深度学习中的优化算法详解
优化算法是深度学习的核心组成部分,用于最小化损失函数以更新神经网络的参数。本文将详细介绍深度学习中常用的优化算法,包括其概念、数学公式、代码示例、实际案例以及图解,帮助读者全面理解优化算法的原理与应用。
一、优化算法的基本概念
在深度学习中,优化算法的目标是通过迭代更新模型参数 θ \theta θ,最小化损失函数 L ( θ ) L(\theta) L(θ)。损失函数通常表示为:
L ( θ ) = 1 N ∑ i = 1 N l ( f ( x i ; θ ) , y i ) L(\theta) = \frac{1}{N} \sum_{i=1}^N l(f(x_i; \theta), y_i) L(θ)=N1∑i=1Nl(f(xi;θ),yi)
其中:
- f ( x i ; θ ) f(x_i; \theta) f(xi;θ):模型对输入 x i x_i xi 的预测;
- y i y_i yi:真实标签;
- l l l:单个样本的损失(如均方误差或交叉熵);
- N N N:样本数量。
优化算法通过计算梯度 ∇ θ L ( θ ) \nabla_\theta L(\theta) ∇θL(θ),按照一定规则更新参数 θ \theta θ,以逼近损失函数的最优解。
二、常见优化算法详解
以下是深度学习中常用的优化算法,逐一分析其原理、公式、优缺点及代码实现。
1. 梯度下降(Gradient Descent, GD)
概念
梯度下降通过计算整个训练集的梯度来更新参数,公式为:
θ t + 1 = θ t − η ∇ θ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta L(\theta_t) θt+1=θt−η∇θL(θt)
其中:
- η \eta η:学习率,控制步长;
- ∇ θ L ( θ t ) \nabla_\theta L(\theta_t) ∇θL(θt):损失函数对参数的梯度。
优缺点
- 优点:全局梯度信息准确,适合简单凸优化问题。
- 缺点:计算全量梯度开销大,速度慢,易陷入局部极小值。
代码示例
python
import numpy as np
# 模拟损失函数 L = (theta - 2)^2
def loss_function(theta):
return (theta - 2) ** 2
def gradient(theta):
return 2 * (theta - 2)
# 梯度下降
theta = 0.0 # 初始参数
eta = 0.1 # 学习率
for _ in range(100):
grad = gradient(theta)
theta -= eta * grad
print(f"优化后的参数: {theta}") # 接近 2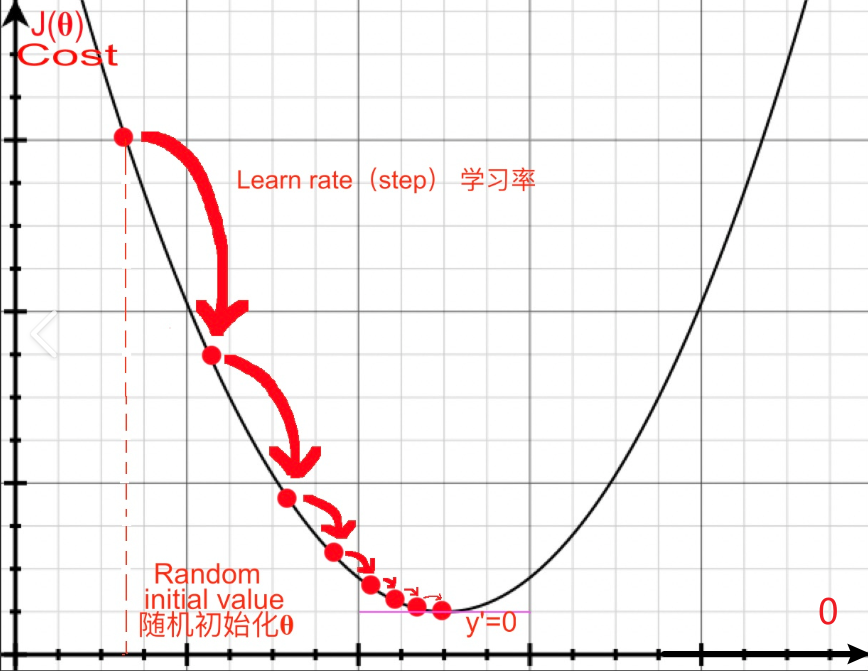
参数沿梯度方向逐步逼近损失函数的最优解。*
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
概念
SGD 每次仅基于单个样本计算梯度,更新公式为:
θ t + 1 = θ t − η ∇ θ l ( f ( x i ; θ t ) , y i ) \theta_{t+1} = \theta_t - \eta \nabla_\theta l(f(x_i; \theta_t), y_i) θt+1=θt−η∇θl(f(xi;θt),yi)
优缺点
- 优点:计算效率高,适合大规模数据集,随机性有助于逃离局部极小值。
- 缺点:梯度噪声大,收敛路径不稳定。
代码示例
python
# 模拟 SGD
np.random.seed(42)
data = np.random.randn(100, 2) # 模拟数据
labels = data[:, 0] * 2 + 1 # 模拟标签
theta = np.zeros(2) # 初始参数
eta = 0.01
for _ in range(100):
i = np.random.randint(0, len(data))
x, y = data[i], labels[i]
grad = -2 * (y - np.dot(theta, x)) * x # 均方误差梯度
theta -= eta * grad
print(f"优化后的参数: {theta}")SGD 的更新路径波动较大,但整体趋向最优解。*
3. 小批量梯度下降(Mini-Batch Gradient Descent)
概念
Mini-Batch GD 结合 GD 和 SGD 的优点,使用小批量样本计算梯度:
θ t + 1 = θ t − η 1 B ∑ i ∈ batch ∇ θ l ( f ( x i ; θ t ) , y i ) \theta_{t+1} = \theta_t - \eta \frac{1}{B} \sum_{i \in \text{batch}} \nabla_\theta l(f(x_i; \theta_t), y_i) θt+1=θt−ηB1∑i∈batch∇θl(f(xi;θt),yi)
其中 B B B 为批量大小。
优缺点
- 优点:平衡了计算效率和梯度稳定性,广泛应用于深度学习框架。
- 缺点:批量大小需调优,学习率敏感。
代码示例
python
import torch
# 模拟数据
X = torch.randn(100, 2)
y = X[:, 0] * 2 + 1
theta = torch.zeros(2, requires_grad=True)
optimizer = torch.optim.SGD([theta], lr=0.01)
# Mini-Batch GD
batch_size = 16
for _ in range(100):
indices = torch.randperm(100)[:batch_size]
batch_X, batch_y = X[indices], y[indices]
pred = batch_X @ theta
loss = ((pred - batch_y) ** 2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"优化后的参数: {theta}")4. 动量法(Momentum)
概念
动量法通过引入速度项 v t v_t vt,加速梯度下降,公式为:
v t + 1 = μ v t + ∇ θ L ( θ t ) v_{t+1} = \mu v_t + \nabla_\theta L(\theta_t) vt+1=μvt+∇θL(θt)
θ t + 1 = θ t − η v t + 1 \theta_{t+1} = \theta_t - \eta v_{t+1} θt+1=θt−ηvt+1
其中 μ \mu μ 为动量系数(通常为 0.9)。
优缺点
- 优点:加速收敛,减少震荡。
- 缺点:超参数需调优,可能超调。
代码示例
python
# 动量法
theta = 0.0
v = 0.0
eta, mu = 0.1, 0.9
for _ in range(100):
grad = gradient(theta)
v = mu * v + grad
theta -= eta * v
print(f"优化后的参数: {theta}")动量法通过累积速度平滑更新路径。*
5. Adam(Adaptive Moment Estimation)
概念
Adam 结合动量法和自适应学习率,通过一阶动量(均值)和二阶动量(方差)更新参数:
m t + 1 = β 1 m t + ( 1 − β 1 ) ∇ θ L ( θ t ) m_{t+1} = \beta_1 m_t + (1 - \beta_1) \nabla_\theta L(\theta_t) mt+1=β1mt+(1−β1)∇θL(θt)
v t + 1 = β 2 v t + ( 1 − β 2 ) ( ∇ θ L ( θ t ) ) 2 v_{t+1} = \beta_2 v_t + (1 - \beta_2) (\nabla_\theta L(\theta_t))^2 vt+1=β2vt+(1−β2)(∇θL(θt))2
m ^ t + 1 = m t + 1 1 − β 1 t + 1 , v ^ t + 1 = v t + 1 1 − β 2 t + 1 \hat{m}{t+1} = \frac{m{t+1}}{1 - \beta_1^{t+1}}, \quad \hat{v}{t+1} = \frac{v{t+1}}{1 - \beta_2^{t+1}} m^t+1=1−β1t+1mt+1,v^t+1=1−β2t+1vt+1
θ t + 1 = θ t − η m ^ t + 1 v ^ t + 1 + ϵ \theta_{t+1} = \theta_t - \eta \frac{\hat{m}{t+1}}{\sqrt{\hat{v}{t+1}} + \epsilon} θt+1=θt−ηv^t+1 +ϵm^t+1
其中:
- β 1 = 0.9 \beta_1 = 0.9 β1=0.9, β 2 = 0.999 \beta_2 = 0.999 β2=0.999;
- ϵ = 1 0 − 8 \epsilon = 10^{-8} ϵ=10−8,防止除零。
优缺点
- 优点:自适应学习率,收敛快,适合复杂模型。
- 缺点:可能过早收敛到次优解。
代码示例
python
import torch.optim as optim
# 使用 PyTorch 的 Adam
model = torch.nn.Linear(2, 1)
optimizer = optim.Adam(model.parameters(), lr=0.001)
for _ in range(100):
pred = model(X)
loss = ((pred - y) ** 2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"优化后的参数: {model.weight}")Adam 通过自适应步长快速逼近最优解。*
三、实际案例:优化神经网络
任务
使用 PyTorch 训练一个简单的二分类神经网络,比较 SGD 和 Adam 的性能。
代码实现
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 生成模拟数据
X = torch.randn(1000, 2)
y = (X[:, 0] + X[:, 1] > 0).float().reshape(-1, 1)
# 定义模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Linear(2, 1)
def forward(self, x):
return torch.sigmoid(self.fc(x))
# 训练函数
def train(model, optimizer, epochs=100):
criterion = nn.BCELoss()
losses = []
for _ in range(epochs):
pred = model(X)
loss = criterion(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
return losses
# 比较 SGD 和 Adam
model_sgd = Net()
model_adam = Net()
optimizer_sgd = optim.SGD(model_sgd.parameters(), lr=0.01)
optimizer_adam = optim.Adam(model_adam.parameters(), lr=0.001)
losses_sgd = train(model_sgd, optimizer_sgd)
losses_adam = train(model_adam, optimizer_adam)
# 绘制损失曲线
plt.plot(losses_sgd, label="SGD")
plt.plot(losses_adam, label="Adam")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.show()结果分析
Adam 通常比 SGD 收敛更快,损失下降更平稳,但在某些任务中 SGD 配合动量可能获得更好的泛化性能。
四、优化算法选择建议
- 小型数据集:SGD + 动量,简单且泛化能力强。
- 复杂模型(如深度神经网络):Adam 或其变体(如 AdamW),收敛速度快。
- 超参数调优 :
- 学习率:尝试 1 0 − 3 10^{-3} 10−3 到 1 0 − 5 10^{-5} 10−5;
- 批量大小:16、32 或 64;
- 动量系数:0.9 或 0.99。
五、总结
优化算法是深度学习训练的基石,从简单的梯度下降到自适应的 Adam,每种算法都有其适用场景。通过理解其数学原理、代码实现和实际表现,开发者可以根据任务需求选择合适的优化策略。