一、什么是决策树?
想象一下你玩"二十个问题"游戏的场景,你通过问一系列"是"或"否"的问题来猜测对方心中的物体。决策树的工作方式与此非常相似。它本质上是一个流程图结构,其中:
- 每个**内部节点(Internal Node)**代表对一个特征(属性)的测试
- 每个**分支(Branch)**代表测试的结果
- 每个**叶节点(Leaf Node)**代表最终的决策结果或类别标签
- 最顶端的节点称为根节点(Root Node)
数据从根节点开始,根据特征测试的结果,沿着树的分支向下移动,最终到达一个叶节点,这个叶节点就给出了数据的预测分类。
目标: 决策树学习的目标是创建一棵能够高效、准确地对数据进行分类或回归的树。理想情况下,我们希望每个叶节点都尽可能"纯净",即包含的样本都属于同一个类别。
二、决策树如何"学习"?------ 核心:选择最佳分裂特征
决策树的学习过程,本质上是一个递归地选择最优特征,并根据该特征对数据集进行分割,使得各个子数据集获得最大"纯度"的过程。想象一下,我们站在树的某个节点,手里有一堆数据样本,我们需要决定问哪个"问题"(即选择哪个特征进行测试)最能有效地将不同类别的样本分开,引导它们走向正确的叶节点。
目标: 我们希望每次分裂后,生成的子节点(数据子集)内部的类别尽可能单一,也就是纯度(Purity)越来越高,或者说不确定性(Uncertainty/Impurity)越来越低。
挑战: 如何量化"最有效"?我们需要一个明确的数学指标来评估不同特征分裂带来的"纯度提升"或"不确定性降低"程度。这就是分裂标准(Splitting Criteria)发挥作用的地方。下面我们详细介绍三种最常用的分裂标准:
1. 信息增益(Information Gain) - ID3 算法的选择
信息增益是基于信息论中**熵(Entropy)的概念。
-
熵(Entropy): 首先,我们需要衡量当前数据集合 D 的不确定性。熵就是这样一个度量,它表示了数据集 D 中样本类别分布的混乱程度。熵越大,表示数据集的类别越混合,不确定性越高,纯度越低。
- 计算公式:
Entropy(D) = - Σ_{k=1}^{|y|} (p_k * log2(p_k))其中,|y|是类别的总数,p_k是数据集中属于第 k 类样本的比例。如果某个子集完全属于同一类别,则其熵为 0(最纯净)。如果类别均匀分布,则熵达到最大值。
- 计算公式:
-
条件熵(Conditional Entropy): 接下来,我们考虑如果使用某个特征 A 来分裂数据集 D,分裂后的数据不确定性会变成多少。假设特征 A 有 V 个可能的取值 {a¹, a², ..., aᵛ},它会将数据集 D 分裂成 V 个子集 {D¹, D², ..., Dᵛ}。条件熵
Entropy(D|A)表示在已知特征 A 的取值后,数据集 D 的熵的期望值。- 计算公式:
Entropy(D|A) = Σ_{v=1}^{V} (|Dᵛ| / |D|) * Entropy(Dᵛ)这里,|Dᵛ|是子集 Dᵛ 中样本的数量,|D|是父节点 D 中样本的总数。它计算的是按特征 A 分裂后,所有子节点熵的加权平均值(权重是各子节点样本数占父节点样本数的比例)。
- 计算公式:
-
信息增益(Information Gain): 现在我们可以定义信息增益了。它表示的是:使用特征 A 对数据集 D 进行划分所带来的不确定性减少量(即纯度提升量)。
- 计算公式:
InfoGain(D, A) = Entropy(D) - Entropy(D|A)信息增益越大,意味着选择特征 A 进行分裂后,数据集的不确定性降低得越多,纯度提升得越明显。因此,ID3 算法在选择分裂特征时,会选择那个使得信息增益最大的特征。
- 计算公式:
-
信息增益的缺点: 一个需要注意的问题是,信息增益倾向于偏好那些具有大量不同取值的特征。例如,如果数据集中有一个"ID"列(每个样本都有唯一值),那么按 ID 分裂会得到最大的信息增益(每个子节点熵为0),但这显然是无意义的,因为它不能泛化到新数据。为了解决这个问题,C4.5 算法引入了信息增益率。
2. 信息增益率(Information Gain Ratio) - C4.5 算法的选择
信息增益率是对信息增益的一种修正,旨在减少其对多值特征的偏好。
-
分裂信息(Split Information / Intrinsic Value): 首先,我们需要计算特征 A 本身的"固有值"或"分裂信息",它衡量了使用特征 A 进行分裂的广度和均匀性。特征 A 的取值越多、越分散,其分裂信息通常越大。
- 计算公式:
SplitInfo(D, A) = - Σ_{v=1}^{V} (|Dᵛ| / |D|) * log2(|Dᵛ| / |D|)注意这个公式形式上与熵很相似,但它衡量的是特征 A 取值的分布情况,而不是类别标签的分布情况。
- 计算公式:
-
信息增益率(Gain Ratio): 信息增益率定义为信息增益与分裂信息的比值。
- 计算公式:
GainRatio(D, A) = InfoGain(D, A) / SplitInfo(D, A)通过除以SplitInfo(D, A),信息增益率惩罚了那些自身取值非常多的特征(因为它们的 SplitInfo 会很大)。这样,即使某个多值特征有较高的信息增益,但如果其分裂信息也很大,它的增益率就会被拉低,从而避免了 ID3 算法的偏好性。
- 计算公式:
-
选择标准: C4.5 算法选择信息增益率最大的特征作为分裂特征。
- 注意: 当 SplitInfo 非常小时(例如,特征只有一个取值,或几乎所有样本都在一个取值上),增益率可能会变得非常大或不稳定。因此,C4.5 算法通常采用一个启发式策略:先找出信息增益高于平均水平的特征,然后在这些候选特征中选择信息增益率最高的那个。
3. 基尼指数(Gini Impurity) - CART 算法的选择
基尼指数是另一种衡量数据纯度的指标,由 CART(Classification And Regression Trees)算法使用。
-
基尼值(Gini Value): 它衡量的是从数据集 D 中随机抽取两个样本,其类别标签不一致的概率。
- 计算公式:
Gini(D) = Σ_{k=1}^{|y|} p_k * (1 - p_k) = 1 - Σ_{k=1}^{|y|} (p_k)²基尼值越小 ,表示数据集的纯净度越高。当所有样本属于同一类时,Gini(D) = 0。当样本均匀分布在所有类别时,基尼值最大。
- 计算公式:
-
基尼指数(Gini Index): 对于一个使用特征 A 进行分裂的操作,基尼指数衡量的是分裂后子节点基尼值的加权平均。CART 通常进行二元分裂(即使特征有多个取值,也会找到一个最优的二分点或二分组)。假设特征 A 将数据集 D 分成 D₁ 和 D₂ 两部分:
- 计算公式:
Gini_split(D, A) = (|D₁| / |D|) * Gini(D₁) + (|D₂| / |D|) * Gini(D₂)
- 计算公式:
-
选择标准: CART 算法在选择分裂特征(以及分裂点/分组)时,会选择那个使得分裂后基尼指数
Gini_split最小的特征和分裂方式。 这同样意味着它在追求分裂后子节点的最高纯度。 -
与熵的比较: 基尼指数的计算通常比熵略快一些,因为它不涉及对数运算。在实践中,两者产生的结果往往非常相似。
|------|---------------|-------------------|----------------------|
| 算法 | 分裂标准 | 核心思想 | 特点/倾向性 |
| ID3 | 信息增益 (Gain) | 最大化熵的减少量 | 倾向于选择取值多的特征 |
| C4.5 | 信息增益率 (Ratio) | 最大化 (信息增益 / 分裂信息) | 对信息增益进行修正,减少对多值特征的偏好 |
| CART | 基尼指数 (Gini) | 最小化分裂后的不纯度(基尼指数) | 计算相对简单,通常用于二叉树构建 |
三、决策树的优缺点
优点:
- 易于理解和解释: 树状结构非常直观,可以轻松可视化。
- 数据预处理要求低: 不需要像某些模型那样进行严格的数据归一化。可以同时处理数值型和类别型数据。
- 非参数模型: 对数据的分布没有太多假设。
缺点:
- 容易过拟合(Overfitting): 决策树可能创建出过于复杂的树,完美拟合训练数据,但在新数据上表现不佳。需要进行剪枝(Pruning)等操作来缓解。
- 对数据微小变化敏感: 数据微小的变动可能导致生成完全不同的树。
- 可能产生偏见: 对于样本数量差异很大的类别,决策树可能偏向于样本多的类别。
四、实战案例:贷款申请分类
我们的目标是根据申请人的年龄段、是否有工作、是否有自己的房子、信贷情况 这四个特征,来预测银行是否应该批准贷款(类别)。
- 数据准备:(数据集如下)
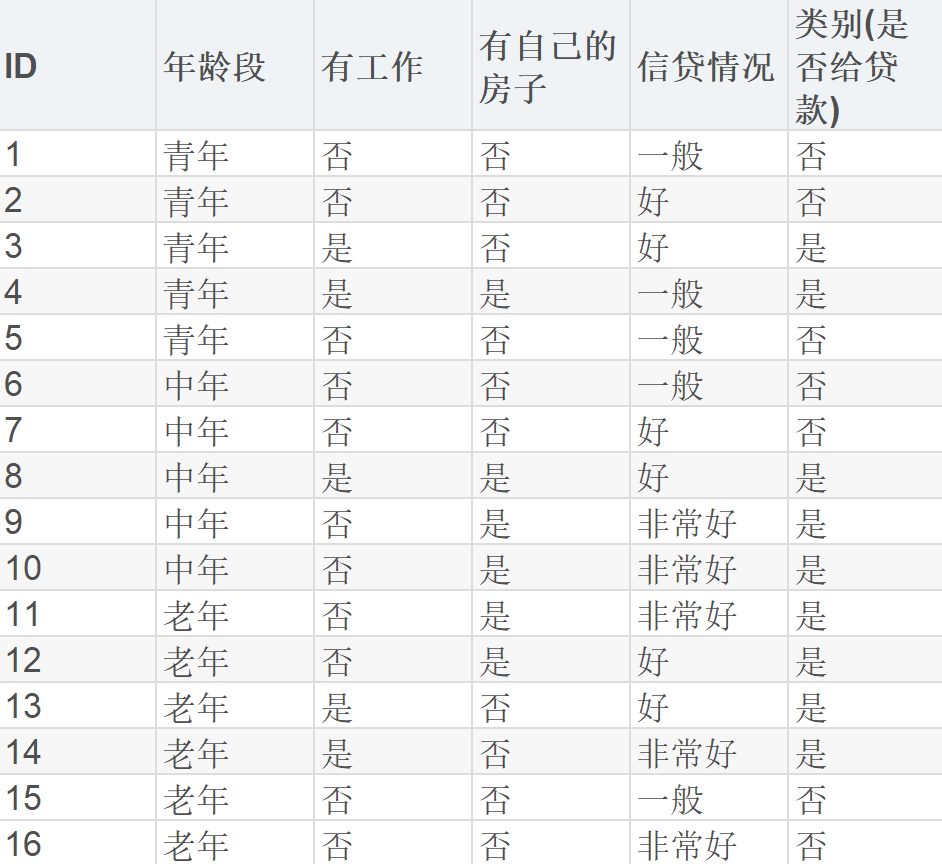
我们使用了以下编码来处理数据:
- 年龄段: 0=青年, 1=中年, 2=老年
- 有工作: 0=否, 1=是
- 有自己的房子: 0=否, 1=是
- 信贷情况: 0=一般, 1=好, 2=非常好
- 类别 (是否给贷款): 0=否, 1=是
- 模型构建与实现 (Python & Scikit-learn):
我们使用了 Python 的 scikit-learn 库来构建模型。
python
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# --- 1. 数据准备 ---
# 训练数据 (已根据规则编码)
X_train_list = [
[0, 0, 0, 0], [0, 0, 0, 1], [0, 1, 0, 1], [0, 1, 1, 0], [0, 0, 1, 0],
[1, 0, 0, 0], [1, 0, 0, 1], [1, 1, 1, 1], [1, 0, 1, 2], [1, 0, 1, 2],
[2, 0, 1, 2], [2, 0, 1, 1], [2, 1, 0, 1], [2, 1, 0, 2], [2, 0, 0, 0],
[2, 0, 0, 2]
]
y_train_list = [0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0]
# 测试数据 (已根据规则编码)
X_test_list = [
[0, 0, 0, 1], [0, 1, 0, 1], [1, 0, 1, 2], [1, 0, 0, 1],
[2, 1, 0, 2], [2, 0, 0, 0], [2, 0, 0, 2]
]
y_test_list = [0, 1, 1, 0, 1, 0, 0]
# 转换为 NumPy 数组
X_train = np.array(X_train_list)
y_train = np.array(y_train_list)
X_test = np.array(X_test_list)
y_test = np.array(y_test_list)
# --- 2. 使用基尼指数 (Gini Impurity) 构建决策树 ---
# 初始化决策树分类器,criterion='gini' 指定使用基尼指数
gini_tree = DecisionTreeClassifier(criterion='gini', random_state=42)
gini_tree.fit(X_train, y_train) # 训练模型
gini_predictions = gini_tree.predict(X_test) # 预测测试集
gini_accuracy = accuracy_score(y_test, gini_predictions) # 计算精度
# --- 3. 使用信息增益 (Entropy) 构建决策树 ---
# 初始化决策树分类器,criterion='entropy' 指定使用信息增益
entropy_tree = DecisionTreeClassifier(criterion='entropy', random_state=42)
entropy_tree.fit(X_train, y_train) # 训练模型
entropy_predictions = entropy_tree.predict(X_test) # 预测测试集
entropy_accuracy = accuracy_score(y_test, entropy_predictions) # 计算精度
# --- 4. 输出结果 ---
print("--- 测试集预测结果与精度 ---")
print(f"真实标签: {y_test}")
print(f"基尼指数模型预测: {gini_predictions}, 精度: {gini_accuracy:.4f}")
print(f"信息增益模型预测: {entropy_predictions}, 精度: {entropy_accuracy:.4f}")3. 结果分析:
代码运行输出结果为:
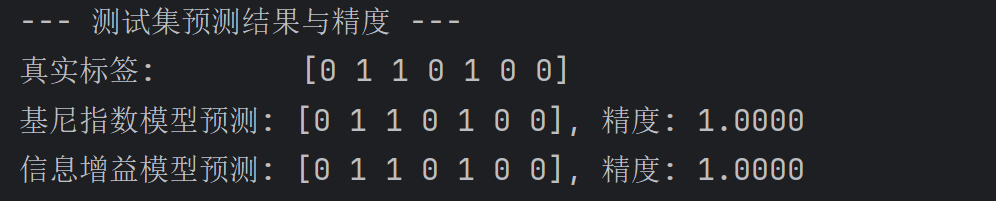
可以看到,在这个特定的案例中,无论是使用基尼指数还是信息增益作为分裂标准,构建出的决策树在我们的测试集上都达到了 100% 的预测精度!这意味着模型完美地预测了测试集中每一个申请人的贷款审批结果。
重要提示: 在实际项目中,尤其是在处理更大数据集时,达到100%的精度是比较少见的。这可能是因为我们使用的数据集非常小,并且特征可能恰好能够完美地将训练数据和测试数据分开。对于更复杂、更大型的数据集,通常需要更深入的模型评估(如交叉验证)和调优(如剪枝)来防止过拟合,并获得在未知数据上更可靠的性能。
五、总结
决策树是一种强大且易于理解的分类和回归工具。它通过模拟人类的决策过程,根据数据的特征进行递归划分。选择合适的分裂标准(如基尼指数或信息增益)是构建高效决策树的关键。虽然它有容易过拟合等缺点,但通过适当的技术(如剪枝、集成方法)可以有效缓解。
通过我们的小型贷款审批案例,我们看到了如何应用 scikit-learn 库快速构建和评估决策树模型。尽管结果很理想,但务必记住在真实场景中数据和模型的复杂性。