二、机器学习概述
文章目录
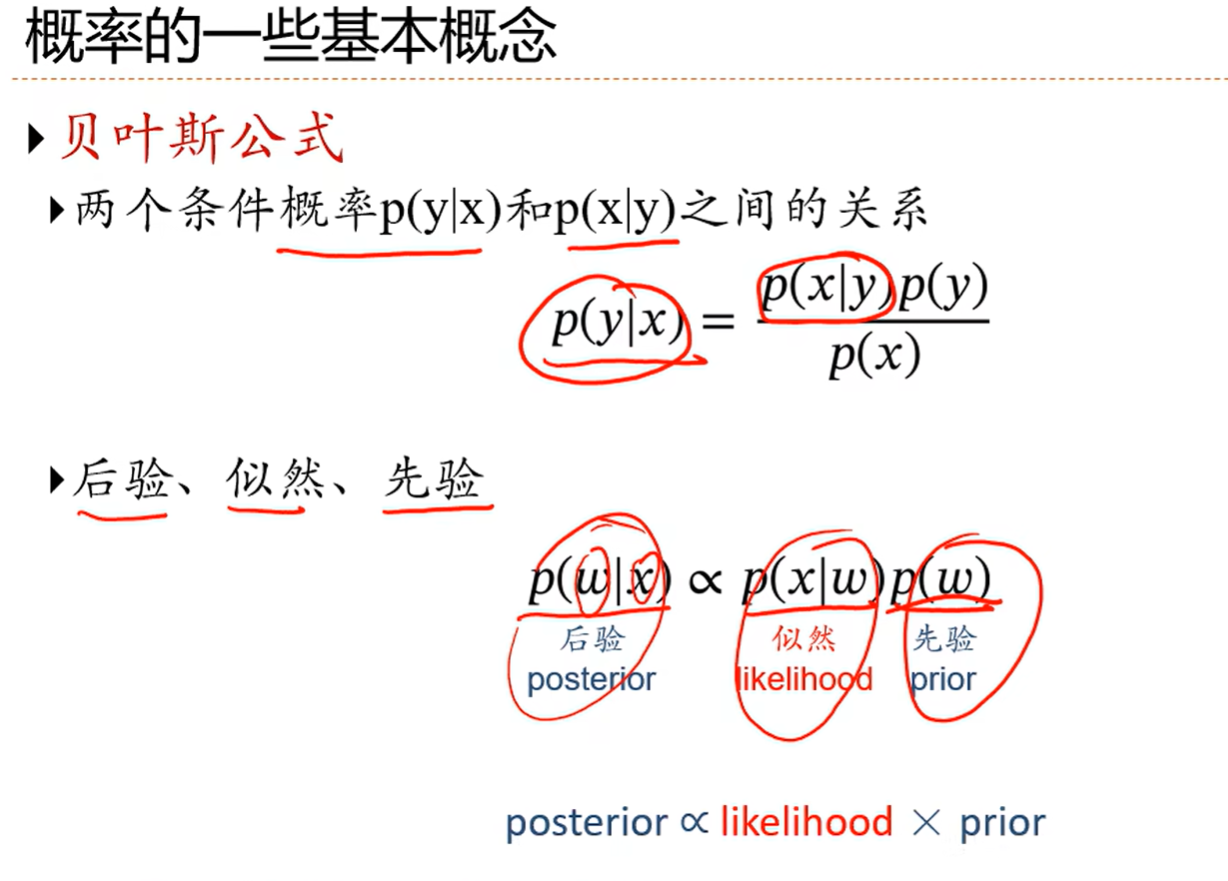
2.1 关于概率
概率&随机变量&概率分布

离散随机变量:
伯努利分布:

二项分布:

连续随机变量:
概率密度函数

累计分布函数

联合概率:
都发生指定的情况的概率,就是相乘;
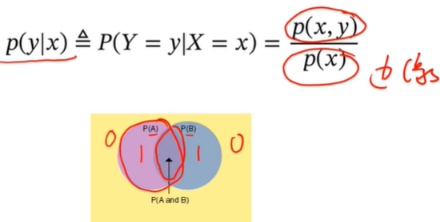
条件概率:
对于离散随机向量(X,Y),已知X=x的条件下,随机变量Y=y的条件概率为
2.2 机器学习
如何构建映射函数 => 大量数据中寻找规律;
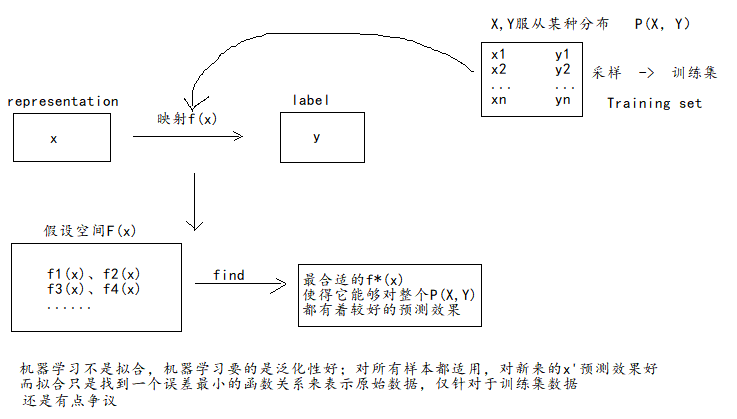
机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或"猜测")出具有一般性的规律,并利用这些规律对未知数据进行预测的方法.
2.3 机器学习类型
- 回归问题:房价预测、股票预测等;
- 分类问题:手写数字识别,垃圾邮件监测、人脸检测;
- 聚类问题:无监督学习,比如找出相似图形;
- 强化学习:与环境交互来学习,比如AlphaGo;
- 多种模型:监督学习+无监督学习等等,自动驾驶;

典型的监督学习:回归、分类;
典型的无监督学习:聚类、降维、密度估计;
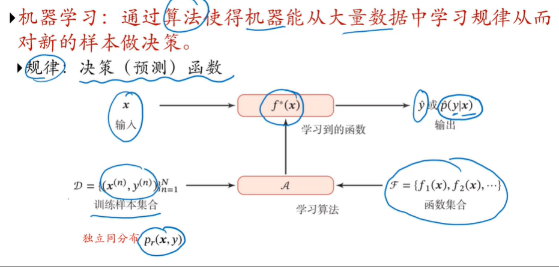
2.4 机器学习基本要素
- 数据:有数据才能训练;
- 模型:给定假设空间,从中选择最优模型,能够预测x和y的关系
- 学习准则:判断模式是好是坏;
- 优化算法:用一些数学优化算法来学到所期望的模型;
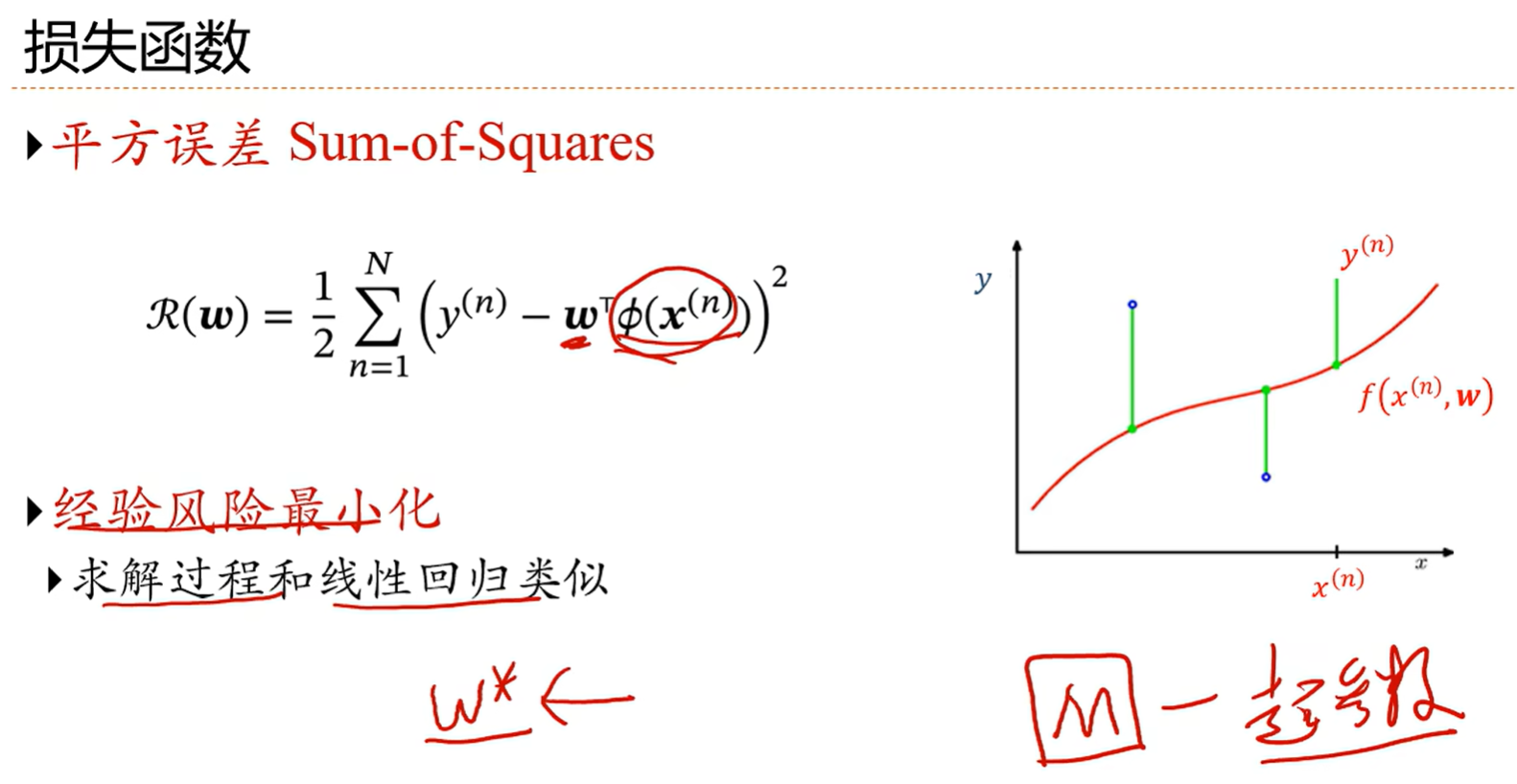
学习准则:以回归问题为例:
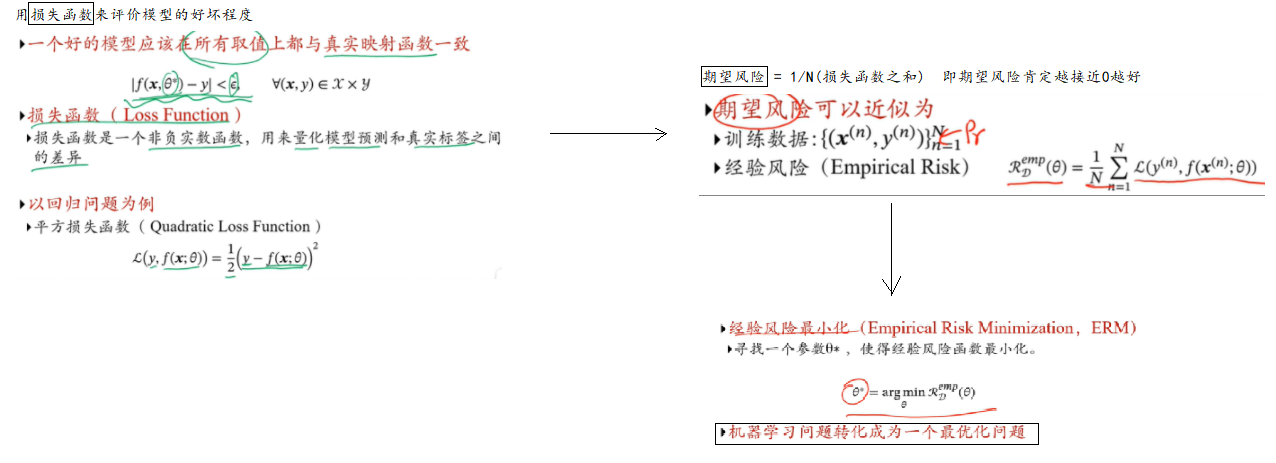
机器学习问题 -> 最优化参数问题;
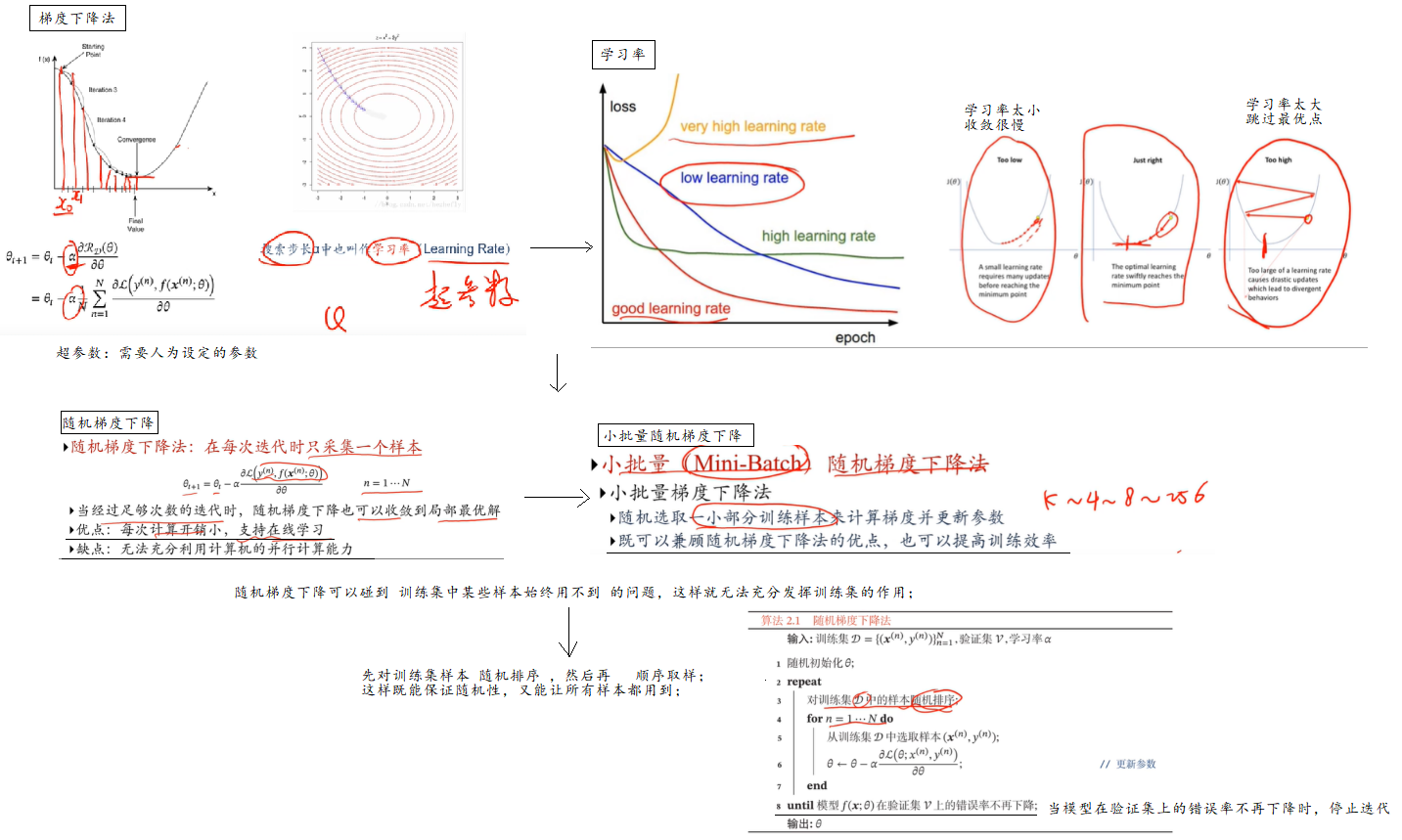
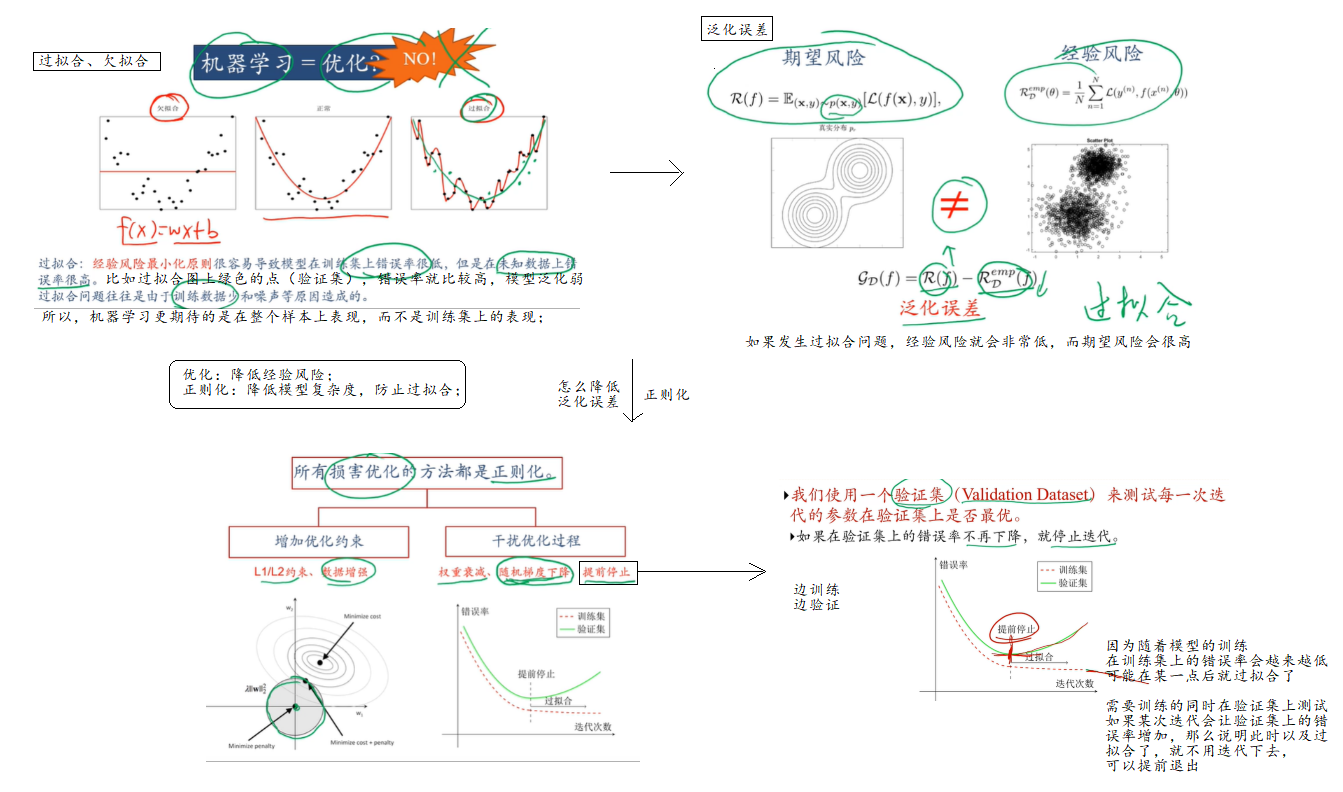
2.5 泛化和正则化
Q:为什么不用训练集上的错误率还验证模型好坏呢?
涉及到模型的泛化问题;
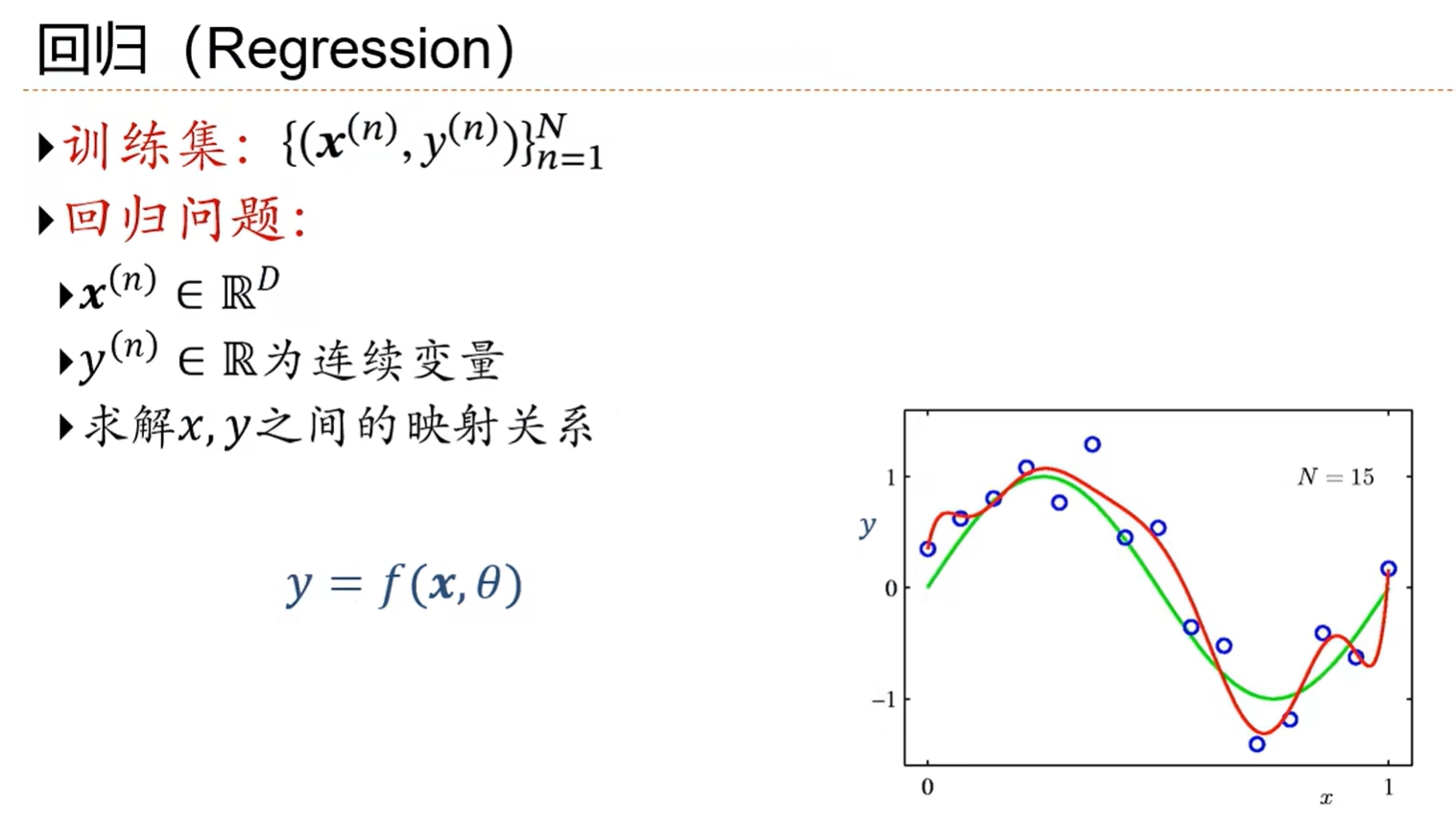
2.6 举例:线性回归
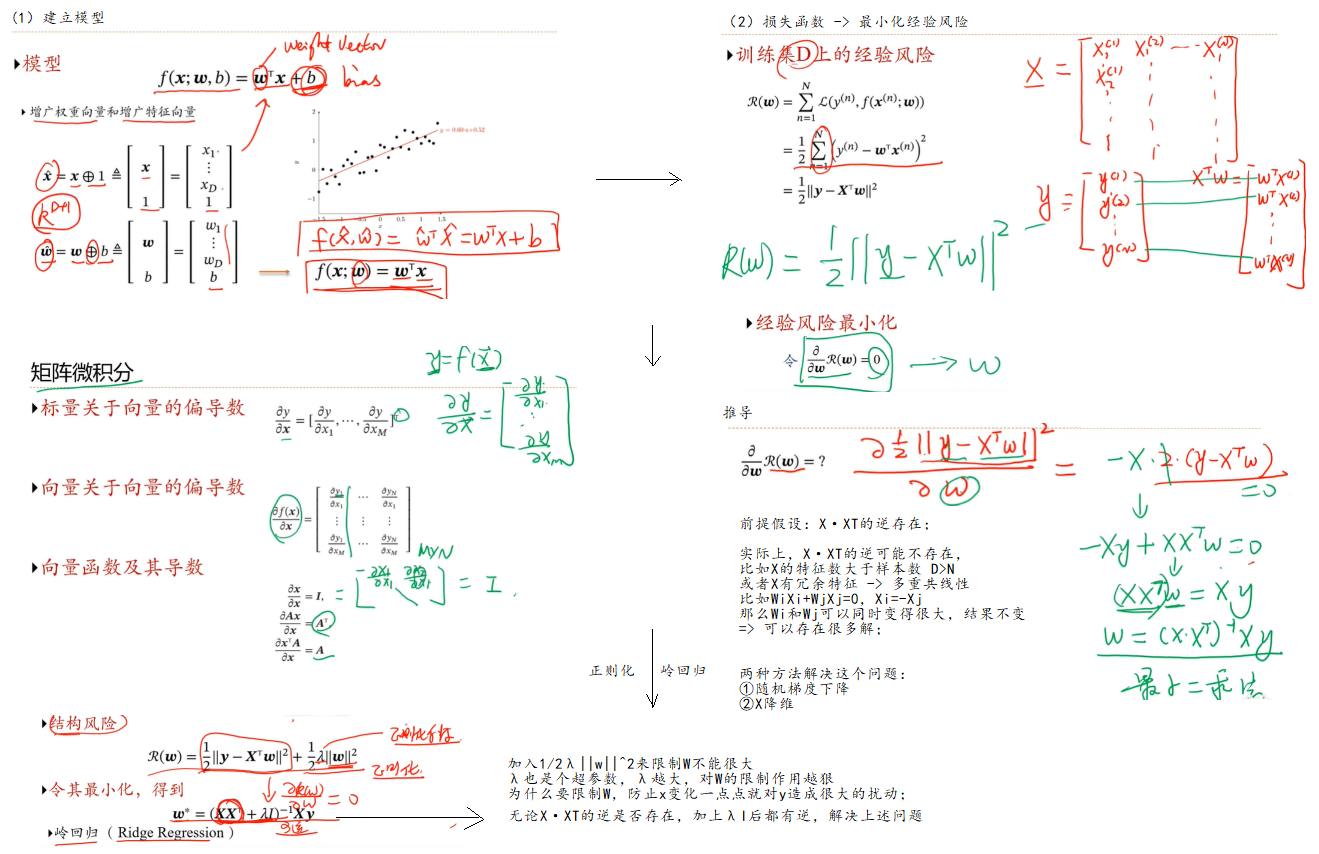
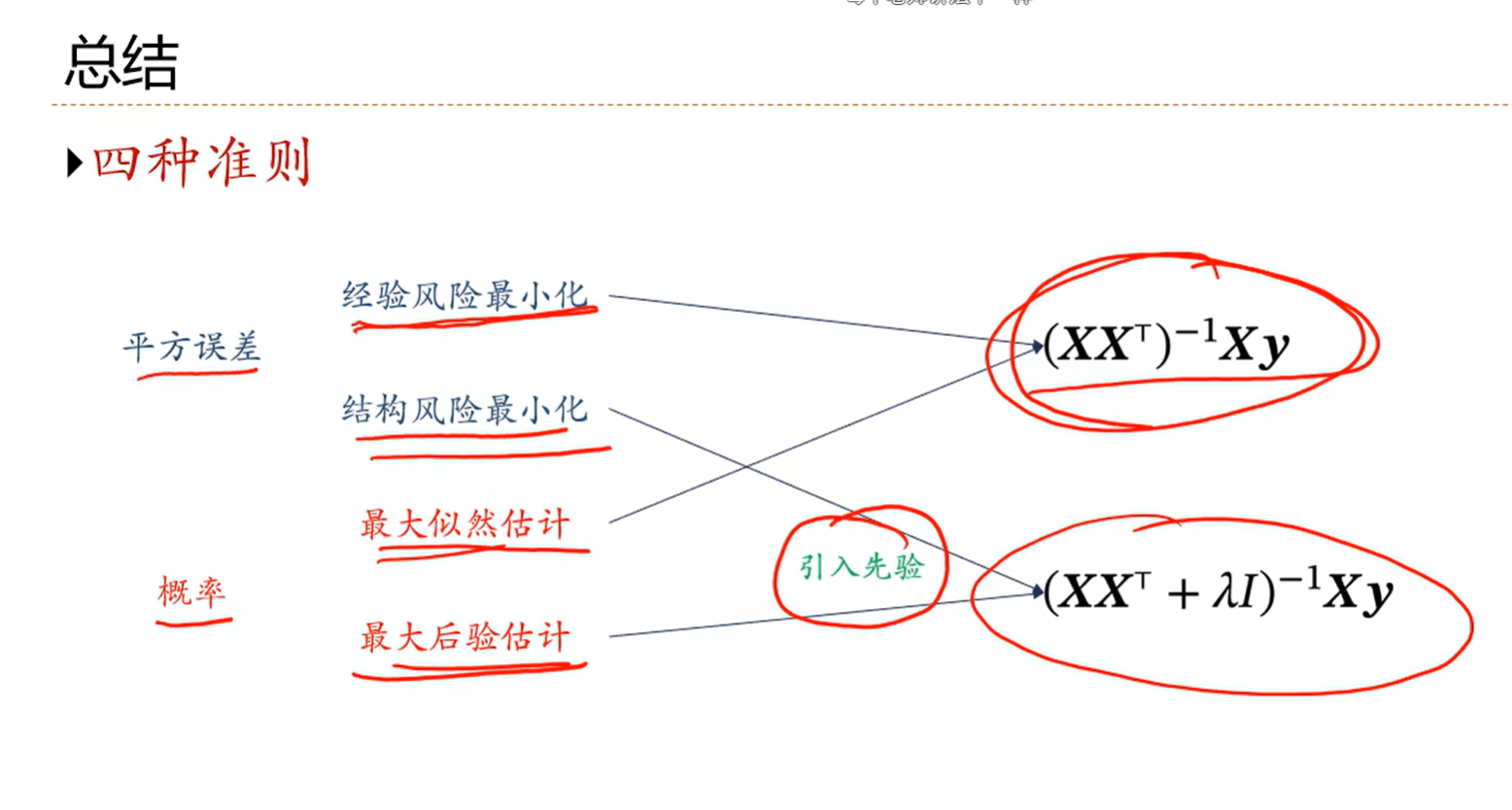
1.下面求解线性回归参数的方法也叫最小二乘法
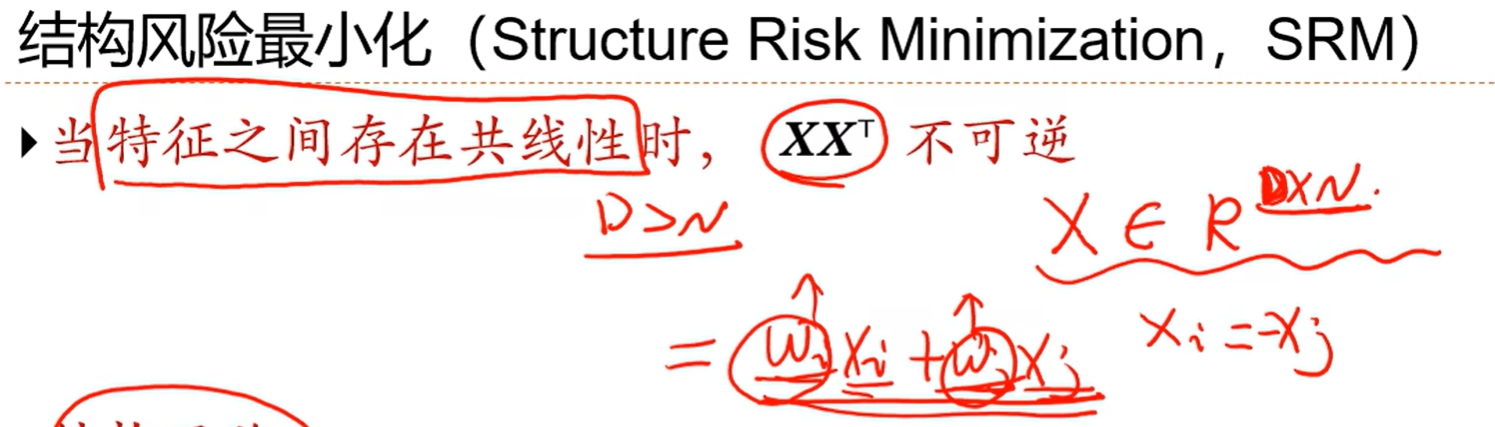
2.x*x转置 的逆存在的条件是x的各个行向量之间是线性不相关的
3.引入结构风险最小化
假如第i个特征和第j个特征互为相反数,即线性相关,那么wi和wj就可以同时变得很大,那么xi的一个非常小的扰动可能会对结果造成较大的影响
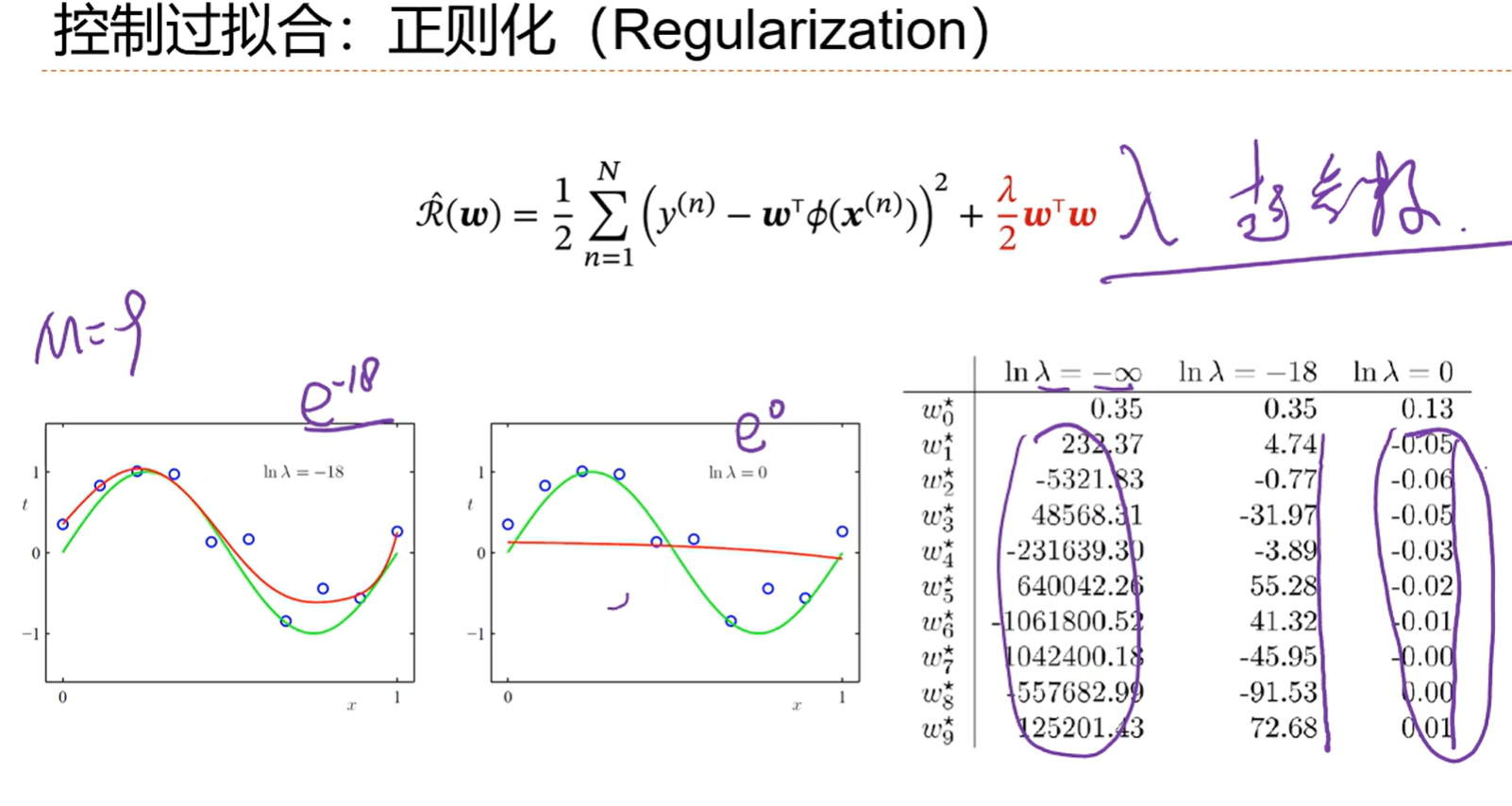
4.结构风险图中的拉姆达是人为加上去的,就是正则化系数,拉姆达越大对w限制越狠
最小化之后发现 x*x转置+拉姆达*单位矩阵,这个东西的逆一定存在,那么就说明会一直有解
就解决了经验风险最小化的时候解有可能不存在即解不稳定的问题
2.7 举例:多项式回归
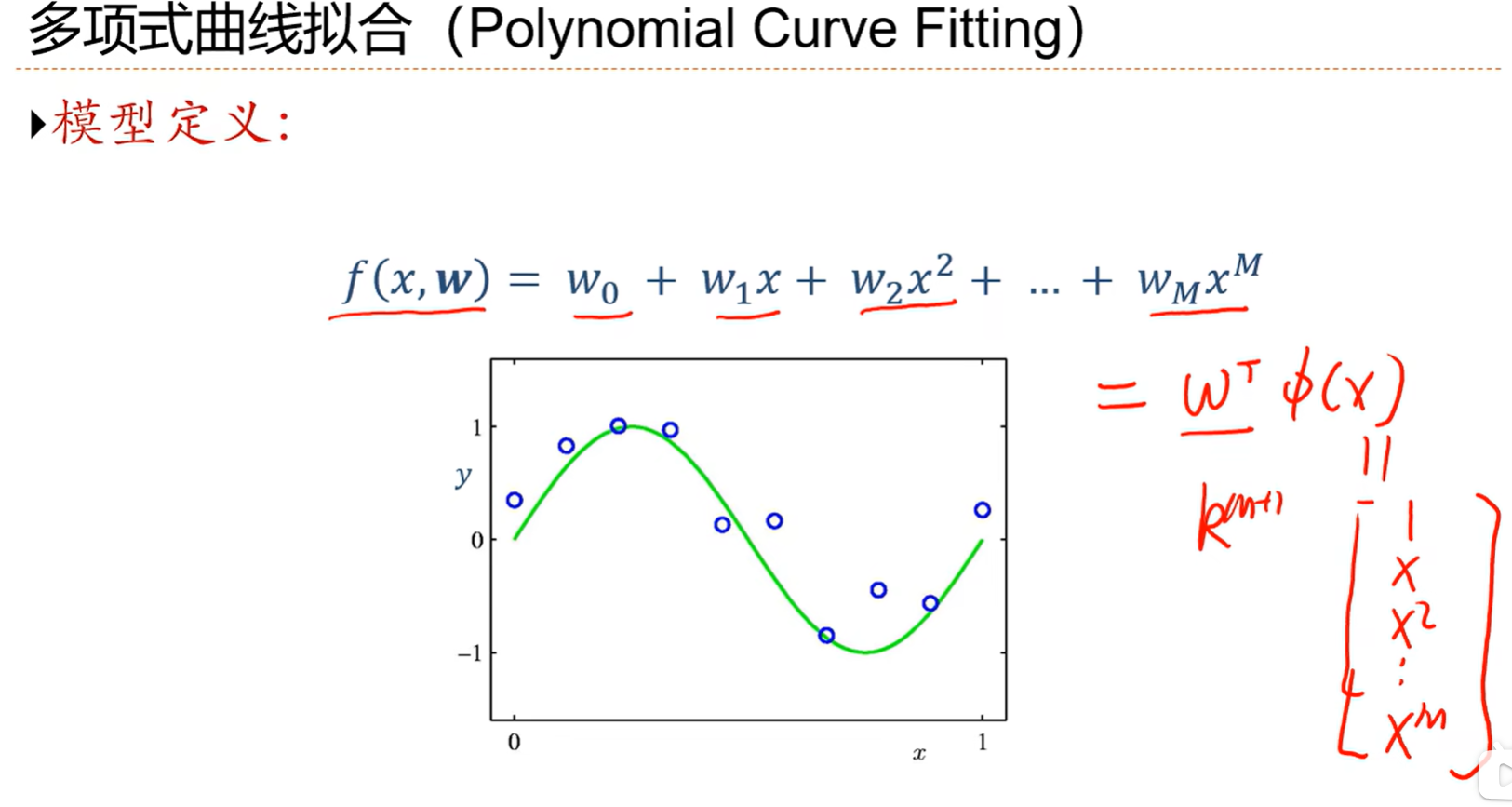
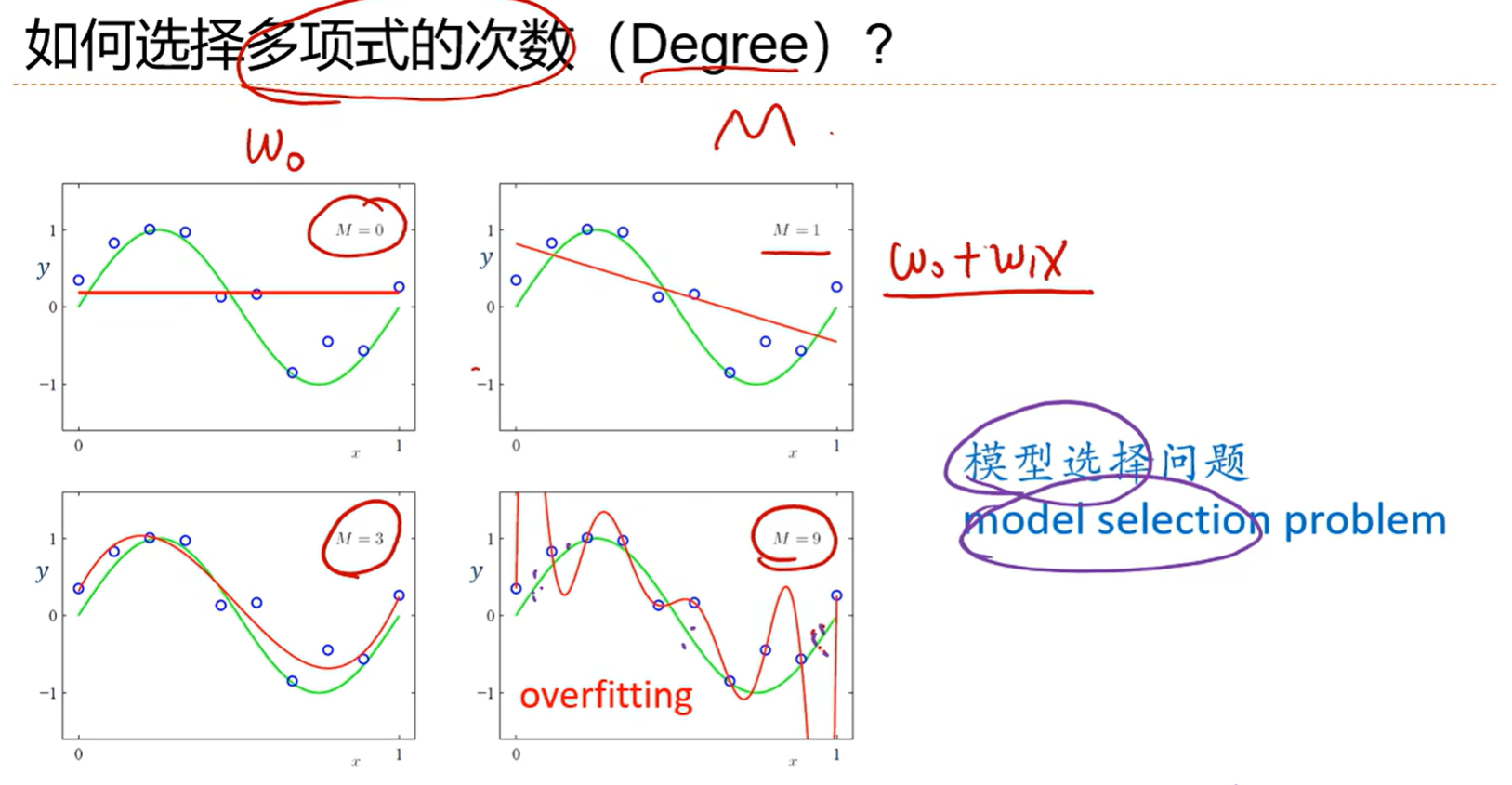
但是我们这些方法都是用来求w的,而多项式次数M却没有求,这是个超参数,是人为设置的
M<3时,欠拟合了
M=9时,过拟合了,所以模型的选择很重要,每个不同的M都是一个不同的模型
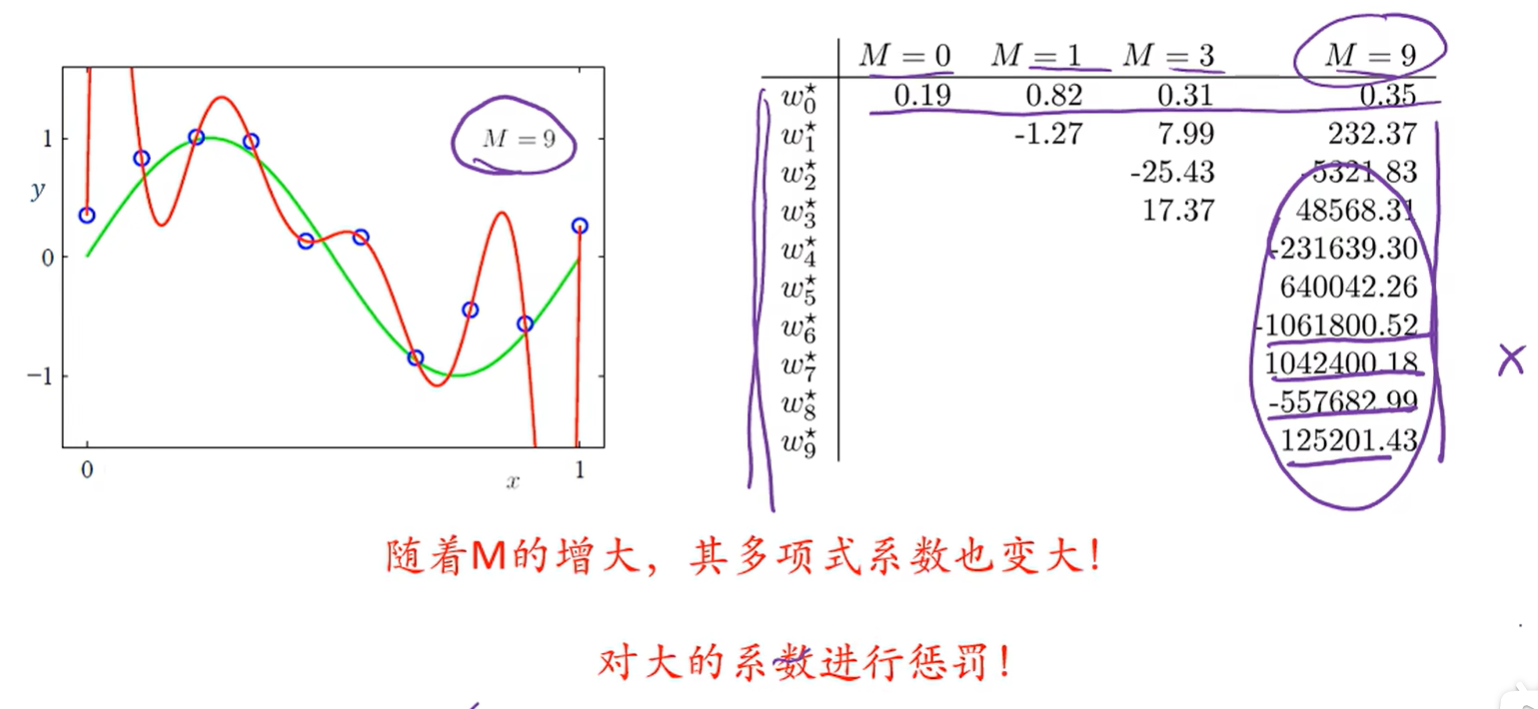
而多项式系数变大代表着不稳定,代表着只要一点小小扰动就会让结果发生很大变化
所以就引入正则化项来解决过拟合

拉姆达也是一个超参数,下图用来表示拉姆达取这两个值的时候对w的约束
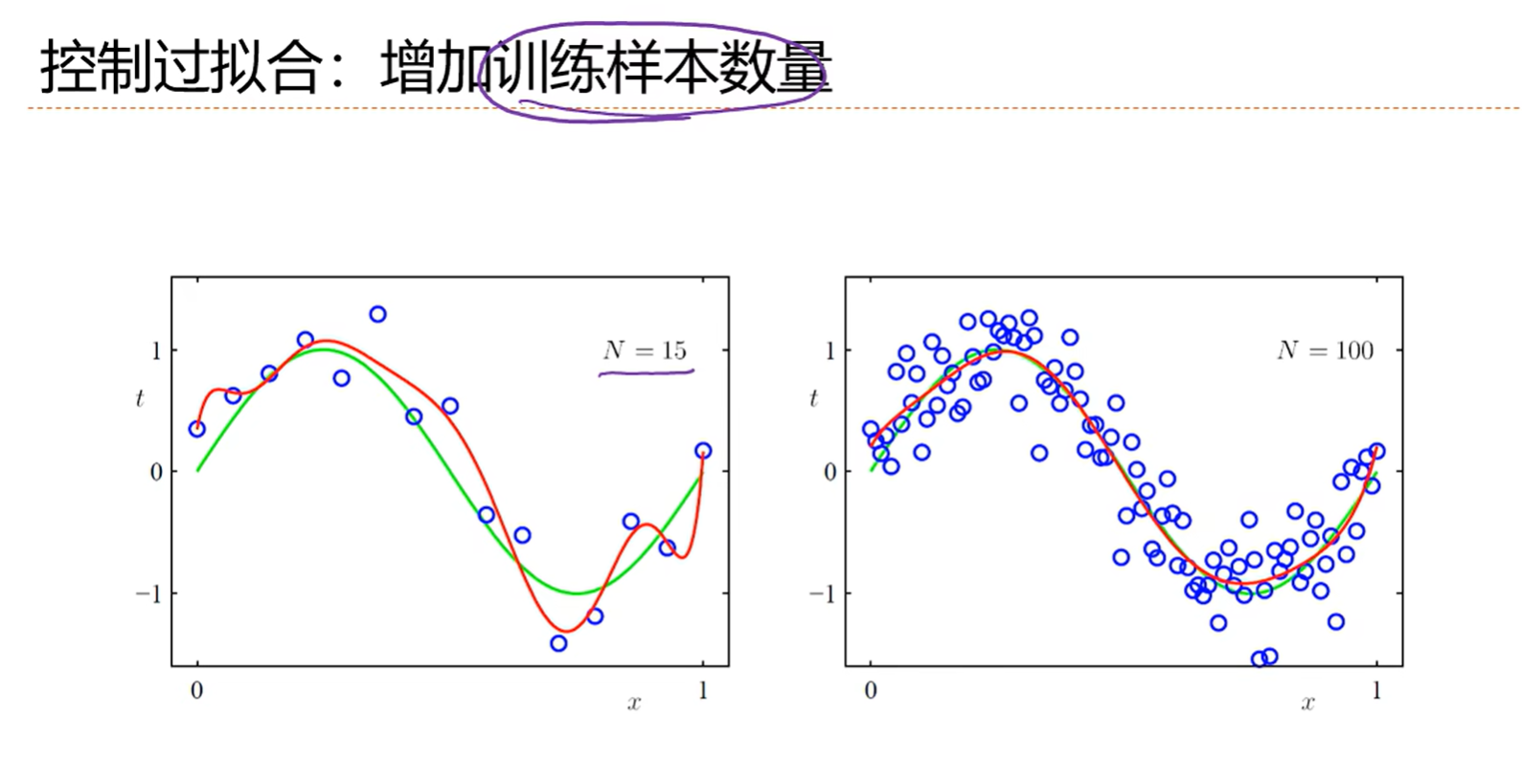
除了正则化还有一个手段解决过拟合
2.8 线性回归的概率视角
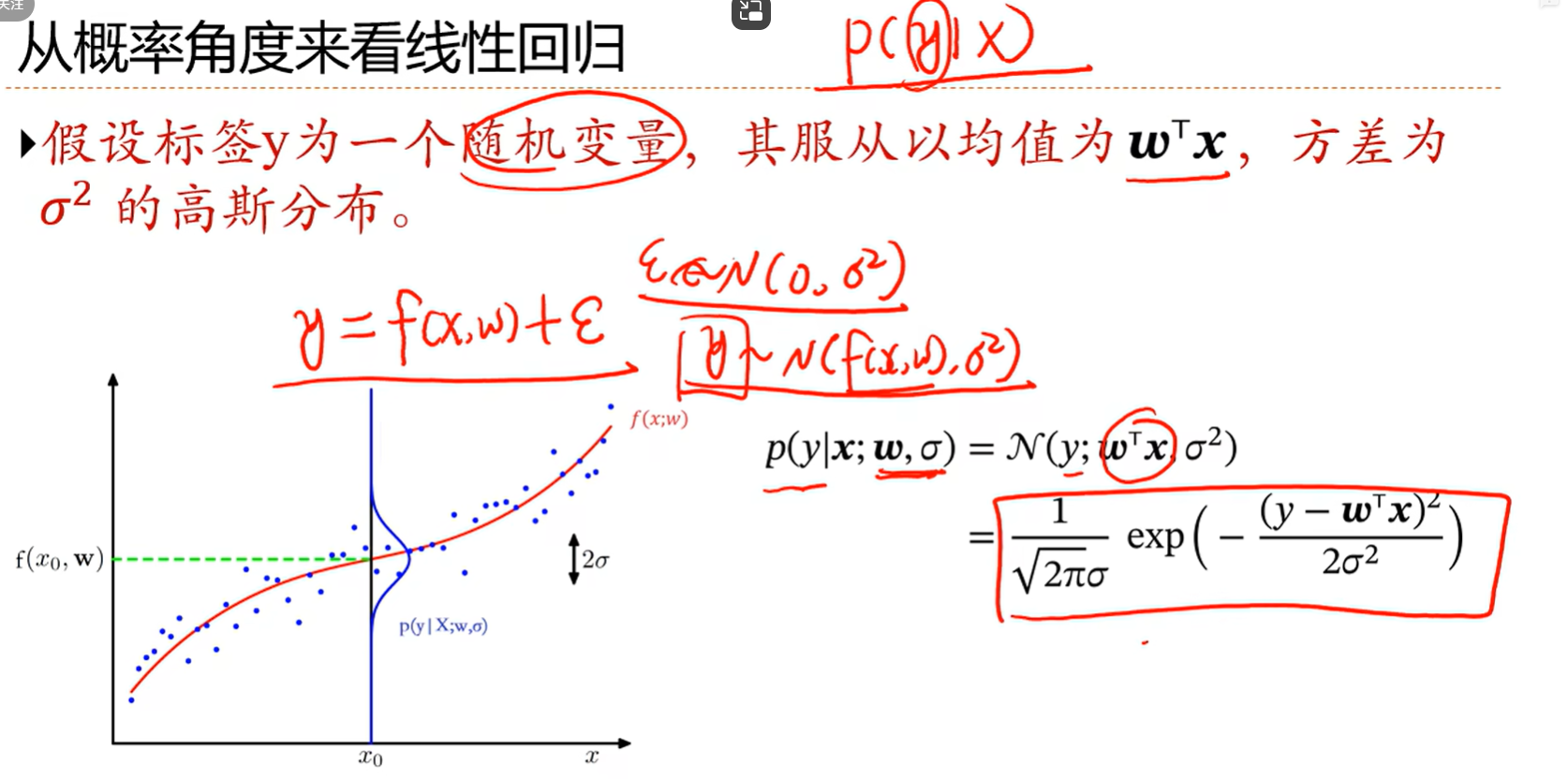

总的似然函数可以分解为每个样本的似然函数的连乘

我们发现最大似然估计求出来的w和最小二乘法的经验风险一样,说明两者是等价的


发现后面那一项其实就是前面提过的正则化项,就是把2v平方分之一定义为拉姆达


总结
2.9 模型选择问题与偏差方差分解
模型选择
- 拟合能力强的模型一般复杂度会比较高,容易过拟合
- 如果限制模型复杂度,降低拟合能力,可能会欠拟合
如何选择模型?
- 模型越复杂,训练错误越低 ×
- 不能根据训练错误最低来选择模型
- 在选择模型时,测试集不可见
一般这么选择模型:
将训练集分出一部分作为验证集:
然后在训练集上训练模型,选择在验证集上错误率最小的模型;
这可能导致数据稀疏问题,引入交叉验证 方法:
将训练集分为S组,每次使用S-1组作为训练集,剩下1组作为验证集,取验证集上平均性能最好的一组;
也可以根据信息准则:AIC、BIC去选择模型
除了这个方法之外还有一些其他的准则来帮助我们选择模型


噪声一般是由于y引起的,没办法通过模型优化来解决,一般就不管了
括号内容进一步如何分解呢?


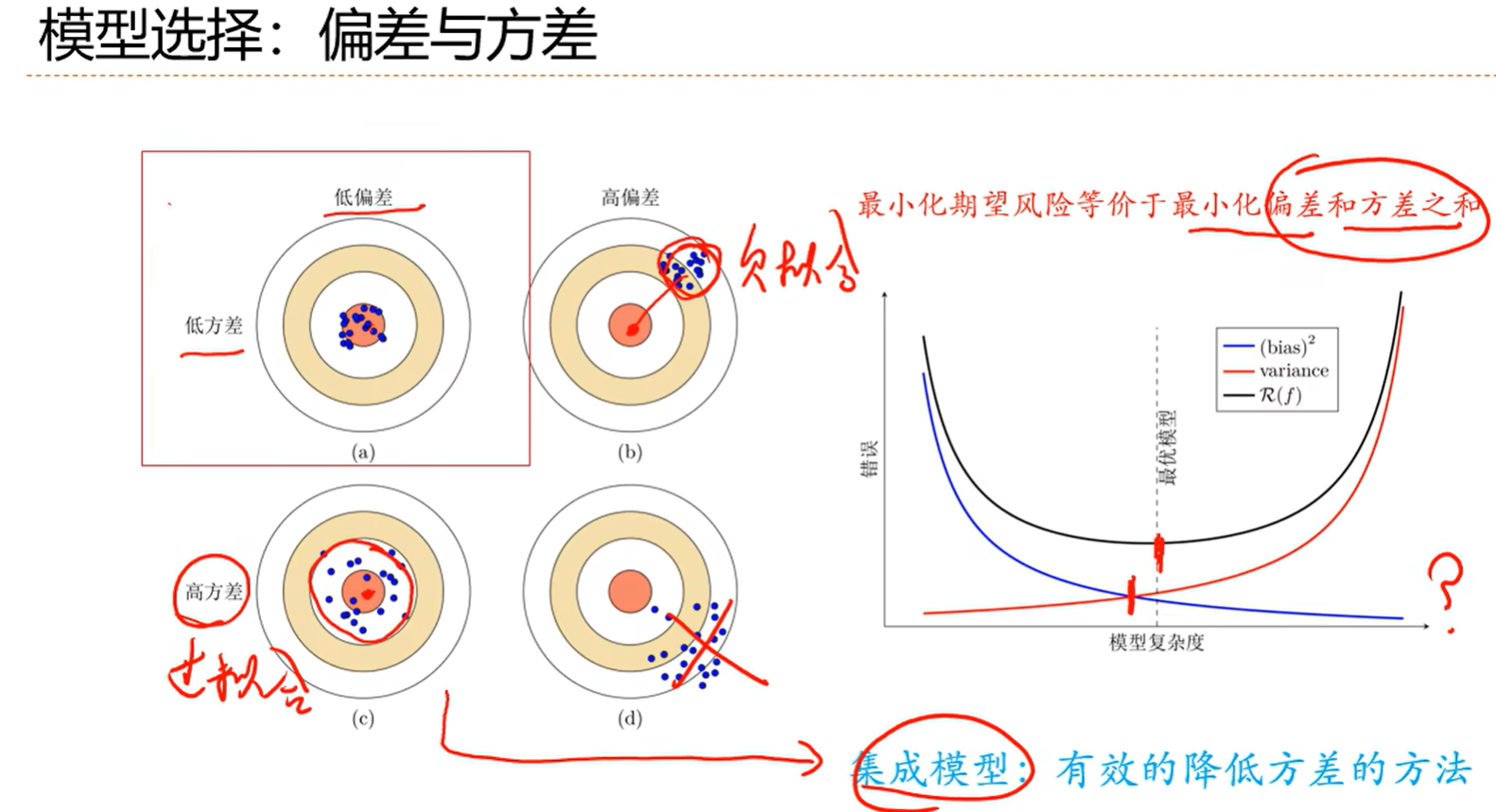
手段:集成模型,把结果搞个平均或者投票什么的
2.10 常用定理
没有免费午餐定理(No Free Lunch Theorem,NFL):对于基于迭代的最优化算法,不存在某种算法对所有问题(有限的搜索空间内)都有效。如果一个算法对某些问题有效,那么它一定在另外一些问题上比纯随机搜索算法更差。
奥卡姆剃刀原理:若无必要,勿增实体,如果能用一个简单模型解决的问题,切勿用一个复杂模型;丑小鸭定理:丑小鸭和白天鹅之间的区别和两只白天鹅之间的区别一样大
因为只有设定了特征或者标签之后才可以说区别大小
比如大小之类的
归纳偏置:很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置。
- 在最近邻分类器中,我们会假设在特征空间中,一个小的局部区域中的大部分样本都同属一类。
- 在朴素贝叶斯分类器中,我们会假设每个特征的条件概率是互相独立的。
- 归纳偏置在贝叶斯学习中也经常称为先验(Prior) 。
大数定律(Probably Approximately correct,PAC):当训练集大小D趋向于无穷大时,泛化误差趋向于0,即经验风险趋向于期望风险;

可以帮助我们确定样本的数量级别
