一、数学原理
1. 多头注意力机制
多头注意力机制允许模型在不同的表示子空间中关注输入序列的不同部分。它通过并行计算多个注意力头来实现这一点,每个头学习序列的不同部分。
2. 注意力分数计算
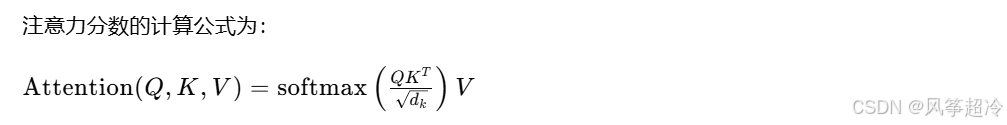

3. 掩码机制
掩码机制用于防止模型访问某些位置的信息。例如,在解码器中,模型不应该看到未来的信息。掩码通过将掩码位置的注意力分数设置为一个非常小的值(如-1e9)来实现,这样在应用Softmax时,这些位置的权重接近于0。
4. 输出计算

二、代码实现
python
import math
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.dropout = nn.Dropout(dropout)
self.q_proj = nn.Linear(d_model, d_model)
self.k_proj = nn.Linear(d_model, d_model)
self.v_proj = nn.Linear(d_model, d_model)
self.o_proj = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask):
batch_size, seq_len, _ = q.shape # (batch, seq_len, d_model)
Q = self.q_proj(q) # (batch, seq_len, d_model)
K = self.q_proj(k) # (batch, seq_len, d_model)
V = self.q_proj(v) # (batch, seq_len, d_model)
# shape: (batch, num_heads, seq_len, d_k)
Q = Q.view(batch_size, Q.shape[1], self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, K.shape[1], self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, V.shape[1], self.num_heads, self.d_k).transpose(1, 2)
# shape: (batch, num_heads, seq_len, seq_len)
atten_scores = (Q @ K.transpose(-1, -2)) / math.sqrt(self.d_k)
if mask is not None:
atten_scores.masked_fill(mask==0, -1e9)
# shape: (batch, num_heads, seq_len, seq_len)
atten_scores = torch.softmax(atten_scores, dim=-1)
# shape: (batch, num_heads, seq_len, d_k)
atten_out = atten_scores @ V
# shape: (batch, seq_len, d_model)
atten_out = atten_out.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
output = self.o_proj(atten_out)
return self.dropout(output)
if __name__ == "__main__":
vocab_size = 10000
d_model = 512
seq_len = 20
dropout = 0.1
num_heads = 8
attn_block = MultiHeadAttention(d_model, num_heads, dropout)
batch_size = 16
x = torch.randn(size=(batch_size, seq_len, d_model))
output = attn_block(x, x, x, None)
pass三、关键代码讲解
self.o_proj 矩阵在代码中的作用?
output = self.o_proj(atten_out) 这一步的数学公式涉及到线性变换,具体来说,是将经过多头注意力机制处理后的输出 atten_out 通过一个线性层 self.o_proj 进行变换。以下是详细的数学公式:

线性变换公式

atten_scores.masked_fill(mask==0, -1e9) 代码的作用?
在多头注意力机制中,掩码用于修改注意力分数矩阵,使得某些位置的注意力权重在应用Softmax函数之前被设置为一个非常小的值(通常是负无穷大或一个非常大的负数)。这样,在Softmax函数的作用下,这些位置的权重将接近于0,从而在计算加权和时被忽略。
代码解释
if mask is not None:
atten_scores.masked_fill(mask==0, -1e9)-
mask是一个布尔型张量或整数型张量,用于指示哪些位置应该被忽略。在自注意力机制中,掩码通常是一个上三角形矩阵,其中序列的未来位置被标记为False(或0)。 -
atten_scores是计算得到的注意力分数矩阵,其形状通常为(batch_size, num_heads, seq_len, seq_len)。 -
mask==0生成一个与mask形状相同的布尔张量,其中掩码为0的位置被标记为True。 -
atten_scores.masked_fill(mask==0, -1e9)使用masked_fill方法将atten_scores中对应于mask中为0的位置的值替换为-1e9。这是一个非常大的负数,确保在应用Softmax时这些位置的权重接近于0。
示例
假设 mask 是一个形状为 (1, 1, 5, 5) 的张量,表示一个序列长度为5的单头注意力掩码:
mask = torch.tensor([[[[True, False, False, False, False],
[True, True, False, False, False],
[True, True, True, False, False],
[True, True, True, True, False],
[True, True, True, True, True]]]])在这个掩码中,只有对角线及其左上方的元素是 True,表示这些位置可以被关注。所有其他位置(即对角线右下方)都是 False,表示这些位置应该被忽略。
应用掩码后,atten_scores 中对应于 False 的位置将被设置为 -1e9,从而在计算Softmax时这些位置的权重将接近于0。