Pytorch 第十四回:神经网络编码器------变分自动编解码器
本次开启深度学习第十四回,基于Pytorch的神经网络编码器。本回分享VAE变分自动编码器。在本回中,通过minist数据集来分享如何建立一个变分自动编码器。接下来给大家分享具体思路。
本次学习,借助的平台是PyCharm 2024.1.3,python版本3.11 numpy版本是1.26.4,pytorch版本2.0.0
文章目录
- [Pytorch 第十四回:神经网络编码器------变分自动编解码器](#Pytorch 第十四回:神经网络编码器——变分自动编解码器)
- 前言
-
- [1 变分自动编码](#1 变分自动编码)
- [2 证据下界](#2 证据下界)
- 一、数据准备
- 二、使用步骤
- 三、模型训练
- 总结
前言
讲述模型前,先讲述两个概念,统一下思路:
1 变分自动编码
变分自动编码(Variational Auto-Encoder,VAE) 是一种通过"概率压缩+结构约束"实现数据生成与特征提取的深度学习模型。简而言之,编码器不直接输出一个隐藏变量,而是输出一个均值和一个方差,这两个变量刻画了隐藏变量的高斯分布。这样,可以从这个分布中随机采样隐藏变量,再用解码器生成新图片。其结构图如下所示:
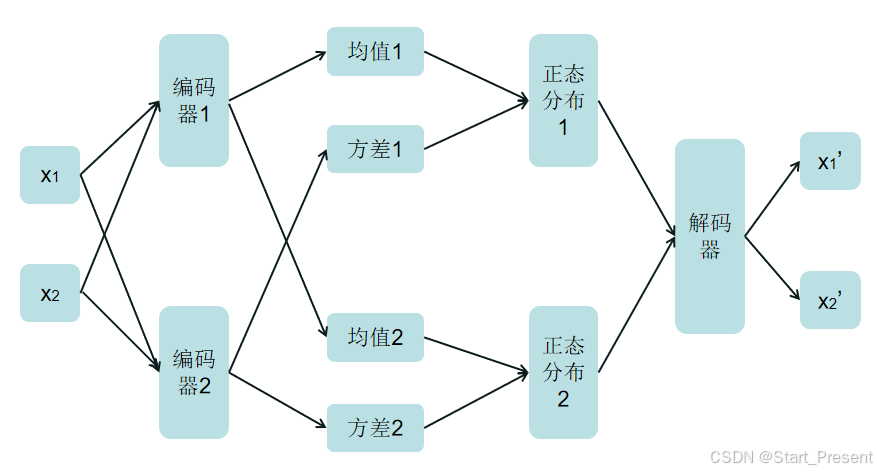
注:
VAE多用在数据生成、插值、半监督学习等场景中。VAE是自动编码器在生成能力上的概率化扩展,通过引入潜在空间分布约束和变分推断优化目标,克服了传统自动编码器无法生成新样本的缺陷。
2 证据下界
证据下界(Evidence Lower Bound, ELBO) 是VAE模型优化的核心,其本质是对数据真实分布的下界近似。ELBO可拆解为两部分,分别对应VAE的两个核心目标:一个是重构项,即解码器从隐藏变量 z 生成的数据 x 与原始输入 x 的匹配程度(本代码中为均方误差MES);另一个是KL散度项(正则化项),约束近似后验分布 q(z∣x) 与先验分布 p(z)(通常为标准正态分布)的相似性,其作用为防止过拟合,保证潜在空间连续性(使 z 的分布平滑,便于生成新样本)。
注:为何需要证据下界?
1)VAE的目标是建模输入数据分布 ,但由于数据复杂(如图像、文本),直接建模非常困难。因此引入隐藏变量 z,借助隐藏变量生成数据的方式得到数据分布 ,即隐变量建模。
2)但这个过程中积分难以直接计算,导致优化目标不可行。因此采用一个近似分布 (编码器)逼近真实后验分布 ,进而推导出一个可优化的下界(ELBO)(换句话说,就是用近似的代替真实的进行积分计算),即变分推断。
闲言少叙,直接展示逻辑,先上引用:
c
import os
import torch
import torch.nn.functional as F
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms as tfs
from torchvision.utils import save_image
import time一、数据准备
首先准备MNIST数据集,并进行数据的预处理。关于数据集、数据加载器的介绍,可以查看第五回内容。
c
data_treating = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.5], [0.5])
])
train_set = MNIST('./data', transform=data_treating)
train_data = DataLoader(train_set, batch_size=64, shuffle=True)二、使用步骤
1、定义模型
模型由五部分组成,分别是初始化函数、编码函数、解码函数、参数重构函数、前向传播函数。各函数的连接对应上面所展示的VAE结构图。即,编码器输出均值和方差,再经过重构函数进行参数重构,最后通过解码器传出新的数据。在初始化函数中,c21用来获得编码器的均值参数,c22用获得编码器的对数方差参数。其代码如下:
c
class vae_net(nn.Module):
def __init__(self):
super(vae_net, self).__init__()
self.c1 = nn.Linear(28 * 28, 400)
self.c21 = nn.Linear(400, 20)
self.c22 = nn.Linear(400, 20)
self.c3 = nn.Linear(20, 400)
self.c4 = nn.Linear(400, 28*28)
def encode(self, x):
code1 = F.relu(self.c1(x))
return self.c21(code1), self.c22(code1)
# 重参数化
def reparameterization(self, b, a):
value1 = torch.exp(a.mul(0.5))
value2 = torch.FloatTensor(value1.size()).normal_()
if torch.cuda.is_available():
value2 = value2.cuda()
return value2.mul(value1).add_(b)
def decode(self, x):
code2 = F.relu(self.c3(x))
return F.tanh(self.c4(code2))
def forward(self, x):
b, a = self.encode(x)
value = self.reparameterization(b, a)
return self.decode(value), b, a2、定义损失函数和优化函数
本次定义的损失函数比较特殊,不能和之前分享的内容一样,直接采用均方误差损失函数计算的损失值。这里,需要计算KL散度项,通过KL散度约束获得模型的损失函数。具体代码如下所示:
c
reconstruction_function = nn.MSELoss(reduction='sum')
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
def loss_f(recons_x, x, b, a):
MSE = reconstruction_function(recons_x, x)
KLD_element = b.pow(2).add_(a.exp()).mul_(-1).add_(1).add_(a)
KLD = torch.sum(KLD_element).mul_(-0.5)
return MSE + KLD3、定义图片生成函数
模型训练后,需要将图片进行保存。由于训练时修改了数据的格式,因此这里需要还原数据的图片格式,代码如下。
c
def change_image(x):
x = 0.5 * (x + 1.)
x = x.clamp(0, 1)
x = x.view(x.shape[0], 1, 28, 28)
return x三、模型训练
1、实例化模型
这里实例化了一个变分自动编码的模型,同时为了加快模型训练,引入GPU进行训练(如何引入GPU进行训练,可以查看第六回)
c
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device=", device)
net = vae_net().to(device)2、迭代训练模型
进行100次迭代训练,并将生成的图片保存。
c
time1 = time.time()
for e in range(100):
for image, _ in train_data:
image = image.view(image.shape[0], -1)
image = image.to(device)
optimizer.zero_grad()
recons_image, b, a = net(image)
loss = loss_f(recons_image, image, b, a) / image.shape[0]
loss.backward()
optimizer.step()
time_consume = time.time() - time1
if (e + 1) % 10 == 0:
print('epoch: {}, Loss: {:.4f},consume time:{:.3f}s'.format(e + 1, loss, time_consume))
new_image = change_image(recons_image.cpu().data)
if not os.path.exists('./vae_image'):
os.mkdir('./vae_image')
save_image(new_image, './vae_image/image_{}.png'.format(e + 1))3、生成图片展示
训练10次的图片

训练100次的图片

相对来说,经过100次迭代训练,生成的数字轮廓还是比较清晰的。
总结
1)数据准备:准备MNIST集;
2)模型准备:定义变分自动编码模型、损失函数和优化器;
3)数据训练:实例化模型并训练,生成新的图片数据