,级联删除,里面的数据表全部被删
注意:不要随意删除数据库,也不要随意对他进行重命名(不支持)

修改数据库
cpp
ALTER DATABASE db_name
[alter_spacification [,alter_spacification]...]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name对数据库的修改主要指的是修改数据库的字符集,校验规则
使用举例:alter database test charset=gbk collate gbk_chinese_ci;

认识系统编码(字符集和校验规则)
只要是数据无论是未来的读取还是存取,这个数据都要有对应的编码格式的,数据库是更注重编码集,且必须是统一的,我存数据的时候使用什么存储的,我取的时候也要用什么取。
创建数据库的时候,有两个编码集
1.数据库编码集 - 数据库未来存储数据
2.数据库校验集 - 支持数据库,进行字段比较使用的编码,本质也是一种读取数据库中数据的采用的编码格式
**结论:**数据库无论对数据做任何操作,都必须保证操作和编码必须是编码一致的!
查看系统默认字符集以及校验规则
cpp
show variables like 'character_set_database';
show variables like 'collation_database';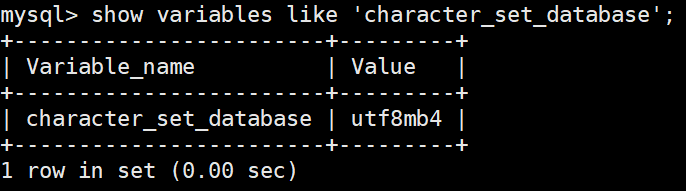
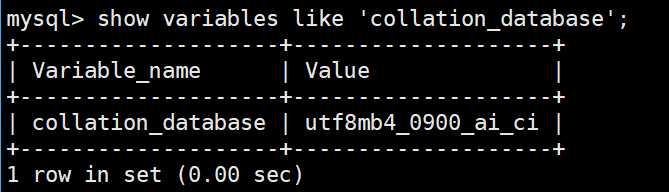
**注意:**MySQL 8.0 及以上版本默认使用 utf8mb4_0900_ai_ci 作为默认排序规则。 其他的版本默认使用的是utf8mb4_general_ci;
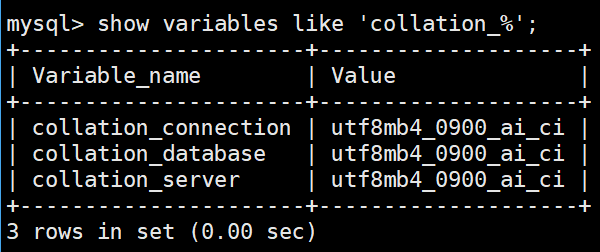
我们可以不只看database,还可以使用
cpp
show variables like 'collation_%';查看connection(链接)和server(服务)
查看数据库支持的字符集和字符集校验规则
查看数据库支持的字符集
cpp
show charset;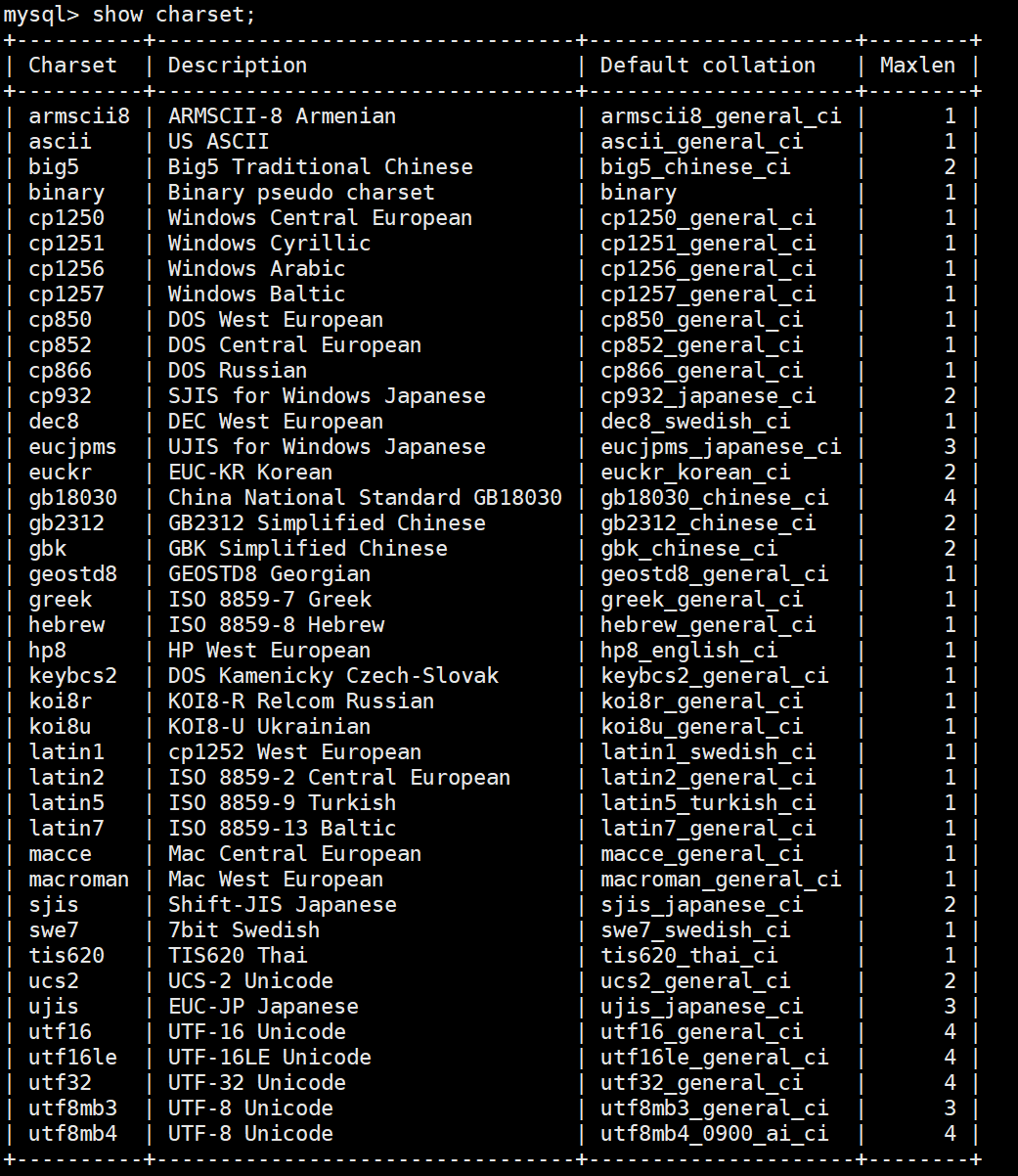
查看字符集校验规则
cpp
show collation;
验证不同校验码编码的影响
cpp
create database d1;
create database d2 charset=utf8;
create database d3 character set utf8;
create database d4 charset=utf8 collate utf8_general_ci;创建一个数据库test1,校验规则使用utf8_ general_ ci不区分大小写
cpp
create database test1 collate utf8_general_ci;创建一个数据库test2,校验规则使用utf8_ bin区分大小写
cpp
create database test2 collate utf8_bin; 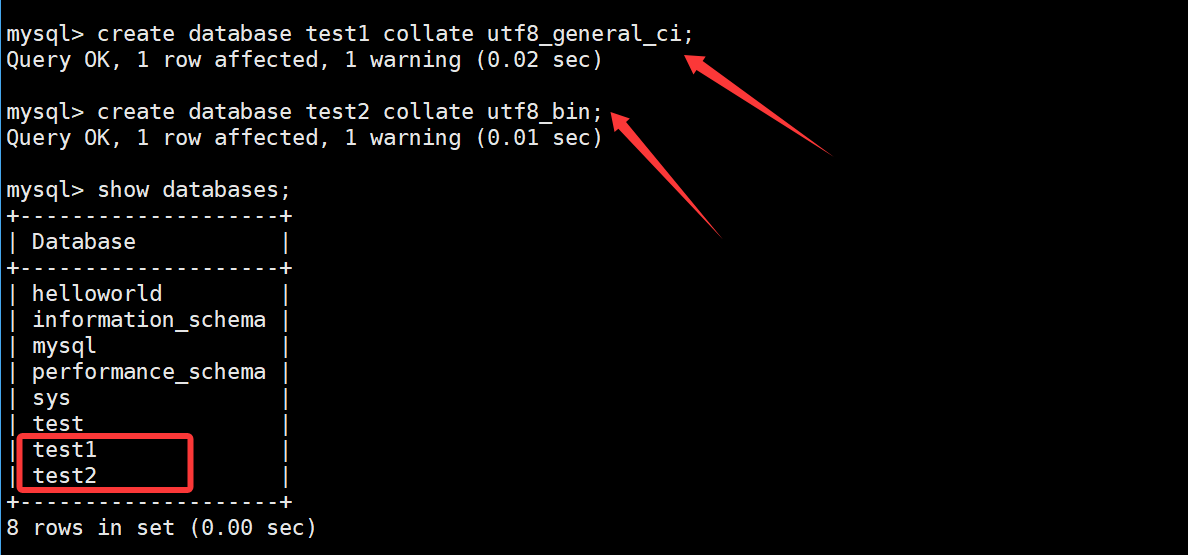
进入第一个数据库,暂时没有表
cpp
use test1;
show tables;
我们开始尝试建表
cpp
create table if not exists person(name varchar(20));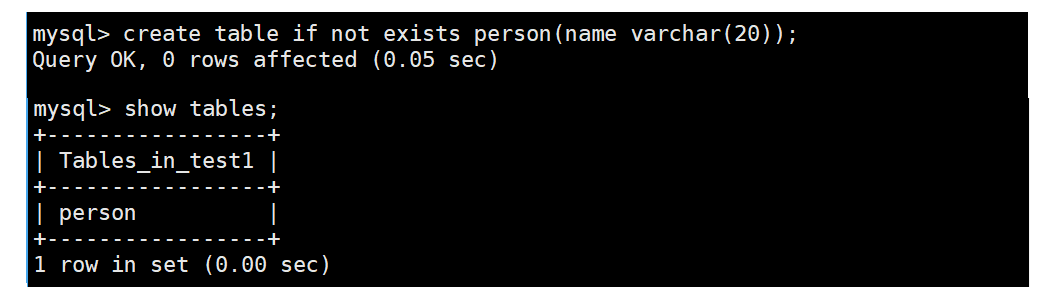
用desc我们查看表结构的详细信息
cpp
desc person;
插入数据并检索数据
insert into person values('a');//采用编码规则
select *from person;//采用校验规则
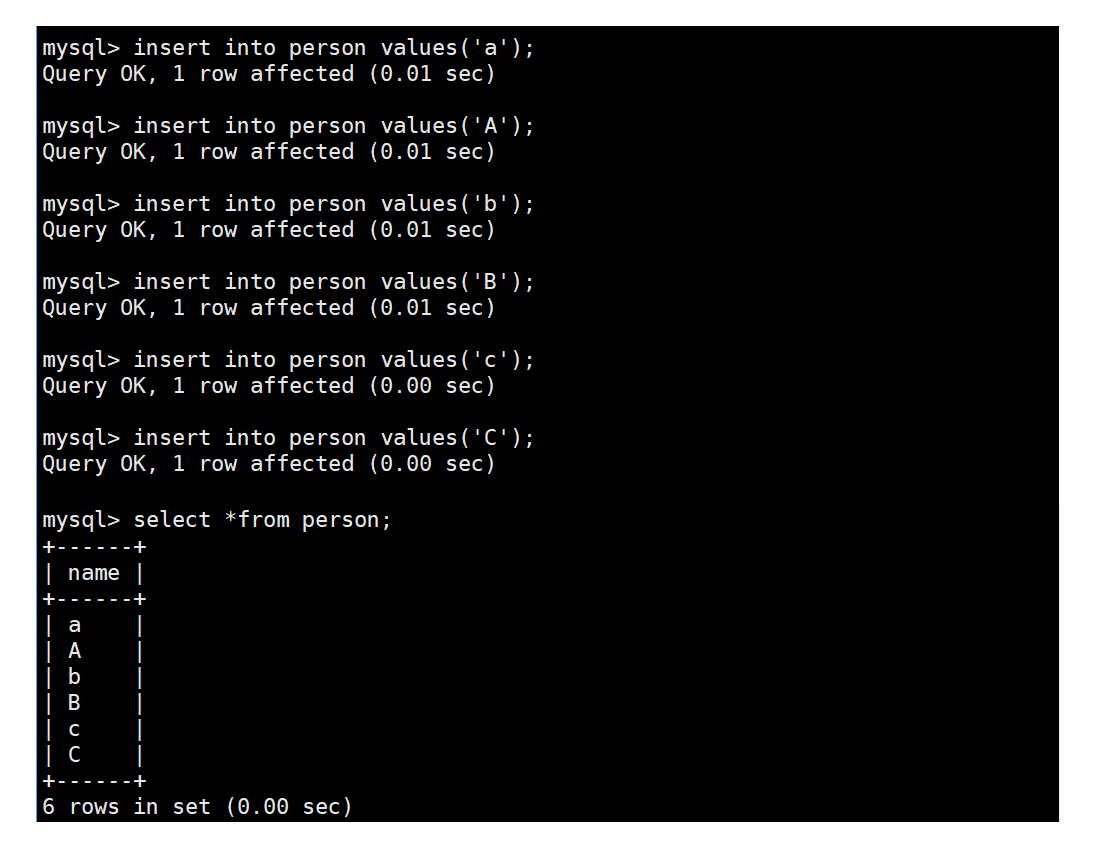
检索name为a的数据
比较也是用校验规则utf8_general_c不区分大小写
cpp
select *from person where name='a';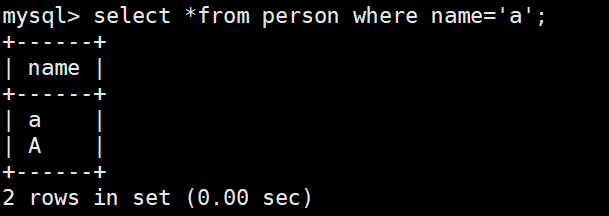
按照上述方法查看test2
utf8_bin 区分大小写
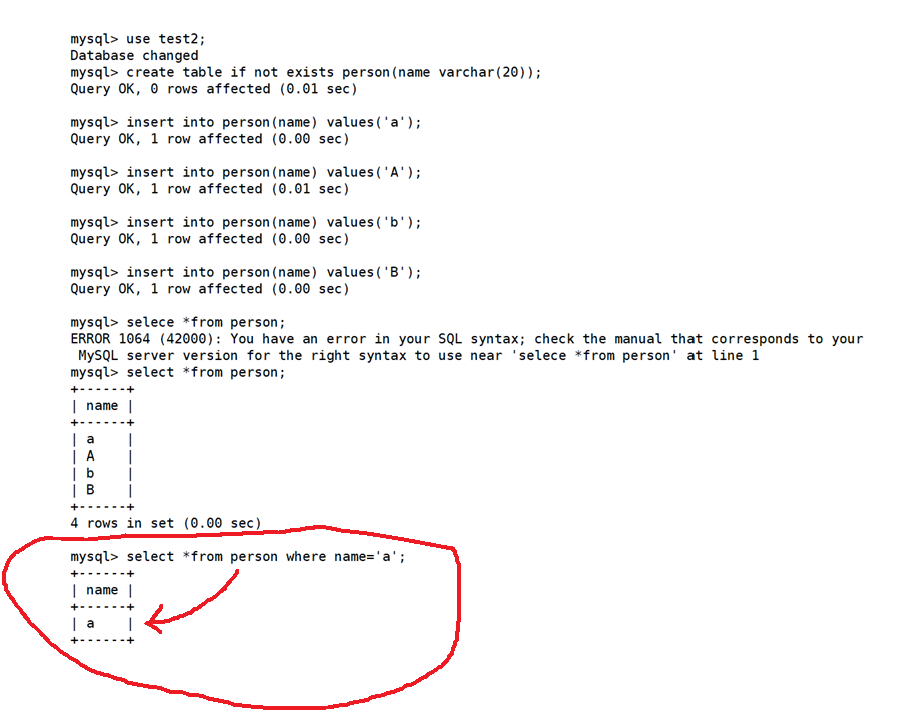
分别对test1和test2进行排序
cpp
select * from person order by name;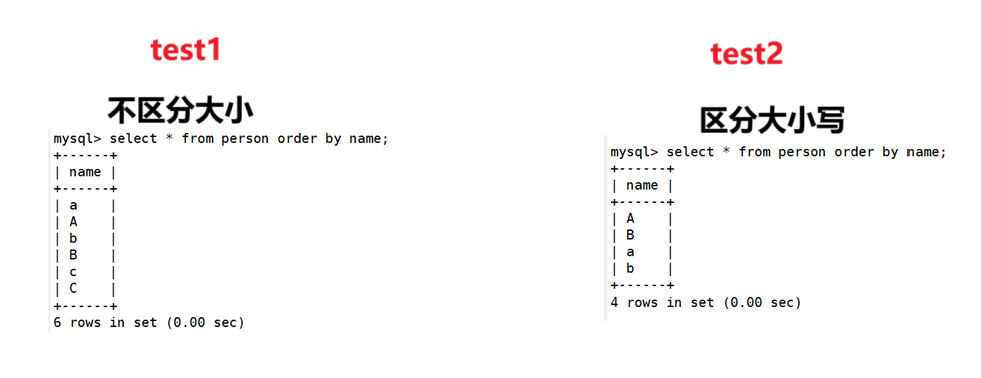
校验规则对数据库的影响
也就是如果不校验规则的话,**那么可能我们想要查找的数据和数据库返回的不一样。**比如说我们想让保安通过喇叭在学校找一个高三叫小明的同学,但是保安忽略了高三年级,而是直接说,请小明同学来到办公室,这里有人找你,那么全学校的小明就都会响应,那这的数据肯定就是错的了
数据库的备份和恢复
备份
备份的并不只有数据,还有使用该数据库的时候的所有有效操作
cpp
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径这个命令的各个部分的含义是:
mysqldump:MySQL 提供的命令行工具,用于创建数据库的备份(导出)-P3306:指定 MySQL 服务器的端口号,3306 是默认端口-u root:指定用户名为 root-p 密码:指定访问数据库的密码(注意:在命令行中直接写密码是不安全的)-B 数据库名:指定要备份的数据库,-B 参数表示包含创建数据库和使用数据库的语句> 数据库备份存储的文件路径:将备份内容重定向到指定的文件路径
执行此命令后,mysqldump 会将指定数据库的所有表结构和数据导出为 SQL 语句,保存到指定的文件中。这个备份文件可以用于数据库的还原操作。

这时,可以打开看看 test2.sql 文件里的内容,其实把我们整个创建数据库,建表,导入数据的语句都装载这个文件中。
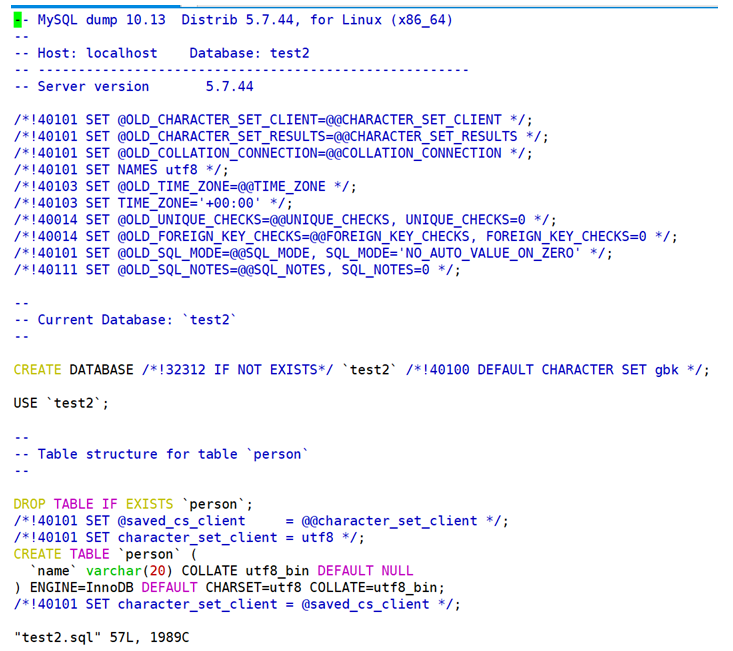
恢复
cpp
mysql> source /root/test2.sql; 我们先把test2给删了 然后再还原。
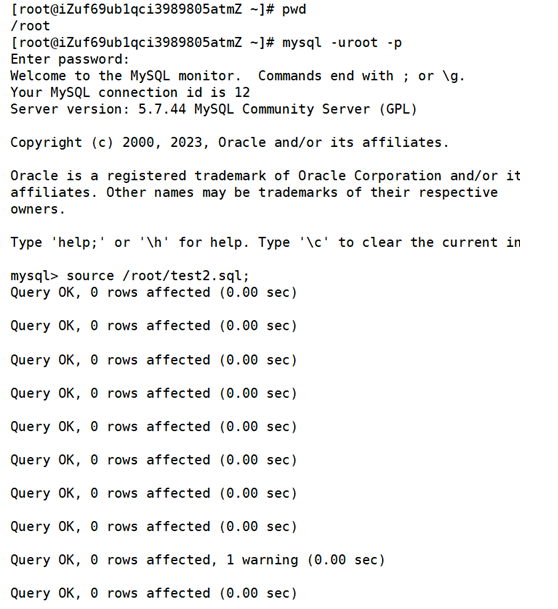
它会把备份文件里的sql语句全部都跑一遍。

其他情况
如果备份的不是整个数据库,而是其中的一张表,怎么做?
cpp
# mysqldump -u root -p 数据库名 表名1 表名2 > D:/mytest.sql 同时备份多个数据库 ?
cpp
# mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径 如果备份一个数据库时,**没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原。**如果带了B 那么备份文件里会有create database这样的语句
查看当前数据库的具体链接情况
cpp
show processlist
可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是你正常登陆的,很有可能你的数据库被人入侵了。以后大家发现自己数据库比较慢时,可以用这个指令来查看数据库连接情况。
表的增删查改
增加表
我们先用MyIsam作为引擎,进行创建表
cpp
CREATE TABLE IF NOT EXISTS user1 (
id int,
name varchar(20) COMMENT '用户名',
password char(32) COMMENT '用户密码',
CHARACTER SET utf8 COLLATE utf8_general_ci ENGINE MyISAM
);如果不加后面的字符集和校验规则就默认使用数据库的
当创建表之后,我们发现对应的Linux下数据库目录中会多了关于user1的文件

注意:在老版本中
在MySQL 8.0之前(5.7及更早版本),表的元数据存储在以下文件中:
- .frm文件:存储表结构
- .MYD文件:MyISAM表的数据文件
- .MYI文件:MyISAM表的索引文件
而在MySQL 8.0及以后版本中:
- .frm文件被移除
- 表元数据存储在InnoDB数据字典中
- .sdi(Serialized Dictionary Information) 文件包含序列化的表定义信息
我们再用InnoDB作为引擎创建个表,如果查看它的文件
cpp
CREATE TABLE IF NOT EXISTS user2 (
id int,
name varchar(20) COMMENT '用户名',
password char(32) COMMENT '用户密码'
) CHARACTER SET utf8 COLLATE utf8_general_ci ENGINE InnoDB;会发现user2和user1的个数不一样
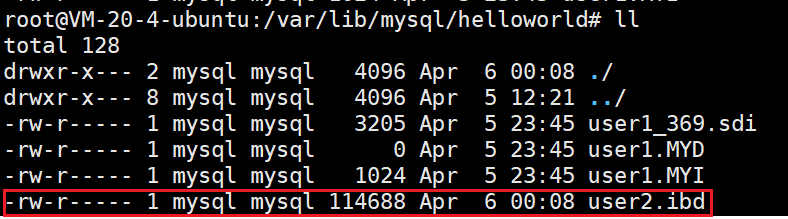
其实这里与存储引擎的索引是有关系的,我们后续再讲。
查看表
如果我们忘记了当前所在数据库的名称,可以使用
cpp
SELECT DATABASE();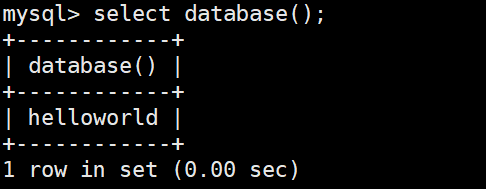
列出数据库中的所有表
cpp
SHOW TABLES;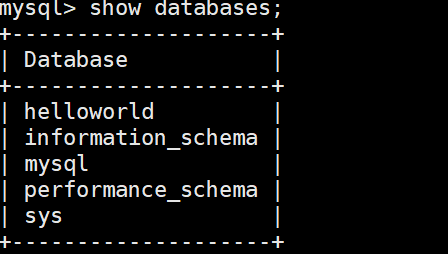
列出特定数据库中的所有表
cpp
SHOW TABLES FROM database_name;
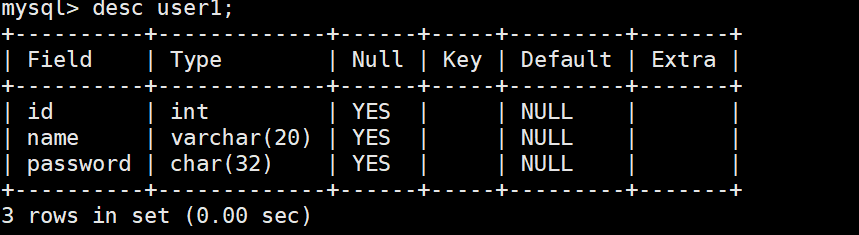
提供表的基本结构信息,以简洁的表格形式展示
cpp
DESC table_name;显示的内容包括:
- 列名(Field)
- 数据类型(Type)
- 是否允许NULL值(Null)
- 键类型(Key),如PK(主键)、FK(外键)等
- 默认值(Default)
- 其他属性(Extra),如AUTO_INCREMENT
返回创建该表时使用的完整CREATE TABLE语句
cpp
SHOW CREATE TABLE table_name;- 包含更详细的信息,比如:
- 表的存储引擎(ENGINE)
- 字符集(CHARSET)
- 排序规则(COLLATE)
- 索引定义(包括主键、外键、唯一索引等)
- 约束条件
- 表注释
- 分区信息(如果有)

这样看着挺不舒服的,我们可以把**;改成\G**,使用\G结尾时,MySQL会将结果以垂直方式显示,每个字段独占一行,这在查看包含多列或宽列的表结构时特别有用。
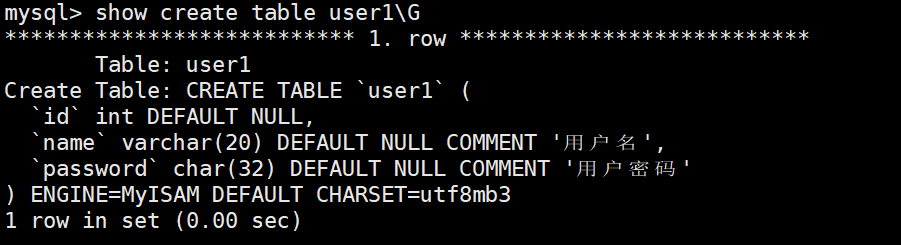
但是仔细看就会发现,这跟我当时写的不一样呀?其实你看起来好像和你创建的写法不一样,但实际上是因为mysqld对你的sql语句进行语法分析词法分析的时候,可能你的sql语句写法不是很标准,他会帮你转化成比较标准化的写法,留下你的所有操作痕迹
修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎 等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
先在我们的user1中添加一些数据
cpp
insert into user1 values(1,'a','1982-01-04');
insert into user1 values(2,'a','1983-05-04');
在password之后,新添加一列
格式
cpp
ALTER TABLE 表名 ADD COLUMN 新列名 数据类型 [约束条件] AFTER 已存在的列名;使用
cpp
alter table user1 add image_path varchar(128) comment '这个是用户的头像路径' after password;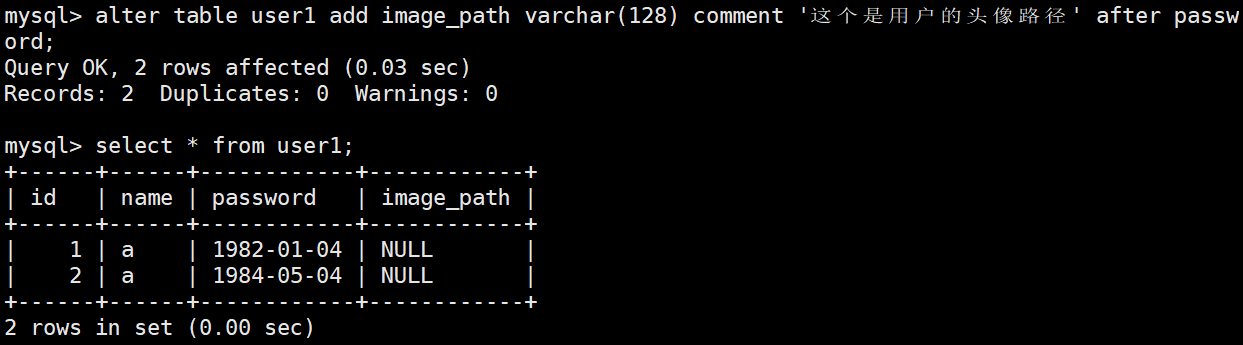
修改某一列的类型属性(比如长度)
格式
cpp
ALTER TABLE 表名 MODIFY COLUMN 列名 新数据类型 [新约束条件];使用
cpp
alter table user1 modify name varchar(60);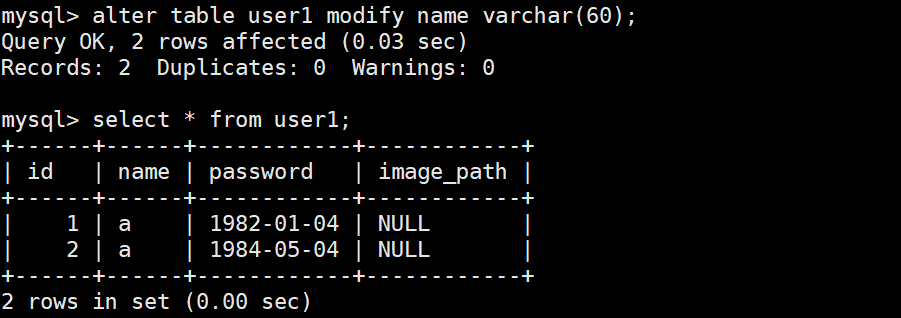
需要注意的是他会把原来所有的属性给直接覆盖!!(name字段的comment描述没有了)
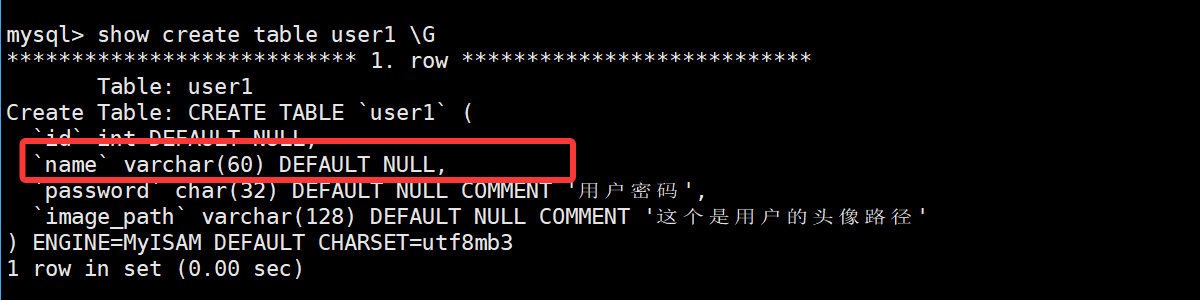
修改-删除password列
格式
cpp
ALTER TABLE 表名 DROP COLUMN 列名;使用
cpp
alter table user1 drop password;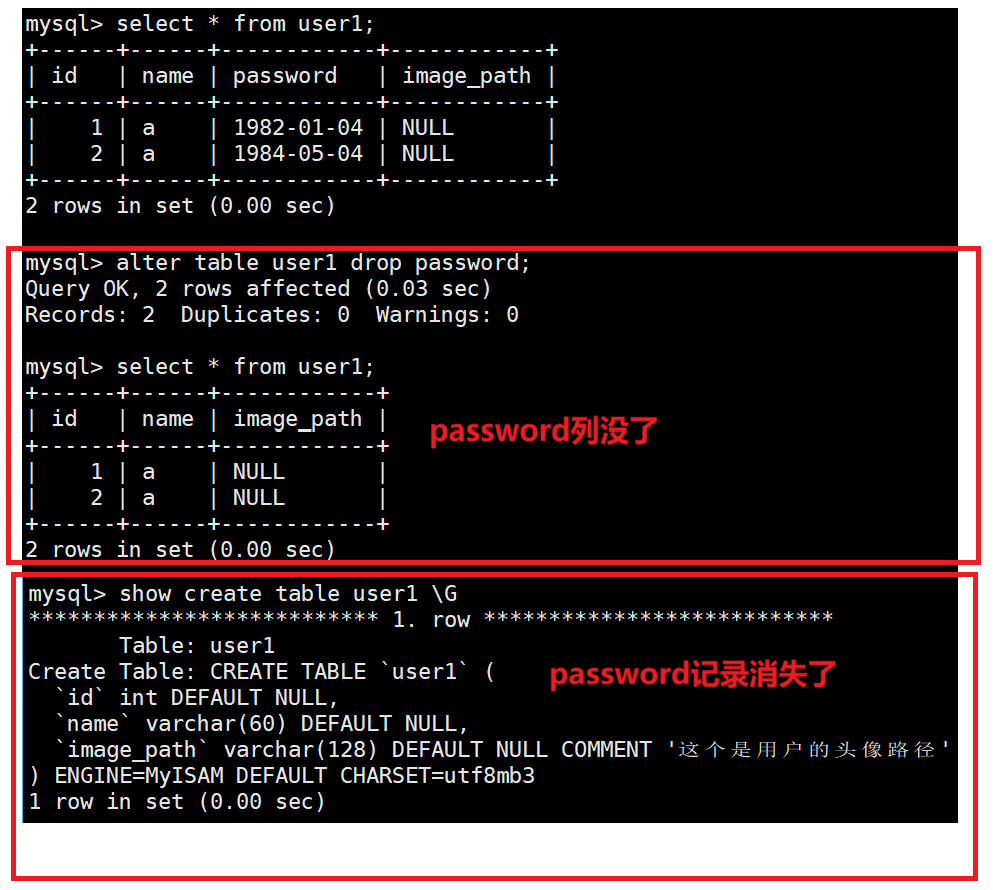
修改表名
格式
cpp
ALTER TABLE 旧表名 RENAME TO 新表名;使用
cpp
alter table user1 rename to user;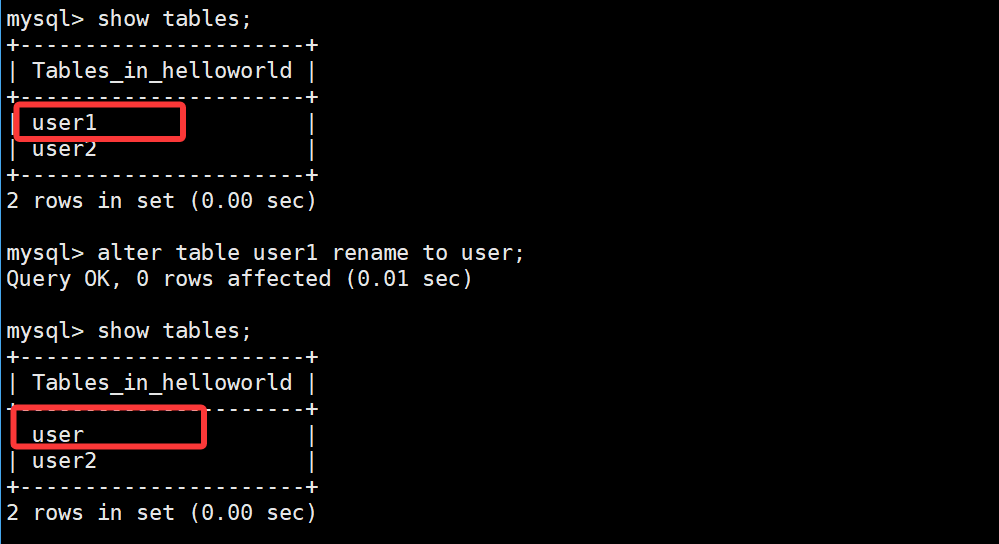
修改列名
cpp
ALTER TABLE 表名 CHANGE COLUMN 旧列名 新列名 数据类型 [约束条件];不仅要提供列名称,也要把列的相关属性提供给我
cpp
alter table user1 change id xuhao int;删除表
格式
cpp
DROP TABLE 表名;使用
cpp
drop table user2;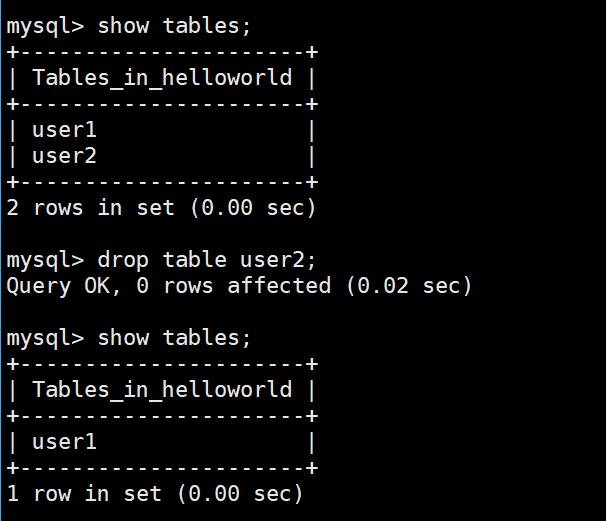
注意:轻易不要做修改或者删除,表跟数据库一样,在所有的业务处理过程中都靠近底层、后端,所以表结构、表名称、表是否存在等修改直接决定了所有使用该数据库的上层要不要改变!!
作为一个程序员来说,如果一旦开发了很长时间且表结构已经建好了,一旦在后期出现了需要修改表结构的情况,那么整个上层的业务逻辑可能都需要被改变!!因此这样的影响是非常巨大的!