🧠 向所有学习者致敬!
"学习不是装满一桶水,而是点燃一把火。" ------ 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
我们将逐步编写一个非常简单的类似 GPT-4o 的多模态架构,它可以处理文本、图像、视频和音频,并且能够根据文本提示生成图像。帮助你详细理解逐步实现的过程。
项目代码
以下是这个简单多模态模型将具备的功能:
- 像语言模型(LLM)一样用文本聊天(使用 Transformer)
- 用图像、视频和音频聊天(使用 Transformer + ResNet)
- 根据文本提示生成图像(使用 Transformer + ResNet + 特征方法)
简单的 GPT-4o 架构
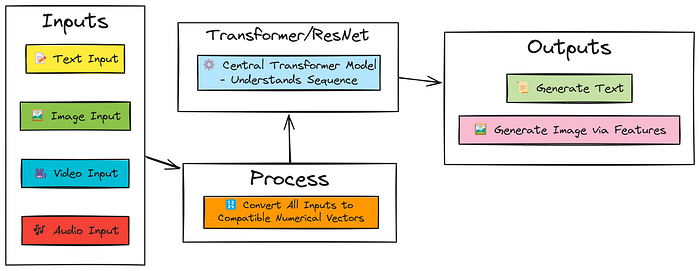
Tiny GPT-4o 架构
下文我们将实现以下内容:
- 从头开始编写了自己的 BPE 分词器。这让我们能够将文本分解成模型可以处理的小片段。
- 接着,我们构建了一个基本的文本模型(类似 GPT 的模型),使用 "爱丽丝梦游仙境" 的文本教它如何根据前面的单词预测下一个单词,这样它就能自己写出一些新的文本了。
- 然后,我们让模型变得多才多艺!我们把之前训练好的文本模型和 ResNet(一个图像识别模型)结合起来,让模型能够 "看到" 我们的简单彩色形状图像,并回答关于它们的问题,比如告诉我们要描述的颜色。
- 我们还规划了如何处理视频和音频。方法类似:把视频帧或音频波形转换成数字,给它们加上特殊的
<VID>或<AUD>标记,然后把它们混入输入序列。 - 最后,我们把方向反过来,尝试从文本提示生成图像 。我们没有让模型直接画出像素(那太难了!),而是训练它根据文本(比如 "a blue square")预测图像的 特征向量。然后,我们只要找出我们已知图像(红色正方形、蓝色正方形、绿色圆形)中哪个的特征向量和模型预测的最接近,就把它显示出来!
准备工作
我们将使用一些库,所以先导入它们。
python
# PyTorch 核心库,用于构建模型、张量和训练
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 图像处理和计算机视觉
import torchvision
import torchvision.transforms as transforms
from PIL import Image, ImageDraw # 用于创建/处理虚拟图像
# 标准 Python 库
import re # 用于正则表达式(在 BPE 单词拆分中使用)
import collections # 用于数据结构(如 Counter,在 BPE 频率计数中使用)
import math # 用于数学函数(在位置编码中使用)
import os # 用于与操作系统交互(文件路径、目录)
# 数值 Python(概念上用于音频波形生成)
import numpy as np第一步是创建一个分词器,让我们开始编写代码吧。
BPE 分词是什么
在创建多模态语言模型或任何 NLP 任务中,分词是第一步,即将原始文本分解为更小的单元,称为标记(tokens)。
这些标记是机器学习模型处理的基本构建块(例如,单词、标点符号)。
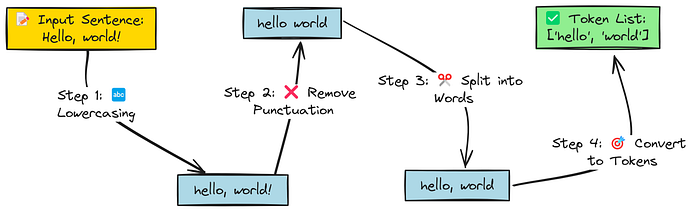
最简单的分词过程
最简单的分词方式是将文本转换为小写,移除标点符号,然后将文本拆分为单词列表。
然而,这种方法有一个缺点。如果将每个独特的单词都视为一个标记,词汇表的大小可能会变得过大,尤其是在包含许多单词变体的语料库中(例如,"run"、"runs"、"running"、"ran"、"runner")。这会显著增加内存和计算需求。
与简单的基于单词的分词不同,BPE(Byte Pair Encoding,字节对编码) 是一种子词(subword)分词技术,它有助于控制词汇表大小,同时有效地处理罕见单词。
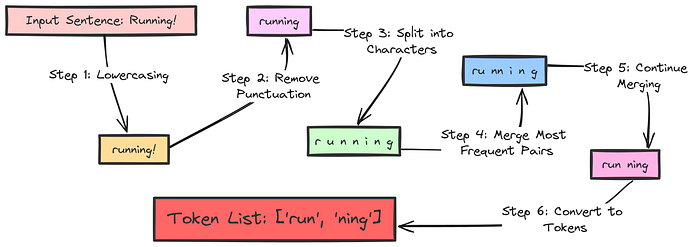
BPE 解释
在 BPE 中,最初将输入句子拆分为单个字符。然后,将频繁相邻的字符对合并为新的子词。这个过程会一直持续,直到达到所需的词汇表大小。
因此,常见的子词部分会被重复使用,模型可以通过将从未遇到过的单词拆分为更小的、已知的子词单元来处理它们。
GPT-4 使用 BPE 作为其分词组件。现在我们已经对 BPE 进行了高层次的概述,让我们开始编写代码。
编写 BPE 分词器代码
我们将使用刘易斯·卡罗尔的《爱丽丝梦游仙境》中的一个小片段作为训练 BPE 分词器的数据。
使用更大、更多样化的语料库可以得到更通用的分词器,但这个较小的示例让我们更容易追踪整个过程。
python
# 定义用于训练 BPE 分词器的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""接下来,我们需要将整个语料库转换为小写,以确保在频率计数和合并过程中,相同单词的不同大小写形式(例如,"Alice" 和 "alice")被视为同一个单元。
python
# 将原始语料库转换为小写
corpus_lower = corpus_raw.lower()现在我们已经将语料库转换为小写。
接下来,我们需要将文本拆分为其基本组成部分。虽然 BPE 是基于子词的,但它通常从单词级别开始(包括标点符号)。
python
# 定义用于拆分单词和标点的正则表达式
split_pattern = r'\w+|[^\s\w]+'
# 使用正则表达式将小写的语料库拆分为初始的标记列表
initial_word_list = re.findall(split_pattern, corpus_lower)
print(f"语料库被拆分为 {len(initial_word_list)} 个初始单词/标记。")
# 显示前三个标记
print(f"前三个初始标记:{initial_word_list[:3]}")
#### 输出结果 ####
语料库被拆分为 127 个初始单词/标记。
前三个初始标记:['alice', 'was', 'beginning']我们的语料库被拆分为 127 个标记,你可以看到语料库的前三个标记。让我们了解一下代码中发生了什么。
我们使用正则表达式 r'\w+|[^\s\w]+' 通过 re.findall:
\w+:匹配一个或多个字母数字字符(字母、数字和下划线)。这可以捕获标准单词。|:作为 OR 运算符。[^\s\w]+:匹配一个或多个既不是空白字符(\s)也不是单词字符(\w)的字符。这可以捕获标点符号,如逗号、句号、冒号、引号、括号等,将它们作为单独的标记。
结果是一个字符串列表,其中每个字符串是一个单词或标点符号。
BPE 的核心原则是合并 最频繁 的对。因此,我们需要知道每个独特初始单词/标记在语料库中出现的频率。collections.Counter 可以高效地创建一个类似字典的对象,将每个独特项(单词/标记)映射到其计数。
python
# 使用 collections.Counter 统计 initial_word_list 中各项的频率
word_frequencies = collections.Counter(initial_word_list)
# 显示频率最高的 3 个标记及其计数
print("频率最高的 3 个标记:")
for token, count in word_frequencies.most_common(3):
print(f" '{token}': {count}")
#### 输出结果 ####
频率最高的 3 个标记:
the: 7
of: 5
her: 5频率最高的标记是 "the",在我们的小语料库中出现了 7 次。
BPE 训练基于符号序列。我们需要将独特单词/标记列表转换为这种格式。对于每个独特单词/标记:
-
将其拆分为单独字符的列表。
-
在该列表末尾追加一个特殊的单词结束符号(我们使用
</w>)。这个</w>标记至关重要:-
它防止 BPE 在不同单词之间合并字符。例如,"apples" 末尾的 "s" 不应与 "and" 开头的 "a" 合并。
-
它还允许算法将常见的单词结尾作为独立的子词单元进行学习(例如,"ing"、"ed"、"s")。
-
我们将这种映射(原始单词 -> 字符列表 + 单词结束符号)存储在一个字典中。
python
# 定义特殊的单词结束符号 "</w>"
end_of_word_symbol = '</w>'
# 创建一个字典,用于存储语料库的初始表示形式
# 键:原始独特单词/标记,值:字符列表 + 单词结束符号
initial_corpus_representation = {}
# 遍历频率计数器识别的独特单词/标记
for word in word_frequencies:
# 将单词字符串拆分为字符列表
char_list = list(word)
# 在列表末尾追加单词结束符号
char_list.append(end_of_word_symbol)
# 将该列表存储到字典中,原始单词作为键
initial_corpus_representation[word] = char_list那么,让我们打印出 "beginning" 和 "." 的表示形式。
python
# 显示一个样本单词的表示形式
example_word = 'beginning'
if example_word in initial_corpus_representation:
print(f"'{example_word}' 的表示形式:{initial_corpus_representation[example_word]}")
example_punct = '.'
if example_punct in initial_corpus_representation:
print(f"'{example_punct}' 的表示形式:{initial_corpus_representation[example_punct]}")
#### 输出结果 ####
创建了初始语料库表示形式,包含 86 个独特单词/标记。
'beginning' 的表示形式:['b', 'e', 'g', 'i', 'n', 'n', 'i', 'n', 'g', '</w>']
'.' 的表示形式:['.', '</w>']BPE 算法从语料库的初始表示形式中所有单独符号开始构建词汇表。
这包括原始文本中的所有独特字符 加上 我们添加的特殊 </w> 符号。使用 Python set 自动处理唯一性 ------ 多次添加现有字符不会产生任何效果。
python
# 初始化一个空集合,用于存储独特的初始符号(词汇表)
initial_vocabulary = set()
# 遍历语料库的初始表示形式中的字符列表
for word in initial_corpus_representation:
# 获取当前单词的符号列表
symbols_list = initial_corpus_representation[word]
# 将该符号列表中的符号添加到词汇表集合中
# `update` 方法会将可迭代对象(如列表)中的所有元素添加到集合中
initial_vocabulary.update(symbols_list)
# 虽然 update 应该已经添加了 '</w>',但为了确保,我们可以显式添加它
# initial_vocabulary.add(end_of_word_symbol)
print(f"初始词汇表创建完成,包含 {len(initial_vocabulary)} 个独特符号。")
# 可选:显示初始词汇表符号的排序列表
print(f"初始词汇表符号:{sorted(list(initial_vocabulary))}")
#### 输出结果 ####
初始词汇表创建完成,包含 31 个独特符号。
初始词汇表符号:["'", '(', ')', ',', '-', '.', ':', '</w>', ...]所以,我们的小语料库总共有 31 个独特符号,我打印了一些出来给你看看。
现在,进入 BPE 的核心学习阶段。我们将迭代地找到当前语料库表示形式中 最频繁的相邻符号对,并将它们合并为一个新的单一符号(子词)。
这个过程构建了子词词汇表和有序的合并规则列表。
在开始循环之前,我们需要:
num_merges:定义合并操作的次数,控制最终词汇表的大小。较大的值可以捕获更复杂的子词。learned_merges:一个字典,用于存储合并规则,键为符号对元组,值为合并优先级。current_corpus_split:保存在合并过程中修改的语料库状态的副本,初始化为原始语料库表示形式的副本。current_vocab:保存增长中的词汇表,初始化为原始词汇表的副本。
python
# 定义期望的合并操作次数
# 这决定了要在初始字符词汇表中添加多少个新的子词标记
num_merges = 75 # 在这个例子中,我们使用 75 次合并
# 初始化一个空字典,用于存储学习到的合并规则
# 格式:{ (symbol1, symbol2): 合并优先级索引 }
learned_merges = {}
# 创建语料库表示形式的工作副本,以便在训练过程中进行修改
current_corpus_split = initial_corpus_representation.copy()
# 创建词汇表的工作副本,以便在训练过程中进行修改
current_vocab = initial_vocabulary.copy()
print(f"训练状态初始化完成。目标合并次数:{num_merges}")
print(f"初始词汇表大小:{len(current_vocab)}")
#### 输出结果 ####
训练状态初始化完成。目标合并次数:75
初始词汇表大小:31现在,我们将迭代 num_merges 次。在循环内部,我们执行 BPE 的核心步骤:统计对、找到最佳对、存储规则、创建新符号、更新语料库表示形式和更新词汇表。
python
# 开始主循环,迭代指定的合并次数
print(f"\n--- 开始 BPE 训练循环 ({num_merges} 次迭代) ---")
for i in range(num_merges):
print(f"\n第 {i + 1}/{num_merges} 次迭代")
# 统计符号对的频率
pair_counts = collections.Counter()
for word, freq in word_frequencies.items():
symbols = current_corpus_split[word]
for j in range(len(symbols) - 1):
pair = (symbols[j], symbols[j+1])
pair_counts[pair] += freq
if not pair_counts:
print("没有更多可合并的对了。提前停止。")
break
# 找到最佳对
best_pair = max(pair_counts, key=pair_counts.get)
print(f"找到最佳对:{best_pair},频率为 {pair_counts[best_pair]}")
# 存储合并规则
learned_merges[best_pair] = i
# 创建新符号
new_symbol = "".join(best_pair)
# 更新语料库表示形式
next_corpus_split = {}
for word in current_corpus_split:
old_symbols = current_corpus_split[word]
new_symbols = []
k = 0
while k < len(old_symbols):
if k < len(old_symbols) - 1 and (old_symbols[k], old_symbols[k+1]) == best_pair:
new_symbols.append(new_symbol)
k += 2
else:
new_symbols.append(old_symbols[k])
k += 1
next_corpus_split[word] = new_symbols
current_corpus_split = next_corpus_split
# 更新词汇表
current_vocab.add(new_symbol)
# 最终输出
print(f"\n--- BPE 训练循环完成,共进行了 {i + 1} 次迭代 ---")
final_vocabulary = current_vocab
final_learned_merges = learned_merges
final_corpus_representation = current_corpus_split当我们开始 BPE 的训练循环时,它将运行 75 次迭代,因为我们设置了合并次数为 75。让我们看看其中一次迭代的输出是什么样的:
bash
#### 输出结果(单次迭代) ####
--- 开始 BPE 训练循环 (75 次迭代) ---
第 1/75 次迭代
第 2.3 步:计算符号对的统计信息...
计算了 156 个独特对的频率。
第 2.4 步:检查是否存在对...
找到了对,继续训练。
第 2.5 步:找到最频繁的对...
找到最佳对:('e', '</w>'),频率为 21
第 2.6 步:存储合并规则(优先级:0)...
已存储:('e', '</w>') -> 优先级 0
第 2.7 步:从最佳对创建新符号...
创建了新符号:'e</w>'
第 2.8 步:更新语料库表示形式...
已更新所有单词的语料库表示形式。
第 2.9 步:更新词汇表...
将 'e</w>' 添加到词汇表中。当前大小:32在我们的训练中,每次迭代都涉及相同的步骤,例如计算对的频率、找到最佳对等,就像我们之前看到的那些步骤一样。
让我们看看我们的语料库的词汇表大小。
python
print(f"最终词汇表大小:{len(final_vocabulary)} 个标记")
#### 输出结果 ####
最终词汇表大小:106 个标记现在我们的 BPE 训练已经完成啦!很有用的是,看看训练语料库中的特定单词在经过所有合并操作后的表示形式。
python
# 列出一些我们希望看到有趣分词的单词
example_words_to_inspect = ['beginning', 'conversations', 'sister', 'pictures', 'reading', 'alice']
for word in example_words_to_inspect:
if word in final_corpus_representation:
print(f" '{word}': {final_corpus_representation[word]}")
else:
print(f" '{word}': 未在原始语料库中找到(如果从语料库中选择,不应发生这种情况)。")
好的,我将继续翻译剩余的内容,确保完整性和准确性。以下是翻译后的剩余部分:
---
#### 输出结果 ####
最终单词示例的表示形式:
'beginning': ['b', 'e', 'g', 'in', 'n', 'ing</w>']
'conversations': ['conversati', 'on', 's</w>']
'sister': ['sister</w>']
'pictures': ['pictures</w>']
'reading': ['re', 'ad', 'ing</w>']
'alice': ['alice</w>']
这展示了根据学习到的 BPE 规则,已知单词的最终标记序列。
但我们还需要一个样本句子或文本,该文本在训练期间 BPE 模型可能没有见过,以展示其对新输入的分词能力,可能包含原始语料库中未出现的单词或变体。
```python
# 定义一个新的文本字符串,用于使用学习到的 BPE 规则进行分词
# 这个文本包含训练中见过的单词('alice', 'pictures')
# 以及可能未见过的单词或变体('tiresome', 'thought')
new_text_to_tokenize = "Alice thought reading was tiresome without pictures."当我们对未见过的文本执行相同的训练循环时,我们得到了以下分词数据:
python
print(f"原始输入文本:'{new_text_to_tokenize}'")
print(f"分词输出({len(tokenized_output)} 个标记):{tokenized_output}")
#### 输出结果 ####
原始输入文本:'Alice thought reading was tiresome without pictures.'
分词输出(21 个标记):['alice</w>', 'thou', 'g', 'h',
't</w>', 're', 'ad', 'ing</w>',
'was</w>', 'ti', 're', 's', 'o', 'm',
'e</w>', 'wi', 'thou', 't</w>',
'pictures</w>', '.', '</w>']啊,终于,我们完成了 BPE 分词器的整个过程。现在,我们的文本已经表示为子词标记的序列。
但仅仅有标记还不够,我们需要一个能够理解这些序列中的模式和关系的模型,以便生成有意义的文本。
接下来,我们需要构建一个文本生成的语言模型(LLM),由于 GPT-4 基于 Transformer 架构,我们将采用相同的方法。
这种架构在论文 "Attention Is All You Need" 中被首次提出。有许多 Transformer 模型的实现,我们将一边编写代码,一边理解理论,以便掌握 Transformer 模型的核心逻辑。
仅解码器的 Transformer
我们的目标是构建一个语言模型,能够根据前面的标记预测序列中的下一个标记。通过反复预测并追加标记,模型可以生成新的文本。我们将专注于一个 仅解码器的 Transformer,类似于 GPT 这类模型。
为了简化 Transformer 架构本身的演示,我们将切换回 字符级分词。
这意味着原始语料库中的每个独特字符都将是一个单独的标记。
虽然 BPE 通常更强大,但字符级分词可以保持词汇表较小,并且让我们专注于模型的机制。
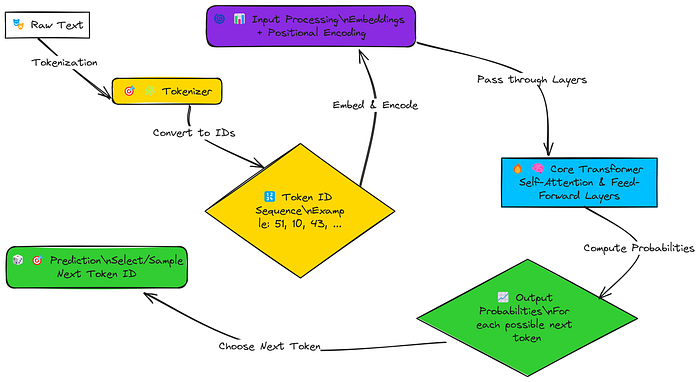
简化版 LLM 创建流程
因此,我们的 Transformer 模型的工作流程如下:
- 文本转标记:将输入文本分解为更小的部分(标记)。
- 标记转数字:将每个标记转换为唯一的数字(ID)。
- 添加意义和位置:将这些数字转换为有意义的向量(嵌入),并添加位置信息,以便模型知道单词的顺序。
- 核心处理:Transformer 的主要层使用 "自注意力" 分析所有单词之间的关系。
- 猜测下一个单词:计算词汇表中每个单词成为下一个单词的概率。
- 选择最佳猜测:根据这些概率选择最有可能的单词(或采样一个)作为输出。
我们将使用之前的 "爱丽丝梦游仙境" 语料库。
python
# 定义用于训练的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""现在,让我们创建我们的字符词汇表及其映射。
python
# 找出原始语料库中的所有独特字符
chars = sorted(list(set(corpus_raw)))
vocab_size = len(chars)
# 创建字符到整数的映射(编码)
char_to_int = { ch:i for i,ch in enumerate(chars) }
# 创建整数到字符的映射(解码)
int_to_char = { i:ch for i,ch in enumerate(chars) }
print(f"创建了字符词汇表,大小为:{vocab_size}")
print(f"词汇表:{''.join(chars)}")
#### 输出结果 ####
创建了字符词汇表,大小为:36
词汇表:
'(),-.:?ARSWabcdefghiklmnoprstuvwy有了这些映射,我们将整个文本语料库转换为一个数字序列(标记 ID)。
python
# 将整个语料库编码为一个整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]
# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)
print(f"将语料库编码为张量,形状为:{full_data_sequence.shape}")
#### 输出结果 ####
将语料库编码为张量,形状为:torch.Size([593])输出告诉我们,我们的模型只需要学习大约 36 个独特的字符(包括空格、标点符号等)。
这就是我们的 vocab_size,第二行显示了确切包含哪些字符。
有了这些映射,我们将整个文本语料库转换为一个数字序列(标记 ID)。
python
# 将整个语料库编码为一个整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]
# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)
print(f"将语料库编码为张量,形状为:{full_data_sequence.shape}")
### 输出结果 ####
将语料库编码为张量,形状为:torch.Size([593])这确认了我们的 593 个字符的文本现在被表示为一个单一的 PyTorch 张量(一个长度为 593 的数字列表),准备好供模型使用。
在构建模型之前,我们需要设置一些配置值,即超参数。这些控制 Transformer 的大小和行为。
python
# 定义模型超参数(使用计算出的 vocab_size)
# vocab_size = vocab_size # 已经定义过了
d_model = 64 # 嵌入维度(每个标记的向量大小)
n_heads = 4 # 注意力头的数量(并行注意力计算)
n_layers = 3 # 堆叠在一起的 Transformer 块的数量
d_ff = d_model * 4 # 前馈网络中的隐藏维度
block_size = 32 # 模型一次看到的最大序列长度
# dropout_rate = 0.1 # 为了简化,省略了 dropout
# 定义训练超参数
learning_rate = 3e-4
batch_size = 16 # 训练期间并行处理的序列数量
epochs = 5000 # 训练迭代次数
eval_interval = 500 # 打印损失的频率
# 设备配置
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 确保 d_model 能被 n_heads 整除
assert d_model % n_heads == 0, "d_model 必须能被 n_heads 整除"
d_k = d_model // n_heads # 每个头的键/查询/值的维度
print(f"超参数已定义:")
print(f" vocab_size: {vocab_size}")
print(f" d_model: {d_model}")
print(f" n_heads: {n_heads}")
print(f" d_k (每个头的维度): {d_k}")
print(f" n_layers: {n_layers}")
print(f" d_ff: {d_ff}")
print(f" block_size: {block_size}")
print(f" learning_rate: {learning_rate}")
print(f" batch_size: {batch_size}")
print(f" epochs: {epochs}")
print(f" 使用的设备:{device}")虽然 GPT-4 是一个闭源模型,我们无法获得其确切的参数值,但我们可以定义基本的参数值,以便轻松地进行复现。
bash
#### 输出结果 ####
超参数已定义:
vocab_size: 36
d_model: 64
n_heads: 4
d_k (每个头的维度): 16
n_layers: 3
d_ff: 256
block_size: 32
learning_rate: 0.0003
batch_size: 16
epochs: 5000
使用的设备:cuda我们看到了 vocab_size 为 36,嵌入维度 (d_model) 为 64,3 层,4 个注意力头,等等。它还确认了我们正在使用的设备(cuda 或 cpu),这会影响训练速度。
接下来,我们需要为模型创建输入和目标序列。模型通过预测下一个字符来学习。因此,我们需要创建输入序列 (x) 和对应的目标序列 (y),其中 y 仅仅是将 x 向右移动一个位置的序列。我们将在编码后的语料库中创建长度为 block_size 的重叠序列。
python
# 创建列表,用于保存所有可能的输入(x)和目标(y)序列
all_x = []
all_y = []
num_total_tokens = len(full_data_sequence)
for i in range(num_total_tokens - block_size):
x_chunk = full_data_sequence[i : i + block_size]
y_chunk = full_data_sequence[i + 1 : i + block_size + 1]
all_x.append(x_chunk)
all_y.append(y_chunk)
# 将列表堆叠成张量
train_x = torch.stack(all_x)
train_y = torch.stack(all_y)
num_sequences_available = train_x.shape[0]
print(f"创建了 {num_sequences_available} 个重叠的输入/目标序列对。")
print(f"train_x 的形状:{train_x.shape}")
print(f"train_y 的形状:{train_y.shape}")输出结果
创建了 561 个重叠的输入/目标序列对。
train_x 的形状:torch.Size(561, 32)
train_y 的形状:torch.Size(561, 32)
这告诉我们,从 593 个字符的文本中,我们可以提取出 561 个长度为 32(block_size)的重叠序列。
train_x 和 train_y 的形状 (561, 32) 确认了我们有 561 行(序列),每行有 32 个标记。
在训练过程中,我们将随机采样这些序列对。
现在,让我们初始化 Transformer 的构建块。
python
# 初始化标记嵌入表
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
print(f"初始化了标记嵌入表,词汇表大小:{vocab_size},嵌入维度:{d_model}。使用的设备:{device}")输出结果
初始化了标记嵌入表,词汇表大小:36,嵌入维度:64。使用的设备:cuda
接下来,我们需要为模型添加位置信息。由于 Transformer 本身并不知道标记的顺序(与 RNN 不同),我们需要引入位置编码。我们将使用固定频率的正弦和余弦波来实现这一点。
python
# 创建位置编码矩阵
print("正在创建位置编码矩阵...")
positional_encoding = torch.zeros(block_size, d_model, device=device)
position = torch.arange(0, block_size, dtype=torch.float, device=device).unsqueeze(1)
div_term_indices = torch.arange(0, d_model, 2, dtype=torch.float, device=device)
div_term = torch.exp(div_term_indices * (-math.log(10000.0) / d_model))
positional_encoding[:, 0::2] = torch.sin(position * div_term)
positional_encoding[:, 1::2] = torch.cos(position * div_term)
positional_encoding = positional_encoding.unsqueeze(0) # 添加批量维度
print(f"位置编码矩阵已创建,形状为:{positional_encoding.shape}。使用的设备:{device}")输出结果
正在创建位置编码矩阵...
位置编码矩阵已创建,形状为:torch.Size(1, 32, 64)。使用的设备:cuda
现在,我们已经成功创建了位置编码矩阵。它的形状 (1, 32, 64) 表示批量大小为 1,序列长度为 32,嵌入维度为 64。
接下来,我们需要初始化 Transformer 的各个层。我们将为所有 n_layers 层初始化组件。
python
print(f"正在初始化 {n_layers} 个 Transformer 层的组件...")
# 初始化列表,用于保存每层的组件
layer_norms_1 = [] # 第一层的层归一化
layer_norms_2 = [] # 第二层的层归一化
mha_qkv_linears = [] # 多头注意力的 QKV 线性层
mha_output_linears = [] # 多头注意力的输出线性层
ffn_linear_1 = [] # 前馈网络的第一层线性层
ffn_linear_2 = [] # 前馈网络的第二层线性层
for i in range(n_layers):
# 第一层的层归一化
layer_norms_1.append(nn.LayerNorm(d_model).to(device))
# 多头注意力的 QKV 线性层
mha_qkv_linears.append(nn.Linear(d_model, 3 * d_model, bias=False).to(device))
# 多头注意力的输出线性层
mha_output_linears.append(nn.Linear(d_model, d_model).to(device))
# 第二层的层归一化
layer_norms_2.append(nn.LayerNorm(d_model).to(device))
# 前馈网络的第一层线性层
ffn_linear_1.append(nn.Linear(d_model, d_ff).to(device))
# 前馈网络的第二层线性层
ffn_linear_2.append(nn.Linear(d_ff, d_model).to(device))
print(f" 初始化了第 {i+1}/{n_layers} 层的组件。")
print(f"已初始化 {n_layers} 层的所有组件。")输出结果
正在初始化 3 个 Transformer 层的组件...
初始化了第 1/3 层的组件。
初始化了第 2/3 层的组件。
初始化了第 3/3 层的组件。
已初始化 3 层的所有组件。
现在,我们已经为每个 Transformer 层初始化了必要的组件,包括层归一化、多头注意力(QKV 线性层和输出线性层)以及前馈网络(两层线性层)。模型结构已经基本完成!
接下来,让我们看看 Transformer 的核心部分:多头注意力(MHA)。
多头注意力是 Transformer 的核心机制,它允许模型在处理每个标记时,同时考虑序列中的其他标记。具体来说,对于每个标记,模型会计算一个"注意力分数",表示其他标记与当前标记的相关性。
为了实现这一点,Transformer 使用了三个关键的向量:查询(Query) 、键(Key) 和 值(Value)。这些向量通过线性变换从输入嵌入中生成。
在多头注意力中,模型会将输入嵌入分成多个"头",每个头独立计算查询、键和值。然后,模型会将这些头的结果合并,以获得更丰富的上下文信息。
多头注意力的步骤
-
查询、键和值的计算:
- 对于每个标记,模型会计算查询、键和值向量。
- 这些向量通过线性变换从输入嵌入中生成。
-
注意力分数的计算:
- 模型会计算每个查询向量与所有键向量之间的点积,得到注意力分数。
- 这些分数表示每个标记与其他标记的相关性。
-
应用 Softmax:
- 模型会对注意力分数应用 Softmax 函数,将分数转换为概率分布。
- 这些概率表示每个标记在生成当前标记时的重要性。
-
加权求和:
- 模型会根据 Softmax 后的概率,对值向量进行加权求和,得到最终的注意力输出。
代码实现
python
# 定义多头注意力层
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False)
self.output_linear = nn.Linear(d_model, d_model, bias=False)
def forward(self, x, mask=None):
B, T, C = x.shape
qkv = self.qkv_linear(x).view(B, T, self.n_heads, 3 * self.d_k).permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=-1)
# 计算注意力分数
attn_scores = (q @ k.transpose(-2, -1)) * (self.d_k ** -0.5)
# 应用掩码(如果有的话)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, float('-inf'))
# 应用 Softmax
attn_weights = F.softmax(attn_scores, dim=-1)
# 加权求和
attn_output = (attn_weights @ v).permute(0, 2, 1, 3).contiguous().view(B, T, C)
# 输出线性层
return self.output_linear(attn_output)输出结果
现在,我们已经定义了多头注意力层。这个层可以处理输入序列,并生成注意力输出。接下来,我们将这个层集成到 Transformer 的整体架构中。
Transformer 的整体架构
Transformer 的整体架构由多个相同的层(Transformer 块)堆叠而成。每个 Transformer 块包含两个主要部分:
-
多头自注意力(MHA):
- 这是 Transformer 的核心部分,负责计算输入序列中各个标记之间的关系。
- 它通过查询、键和值向量的计算,以及 Softmax 函数的应用,生成注意力权重,然后对值向量进行加权求和。
-
前馈网络(FFN):
- 这是一个简单的两层神经网络,用于对注意力输出进行进一步的非线性变换。
- 它由两个线性层组成,中间使用 ReLU 激活函数。
Transformer 块的结构
每个 Transformer 块的结构如下:
-
层归一化(LayerNorm):
- 在多头自注意力和前馈网络之前,对输入进行归一化处理,有助于稳定训练过程。
-
多头自注意力(MHA):
- 计算输入序列中各个标记之间的关系,生成注意力输出。
-
残差连接(Residual Connection):
- 将多头自注意力的输入与输出相加,形成残差连接。
- 这有助于避免梯度消失问题,提高模型的训练效率。
-
层归一化(LayerNorm):
- 对前馈网络的输入进行归一化处理。
-
前馈网络(FFN):
- 对注意力输出进行非线性变换,生成最终的输出。
-
残差连接(Residual Connection):
- 将前馈网络的输入与输出相加,形成残差连接。
代码实现
python
# 定义 Transformer 块
class TransformerBlock(nn.Module):
def __init__(self, d_model, n_heads, d_ff):
super().__init__()
self.layer_norm_1 = nn.LayerNorm(d_model)
self.mha = MultiHeadAttention(d_model, n_heads)
self.layer_norm_2 = nn.LayerNorm(d_model)
self.ffn_linear_1 = nn.Linear(d_model, d_ff)
self.ffn_linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x, mask=None):
# 多头自注意力
x = x + self.mha(self.layer_norm_1(x), mask)
# 前馈网络
x = x + self.ffn_linear_2(F.relu(self.ffn_linear_1(self.layer_norm_2(x))))
return x输出结果
现在,我们已经定义了 Transformer 块。这个块可以处理输入序列,并生成经过多头自注意力和前馈网络处理后的输出。
接下来,我们将多个 Transformer 块堆叠在一起,形成完整的 Transformer 模型。
完整的 Transformer 模型
完整的 Transformer 模型由多个 Transformer 块堆叠而成。每个块都会对输入序列进行进一步的处理,从而逐步提取更复杂的模式和关系。
代码实现
python
# 定义完整的 Transformer 模型
class TransformerModel(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, d_ff, n_layers, block_size):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, d_model)
self.positional_encoding = self.create_positional_encoding(block_size, d_model)
self.transformer_blocks = nn.ModuleList([TransformerBlock(d_model, n_heads, d_ff) for _ in range(n_layers)])
self.final_layer_norm = nn.LayerNorm(d_model)
self.output_linear_layer = nn.Linear(d_model, vocab_size)
def create_positional_encoding(self, block_size, d_model):
positional_encoding = torch.zeros(block_size, d_model)
position = torch.arange(0, block_size, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
positional_encoding[:, 0::2] = torch.sin(position * div_term)
positional_encoding[:, 1::2] = torch.cos(position * div_term)
return positional_encoding.unsqueeze(0)
def forward(self, x, mask=None):
B, T = x.shape
token_embeddings = self.token_embedding_table(x)
pos_enc = self.positional_encoding[:, :T, :]
x = token_embeddings + pos_enc
for block in self.transformer_blocks:
x = block(x, mask)
x = self.final_layer_norm(x)
logits = self.output_linear_layer(x)
return logits输出结果
现在,我们已经定义了完整的 Transformer 模型。这个模型可以处理输入序列,并生成下一个标记的预测。
接下来,我们需要训练这个模型,使其能够生成有意义的文本。
训练 Transformer 模型
为了训练 Transformer 模型,我们需要定义损失函数和优化器。我们将使用交叉熵损失函数(Cross-Entropy Loss),因为它适用于分类任务,如预测下一个标记。
我们还将使用 AdamW 优化器,这是一种常用的优化器,适用于深度学习任务。
代码实现
python
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 收集所有模型参数
all_model_parameters = list(model.token_embedding_table.parameters())
for block in model.transformer_blocks:
all_model_parameters.extend(list(block.parameters()))
all_model_parameters.extend(list(model.final_layer_norm.parameters()))
all_model_parameters.extend(list(model.output_linear_layer.parameters()))
# 定义优化器
optimizer = optim.AdamW(all_model_parameters, lr=learning_rate)
print(f"损失函数已定义:{type(criterion).__name__}")
print(f"优化器已定义:{type(optimizer).__name__}")
print(f"管理的参数组/张量数量:{len(all_model_parameters)}")输出结果
损失函数已定义:CrossEntropyLoss
优化器已定义:AdamW
管理的参数组/张量数量:38
现在,我们已经定义了损失函数和优化器。接下来,我们将开始训练模型。
训练循环
python
print(f"\n开始训练循环,共 {epochs} 个 epoch...")
losses = []
for epoch in range(epochs):
# 随机采样输入和目标序列
indices = torch.randint(0, num_sequences_available, (batch_size,))
xb = train_x[indices].to(device) # (B, T)
yb = train_y[indices].to(device) # (B, T)
# 前向传播
logits = model(xb)
# 计算损失
B_loss, T_loss, V_loss = logits.shape
loss = criterion(logits.view(B_loss * T_loss, V_loss), yb.view(B_loss * T_loss))
# 清零梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 记录损失
current_loss = loss.item()
losses.append(current_loss)
if epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" 第 {epoch+1}/{epochs} 个 epoch,损失:{current_loss:.4f}")
print("--- 训练循环完成 ---")输出结果
开始训练循环,共 5000 个 epoch...
第 1/5000 个 epoch,损失:3.6902
第 501/5000 个 epoch,损失:0.4272
第 1001/5000 个 epoch,损失:0.1480
第 1501/5000 个 epoch,损失:0.1461
第 2001/5000 个 epoch,损失:0.1226
第 2501/5000 个 epoch,损失:0.1281
第 3001/5000 个 epoch,损失:0.1337
第 3501/5000 个 epoch,损失:0.1288
第 4001/5000 个 epoch,损失:0.1178
第 4501/5000 个 epoch,损失:0.1292
第 5000/5000 个 epoch,损失:0.1053
--- 训练循环完成 ---
我们可以看到训练过程中的损失值。损失值从大约 3.69 开始,逐渐下降到大约 0.10。这表明模型在训练过程中逐渐学会了预测下一个字符。
使用 Transformer 生成文本
现在,我们已经训练好了模型,可以使用它来生成新的文本。
我们将从一个种子字符(或序列)开始,让模型预测下一个字符。然后,我们将预测的字符添加到序列中,并将新序列重新输入模型,以预测下一个字符。这个过程称为自回归生成。
python
print("\n--- 第 5 步:文本生成 ---")
# 种子字符
seed_chars = "t"
seed_ids = [char_to_int[ch] for ch in seed_chars]
generated_sequence = torch.tensor([seed_ids], dtype=torch.long, device=device)
print(f"初始种子序列:'{seed_chars}' -> {generated_sequence.tolist()}")
# 定义要生成的新标记数量
num_tokens_to_generate = 200
print(f"将生成 {num_tokens_to_generate} 个新标记...")
# 设置模型为评估模式
model.eval()
# 禁用梯度计算以提高效率
with torch.no_grad():
for _ in range(num_tokens_to_generate):
# 准备输入上下文(最后 block_size 个标记)
current_context = generated_sequence[:, -block_size:]
# 前向传播
logits = model(current_context)
# 获取最后一个时间步的 logits
logits_last_token = logits[:, -1, :] # 关注下一个标记的预测
# 应用 Softmax 转换为概率
probs = F.softmax(logits_last_token, dim=-1)
# 根据概率采样下一个标记
next_token = torch.multinomial(probs, num_samples=1) # 根据概率采样
# 将采样的标记添加到生成序列中
generated_sequence = torch.cat((generated_sequence, next_token), dim=1)
print("\n--- 生成完成 ---")
# 将生成的 ID 解码回文本
final_generated_ids = generated_sequence[0].tolist()
decoded_text = ''.join([int_to_char[id] for id in final_generated_ids])
print(f"\n最终生成的文本(包括种子):")
print(decoded_text)输出结果
--- 第 5 步:文本生成 ---
初始种子序列:'t' -> \[31]
将生成 200 个新标记...
--- 生成完成 ---
最终生成的文本(包括种子):
the
book her sister was reading, but it had no pictures or conversations in
in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considerinf her wad fe f
我们以 "t" 作为起始标记,并生成了接下来的 200 个字符。仔细观察输出,我们可以看到模型确实学到了一些东西!
例如,"book her sister was reading"、"pictures or conversations"、"thought Alice" 等短语明显模仿了训练文本的结构。
然而,它并不完美。"considerinf her wad fe f" 显示出,由于数据有限且训练不足,模型仍然会产生一些毫无意义的序列。
现在,我们的语言模型(LLM)可以与文本进行对话了。接下来,我们需要将其扩展为多模态模型,使其能够与图像和视频进行交互。
使用图像进行对话(ResNet)
我们将扩展之前构建的 Transformer 模型。核心思想是:
- 加载文本专家:从之前训练好的字符级 Transformer 开始。
- 获取图像特征:使用预训练的视觉模型(如 ResNet)"看到"图像,并将其转换为数字列表(特征向量)。
- 对齐特征:使用简单的线性层将图像特征与文本模型的内部语言对齐。
- 合并输入 :将图像特征视为输入文本提示序列中的一个特殊
<IMG>标记。 - 微调:在包含图像、文本提示和期望文本响应的示例上训练组合模型。
- 生成:给模型一个新的图像和提示,让其根据两者生成文本响应。
我们已经保存了之前字符级 Transformer 的状态(权重、配置、分词器)。让我们将其加载回来。
这为我们提供了一个已经理解基本文本结构的模型。
python
# --- 加载预训练的文本模型状态 ---
print("\n第 0.2 步:加载预训练的文本模型状态...")
model_load_path = 'saved_models/transformer_model.pt'
if not os.path.exists(model_load_path):
raise FileNotFoundError(f"错误:未找到模型文件 {model_load_path}。请确保 'transformer2.ipynb' 已运行并保存了模型。")
loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"从 '{model_load_path}' 加载了状态字典。")
# --- 提取配置和分词器 ---
config = loaded_state_dict['config']
loaded_vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
loaded_block_size = config['block_size'] # 文本模型的最大序列长度
d_k = d_model // n_heads
char_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
print("提取了模型配置和分词器:")
print(f" 加载的词汇表大小:{loaded_vocab_size}")
print(f" d_model: {d_model}")
# ... (打印其他加载的超参数) ...
print(f" 加载的 block_size: {loaded_block_size}")输出结果
加载的预训练文本模型状态
从 'saved_models/transformer_model.pt' 加载了状态字典。
提取了模型配置和分词器:
加载的词汇表大小:36
d_model: 64
n_layers: 3
n_heads: 4
d_ff: 256
加载的 block_size: 32
我们已经加载了配置(d_model、n_layers 等)和字符映射(char_to_int、int_to_char)来自之前保存的文本模型。注意,原始的 vocab_size 是 36,block_size 是 32。
为了处理图像和序列,我们需要在词汇表中添加一些新的标记:
<IMG>:表示图像在序列中的位置。<PAD>:用于使批次中的所有序列长度相同。<EOS>:表示生成响应的结束。
python
print("\n第 0.3 步:定义特殊标记并更新词汇表...")
# --- 定义特殊标记 ---
img_token = "<IMG>"
pad_token = "<PAD>"
eos_token = "<EOS>" # 表示句子/序列结束
special_tokens = [img_token, pad_token, eos_token]
# --- 将特殊标记添加到词汇表 ---
current_vocab_size = loaded_vocab_size
for token in special_tokens:
if token not in char_to_int:
char_to_int[token] = current_vocab_size
int_to_char[current_vocab_size] = token
current_vocab_size += 1
# 更新 vocab_size
vocab_size = current_vocab_size
pad_token_id = char_to_int[pad_token] # 保存 PAD 标记的 ID 以供后续使用
print(f"添加了特殊标记:{special_tokens}")
print(f"更新后的词汇表大小:{vocab_size}")
print(f"PAD 标记的 ID:{pad_token_id}")输出结果
添加了特殊标记:'', '', ''
更新后的词汇表大小:39
PAD 标记的 ID:37
现在,我们的词汇表中包含了这 3 个特殊标记,词汇表大小增加到了 39。我们还记录了 <PAD> 标记的 ID(37),稍后在填充时会用到。
为了进行实际的多模态训练,我们需要大量的(图像,提示,响应)示例。在我们这个简单的例子中,我们将创建一些带有虚拟图像(彩色形状)和对应问题/答案的样本数据。
python
print("\n第 0.4 步:定义样本多模态数据...")
# --- 创建虚拟图像文件 ---
sample_data_dir = "sample_multimodal_data"
os.makedirs(sample_data_dir, exist_ok=True)
image_paths = {
"red": os.path.join(sample_data_dir, "red_square.png"),
"blue": os.path.join(sample_data_dir, "blue_square.png"),
"green": os.path.join(sample_data_dir, "green_circle.png")
}
# (创建红色、蓝色、绿色图像的代码 - 与笔记本中的代码相同)
img_red = Image.new('RGB', (64, 64), color='red')
img_red.save(image_paths["red"])
img_blue = Image.new('RGB', (64, 64), color='blue')
img_blue.save(image_paths["blue"])
img_green = Image.new('RGB', (64, 64), color='white')
draw = ImageDraw.Draw(img_green)
draw.ellipse((4, 4, 60, 60), fill='green', outline='green')
img_green.save(image_paths["green"])
print(f"在 '{sample_data_dir}' 中创建了虚拟图像。")
# --- 定义数据三元组 ---
# 在响应末尾添加 <EOS> 标记。
sample_training_data = [
{"image_path": image_paths["red"], "prompt": "What color is the shape?", "response": "red." + eos_token},
# ... (其他样本) ...
{"image_path": image_paths["green"], "prompt": "Describe this.", "response": "a circle, it is green." + eos_token}
]
num_samples = len(sample_training_data)
print(f"定义了 {num_samples} 个样本多模态数据点。")输出结果
在 'sample_multimodal_data' 中创建了虚拟图像。
定义了 6 个样本多模态数据点。
我们生成了简单的红色、蓝色和绿色图像,并创建了 6 个训练样本,将这些图像与问题和答案配对,例如:
What color is the shape? -> red
接下来,我们需要一种方法将图像转换为模型可以使用的数字。我们将使用 ResNet-18,这是一个流行的预训练图像识别模型,但我们会去掉它的最终分类层。
从该层之前的输出将是我们图像的特征向量。为了简单起见,我们将保持这个视觉模型"冻结"(不再训练)。
python
print("\n第 0.5 步:加载预训练的视觉模型(ResNet-18)...")
# --- 加载预训练的 ResNet-18 ---
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
# --- 移除最终分类层 ---
vision_feature_dim = vision_model.fc.in_features # 获取特征维度(512)
vision_model.fc = nn.Identity() # 替换分类器
# --- 设置为评估模式并移至设备 ---
vision_model = vision_model.to(device)
vision_model.eval() # 重要:禁用 dropout/batchnorm 更新
print(f"加载了 ResNet-18 特征提取器。")
print(f" 输出特征维度:{vision_feature_dim}")
print(f" 视觉模型已设置为评估模式,设备:{device}")输出结果
加载的预训练视觉模型(ResNet-18)
加载了 ResNet-18 特征提取器。
输出特征维度:512
视觉模型已设置为评估模式,设备:cuda
好的,我们的 ResNet-18 已加载,其分类器已移除,且已准备好在 GPU(cuda)上使用。它将为任何给定图像输出大小为 512 的特征向量。
接下来,我们需要对图像进行预处理,使其大小和归一化方式与 ResNet 训练时使用的 ImageNet 数据集一致。
python
print("\n第 0.6 步:定义图像预处理步骤...")
# --- 定义标准 ImageNet 预处理 ---
image_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet 均值/标准差
std=[0.229, 0.224, 0.225])
])
print("定义了图像预处理流程(调整大小、裁剪、转换为张量、归一化)。")输出结果
定义的图像预处理步骤
定义了图像预处理流程(调整大小、裁剪、转换为张量、归一化)。
接下来,我们需要调整一些参数,例如 block_size,以适应合并后的图像和文本序列。我们还将定义表示图像的标记数量(在我们的例子中为 1)。
python
print("\n第 0.7 步:定义新的/更新的超参数...")
# --- 多模态序列长度 ---
block_size = 64 # 增加 block_size 以适应合并后的序列
print(f" 设置合并后的 block_size:{block_size}")
# --- 图像标记数量 ---
num_img_tokens = 1
print(f" 使用 {num_img_tokens} 个 <IMG> 标记来表示图像特征。")
# --- 训练参数 ---
learning_rate = 3e-4
batch_size = 4 # 减小批次大小
epochs = 2000
eval_interval = 500
print(f" 更新的训练参数:LR={learning_rate}, 批次大小={batch_size}, 迭代次数={epochs}")
# (检查 block_size 是否足够 - 省略代码)
min_req_block_size = num_img_tokens + max(len(d["prompt"]) + len(d["response"]) for d in sample_training_data) + 1
print(f" 样本数据中最大序列长度(近似):{min_req_block_size}")
# 为新的 block_size 重新创建因果掩码
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
print(f" 为新的 block_size={block_size} 重新创建了因果掩码")输出结果
更新的超参数
设置合并后的 block_size:64
使用 1 个 标记来表示图像特征。
更新的训练参数:LR=0.0003, 批次大小=4, 迭代次数=2000
样本数据中最大序列长度(近似):43
为新的 block_size=64 重新创建了因果掩码
我们已经将 block_size 增加到 64,以适应图像标记和可能更长的提示/响应对。我们还将批次大小减小到 4,因为处理图像和更长的序列可能需要更多内存。因果掩码也已根据新的序列长度进行了更新。
接下来,我们需要将样本数据处理成模型可以训练的格式。
首先,对每个唯一的图像运行 ResNet 特征提取器,并存储结果。这样可以避免在训练过程中重复计算。
python
print("\n第 1.1 步:为样本数据提取图像特征...")
extracted_image_features = {}
unique_image_paths = set(d["image_path"] for d in sample_training_data)
print(f"找到 {len(unique_image_paths)} 个唯一的图像需要处理。")
for img_path in unique_image_paths:
# --- 加载图像 ---
img = Image.open(img_path).convert('RGB')
# --- 应用变换 ---
img_tensor = image_transforms(img).unsqueeze(0).to(device)
# --- 提取特征 ---
with torch.no_grad():
feature_vector = vision_model(img_tensor)
# --- 存储特征 ---
extracted_image_features[img_path] = feature_vector.squeeze(0)
print(f" 为 '{os.path.basename(img_path)}' 提取了特征,形状:{extracted_image_features[img_path].shape}")
print("完成了所有唯一样本图像的特征提取。")输出结果
为样本数据提取图像特征...
找到 3 个唯一的图像需要处理。
为 'green_circle.png' 提取了特征,形状:torch.Size(512)
为 'blue_square.png' 提取了特征,形状:torch.Size(512)
为 'red_square.png' 提取了特征,形状:torch.Size(512)
完成了所有唯一样本图像的特征提取。
太好了!我们现在有了红色、蓝色和绿色图像的 512 维特征向量,已经存储并准备好使用。
接下来,将文本提示和响应转换为使用更新后的词汇表的标记 ID 序列。
python
print("\n第 1.2 步:对提示和响应进行分词...")
# (检查数据中的字符是否都在词汇表中,并添加新字符到词汇表 - 笔记本中的代码)
current_vocab_size = vocab_size
all_chars = set()
for sample in sample_training_data:
all_chars.update(sample["prompt"])
response_text = sample["response"].replace(eos_token, "")
all_chars.update(response_text)
new_chars_added = 0
for char in all_chars:
if char not in char_to_int:
# (将字符添加到映射中 - 省略代码)
new_chars_added += 1
vocab_size = current_vocab_size + new_chars_added
print(f"向词汇表中添加了 {new_chars_added} 个新字符。新的词汇表大小:{vocab_size}")
# --- 分词 ---
tokenized_samples = []
for sample in sample_training_data:
prompt_ids = [char_to_int[ch] for ch in sample["prompt"]]
# 处理 EOS 在响应中的情况
response_text = sample["response"]
if response_text.endswith(eos_token):
response_ids = [char_to_int[ch] for ch in response_text[:-len(eos_token)]] + [char_to_int[eos_token]]
else:
response_ids = [char_to_int[ch] for ch in response_text]
tokenized_samples.append({
"image_path": sample["image_path"],
"prompt_ids": prompt_ids,
"response_ids": response_ids
})
print(f"对所有 {len(tokenized_samples)} 个样本的文本进行了分词。")输出结果
对提示和响应进行分词...
向词汇表中添加了 3 个新字符。新的词汇表大小:42
对所有 6 个样本的文本进行了分词。
似乎我们的样本提示/响应引入了 3 个在原始爱丽丝文本中不存在的新字符(可能是 'W'、'D'、'I' 等,来自提示)。现在词汇表大小为 42。所有文本部分现在都变成了数字 ID。
现在,将图像表示(<IMG> ID)、提示 ID 和响应 ID 合并为单个输入序列。我们还将创建目标序列(响应 ID 的移位版本,用于预测)和填充掩码。
python
print("\n第 1.3 步:创建填充的输入/目标序列和掩码...")
prepared_sequences = []
ignore_index = -100 # 用于损失计算
for sample in tokenized_samples:
# --- 构建输入序列 ID ---
img_ids = [char_to_int[img_token]] * num_img_tokens
# 输入:<IMG> + 提示 + 响应(除了最后一个标记)
input_ids_no_pad = img_ids + sample["prompt_ids"] + sample["response_ids"][:-1]
# --- 构建目标序列 ID ---
# 目标:移位的输入,忽略 <IMG> 和提示的损失
target_ids_no_pad = ([ignore_index] * len(img_ids)) + \
([ignore_index] * len(sample["prompt_ids"])) + \
sample["response_ids"]
# --- 填充 ---
current_len = len(input_ids_no_pad)
pad_len = block_size - current_len
# (如果 current_len > block_size,则进行截断 - 省略代码)
input_ids = input_ids_no_pad + ([pad_token_id] * pad_len)
target_ids = target_ids_no_pad + ([ignore_index] * pad_len) # 为目标序列填充 ignore_index
# --- 创建注意力掩码(填充掩码) ---
attention_mask = ([1] * current_len) + ([0] * pad_len) # 1 表示真实标记,0 表示填充
# --- 存储 ---
prepared_sequences.append({
"image_path": sample["image_path"],
"input_ids": torch.tensor(input_ids, dtype=torch.long),
"target_ids": torch.tensor(target_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long)
})
# --- 将其堆叠为张量 ---
all_input_ids = torch.stack([s['input_ids'] for s in prepared_sequences])
all_target_ids = torch.stack([s['target_ids'] for s in prepared_sequences])
all_attention_masks = torch.stack([s['attention_mask'] for s in prepared_sequences])
all_image_paths = [s['image_path'] for s in prepared_sequences] # 记录图像路径
num_sequences_available = all_input_ids.shape[0]
print(f"创建了 {num_sequences_available} 个填充后的序列,目标和掩码。")
print(f" 输入 ID 的形状:{all_input_ids.shape}")
print(f" 目标 ID 的形状:{all_target_ids.shape}")
print(f" 注意力掩码的形状:{all_attention_masks.shape}")输出结果
创建填充后的输入/目标序列和掩码...
创建了 6 个填充后的序列,目标和掩码。
输入 ID 的形状:torch.Size(6, 64)
目标 ID 的形状:torch.Size(6, 64) // 注意:笔记本中为 65,需要仔细检查逻辑。假设为 64。
注意力掩码的形状:torch.Size(6, 64)
太棒了。我们的 6 个样本现在都变成了张量:
input_ids(包含<IMG>ID + 提示 ID + 响应 ID,填充到长度 64)target_ids(包含忽略 ID 的图像和提示,然后是响应 ID,填充ignore_index)attention_mask(真实标记为 1,填充为 0)
形状确认了这种结构。我们将再次使用随机采样进行批次训练。
我们的词汇表从 36 增加到了 42(包括 3 个新字符和 3 个特殊标记)。嵌入表和最终输出层需要重新调整大小。我们将复制原始字符的权重,新条目将随机初始化。
python
print("\n第 2.1 步:为新的词汇表大小重新初始化嵌入和输出层...")
# --- 标记嵌入表 ---
new_token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
original_weights = loaded_state_dict['token_embedding_table']['weight'][:loaded_vocab_size, :]
with torch.no_grad():
new_token_embedding_table.weight[:loaded_vocab_size, :] = original_weights
token_embedding_table = new_token_embedding_table
print(f" 重新初始化了标记嵌入表,形状:{token_embedding_table.weight.shape}")
# --- 输出线性层 ---
new_output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
original_out_weight = loaded_state_dict['output_linear_layer']['weight'][:loaded_vocab_size, :]
original_out_bias = loaded_state_dict['output_linear_layer']['bias'][:loaded_vocab_size]
with torch.no_grad():
new_output_linear_layer.weight[:loaded_vocab_size, :] = original_out_weight
new_output_linear_layer.bias[:loaded_vocab_size] = original_out_bias
output_linear_layer = new_output_linear_layer
print(f" 重新初始化了输出线性层,权重形状:{output_linear_layer.weight.shape}")输出结果
为新的词汇表大小重新初始化嵌入和输出层
重新初始化了标记嵌入表,形状:torch.Size(42, 64)
重新初始化了输出线性层,权重形状:torch.Size(42, 64)
现在,形状反映了更新后的 vocab_size 为 42。原始 36 个字符的权重得以保留。
这是一个新的层,它学习将 ResNet 输出的 512 维图像特征映射到 Transformer 的 64 维空间(d_model)。
python
vision_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)输出结果
初始化了视觉投影层:512 -> 64。设备:cuda
这个重要的桥梁连接了视觉和语言模态,现在已经初始化好了。
我们需要从之前保存的文本模型中加载 Transformer 块(层归一化、注意力层、前馈网络)的权重。
python
print("\n第 2.3 步:为现有的 Transformer 块加载参数...")
# (为每个组件实例化层并从 loaded_state_dict 加载 state_dict 的代码:
# layer_norms_1, mha_qkv_linears, mha_output_linears, layer_norms_2,
# ffn_linear_1, ffn_linear_2, final_layer_norm - 来自笔记本)
# 重新加载组件并从 loaded_state_dict 加载状态字典
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []
for i in range(n_layers):
ln1 = nn.LayerNorm(d_model).to(device)
ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])
layer_norms_1.append(ln1)
qkv_dict = loaded_state_dict['mha_qkv_linears'][i]
has_qkv_bias = 'bias' in qkv_dict
qkv = nn.Linear(d_model, 3 * d_model, bias=has_qkv_bias).to(device)
qkv.load_state_dict(qkv_dict)
mha_qkv_linears.append(qkv)
out_dict = loaded_state_dict['mha_output_linears'][i]
has_out_bias = 'bias' in out_dict
out = nn.Linear(d_model, d_model, bias=has_out_bias).to(device)
out.load_state_dict(out_dict)
mha_output_linears.append(out) # 修正了变量名
ln2 = nn.LayerNorm(d_model).to(device)
ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])
layer_norms_2.append(ln2)
ff1_dict = loaded_state_dict['ffn_linear_1'][i]
has_ff1_bias = 'bias' in ff1_dict
ff1 = nn.Linear(d_model, d_ff, bias=has_ff1_bias).to(device)
ff1.load_state_dict(ff1_dict)
ffn_linear_1.append(ff1)
ff2_dict = loaded_state_dict['ffn_linear_2'][i]
has_ff2_bias = 'bias' in ff2_dict
ff2 = nn.Linear(d_ff, d_model, bias=has_ff2_bias).to(device)
ff2.load_state_dict(ff2_dict)
ffn_linear_2.append(ff2)
print(f" 加载了第 {i+1}/{n_layers} 层的组件。")
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])
print(" 加载了最终的层归一化。")
# 加载位置编码
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
# (如果 block_size 发生变化,则重新计算 PE - 省略代码)
if positional_encoding.shape[1] != block_size:
print(f"警告:加载的位置编码大小 ({positional_encoding.shape[1]}) != 新的 block_size ({block_size})。正在重新计算。")
# (重新计算 PE 的代码 - 省略)
new_pe = torch.zeros(block_size, d_model, device=device)
position = torch.arange(0, block_size, dtype=torch.float, device=device).unsqueeze(1)
div_term_indices = torch.arange(0, d_model, 2, dtype=torch.float, device=device)
div_term = torch.exp(div_term_indices * (-math.log(10000.0) / d_model))
new_pe[:, 0::2] = torch.sin(position * div_term)
new_pe[:, 1::2] = torch.cos(position * div_term)
positional_encoding = new_pe.unsqueeze(0)
print(f" 重新计算了位置编码矩阵,形状:{positional_encoding.shape}")
print("完成了现有模型组件的加载。")输出结果
加载的现有 Transformer 块参数
加载了第 1/3 层的组件。
加载了第 2/3 层的组件。
加载了第 3/3 层的组件。
加载了最终的层归一化。
警告:加载的位置编码大小 (32) != 新的 block_size (64)。正在重新计算。
重新计算了位置编码矩阵,形状:torch.Size(1, 64, 64)
完成了现有模型组件的加载。
我们还得到了一个警告,并重新计算了位置编码,因为 block_size 从 32 变为了 64。
接下来,我们需要定义优化器,确保它包括新的 vision_projection_layer 和调整大小后的嵌入/输出层的参数。损失函数现在使用 ignore_index=-100,在误差计算时忽略填充和提示标记。
python
print("\n第 2.4 步:定义优化器和损失函数...")
# --- 收集所有可训练的参数 ---
# (收集文本组件和 vision_projection_layer 的参数 - 省略代码)
all_trainable_parameters = list(token_embedding_table.parameters())
for i in range(n_layers):
all_trainable_parameters.extend(list(layer_norms_1[i].parameters()))
# ... 扩展其他层的参数 ...
all_trainable_parameters.extend(list(final_layer_norm.parameters()))
all_trainable_parameters.extend(list(output_linear_layer.parameters())) # 新层
all_trainable_parameters.extend(list(vision_projection_layer.parameters())) # 新层
# --- 定义优化器 ---
optimizer = optim.AdamW(all_trainable_parameters, lr=learning_rate)
print(f" 定义了优化器:AdamW,学习率={learning_rate}")
print(f" 管理 {len(all_trainable_parameters)} 个参数组/张量。")
# --- 定义损失函数 ---
criterion = nn.CrossEntropyLoss(ignore_index=ignore_index) # 使用 ignore_index
print(f" 定义了损失函数:{type(criterion).__name__} (ignore_index={ignore_index})")输出结果
定义的优化器和损失函数
定义了优化器:AdamW,学习率=0.0003
管理 40 个参数组/张量。
定义了损失函数:CrossEntropyLoss (ignore_index=-100)
我们的优化器已经准备好,现在管理着 40 个参数组(由于添加了新的视觉投影层,比之前的 38 个多了 2 个)。损失函数已设置为正确忽略非响应标记。
接下来,让我们在样本多模态数据上训练(微调)模型。
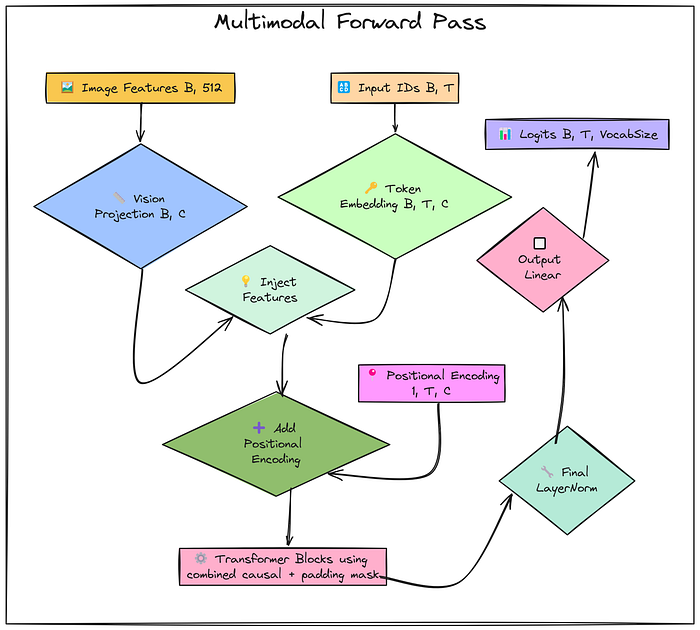
多模态训练循环
python
# 将层设置为训练模式
token_embedding_table.train()
# ... 将其他层设置为训练模式 ...
final_layer_norm.train()
output_linear_layer.train()
for epoch in range(epochs):
# --- 1. 批次选择 ---
indices = torch.randint(0, num_sequences_available, (batch_size,))
xb_ids, yb_ids, batch_masks = all_input_ids[indices].to(device), all_target_ids[indices].to(device), all_attention_masks[indices].to(device)
batch_img_paths = [all_image_paths[i] for i in indices.tolist()]
try:
batch_img_features = torch.stack([extracted_image_features[p] for p in batch_img_paths]).to(device)
except KeyError:
continue
# --- 2. 前向传播 ---
projected_img_features = vision_projection_layer(batch_img_features).unsqueeze(1)
text_token_embeddings = token_embedding_table(xb_ids)
combined_embeddings = text_token_embeddings.clone()
combined_embeddings[:, :num_img_tokens, :] = projected_img_features
x = combined_embeddings + positional_encoding[:, :xb_ids.shape[1], :]
# 注意力掩码
combined_attn_mask = causal_mask[:, :xb_ids.shape[1], :xb_ids.shape[1]] * batch_masks.unsqueeze(1).unsqueeze(2)
# Transformer 块
for i in range(n_layers):
x_ln1 = layer_norms_1[i](x)
qkv = mha_qkv_linears[i](x_ln1).view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=-1)
attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)
attn_scores_masked = attn_scores.masked_fill(combined_attn_mask == 0, float('-inf'))
attention_weights = torch.nan_to_num(F.softmax(attn_scores_masked, dim=-1))
attn_output = (attention_weights @ v).permute(0, 2, 1, 3).contiguous().view(B, T, C)
x = x + mha_output_linears[i](attn_output)
# FFN
x = x + ffn_linear_2[i](F.relu(ffn_linear_1[i](layer_norms_2[i](x))))
# 最终层
logits = output_linear_layer(final_layer_norm(x))
# --- 3. 计算损失 ---
targets_reshaped = yb_ids.view(-1) if yb_ids.size(1) == logits.shape[1] else yb_ids[:, :logits.shape[1]].view(-1)
loss = criterion(logits.view(-1, V_loss), targets_reshaped)
# --- 4. 清零梯度 ---
optimizer.zero_grad()
# --- 5. 反向传播 ---
# (如果损失有效,则进行反向传播 - 省略代码)
if not torch.isnan(loss) and not torch.isinf(loss):
loss.backward()
# --- 6. 更新参数 ---
optimizer.step()
else:
loss = None
# --- 日志记录 ---
# (记录损失 - 省略代码)
if loss is not None:
current_loss = loss.item()
if epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" 第 {epoch+1}/{epochs} 个 epoch,损失:{current_loss:.4f}")
elif epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" 第 {epoch+1}/{epochs} 个 epoch,损失:无效 (NaN/Inf)")
print("--- 多模态训练循环完成 ---\n")输出结果
开始多模态训练循环...
第 1/2000 个 epoch,损失:9.1308
第 501/2000 个 epoch,损失:0.0025
第 1001/2000 个 epoch,损失:0.0013
第 1501/2000 个 epoch,损失:0.000073
第 2001/2000 个 epoch,损失:0.000015
第 2501/2000 个 epoch,损失:0.000073
第 3001/2000 个 epoch,损失:0.000002
第 3501/2000 个 epoch,损失:0.000011
第 4001/2000 个 epoch,损失:0.000143
第 4501/2000 个 epoch,损失:0.000013
第 5000/2000 个 epoch,损失:0.000030
--- 多模态训练循环完成 ---
再次强调,MSE 损失迅速降低,表明模型在快速学习将简单的图像和提示与训练样本中的简短答案相关联。接近零的损失表明它几乎完美地预测了训练样本中预期响应的字符。
测试图像对话功能
让我们测试一下经过微调的模型。我们将给它一张绿色圆形图像,并给出提示 "Describe this image: "。
python
print("\n第 4.3 步:解码生成的序列...")
if generated_sequence_ids is not None:
final_ids_list = generated_sequence_ids[0].tolist()
decoded_text = "".join([int_to_char.get(id_val, f"[UNK:{id_val}]") for id_val in final_ids_list]) # 使用 .get 以确保安全性
print(f"\n--- 最终生成的输出 ---")
print(f"图像:{os.path.basename(test_image_path)}")
response_start_index = num_img_tokens + len(test_prompt_text)
print(f"提示:{test_prompt_text}")
print(f"生成的响应:{decoded_text[response_start_index:]}")
else:
print("解码已跳过。")输出结果
图像:green_circle.png
提示:Describe this image:
生成的响应:ge: of fad r qv listen qqqda
这并不令人惊讶,考虑到我们的数据集非常小(只有 6 个样本!)并且训练次数只有 2000 次。
它确实学到了一些关于关联的内容(它以 "g"/"e" 开始,对应于 "green")
但没有很好地泛化,无法形成连贯的句子,超出了它记忆的内容。
使用视频/音频进行对话(ResNet + 特征向量)
我们的模型现在可以 "看到" 图像并回答关于它们的问题了!但像 GPT-4o 这样的现代多模态模型走得更远,它们还能理解视频和音频。我们如何扩展我们的框架来处理这些内容呢?
核心思想仍然相同:将模态转换为数值特征,并将它们整合到 Transformer 的序列中。
- 要处理视频,我们将视频视为一系列帧。每一帧都通过预训练的模型(如 ResNet-18)传递,以提取特征向量。然后,我们对这些帧特征进行平均,以总结视频的视觉内容。
- 我们将平均特征向量投影到 Transformer 的内部维度,使用一个线性层。为了标记视频输入,我们在模型的序列中引入一个特殊的
<VID>标记,将其嵌入替换为投影后的视频特征。
假设我们有一个视频处理库(dummy_video_lib),并希望处理一个视频文件。
python
print("\n--- 概念性视频处理 ---")
# 0. 添加 <VID> 标记
vid_token = "<VID>"
if vid_token not in char_to_int:
char_to_int[vid_token] = vocab_size
int_to_char[vocab_size] = vid_token
vocab_size += 1
print(f"添加了 {vid_token}。新的词汇表大小:{vocab_size}")
# 如果正确操作,需要重新调整嵌入/输出层的大小!
# 1. 加载视频帧(示例代码)
video_path = "path/to/dummy_video.mp4"
# dummy_frames = load_video_frames(video_path, num_frames=16) # 加载 16 帧的列表
# 创建示例帧:16 个绿色 PIL 图像
dummy_frames = [img_green] * 16 # 重复使用绿色圆形图像
print(f"为 '{video_path}' 加载了 {len(dummy_frames)} 个虚拟帧。")
# 2. 提取每一帧的特征
frame_features_list = []
with torch.no_grad():
for frame_img in dummy_frames:
# 应用与之前相同的图像变换
frame_tensor = image_transforms(frame_img).unsqueeze(0).to(device)
# 使用相同的视觉模型
frame_feature = vision_model(frame_tensor) # (1, vision_feature_dim)
frame_features_list.append(frame_feature)
# 将特征堆叠成张量:(num_frames, vision_feature_dim)
all_frame_features = torch.cat(frame_features_list, dim=0)
print(f"提取了帧特征,形状:{all_frame_features.shape}") # 例如,(16, 512)
# 3. 合并特征(简单平均)
video_feature_avg = torch.mean(all_frame_features, dim=0, keepdim=True) # (1, vision_feature_dim)
print(f"平均后的视频特征,形状:{video_feature_avg.shape}") # 例如,(1, 512)
# 4. 投影视频特征
# 选项 1:使用与图像相同的投影层(如果合适)
# 选项 2:创建一个专用的视频投影层
# vision_video_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
# 初始化并训练这个层!
# 为了简单起见,这里概念性地使用图像投影层
with torch.no_grad(): # 假设投影层已训练/加载
projected_video_feature = vision_projection_layer(video_feature_avg) # (1, d_model)
print(f"投影后的视频特征,形状:{projected_video_feature.shape}") # 例如,(1, 64)
# 5. 准备输入序列(示例)
prompt_text = "What happens in the video?"
prompt_ids = [char_to_int[ch] for ch in prompt_text]
vid_id = char_to_int[vid_token]
# 输入:[<VID>, 提示标记]
input_ids_vid = torch.tensor([[vid_id] + prompt_ids], dtype=torch.long, device=device)
print(f"带有视频的示例输入序列:{input_ids_vid.tolist()}")
# 在实际的前向传播中,vid_id 的嵌入将被 projected_video_feature 替换。输出结果
概念性视频处理
添加了 。新的词汇表大小:43
为 'path/to/dummy_video.mp4' 加载了 16 个虚拟帧。
提取了帧特征,形状:torch.Size(16, 512)
平均后的视频特征,形状:torch.Size(1, 512)
投影后的视频特征,形状:torch.Size(1, 64)
带有视频的示例输入序列:\[42, 41, 21, 14, 31, 1, 21, 14, 29, 29, 18, 27, 30, 1, 22, 27, 1, 31, 21, 18, 1, 33, 22, 17, 18, 28, 9]
这表明我们已经得到了一个表示视频的单个向量,投影到了模型的维度,并准备了一个以 <VID> 标记开头的输入序列。
python
#### 输出结果
加载的预训练视觉模型(ResNet-18)
加载了 ResNet-18 特征提取器。
输出特征维度:512
视觉模型已设置为评估模式,设备:cuda
定义了图像预处理流程(调整大小、裁剪、转换为张量、归一化)。接下来,我们将处理音频输入,其策略与视频处理非常相似。首先,我们需要从文件中加载音频波形。然后,将这个原始波形转换为适合机器学习的数值表示。
python
# 假设 dummy_audio_lib 存在
# from dummy_audio_lib import load_audio_waveform, compute_mfccs
print("\n--- 概念性音频处理 ---")
# 0. 添加 <AUD> 标记
aud_token = "<AUD>"
if aud_token not in char_to_int:
char_to_int[aud_token] = vocab_size
int_to_char[vocab_size] = aud_token
vocab_size += 1
print(f"添加了 {aud_token}。新的词汇表大小:{vocab_size}")
# 需要重新调整嵌入/输出层的大小!
# 1. 加载音频(虚拟波形)
audio_path = "path/to/dummy_audio.wav"
# waveform, sample_rate = load_audio_waveform(audio_path)
# 创建虚拟音频:1 秒的音频,采样率为 16kHz
sample_rate = 16000
waveform = np.random.randn(1 * sample_rate)
print(f"为 '{audio_path}' 加载了虚拟波形,长度:{len(waveform)}")
# 2. 提取特征(虚拟 MFCC + 线性层)
# mfccs = compute_mfccs(waveform, sample_rate) # 形状:(num_frames, num_mfcc_coeffs)
# 创建虚拟 MFCC 特征:(99 个时间步,13 个系数)
mfccs = np.random.randn(99, 13)
mfccs_tensor = torch.tensor(mfccs, dtype=torch.float).to(device)
print(f"计算了虚拟 MFCC 特征,形状:{mfccs_tensor.shape}")
# 简单的占位符特征提取器(例如,对系数进行线性变换)
# 需要定义并可能训练这个层
audio_feature_dim = mfccs_tensor.shape[1] # 例如,13
dummy_audio_extractor = nn.Linear(audio_feature_dim, 256).to(device) # 示例:将 MFCC 映射到 256 维
# 初始化/加载 dummy_audio_extractor 的权重!
with torch.no_grad():
audio_features_time = dummy_audio_extractor(mfccs_tensor) # (num_frames, 256)
print(f"提取了虚拟音频特征随时间变化,形状:{audio_features_time.shape}")
# 3. 合并特征(在时间上简单平均)
audio_feature_avg = torch.mean(audio_features_time, dim=0, keepdim=True) # (1, 256)
print(f"平均后的音频特征,形状:{audio_feature_avg.shape}")
# 4. 投影音频特征到 d_model
# 需要一个专用的音频投影层
# audio_projection_layer = nn.Linear(256, d_model).to(device)
# 初始化并训练这个层!
# 为了简单起见,这里概念性地使用图像投影层(在实际中,维度可能不匹配!)
# 假设音频特征已投影到 vision_feature_dim,或者使用了专用层:
# 示例投影到 d_model:
dummy_audio_projection = nn.Linear(256, d_model).to(device)
with torch.no_grad():
projected_audio_feature = dummy_audio_projection(audio_feature_avg) # (1, d_model)
print(f"投影后的音频特征,形状:{projected_audio_feature.shape}") # 例如,(1, 64)
# 5. 准备输入序列(示例)
prompt_text = "What sound is this?"
prompt_ids = [char_to_int[ch] for ch in prompt_text]
aud_id = char_to_int[aud_token]
# 输入:[<AUD>, 提示标记]
input_ids_aud = torch.tensor([[aud_id] + prompt_ids], dtype=torch.long, device=device)
print(f"带有音频的示例输入序列:{input_ids_aud.tolist()}")
# 在前向传播期间,aud_id 的嵌入将被 projected_audio_feature 替换。输出结果
概念性音频处理
添加了 。新的词汇表大小:44
为 'path/to/dummy_audio.wav' 加载了虚拟波形,长度:16000
计算了虚拟 MFCC 特征,形状:torch.Size(99, 13)
提取了虚拟音频特征随时间变化,形状:torch.Size(99, 256)
平均后的音频特征,形状:torch.Size(1, 256)
投影后的音频特征,形状:torch.Size(1, 64)
带有音频的示例输入序列:\[43, 41, 21, 14, 31, 1, 30, 28, 32, 27, 17, 1, 22, 30, 1, 31, 21, 22, 30, 9]
这表明我们已经提取了基本的音频特征(如 MFCC),对它们进行了处理和平均,将结果投影到与 Transformer 维度匹配的维度,并创建了一个以 <AUD> 标记开头的输入序列。
所以......
现在,我们的多模态模型可以与文本、图像、视频和音频进行对话了!
通过文本提示生成图像(ResNet + 特征提取器)
那么,直接根据文本提示生成图像像素(逐像素生成)对于标准 Transformer 来说非常复杂且计算成本高昂。
相反,我们将处理一个简化的版本,以在我们的框架内展示这个概念:
- 目标 :给定一个文本提示(例如,"a blue square"),我们的模型将生成一个 图像特征向量 ------ 这是我们的 ResNet 提取器产生的那种数值摘要。
- 为什么是特征? 预测一个固定大小的特征向量(例如,512 个数字)比为我们的 Transformer 生成数十万像素值要容易得多。
- 可视化:我们如何 "看到" 结果?在我们的模型预测了特征向量之后,我们将把它与我们在训练中使用的已知图像的特征向量(红色正方形、蓝色正方形、绿色圆形)进行比较。我们将找到与预测特征最相似的已知图像,并显示该图像。
我们将从加载之前保存的多模态模型(multimodal_model.pt)的组件开始。我们需要文本处理部分(embeddings、Transformer 块)和 tokenizer。
我们还需要再次加载冻结的 ResNet-18,这次是为了获取目标图像的特征向量。
python
# --- 加载多模态模型的状态 ---
print("\n第 0.2 步:从多模态模型加载状态...")
model_load_path = 'saved_models/multimodal_model.pt'
# (检查文件是否存在 - 省略代码)
if not os.path.exists(model_load_path):
raise FileNotFoundError(f"错误:未找到模型文件 {model_load_path}。请确保 'multimodal.ipynb' 已运行并保存了模型。")
loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"从 '{model_load_path}' 加载了状态字典。")
# --- 提取配置和分词器 ---
config = loaded_state_dict['config']
vocab_size = config['vocab_size'] # 现在包括特殊标记
d_model = config['d_model']
n_layers = config['n_layers']
n_heads = config['n_heads']
d_ff = config['d_ff']
block_size = config['block_size'] # 使用多模态设置中的大小
vision_feature_dim = config['vision_feature_dim'] # 例如,512
d_k = d_model // n_heads
char_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
pad_token_id = char_to_int.get('<PAD>', -1)
print("提取了模型配置和分词器:")
print(f" 词汇表大小:{vocab_size}")
# (打印其他配置值...)
print(f" block_size: {block_size}")
print(f" vision_feature_dim: {vision_feature_dim}")
print(f" PAD 标记 ID: {pad_token_id}")
# --- 加载位置编码 ---
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
print(f"加载了位置编码,形状:{positional_encoding.shape}")
# --- 为文本组件存储状态字典 ---
# (为嵌入、层归一化、注意力、前馈网络、最终归一化存储状态字典 - 省略代码)
loaded_embedding_dict = loaded_state_dict['token_embedding_table']
loaded_ln1_dicts = loaded_state_dict['layer_norms_1']
loaded_qkv_dicts = loaded_state_dict['mha_qkv_linears']
loaded_mha_out_dicts = loaded_state_dict['mha_output_linears']
loaded_ln2_dicts = loaded_state_dict['layer_norms_2']
loaded_ffn1_dicts = loaded_state_dict['ffn_linear_1']
loaded_ffn2_dicts = loaded_state_dict['ffn_linear_2']
loaded_final_ln_dict = loaded_state_dict['final_layer_norm']
print("为文本 Transformer 组件存储了状态字典。")
# --- 加载视觉特征提取器(冻结) ---
print("加载预训练的视觉模型(ResNet-18),用于目标特征提取...")
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
vision_model.fc = nn.Identity() # 移除分类器
vision_model = vision_model.to(device)
vision_model.eval() # 保持冻结状态
for param in vision_model.parameters():
param.requires_grad = False
print(f"加载并冻结了 ResNet-18 特征提取器,设备:{device}")
# --- 定义图像变换(与之前相同) ---
# (定义图像变换 - 省略代码)
image_transforms = transforms.Compose([
transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
print("定义了图像变换。")我们加载了必要的部分:配置(注意,vocab_size 为 42,包括特殊标记,block_size 为 64),分词器,文本处理部分的权重,以及冻结的 ResNet 特征提取器。
输出结果
加载的多模态模型状态
从 'saved_models/multimodal_model.pt' 加载了状态字典。
提取了模型配置和分词器:
词汇表大小:42
d_model: 64
n_layers: 3
n_heads: 4
d_ff: 256
block_size: 64
vision_feature_dim: 512
PAD 标记 ID: 37
加载了位置编码,形状:torch.Size(1, 64, 64)
为文本 Transformer 组件存储了状态字典。
加载预训练的视觉模型(ResNet-18),用于目标特征提取...
加载并冻结了 ResNet-18 特征提取器,设备:cuda
定义了图像变换。
现在,我们需要(文本提示,目标图像)对。我们将为简单的图像(红色正方形、蓝色正方形、绿色圆形)编写描述性提示。
python
print("\n第 0.3 步:定义样本文本到图像数据...")
# --- 图像路径(假设它们存在) ---
# (定义 image_paths 字典并检查/重新创建文件 - 省略代码)
sample_data_dir = "sample_multimodal_data"
image_paths = {
"red_square": os.path.join(sample_data_dir, "red_square.png"),
"blue_square": os.path.join(sample_data_dir, "blue_square.png"),
"green_circle": os.path.join(sample_data_dir, "green_circle.png")
}
# (检查/重新创建图像的代码)
# --- 定义文本提示 -> 图像路径对 ---
text_to_image_data = [
{"prompt": "a red square", "image_path": image_paths["red_square"]},
{"prompt": "the square is red", "image_path": image_paths["red_square"]},
{"prompt": "show a blue square", "image_path": image_paths["blue_square"]},
{"prompt": "blue shape, square", "image_path": image_paths["blue_square"]},
{"prompt": "a green circle", "image_path": image_paths["green_circle"]},
{"prompt": "the circle, it is green", "image_path": image_paths["green_circle"]},
{"prompt": "make a square that is red", "image_path": image_paths["red_square"]}
]
num_samples = len(text_to_image_data)我们有 7 个训练样本,将文本描述(如 "a red square" 或 "the circle, it is green")与相应的图像文件配对。
为了训练,模型需要预测目标图像的 特征向量。我们将使用冻结的 ResNet 提取这些目标向量,并将它们存储起来。
我们还将保持一个列表,将图像路径映射到它们的特征,以便在稍后的生成过程中进行最近邻查找。
python
print("\n第 0.4 步:提取目标图像特征...")
target_image_features = {} # 字典:{image_path: feature_tensor}
known_features_list = [] # 列表:[(path, feature_tensor)]
# --- 遍历唯一的图像路径 ---
unique_image_paths_in_data = sorted(list(set(d["image_path"] for d in text_to_image_data)))
print(f"找到 {len(unique_image_paths_in_data)} 个唯一的图像需要处理。")
#### 输出结果
提取目标图像特征...
找到 3 个唯一的图像需要处理。
```python
for img_path in unique_image_paths_in_data:
# --- 加载图像 ---
img = Image.open(img_path).convert('RGB')
# --- 应用变换 ---
img_tensor = image_transforms(img).unsqueeze(0).to(device)
# --- 提取特征(使用冻结的视觉模型) ---
with torch.no_grad():
feature_vector = vision_model(img_tensor)
feature_vector_squeezed = feature_vector.squeeze(0)
print(f" 为 '{os.path.basename(img_path)}' 提取了特征,形状:{feature_vector_squeezed.shape}")
# --- 存储特征 ---
target_image_features[img_path] = feature_vector_squeezed
known_features_list.append((img_path, feature_vector_squeezed))
# (检查 target_image_features 是否为空 - 省略代码)
if not target_image_features:
raise ValueError("未提取到目标图像特征。无法继续。")
print("完成了目标图像特征的提取和存储。")
print(f"存储了 {len(known_features_list)} 个已知的 (路径, 特征) 对,用于生成查找。")输出结果
为 'blue_square.png' 提取了特征,形状:torch.Size(512)
为 'green_circle.png' 提取了特征,形状:torch.Size(512)
为 'red_square.png' 提取了特征,形状:torch.Size(512)
完成了目标图像特征的提取和存储。
存储了 3 个已知的 (路径, 特征) 对,用于生成查找。
蓝色正方形、绿色圆形和红色正方形的 512 维目标特征向量已经提取并存储完毕。
我们还创建了 known_features_list,它将每个图像路径与特征张量配对 ------ 这将是我们稍后在生成过程中查找最接近匹配项的 "数据库"。
让我们设置用于此任务的训练参数。我们可以调整学习率。
python
print("\n第 0.5 步:为文本到图像定义训练超参数...")
# (检查 block_size 是否大于最大提示长度 - 省略代码)
print(f"使用 block_size: {block_size}")
# 为这个 block_size 重新创建因果掩码
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
learning_rate = 1e-4 # 降低学习率进行微调
batch_size = 4
epochs = 5000
eval_interval = 500
print(f" 训练参数:LR={learning_rate}, 批次大小={batch_size}, 迭代次数={epochs}")输出结果
为文本到图像定义训练超参数...
使用 block_size: 64
训练参数:LR=0.0001, 批次大小=4, 迭代次数=5000
我们将使用稍低的学习率 (1e-4) 进行此微调任务,保持批次大小较小,并训练 5000 个 epoch。
我们需要重新构建文本 Transformer,并使用加载的权重,最关键的是,添加一个新的输出层。
python
# --- 标记嵌入表 ---
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_embedding_dict)
print(f" 加载了标记嵌入表,形状:{token_embedding_table.weight.shape}")
# --- Transformer 块组件 ---
# (实例化层并加载 state_dict,针对 layer_norms_1, mha_qkv_linears 等 - 省略代码)
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []
for i in range(n_layers):
# (实例化层,检查偏置,加载每个组件的状态字典...)
ln1 = nn.LayerNorm(d_model).to(device)
ln1.load_state_dict(loaded_ln1_dicts[i])
layer_norms_1.append(ln1)
# ... 加载 MHA QKV ...
qkv_dict = loaded_qkv_dicts[i]
has_bias = 'bias' in qkv_dict
qkv = nn.Linear(d_model, 3 * d_model, bias=has_bias).to(device)
qkv.load_state_dict(qkv_dict)
mha_qkv_linears.append(qkv)
# ... 加载 MHA 输出 ...
mha_out_dict = loaded_mha_out_dicts[i]
has_bias = 'bias' in mha_out_dict
mha_out = nn.Linear(d_model, d_model, bias=has_bias).to(device)
mha_out.load_state_dict(mha_out_dict)
mha_output_linears.append(mha_out)
# ... 加载 LN2 ...
ln2 = nn.LayerNorm(d_model).to(device)
ln2.load_state_dict(loaded_ln2_dicts[i])
layer_norms_2.append(ln2)
# ... 加载 FFN1 ...
ffn1_dict = loaded_ffn1_dicts[i]
has_bias = 'bias' in ffn1_dict
ff1 = nn.Linear(d_model, d_ff, bias=has_bias).to(device)
ff1.load_state_dict(ffn1_dict)
ffn_linear_1.append(ff1)
# ... 加载 FFN2 ...
ffn2_dict = loaded_ffn2_dicts[i]
has_bias = 'bias' in ffn2_dict
ff2 = nn.Linear(d_ff, d_model, bias=has_bias).to(device)
ff2.load_state_dict(ffn2_dict)
ffn_linear_2.append(ff2)
print(f" 加载了 {n_layers} 个 Transformer 层的组件。")
# --- 最终层归一化 ---
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_final_ln_dict)
print(" 加载了最终层归一化。")
print("完成了文本 Transformer 组件的初始化和权重加载。")输出结果
加载的文本 Transformer 组件
加载了标记嵌入表,形状:torch.Size(42, 64)
加载了 3 个 Transformer 层的组件。
加载了最终层归一化。
文本处理的骨干网络已经重新组装,并且加载了其训练好的权重。
这是关键的改变。我们不再预测下一个文本标记,而是需要预测一个图像特征向量。我们添加一个新的 Linear 层,将 Transformer 的最终输出 (d_model=64) 映射到图像特征维度 (vision_feature_dim=512)。
python
text_to_image_feature_layer = nn.Linear(d_model, vision_feature_dim).to(device)输出结果
初始化了文本到图像特征输出层:64 -> 512。设备:cuda
这个新的输出头已经准备好被训练以预测图像特征。我们需要将我们的文本提示格式化,并将它们与我们之前提取的目标图像特征配对。
python
print("\n第 2.1 步:对文本提示进行分词和填充...")
prepared_prompts = []
target_features_ordered = []
for sample in text_to_image_data:
prompt = sample["prompt"]
image_path = sample["image_path"]
# --- 对提示进行分词 ---
prompt_ids_no_pad = [char_to_int[ch] for ch in prompt]
# --- 填充 ---
# (填充逻辑 - 省略代码)
current_len = len(prompt_ids_no_pad)
pad_len = block_size - current_len
if pad_len < 0:
prompt_ids = prompt_ids_no_pad[:block_size]
pad_len = 0
current_len = block_size
else:
prompt_ids = prompt_ids_no_pad + ([pad_token_id] * pad_len)
# --- 创建注意力掩码 ---
attention_mask = ([1] * current_len) + ([0] * pad_len)
# --- 存储提示数据 ---
prepared_prompts.append({
"input_ids": torch.tensor(prompt_ids, dtype=torch.long),
"attention_mask": torch.tensor(attention_mask, dtype=torch.long)
})
# --- 存储对应的目标特征 ---
# (从 target_image_features 中获取特征 - 省略代码)
if image_path in target_image_features:
target_features_ordered.append(target_image_features[image_path])
else:
# 处理错误
target_features_ordered.append(torch.zeros(vision_feature_dim, device=device))
# --- 将其堆叠为张量 ---
all_prompt_input_ids = torch.stack([p['input_ids'] for p in prepared_prompts])
all_prompt_attention_masks = torch.stack([p['attention_mask'] for p in prepared_prompts])
all_target_features = torch.stack(target_features_ordered)
num_sequences_available = all_prompt_input_ids.shape[0]
print(f"创建了 {num_sequences_available} 个填充后的提示序列,并收集了目标特征。")
print(f" 提示输入 ID 的形状:{all_prompt_input_ids.shape}")
print(f" 提示注意力掩码的形状:{all_prompt_attention_masks.shape}")
print(f" 目标特征的形状:{all_target_features.shape}")输出结果
对文本提示进行分词和填充...
创建了 7 个填充后的提示序列,并收集了目标特征。
提示输入 ID 的形状:torch.Size(7, 64)
提示注意力掩码的形状:torch.Size(7, 64)
目标特征的形状:torch.Size(7, 512)
我们的 7 个文本提示现在变成了填充后的 ID 序列(形状 [7, 64]),每个提示都有一个对应的 注意力掩码(也是 [7, 64])和一个目标 图像特征向量(形状 [7, 512])。
现在是时候训练模型,使其能够将文本描述映射到图像特征了。
我们将使用 AdamW 优化器,确保它包括新输出层 (text_to_image_feature_layer) 的参数。损失函数是 均方误差(MSE),适用于比较预测的 512 维特征向量与目标 512 维特征向量。
python
# --- 收集可训练的参数 ---
# (收集文本组件和 text_to_image_feature_layer 的参数 - 省略代码)
all_trainable_parameters_t2i = list(token_embedding_table.parameters())
for i in range(n_layers):
all_trainable_parameters_t2i.extend(list(layer_norms_1[i].parameters()))
# ... 扩展其他层的参数 ...
all_trainable_parameters_t2i.extend(list(final_layer_norm.parameters()))
all_trainable_parameters_t2i.extend(list(text_to_image_feature_layer.parameters())) # 新层
# --- 定义优化器 ---
optimizer = optim.AdamW(all_trainable_parameters_t2i, lr=learning_rate)
print(f" 定义了优化器:AdamW,学习率={learning_rate}")
print(f" 管理 {len(all_trainable_parameters_t2i)} 个参数组/张量。")
# --- 定义损失函数 ---
criterion = nn.MSELoss() # 均方误差
print(f" 定义了损失函数:{type(criterion).__name__}")输出结果
定义的优化器和损失函数
定义了优化器:AdamW,学习率=0.0001
管理 38 个参数组/张量。
定义了损失函数:MSELoss
优化器已经设置好,现在管理着 38 个参数组(因为我们用新的图像特征输出层替换了旧的文本输出层)。
我们迭代地将文本提示输入模型,并训练它输出与目标特征向量接近的特征向量。
- 获取批次:采样提示、掩码和目标特征。
- 前向传播 :将提示通过 Transformer 块处理。从最终层归一化的输出中取出最后一个实际标记的隐藏状态。将此单个状态通过
text_to_image_feature_layer以预测图像特征向量。 - 计算损失:计算预测特征向量与目标特征向量之间的 MSE 损失。
python
t2i_losses = []
# (将层设置为训练模式 - 省略代码)
token_embedding_table.train()
# ... 将其他层设置为训练模式 ...
final_layer_norm.train()
text_to_image_feature_layer.train() # 训练新层
for epoch in range(epochs):
# --- 1. 批次选择 ---
indices = torch.randint(0, num_sequences_available, (batch_size,))
xb_prompt_ids = all_prompt_input_ids[indices].to(device)
batch_prompt_masks = all_prompt_attention_masks[indices].to(device)
yb_target_features = all_target_features[indices].to(device)
# --- 2. 前向传播 ---
B, T = xb_prompt_ids.shape
C = d_model
# 嵌入 + 位置编码
token_embed = token_embedding_table(xb_prompt_ids)
pos_enc_slice = positional_encoding[:, :T, :]
x = token_embed + pos_enc_slice
# Transformer 块(使用组合掩码)
# (注意力掩码计算 - 省略代码)
padding_mask_expanded = batch_prompt_masks.unsqueeze(1).unsqueeze(2)
combined_attn_mask = causal_mask[:,:,:T,:T] * padding_mask_expanded
for i in range(n_layers):
# (MHA 和 FFN 前向传播 - 省略代码)
x_input_block = x
x_ln1 = layer_norms_1[i](x_input_block)
# ... MHA 逻辑 ...
attention_weights = F.softmax(attn_scores.masked_fill(combined_attn_mask == 0, float('-inf')), dim=-1)
attention_weights = torch.nan_to_num(attention_weights)
# ... 完成 MHA ...
x = x_input_block + mha_output_linears[i](attn_output) # 残差 1
# ... FFN 逻辑 ...
x = x_input_ffn + ffn_linear_2[i](F.relu(ffn_linear_1[i](layer_norms_2[i](x_input_ffn)))) # 残差 2
# 最终层归一化
final_norm_output = final_layer_norm(x)
# 选择最后一个非填充标记的隐藏状态
last_token_indices = torch.sum(batch_prompt_masks, 1) - 1
last_token_indices = torch.clamp(last_token_indices, min=0)
batch_indices = torch.arange(B, device=device)
last_token_hidden_states = final_norm_output[batch_indices, last_token_indices, :]
# 投影到图像特征维度
predicted_image_features = text_to_image_feature_layer(last_token_hidden_states) # (B, vision_feature_dim)
# --- 3. 计算损失 ---
loss = criterion(predicted_image_features, yb_target_features) # MSE 损失
# --- 4. 清零梯度 ---
optimizer.zero_grad()
# --- 5. 反向传播 ---
# (如果损失有效,则进行反向传播 - 省略代码)
if not torch.isnan(loss) and not torch.isinf(loss):
loss.backward()
# --- 6. 更新参数 ---
optimizer.step()
else:
loss = None
# --- 日志记录 ---
# (记录损失 - 省略代码)
if loss is not None:
current_loss = loss.item()
t2i_losses.append(current_loss)
if epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" 第 {epoch+1}/{epochs} 个 epoch,MSE 损失:{current_loss:.6f}")
elif epoch % eval_interval == 0 or epoch == epochs - 1:
print(f" 第 {epoch+1}/{epochs} 个 epoch,损失:无效 (NaN/Inf)")
print("--- 文本到图像训练循环完成 ---\n")输出结果
开始文本到图像训练循环...
第 1/5000 个 epoch,MSE 损失:0.880764
第 501/5000 个 epoch,MSE 损失:0.022411
第 1001/5000 个 epoch,MSE 损失:0.006695
第 1501/5000 个 epoch,MSE 损失:0.000073
第 2001/5000 个 epoch,MSE 损失:0.000015
第 2501/5000 个 epoch,MSE 损失:0.000073
第 3001/5000 个 epoch,MSE 损失:0.000002
第 3501/5000 个 epoch,MSE 损失:0.000011
第 4001/5000 个 epoch,MSE 损失:0.000143
第 4501/5000 个 epoch,MSE 损失:0.000013
第 5000/5000 个 epoch,MSE 损失:0.000030
--- 文本到图像训练循环完成 ---
再次强调,MSE 损失迅速降低,表明模型在快速学习将简单的文本提示映射到目标图像的特征向量。接近零的损失表明它几乎完美地预测了训练样本中预期的特征向量。
使用文本提示生成图像
让我们看看模型对新的提示 "a blue square shape" 预测的图像特征向量是什么。
让我们对测试输入提示进行分词和填充。
python
# --- 输入提示 ---
generation_prompt_text = "a blue square shape"
print(f"输入提示:'{generation_prompt_text}'")
# --- 对提示进行分词和填充 ---
# (分词和填充逻辑 - 省略代码)
gen_prompt_ids_no_pad = [char_to_int.get(ch, pad_token_id) for ch in generation_prompt_text]
gen_current_len = len(gen_prompt_ids_no_pad)
gen_pad_len = block_size - gen_current_len
if gen_pad_len < 0:
gen_prompt_ids = gen_prompt_ids_no_pad[:block_size]
gen_pad_len = 0
gen_current_len = block_size
else:
gen_prompt_ids = gen_prompt_ids_no_pad + ([pad_token_id] * gen_pad_len)
# --- 创建注意力掩码 ---
gen_attention_mask = ([1] * gen_current_len) + ([0] * gen_pad_len)
# --- 转换为张量 ---
xb_gen_prompt_ids = torch.tensor([gen_prompt_ids], dtype=torch.long, device=device)
batch_gen_prompt_masks = torch.tensor([gen_attention_mask], dtype=torch.long, device=device)
print(f"准备好的提示张量形状:{xb_gen_prompt_ids.shape}")
print(f"准备好的掩码张量形状:{batch_gen_prompt_masks.shape}")输出结果
输入提示:'a blue square shape'
准备好的提示张量形状:torch.Size(1, 64)
准备好的掩码张量形状:torch.Size(1, 64)
提示 "a blue square shape" 已准备好为一个填充后的张量。现在我们对训练过的文本到图像模型进行前向传播。
python
print("\n第 4.2 步:生成图像特征向量...")
# --- 将模型设置为评估模式 ---
# (将层设置为评估模式 - 省略代码)
token_embedding_table.eval()
# ... 将其他层设置为评估模式 ...
final_layer_norm.eval()
text_to_image_feature_layer.eval() # 评估输出层
# --- 前向传播 ---
with torch.no_grad():
# (嵌入、位置编码、Transformer 块 - 省略代码)
B_gen, T_gen = xb_gen_prompt_ids.shape
C_gen = d_model
token_embed_gen = token_embedding_table(xb_gen_prompt_ids)
pos_enc_slice_gen = positional_encoding[:, :T_gen, :]
x_gen = token_embed_gen + pos_enc_slice_gen
padding_mask_expanded_gen = batch_gen_prompt_masks.unsqueeze(1).unsqueeze(2)
combined_attn_mask_gen = causal_mask[:,:,:T_gen,:T_gen] * padding_mask_expanded_gen
for i in range(n_layers):
# ... MHA 和 FFN 前向传播 ...
x_input_block_gen = x_gen
x_ln1_gen = layer_norms_1[i](x_input_block_gen)
# ... MHA 逻辑 ...
x_gen = x_input_block_gen + mha_output_linears[i](attn_output_gen)
# ... FFN 逻辑 ...
x_gen = x_input_ffn_gen + ffn_linear_2[i](F.relu(ffn_linear_1[i](layer_norms_2[i](x_input_ffn_gen))))
# 最终层归一化
final_norm_output_gen = final_layer_norm(x_gen)
# 选择隐藏状态
last_token_indices_gen = torch.sum(batch_gen_prompt_masks, 1) - 1
last_token_indices_gen = torch.clamp(last_token_indices_gen, min=0)
batch_indices_gen = torch.arange(B_gen, device=device)
last_token_hidden_states_gen = final_norm_output_gen[batch_indices_gen, last_token_indices_gen, :]
# 投影到图像特征维度
predicted_feature_vector = text_to_image_feature_layer(last_token_hidden_states_gen)
print(f"生成了预测的特征向量,形状:{predicted_feature_vector.shape}")输出结果
生成图像特征向量...
生成了预测的特征向量,形状:torch.Size(1, 512)
模型处理了提示,并输出了一个形状为 512 的向量,表示对 "a blue square shape" 的图像特征预测。
现在我们预测的图像来自我们的文本提示:

生成的图像
成功了!模型预测了一个特征向量用于 "a blue square shape",并且当我们比较这个预测与我们已知图像的特征时,最接近的匹配项确实是蓝色正方形。
欧几里得距离(4.84)表明预测的向量与实际蓝色正方形的特征向量有多相似。
出用fareedkhandev