概述
平均精度均值(mAP)是目标检测领域中最为流行且复杂的重要评估指标之一。它广泛用于综合总结目标检测器的性能。许多目标检测模型会输出类似以下的参数结果:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.309
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.519
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.327
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.173
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.462
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.547
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.297
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.511
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.376
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.686
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.686这是 COCO 数据集的 mAP 版本(或他们称之为 AP)。但这些数字到底是什么意思?这些符号又代表什么呢?
一、如何选择目标检测器
当衡量目标检测器的质量时,主要想评估两个标准:
- 模型是否正确预测了目标的类别。
- 预测的边界框是否足够接近真实框。
当将两者结合起来时,事情开始变得复杂。与其他机器学习任务(如分类)相比,目标检测没有一个明确的"正确预测"的定义。这在边界框标准中尤为明显。
如下面的图像,可以看出正确与不正确检测框的区别:

在目标检测领域,决策的制定往往充满挑战,尤其是在面对复杂多变的评估需求时。目标检测器的性能评估并非一成不变,其表现可能因目标的大小而异。例如,某些检测器在处理大型目标时表现出色,但在检测小型目标时却显得力不从心;而另一些检测器虽然在整体性能上并不突出,但在小型目标的检测上却具有独特的优势。此外,模型同时检测到的目标数量也是一个重要的考量因素。这些因素相互交织,使得评估过程变得异常复杂。
COCO评估指标的出现,正是为了解决这一难题。它提供了一套标准化的评估体系,能够在多种已确立的场景下,全面衡量目标检测器的性能。COCO评估指标不仅关注目标检测的准确性,还综合考虑了检测器在不同目标大小下的表现,以及模型同时检测到的目标数量等多个维度。通过这种多维度的评估方式,COCO评估指标能够更准确地反映目标检测器在实际应用中的表现。
值得注意的是,COCO评估指标的应用范围远不止于目标检测。它还涵盖了分割、关键点检测等多个领域,为这些领域的研究提供了统一的评估标准。然而,这些内容已经超出了当前讨论的范畴,值得在后续的研究中进一步深入探讨。
二、交并比
理解 mAP 的旅程从 IoU 开始。交并比(Intersection over Union) 是衡量两个边界框对齐程度的一种方法。它通常用于衡量预测框与真实框的质量。
正如其名称所示,IoU 定义为两个框的交集除以它们的并集:
I o U = A ∩ B A ∪ B IoU = \frac{A \cap B}{A \cup B} IoU=A∪BA∩B
从图上来看,交集和并集可以理解为:

左:原始预测。中:并集。右:交集。
在目标检测任务中,评估预测框与真实框之间的匹配程度是一个关键的指标。这正是交并比(Intersection over Union,IoU)发挥作用的地方。IoU 是通过计算预测框与真实框的交集面积与它们的并集面积之比来定义的。这个比值提供了一个介于 0 和 1 之间的数值,用以衡量两个框之间的重叠程度。
首先,我们来分析一下 IoU 公式的几个关键点:
- 并集与交集的关系:并集总是大于或等于交集。这是因为并集包含了两个框中所有的点,而交集只包含两个框共有的点。
- 非重叠情况:如果两个框不重叠,它们的交集将为零。在这种情况下,IoU 的值将为 0,表示两个框之间没有重叠。
- 完美重叠情况:如果两个框完美重叠,它们的交集将与并集相等。在这种情况下,IoU 的值将为 1,表示两个框完全匹配。
- IoU 的取值范围:IoU 总是一个介于 0 和 1 之间的值,包括 0 和 1。这个范围内的值表示了两个框之间重叠程度的大小。
- IoU 的优化目标:在目标检测任务中,IoU 越大越好。一个高的 IoU 值意味着预测框与真实框之间的重叠程度更高,这通常表示模型的预测更加准确。
除了 IoU,有时可能会听到 Jaccard Index 或 Jaccard Similarity 这两个术语。在目标检测的上下文中,它们与 IoU 是相同的。Jaccard Index 是一种更通用的数学形式,用于比较两个有限集之间的相似性。它通过计算两个集合交集的大小与它们并集的大小之比来定义。在目标检测中,我们通常将预测框和真实框视为两个集合,因此 IoU 和 Jaccard Index 在这种情况下是等价的。
IoU 是一个重要的评估指标,用于衡量目标检测模型的预测准确性。通过计算预测框与真实框之间的交集与并集之比,IoU 提供了一个介于 0 和 1 之间的数值,用以表示两个框之间的重叠程度。一个高的 IoU 值通常表示模型的预测更加准确。
在 Python 中,IoU 可以这样计算:
python
def iou(bbox_a, bbox_b):
ax1, ay1, ax2, ay2 = bbox_a
bx1, by1, bx2, by2 = bbox_b
# 计算交集的坐标
ix1 = max(ax1, bx1)
iy1 = max(ay1, by1)
ix2 = min(ax2, bx2)
iy2 = min(ay2, by2)
# 计算交集矩形的面积
intersection = max(0, ix2 - ix1) * max(0, iy2 - iy1)
# 计算两个边界框的面积
box1_area = (ax2 - ax1) * (ay2 - ay1)
box2_area = (bx2 - bx1) * (by2 - by1)
# 最后计算两个面积的并集
union = box1_area + box2_area - intersection
return intersection / unionIoU 的值介于 0 和 1 之间,其中 1 表示完美匹配,0 表示没有重叠。但是,我们需要确定一个阈值,当 IoU 低于这个阈值时,我们就会认为预测是不准确的,从而放弃这个预测。
三、IoU 作为检测阈值
再看看猫的预测示例。很明显,最右边的那个是错误的,而左边的那个是可以接受的。我们的大脑是如何如此快速地做出这个决定的呢?中间的那个呢?如果我们比较模型的性能,我们不能让这个决定主观化。

3.1 IoU 作为阈值的定义与应用
IoU(交并比)不仅可以衡量预测边界框与真实框的匹配程度,还可以作为阈值来决定是否接受一个预测。在目标检测领域,IoU 阈值的设定是评估模型性能的关键因素之一。
具体来说,当 IoU 阈值被指定为 IoU@0.5 时,这意味着只有当预测框与真实框的 IoU 大于或等于 0.5(即 50%)时,该预测框才被视为正确匹配。换句话说,如果预测框与真实框的重叠面积不足 50%,则认为该预测是不准确的,从而被舍弃。
3.2 常见的 IoU 阈值及其含义
在学术文献和实际应用中,常见的 IoU 阈值包括:
- IoU@0.5:这是最常用的阈值,表示预测框与真实框的重叠面积至少为 50% 时,预测才被视为正确。
- IoU@0.75:这是一个更高的阈值,要求预测框与真实框的重叠面积至少为 75%,通常用于评估更严格的匹配标准。
- IoU@0.95:这是一个非常严格的阈值,要求预测框与真实框的重叠面积至少为 95%,通常用于评估模型在极端情况下的性能。
3.3 多个 IoU 阈值的表示方法
除了单一的 IoU 阈值,有时我们还会遇到表示多个阈值的表达式,例如 IoU@0.5:0.05:0.95。这个表达式表示从 0.5 到 0.95,以 0.05 为步长的所有 IoU 阈值。具体来说,它涵盖了以下 10 个不同的 IoU 阈值:
- IoU@0.5
- IoU@0.55
- IoU@0.6
- IoU@0.65
- IoU@0.7
- IoU@0.75
- IoU@0.8
- IoU@0.85
- IoU@0.9
- IoU@0.95
这种表示方法在 COCO 数据集的评估中非常流行,因为它能够全面评估模型在不同严格程度下的性能。通过计算模型在这些不同阈值下的平均性能(如平均精度,AP),可以更全面地反映模型的鲁棒性和准确性。
3.4 关于简写和默认值
在目标检测的文献中,作者有时会省略步长,简单地写成 IoU@0.5:0.95。虽然这种简写可能会引起一些混淆,但通常可以推断出作者指的是从 0.5 到 0.95,步长为 0.05 的 10 个 IoU 阈值。
此外,当评估目标检测器时,如果作者没有明确指定 IoU 阈值,通常默认为 IoU=0.5。这是因为 IoU@0.5 是最常用的标准,能够提供一个基本的性能评估。
四、真正例、假正例、真负例和假负例
接下来需要理解的概念是 TP(真正例)、FP(假正例)、TN(真负例)和 FN(假负例)。这些术语是从二元分类任务中借来的。下表是一个假设的苹果分类器的总结:
| Object | Prediction | Category | Explanation |
|---|---|---|---|
| 🍎 | ✅ | TP | 该物体被正确分类为苹果。 |
| 🍌 | ✅ | FP | 该物体被错误地分类为苹果。 |
| 🍎 | ❌ | FN | 该物体被错误地分类为非苹果。 |
| 🍌 | ❌ | TN | 该物体被正确分类为非苹果。 |
一个好的分类器会有大量的真正例和真负例,同时尽量减少假正例和假负例。
4.1 多类分类器
上面提到的概念并不完全适用于多类分类器。二元分类器回答的是"这个对象是否属于这个类别?"而多类分类器回答的是"这个对象属于这些类别中的哪一个?"幸运的是,我们可以使用"一对一"或"一对多"的方法将其扩展。想法很简单:我们分别评估每个类别,并将其视为一个二元分类器。那么,以下内容成立:
- 正例:正确预测了该类别属于目标对象。
- 负例:预测了其他类别属于目标对象。
以下是从苹果(🍎)类别角度出发的相同总结表。
| Object | Prediction | Category | Explanation |
|---|---|---|---|
| 🍎 | 🍎 | TP | 该物体被正确分类为苹果。 |
| 🍌 | 🍎 | FP | 该物体被错误地分类为苹果。 |
| 🍎 | 🍌 | FN | 该物体被错误地分类为香蕉(即未被正确分类为苹果)。 |
| 🍎 | 🥭 | FN | 该物体被错误地分类为芒果(即未被正确分类为苹果)。 |
在谈论多类模型时,很少使用"真负例"这个术语,但它可以理解为"正确识别为其他类别的样本"。
现在,让我们从香蕉(🍌)的角度做一个类似的练习。
| Object | Prediction | Category | Explanation |
|---|---|---|---|
| 🍌 | 🍌 | TP | 该物体被正确分类为香蕉。 |
| 🍌 | 🍎 | FN | 该物体被错误地分类为苹果(即未被正确分类为香蕉)。 |
| 🍎 | 🍌 | FP | 该物体被错误地分类为香蕉。 |
从苹果类别的角度来看,(🍌,🍎)组合是一个 FP ,但从香蕉类别的角度来看,它是一个 FN 。类似的情况也发生在(🍎,🍌)组合上,它从苹果类别的角度来看是一个 FN ,但从香蕉类别的角度来看是一个 FP。这种重叠是多类模型中预期和典型的!
4.2 应用
剩下的问题是:如何将上述概念应用到目标检测器中?检测器通常是多类分类器,但也有目标定位的因素。幸运的是,我们已经有 IoU 指标可供使用!
在这里,我们可以直接跳到总结。假设 IoU=50%。
真正例(True Positive)
- 预测边界框与真实框的 IoU 高于 50%。并且
- 预测类别与真实类别匹配。
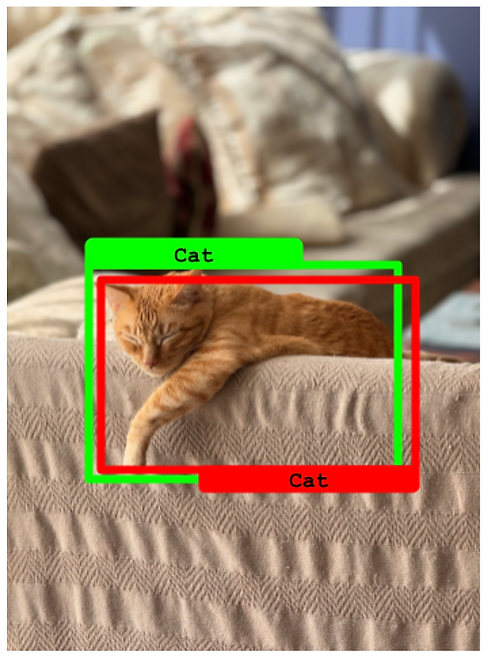
目标检测中的真正例示例。
假正例(False Positive)
- 预测边界框与真实框的 IoU 低于 50% 或者
- 没有对应的真实框 或者
- 预测类别与真实类别不匹配。

目标检测中的假正例示例。左:IoU 低于 50%。中:缺少真实框。右:错误的类别。
假负例(False Negative)
- 每一个没有匹配预测的真实框。
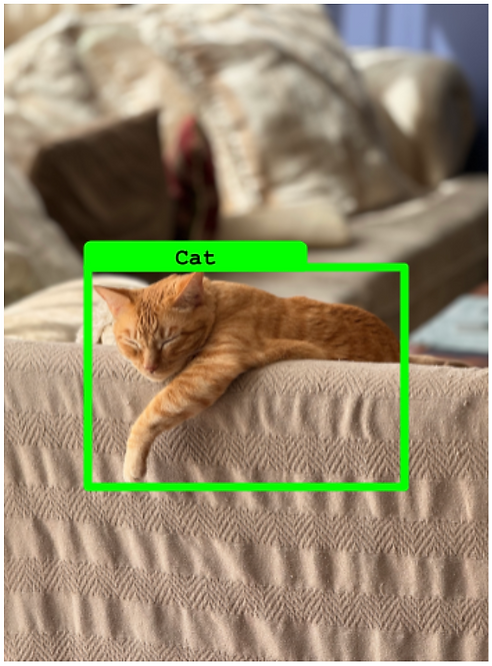
目标检测中的假负例示例(对于某个真实框没有预测)。
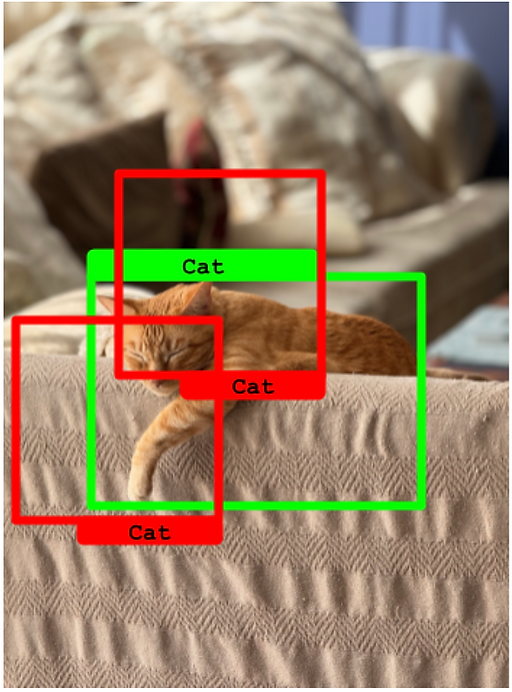
4.3 模糊的例子
在下图中,有两个真实框,但只有一个预测框。在这种情况下,预测框只能归属于其中一个真实框(IoU 超过 50%)。不幸的是,另一个真实框变成了一个 假负例。
预测框只能归属于一个真实框。另一个真实框变成了假负例。
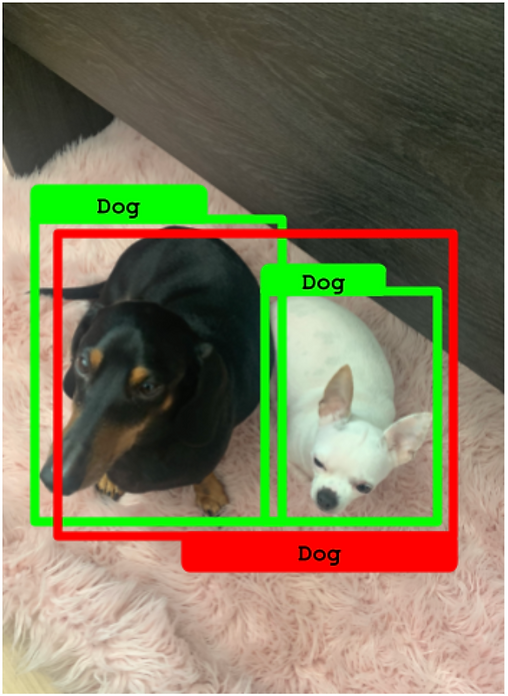
在下一个例子中,对同一个真实框做出了两个预测。然而,这两个预测的 IoU 都低于 50%。在这种情况下,这两个预测都被算作 假正例 ,而孤立的真实框是一个 假负例。
两个预测的 IoU 都低于 50%。它们变成了假正例,而真实框变成了假负例。
在最后一个例子中,我们有一个类似的场景,但两个预测的 IoU 都很好(超过 50%)。在这种情况下,IoU 最好的那个被算作一个 真正例 ,而另一个变成了一个 假正例。
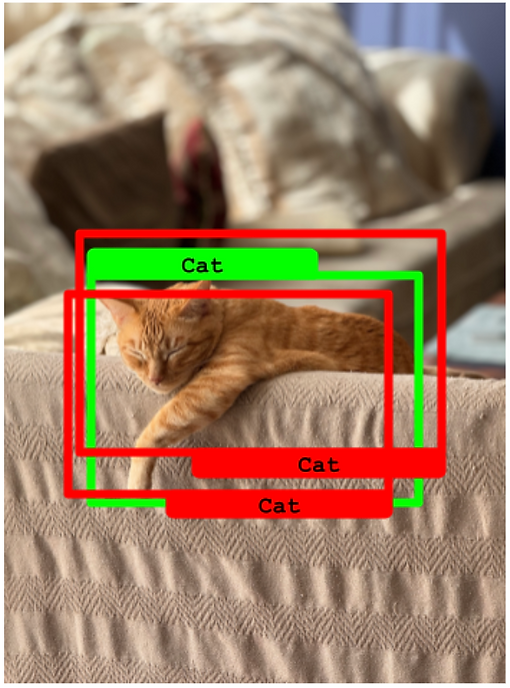
两个预测的 IoU 都超过 50%。一个变成真正例,另一个变成假正例。
五、精确率、召回率和 F1 分数
现在我们知道了如何将 TP、FP、TN 和 FN 应用于目标检测器,我们可以从分类器中借鉴其他指标。这些是 精确率(Precision)、召回率(Recall) 和 F1 分数(F1 Score)。同样,这些指标是按类别衡量的。下表总结了它们:
| 指标 | 公式 | 概念 |
|---|---|---|
| 精确率(Precision) | ( P = \frac{TP}{TP + FP} ) | 对于一个类别所做的所有预测中,实际正确的预测所占的百分比。 |
| 召回率(Recall) | ( R = \frac{TP}{TP + FN} ) | 在一个类别的所有物体中,被正确预测的物体所占的百分比。 |
| F1值(F1) | ( F1 = 2 \cdot \frac{P \cdot R}{P + R} ) | 精确率和召回率的几何平均值。 |
5.1 精确率(Precision)
对于一个给定的类别,精确率告诉我们该类别预测中实际属于该类别的比例是多少。下图显示了一个检测器的结果,其中有 3 个真正例和 1 个假正例,精确率为:
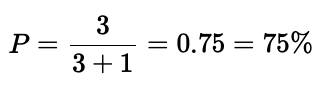

3 个人物,但只有 3 次人物检测。
如果你关心模型不产生假正例,就要关注精确率。例如:错过股市上涨总比错误地将上涨预测为下跌要好。
敏锐的读者可能已经注意到,精确率公式没有考虑假负例。只关注精确率可能会非常误导人。如下例所示:
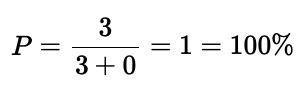

虽然只有 3 次检测,但它们的类别都是正确的,因此精确率是 100%。
正如你所见,精确率指标达到了 100%,但模型表现不佳,因为它有很多假负例。
不要单独测量精确率,因为没有考虑假负例。
5.2 召回率(Recall)
对于一个给定的类别,召回率(或灵敏度)告诉我们实际类别实例中有多少被正确预测了。从同一张图来看,检测器正确预测了 3 个类别实例(真正例),但有 3 个实例完全没有被预测到(假负例):
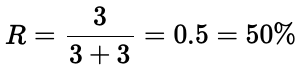

6 个面包中只检测到了 3 个。
如果你希望避免假负例,就要关注召回率。例如:误诊癌症总比错误地将患者预测为健康要好。
同样,可以注意到召回率没有考虑假正例,因此如果单独测量也会误导人:
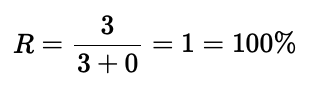
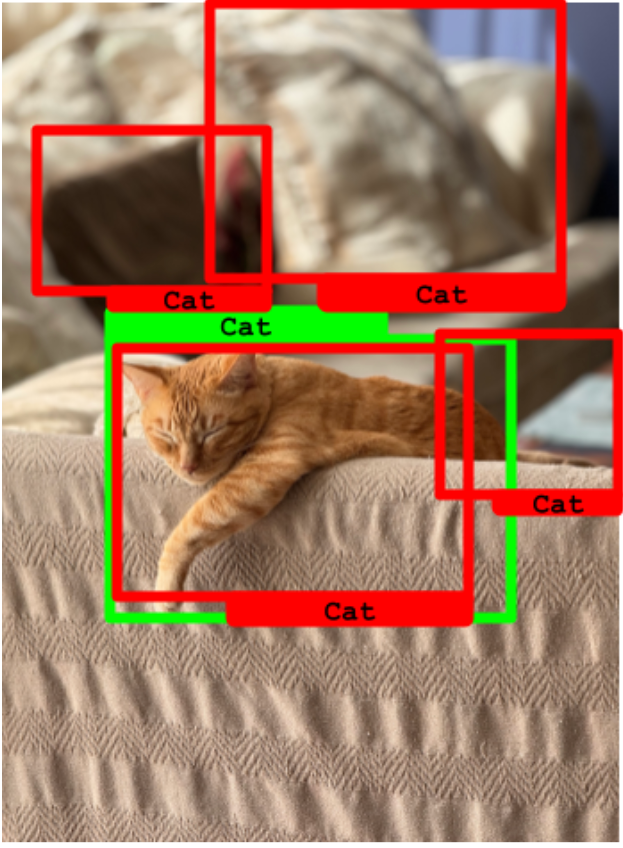
图中的一只猫被成功检测到,但还有 3 个假正例。
正如你所见,召回率指标达到了 100%,但模型表现不佳,因为它有很多假正例。
不要单独测量召回率,因为没有考虑假正例。
5.3 F1 分数(F1 Score)
F 分数或 F1 分数是一个结合了精确率和召回率的指标,为我们提供了一个平衡。再次使用上面的同一张图,模型将返回一个 F1 分数为:
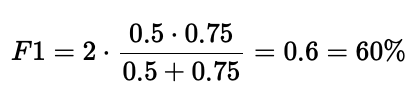
F1 分数衡量了精确率和召回率之间的平衡。
六、PR(精确率 - 召回率)曲线
到目前为止,我们已经看到精确率和召回率描述了模型的不同方面。在某些场景中,拥有更高的精确率更方便,而在其他场景中,拥有更高的召回率更方便。你可以通过调整检测器的目标置信度阈值来调整这些指标。
事实证明,有一种非常方便的方法可以直观地展示模型对特定类别的响应在不同分类阈值下的表现。这就是精确率 - 召回率曲线,如下图所示:
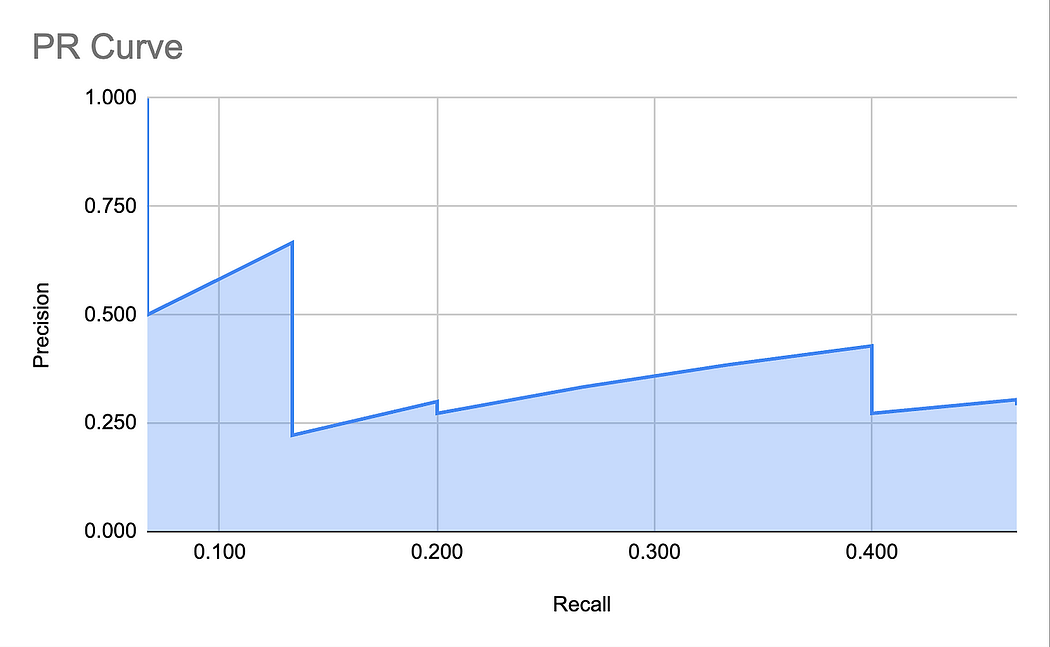
创建 PR 曲线的过程如下:
- 将置信度设置为 1,初始精确率设为 1。召回率将为 0(如果你做数学计算的话)。在曲线上标记这个点。
- 开始降低置信度,直到获得第一次检测。计算精确率和召回率。精确率将再次为 1(因为你没有假正例)。在曲线上标记这个点。
- 继续降低阈值,直到新的检测出现。在曲线上标记这个点。
- 重复上述步骤,直到阈值足够低,使得召回率达到 1。此时,精确率可能在 0.5 左右。
下图展示了在 PR 曲线上评估某些点的阈值。
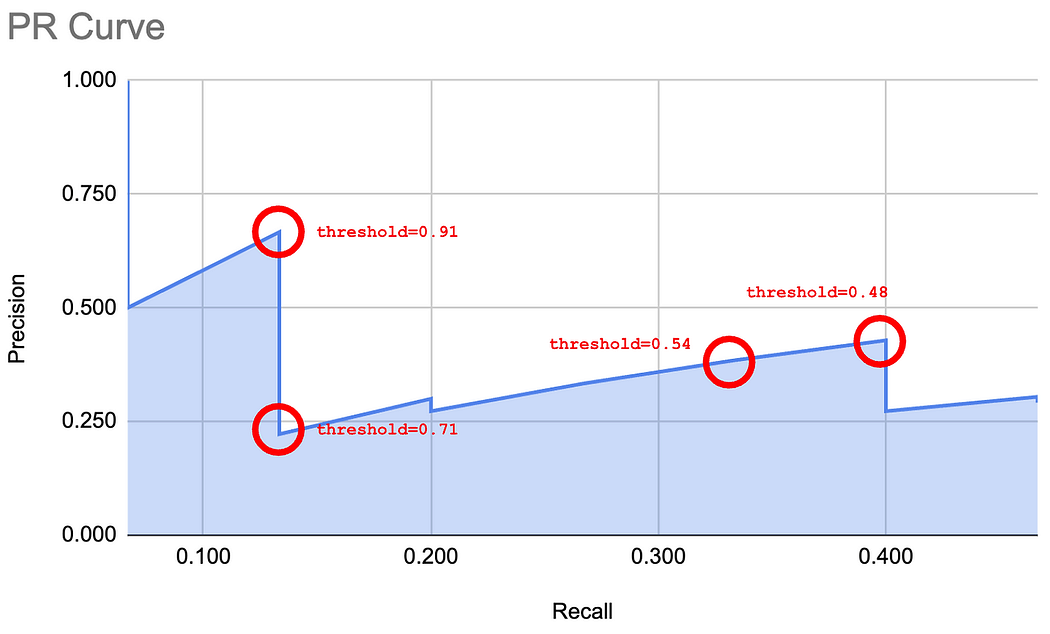
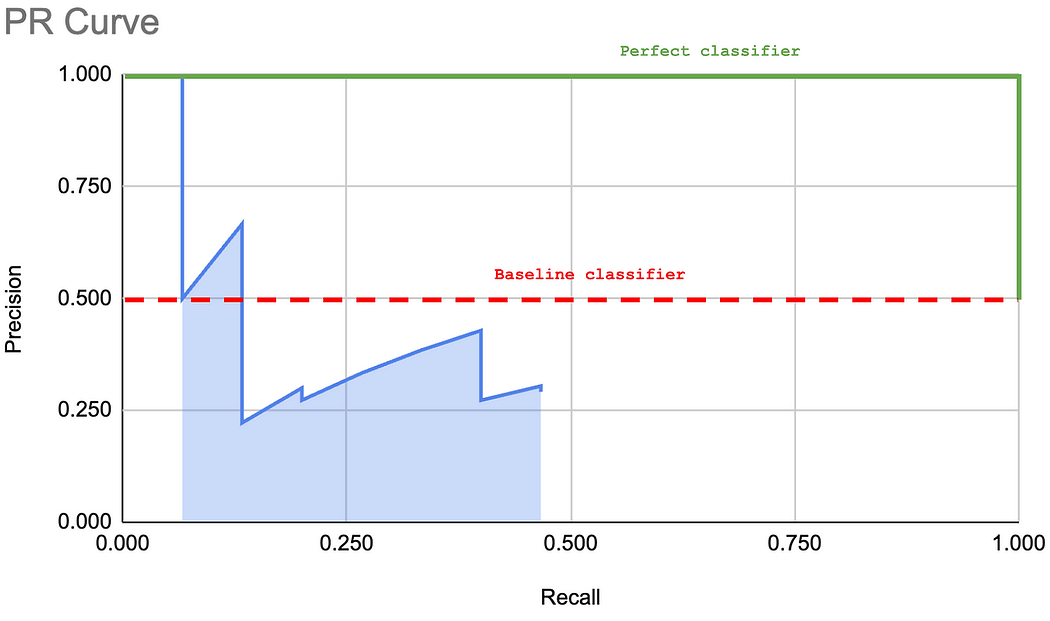
可以看到,这条曲线的形状可以用来描述模型的性能。下图展示了一个"基线"分类器和一个"完美"分类器。分类器越接近"完美"曲线,性能越好。
6.1 实用的 PR 曲线算法
在现实中,有一种更实用的方法来计算 PR 曲线。虽然这可能看起来有些反直觉,但结果与上述步骤相同,只是更适合脚本化:
- 将所有图像的所有预测按置信度从高到低排序。
- 对于每个预测,计算 TP、FP 以及累积的 TP 和 FP 数量(之前所有 TP 和 FP 的总和)。
- 对于每个预测,使用累积的 TP 和 FP 计算精确率和召回率。
- 绘制结果的精确率和召回率的散点图。
下表展示了在包含 15 个对象的小数据集上运行该算法的结果:
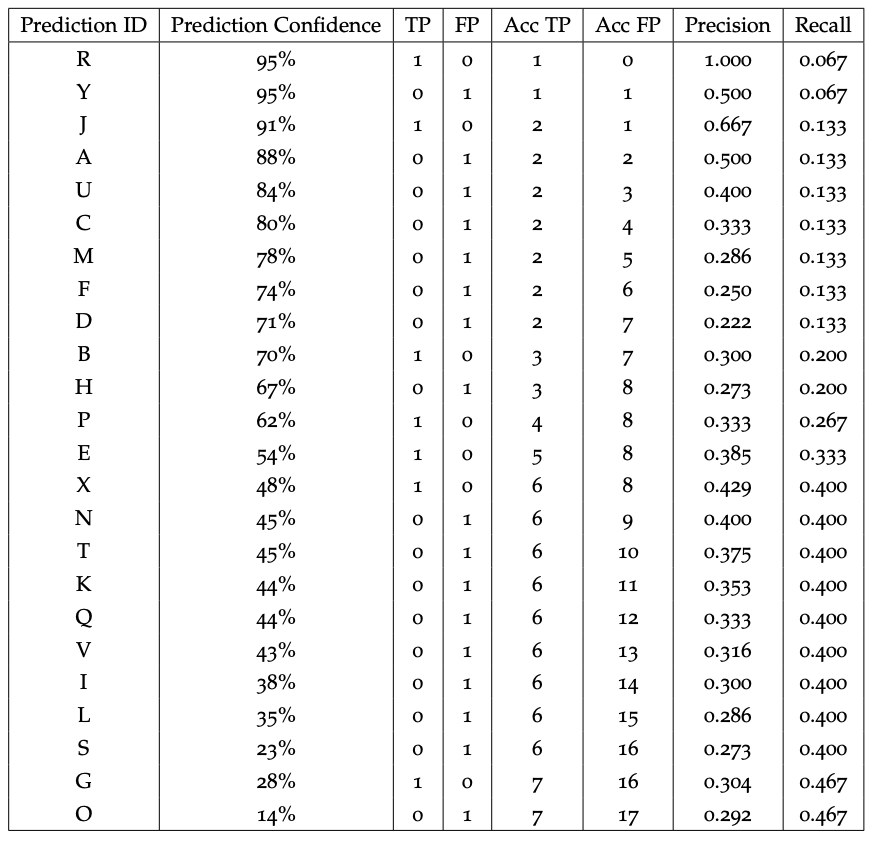
计算 PR 曲线的运行表。来源。
例如,如果我们计算 ID 为 K 的检测的精确率和召回率(记住该数据集有 15 个真实对象,即 TP+FN=15):
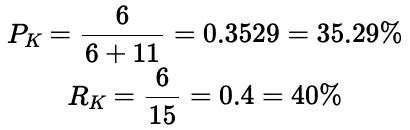
得到的 PR 曲线就是我们之前展示过的那条。为了方便起见,再次展示这个图:
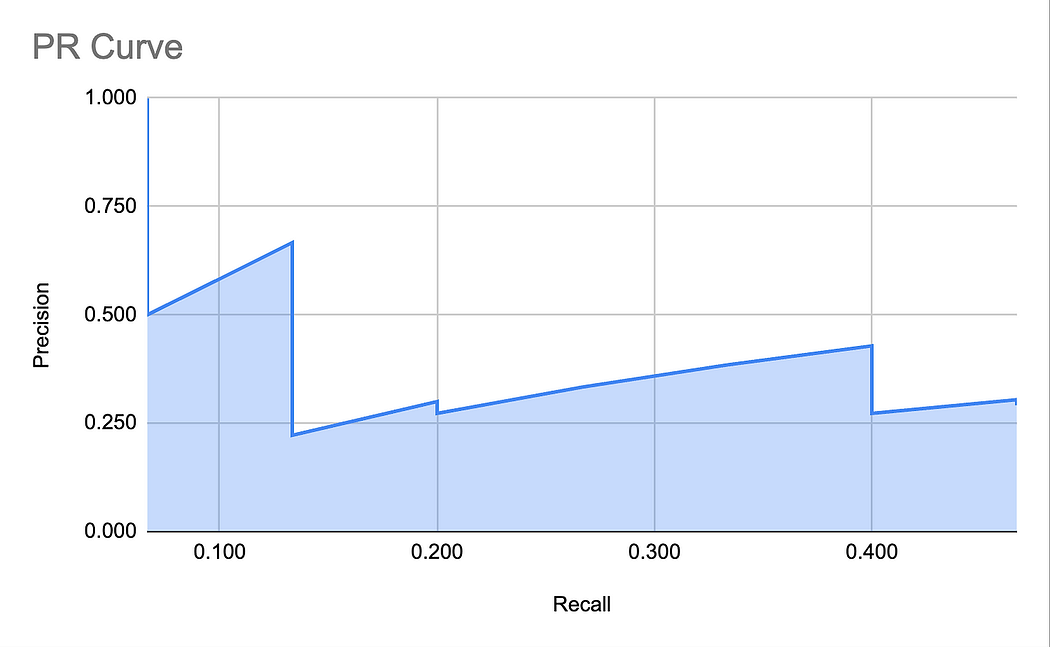
七、AP------平均精确率
到目前为止,我们已经知道如何为每个类别创建 PR 曲线。现在是时候计算平均精确率了。
AP 是 PR 曲线下的面积(AUC)。
然而,正如你可能已经注意到的,PR 曲线的不规则形状和尖峰使得计算这个面积相当困难。因此,COCO 定义了一个 11 点插值,使计算变得更简单。
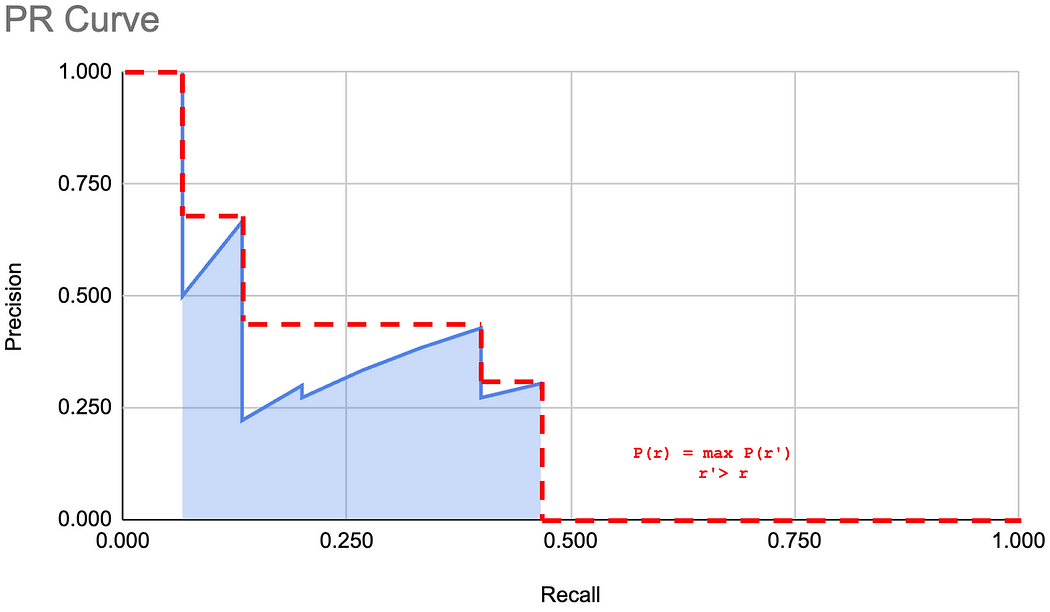
7.1 COCO 11 点插值
对于一个给定的类别 C,11 点插值包括以下三个步骤:
- 定义 11 个等间距的召回率评估点:0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0。
- 对于每个召回率评估点 r ,找到所有召回率 r' >= r 中最高的精确率 p。或者用数学公式表示为:
p ( r ) = max r ′ ≥ r p ( r ′ ) p(r) = \max_{r' \geq r} p(r') p(r)=r′≥rmaxp(r′)
图形化地看,这仅仅是一种从图中去除尖峰的方法,使其看起来像这样:
- 在这些召回率评估点上对获得的精确率取平均值,得到类别 C 的平均精确率 AP_C :
A P C = 1 11 ∑ r ∈ 0.0 , 0.1 , ... , 1.0 p ( r ) AP_C = \frac{1}{11} \sum_{r \in 0.0, 0.1, \\dots, 1.0} p(r) APC=111r∈0.0,0.1,...,1.0∑p(r)
让我们以同一个图表为例,计算 AP。
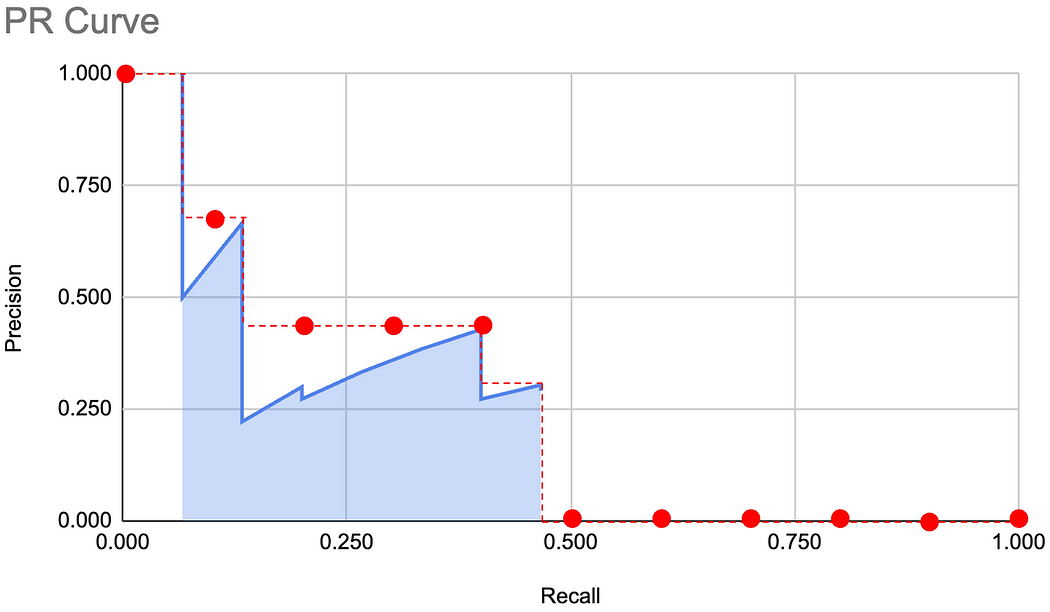
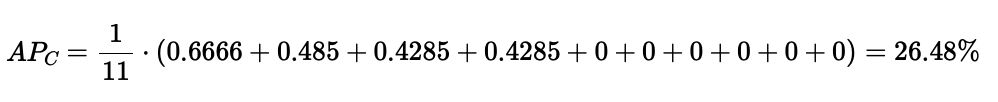
7.2 COCO mAP------平均精度均值
我们终于可以计算 mAP 了,这也是本文的核心指标。在上一节中,我们计算了一个给定类别的 AP。mAP 不过是每个类别的 AP 的平均值。换句话说:
m A P = 1 N ∑ C = 1 N A P C mAP = \frac{1}{N} \sum_{C=1}^{N} AP_C mAP=N1C=1∑NAPC
其中 ( N ) 是类别的总数。
因此,从某种意义上说,mAP 是精确率的平均值的平均值。现在让我们深入了解 COCO 生成的报告的具体内容。
COCO 没有区分 AP 和 mAP,但从概念上讲,它们指的是 mAP。
7.3 不同 IoU 阈值下的 mAP
报告的第一部分如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.309
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.519
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.327让我们先关注 IoU。
- IoU@0.50 和 IoU@0.75 是很简单的。正如在 IoU 部分解释的那样,这些只是在两个不同的 IoU 阈值(分别为 50% 和 75%)下评估的系统。当然,你期望 0.75 的值会低于 0.5,因为它更严格,需要更好的边界框匹配。
- IoU@0.50:0.95 我们已经知道它扩展为 10 个不同的 IoU 阈值:0.5, 0.55, 0.6, ..., 0.95。从这些值中,我们计算每个 IoU 阈值的 mAP 并取平均值。这通常是最严格的指标,因此也是默认的。
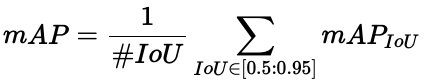
这变成了"平均值的平均值的平均值"!
7.4 不同目标大小的 mAP
报告的下一部分如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.173
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.462
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.547现在我们关注面积部分。这些作为过滤器,用于衡量检测器在不同大小范围的目标上的性能。
- 小目标 的面积范围为 ([0², 32²))。
- 中等目标 的面积范围为 ([32², 96²))。
- 大目标 的面积范围为 ([96², ∞))。
面积以像素为单位,而 (∞) 在实际中被定义为 (1e⁵²)。因此,对于 area=small 的报告,只会考虑面积在指定范围内的目标。
八、AR------平均召回率
最后,除了 mAP(或 AP)之外,COCO 还提供了 AR(平均召回率)。正如你所想象的,计算方法相同,只是从召回率的角度进行评估。除了常规的报告行之外,值得注意的是以下几行:
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.297
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.456
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.511在这里,他们变化了一个 maxDets 参数,它控制了每张图像中可能的检测数量上限,用于进行精确率和召回率的计算。每张图像最多检测 100 个目标听起来可能很多,但要记住,在 PR 曲线中,你会从 0 到 1 变化置信度阈值,而在最低值时,你可能会得到很多假正例。
值得注意的是,maxDets 的变化只在召回率方面才有意义。这是因为精确率衡量的是检测的准确性,而召回率衡量的是模型在数据集中检测所有相关实例的能力,这受到潜在检测数量的影响。
九、COCO 评估 API
现在,希望你已经清楚了不同类型的 mAP 的计算方法,更重要的是,理解了它们的含义。COCO 提供了一个 Python 模块,能够在后台计算所有这些指标,并且实际上是 他们竞赛任务的官方结果呈现方式。
以下是如何使用 COCO 评估 API 的示例:
python
# 下载示例数据集
import requests
import zipfile
from tqdm import tqdm
# 示例模型
from ultralytics import YOLO
# COCO 工具
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# 检查是否需要重新下载
import os
# 下载文件的辅助函数
def download_file(url, file_path):
response = requests.get(url, stream=True)
total_size_in_bytes = int(response.headers.get('content-length', 0))
block_size = 1024 # 1 Kibibyte
progress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True)
with open(file_path, 'wb') as file:
for data in response.iter_content(block_size):
progress_bar.update(len(data))
file.write(data)
progress_bar.close()
coco_url = "https://github.com/ultralytics/yolov5/releases/download/v1.0/coco2017val.zip"
coco_zip_path = 'coco2017val.zip'
# 如果没有 coco 目录,则下载并解压
if not os.path.exists('coco'):
download_file(coco_url, coco_zip_path)
# 解压文件
with zipfile.ZipFile(coco_zip_path, 'r') as zip_ref:
zip_ref.extractall('.')
# 加载预训练的 YOLOv8 模型
model = YOLO('./yolov8n.pt')
# 加载 COCO 验证图像注释
coco_annotations_path = 'coco/annotations/instances_val2017.json'
coco = COCO(coco_annotations_path)
# 获取图像 ID
image_ids = coco.getImgIds()
images = coco.loadImgs(image_ids)
# 处理图像并收集检测结果
results = []
for img in images:
image_path = f"coco/images/val2017/{img['file_name']}"
preds = model(image_path)[0].numpy().boxes
# 将结果转换为 COCO 兼容的格式
for xyxy, conf, cls in zip(preds.xyxy, preds.conf, preds.cls):
result = {
'image_id': img['id'],
'category_id': int(cls.item() + 1),
'bbox': [xyxy[0].item(), xyxy[1].item(), xyxy[2].item() - xyxy[0].item(), xyxy[3].item() - xyxy[1].item()],
'score': conf.item()
}
results.append(result)
# 将结果转换为 COCO 对象
coco_dt = coco.loadRes(results)
# 运行 COCO 评估
coco_eval = COCOeval(coco, coco_dt, 'bbox')
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()创建虚拟环境,安装依赖项并运行报告:
bash
pip3 install ultralytics
pip3 install requests
pip3 install pycocotools
python3 ./coco_map_report.py输出结果如下:
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.053
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.071
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.058
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.021
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.052
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.083
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.043
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.061
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.061
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.027
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.062
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.094