概述
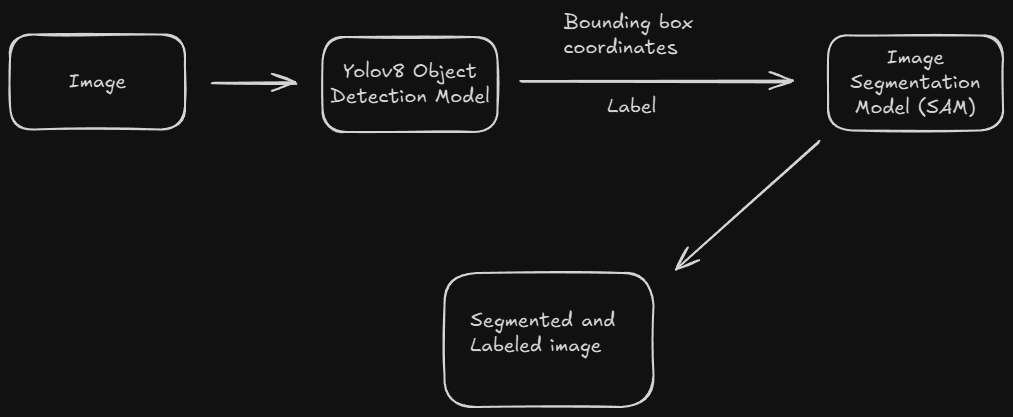
在当前的计算机视觉领域,目标分割技术正变得越来越重要。市面上有许多分割模型,它们的工作原理大致相似,通常包括收集数据、配置模型以及训练分割模型等步骤。最终目标是实现精确的目标分割。而随着 SAM(Segment Anything Model)的出现,这一过程变得更加高效。SAM 的独特之处在于,它只需要用户向模型提供某种坐标信息,就能自动完成所有分割工作,极大地简化了操作流程。

在深入探讨之前,可能会提出这样一个问题:为何选择 YOLO 模型作为我们的工具? 答案十分明确:SAM(Segment Anything Model)本身并不具备直接输出目标类别标签的功能。 它仅能依据用户提供的位置信息来执行分割任务。而 YOLO 模型的引入,恰到好处地填补了这一空白。借助目标检测模型,我们能够精准地定位目标的位置,并获取其对应的类别标签。随后,利用这些位置数据引导 SAM 进行分割操作,从而最终实现目标的清晰分割,并为分割结果赋予明确的类别标注。
与传统分割模型不同,SAM(Segment Anything Model)在执行分割任务时,需要用户主动提供目标的位置信息。这些位置信息有三种主要类型:
- 单点输入:仅提供一个坐标点(x,y),用于指示目标的大致位置。
- 边界框输入:提供一个边界框的坐标(x1,y1,x2,y2),明确指定目标的区域范围。
- 多点输入:同时输入多个正点和负点,以更精细地引导模型进行分割。
鉴于我们采用的是 YOLO 模型,边界框方法无疑是最佳选择。YOLO 模型能够直接输出目标的边界框坐标,这与 SAM 的输入需求完美契合。因此,我们可以无缝地将 YOLO 模型的输出作为 SAM 的输入,从而实现高效的目标检测与分割。在接下来的内容中,我们将详细阐述如何将 YOLO 与 SAM 结合,以实现这一目标。
YOLOv8 目标检测
在正式展开本文内容之前,若对如何从零开始训练自定义的 YOLO 模型抱有兴趣,不妨参考我过往撰写的一篇文章《YOLOV8目标识别------详细记录从环境配置、自定义数据、模型训练到模型推理部署》。不过,在本文中,为了便于快速上手和聚焦于核心问题,我将直接调用预训练好的 yolov8n.pt 模型。若您选择采用这一预训练模型,仅需运行以下代码,系统便会自动为您完成模型的下载工作。
python
conda create -n yolo_sam python==3.10
conda activate yolo_sam
pip install ultralytics
python
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8n.pt") # 预训练的 YOLOv8n 模型
# 对一系列图像进行批量推理
results = model([r"ball.jpg"]) # 返回一个 Results 对象列表
# 处理结果列表
for result in results:
boxes = result.boxes # 用于边界框输出的 Boxes 对象
masks = result.masks # 用于分割掩码输出的 Masks 对象
keypoints = result.keypoints # 用于姿态输出的 Keypoints 对象
probs = result.probs # 用于分类输出的 Probs 对象
obb = result.obb # 用于 OBB 输出的 Oriented boxes 对象
result.show() # 显示到屏幕
result.save(filename="result.jpg") # 保存到磁盘
检测 + 分割与 SAM
在开始之前,你需要下载 SAM 模型。你可以从 Hugging Face 下载它(链接)。
1. 安装必要的库
python
pip install git+https://github.com/facebookresearch/segment-anything.git
pip install opencv-python mediapipe ultralytics numpy torch matplotlib2. 导入库
python
import torch
import cv2
import numpy as np
import matplotlib.pyplot as plt
from ultralytics import YOLO
from segment_anything import sam_model_registry, SamPredictor3. 加载模型
python
# 加载 YOLO 模型
model = YOLO("yolov8n.pt")
# 加载 SAM 模型
sam_checkpoint = "sam_vit_b_01ec64.pth" # 替换为你的模型路径
model_type = "vit_b"
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)4. 检测 + 分割
python
# 加载图像
image_path = r"ball.jpg"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转换为 RGB 格式以供 SAM 使用
# 运行 YOLO 推理
results = model(image, conf=0.3)
# 遍历检测结果
for result in results:
# 获取边界框
for box, cls in zip(result.boxes.xyxy, result.boxes.cls):
x1, y1, x2, y2 = map(int, box) # 转换为整数
# 获取 ID
class_id = int(cls) # 类别 ID
# 获取类别标签
class_label = model.names[class_id]
# 准备 SAM
predictor.set_image(image_rgb)
# 定义一个边界框提示供 SAM 使用
input_box = np.array([[x1, y1, x2, y2]])
# 获取 SAM 掩码
masks, _, _ = predictor.predict(box=input_box, multimask_output=False)
# 创建原始图像的副本以叠加掩码
highlighted_image = image_rgb.copy()
# 将掩码以半透明蓝色应用于图像
mask = masks[0]
# 创建一个空白图像
blue_overlay = np.zeros_like(image_rgb, dtype=np.uint8)
# 蓝色用于分割区域(RGB)
blue_overlay[mask == 1] = [0, 0, 255]
# 使用透明度将蓝色叠加层与原始图像混合
alpha = 0.7 # 叠加层的透明度
highlighted_image = cv2.addWeighted(highlighted_image, 1 - alpha, blue_overlay, alpha, 0)
# 在边界框上方添加标签(类别名称)
font = cv2.FONT_HERSHEY_SIMPLEX
label = f"{class_label}" # 标签为类别名称
cv2.putText(highlighted_image, label, (x1, y1 - 10), font, 2, (255, 255, 0), 2, cv2.LINE_AA)
# 可选:保存带有边界框和突出显示的分割结果的图像
output_filename = f"highlighted_output.png"
cv2.imwrite(output_filename, cv2.cvtColor(highlighted_image, cv2.COLOR_RGB2BGR))

交互加分割
使用 OpenCV 鼠标事件来画框交互,并将框的坐标传入 SAM 进行分割,是一种非常直观且灵活的方法。
1. 代码实现
python
import cv2
import numpy as np
import torch
from segment_anything import sam_model_registry, SamPredictor
# 初始化全局变量
start_point = None
end_point = None
drawing = False
# 鼠标回调函数
def draw_rectangle(event, x, y, flags, param):
global start_point, end_point, drawing
if event == cv2.EVENT_LBUTTONDOWN:
start_point = (x, y)
drawing = True
elif event == cv2.EVENT_MOUSEMOVE:
if drawing:
end_point = (x, y)
elif event == cv2.EVENT_LBUTTONUP:
drawing = False
end_point = (x, y)
cv2.rectangle(image, start_point, end_point, (0, 255, 0), 2)
cv2.imshow("Image", image)
# 加载 SAM 模型
sam_checkpoint = "sam_vit_b_01ec64.pth" # 替换为你的模型路径
model_type = "vit_b"
device = "cuda" if torch.cuda.is_available() else "cpu"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)
# 加载图像
image_path = "example.jpg"
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转换为 RGB 格式
# 创建窗口并绑定鼠标回调函数
cv2.namedWindow("Image")
cv2.setMouseCallback("Image", draw_rectangle)
while True:
cv2.imshow("Image", image)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 如果框已经画好,进行分割
if start_point and end_point:
# 转换为 SAM 需要的边界框格式
input_box = np.array([start_point[0], start_point[1], end_point[0], end_point[1]])
input_box = np.array([min(input_box[0], input_box[2]), min(input_box[1], input_box[3]),
max(input_box[0], input_box[2]), max(input_box[1], input_box[3])])
# 生成分割掩码
predictor.set_image(image_rgb)
masks, _, _ = predictor.predict(box=input_box, multimask_output=False)
# 显示分割结果
highlighted_image = image_rgb.copy()
mask = masks[0]
blue_overlay = np.zeros_like(image_rgb, dtype=np.uint8)
blue_overlay[mask == 1] = [0, 0, 255] # 蓝色掩码
highlighted_image = cv2.addWeighted(highlighted_image, 1, blue_overlay, 0.7, 0)
cv2.imshow("Segmented Image", cv2.cvtColor(highlighted_image, cv2.COLOR_RGB2BGR))
cv2.waitKey(0)
cv2.destroyAllWindows()
break
cv2.destroyAllWindows()实现效果:
 ### 2. 代码说明
### 2. 代码说明
-
全局变量:
start_point和end_point用于记录鼠标点击和释放时的坐标。drawing用于标记是否正在绘制矩形。
-
鼠标回调函数:
draw_rectangle函数用于处理鼠标事件,包括按下、移动和释放。- 当鼠标按下时,记录起始点。
- 当鼠标移动时,更新终点。
- 当鼠标释放时,绘制矩形并更新图像。
-
加载 SAM 模型:
- 使用
sam_model_registry加载预训练的 SAM 模型。 - 将模型移动到 GPU(如果可用)。
- 使用
-
加载图像:
- 使用 OpenCV 读取图像,并将其转换为 RGB 格式以供 SAM 使用。
-
创建窗口并绑定鼠标回调:
- 使用
cv2.namedWindow创建窗口。 - 使用
cv2.setMouseCallback绑定鼠标回调函数。
- 使用
-
主循环:
- 显示图像并等待用户操作。
- 如果用户绘制了矩形,将矩形的坐标转换为 SAM 需要的格式,并调用 SAM 进行分割。
- 显示分割结果。
3. 运行效果
-
绘制矩形:
- 运行程序后,使用鼠标在图像上绘制一个矩形框,表示需要分割的目标区域。
-
显示分割结果:
- 按下
q键后,程序会根据绘制的矩形框调用 SAM 进行分割,并显示分割结果。
- 按下
4. 注意事项
- 图像路径 :确保
image_path指向正确的图像文件。 - 模型路径 :确保
sam_checkpoint指向正确的 SAM 模型文件。 - 环境依赖 :确保安装了必要的依赖库,如
opencv-python、torch和segment_anything。