一、图搜图与文搜图
图搜图和文搜图的场景相信大家并不少见,比如度娘的搜索框就可以直接上传图片找到相似的图片,还有某宝某团都有这种上传图片匹配到相似商品或者商品页的推荐的功能。那比如我想搜一张"正在跳舞的狗"的图片,是不是就能搜出来呢?
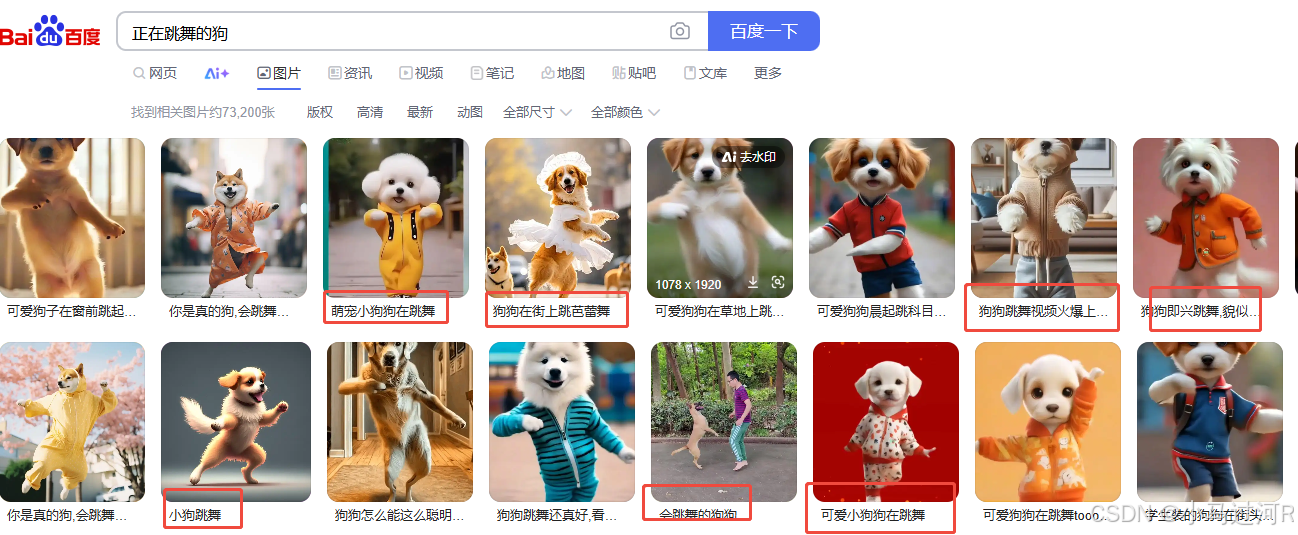
我们可以看到搜是搜出来了,但是基本图片的标题都涵盖了关键字"跳舞"、"狗"等。那么问题来了,度娘的图片搜索用的是图片标签的关键词匹配还是深度学习的文搜图?这个小马目前也不得而知,但丝毫不影响今天的主题。
二、如何实现图搜图与文搜图
关键字匹配的搜索方式显然不是最优解,会面临标签的准确性和图片多样性的问题,从原理上来分析效果就并不会很理想。
那要怎么实现呢?这个得益于"万物皆可向量"的道理。

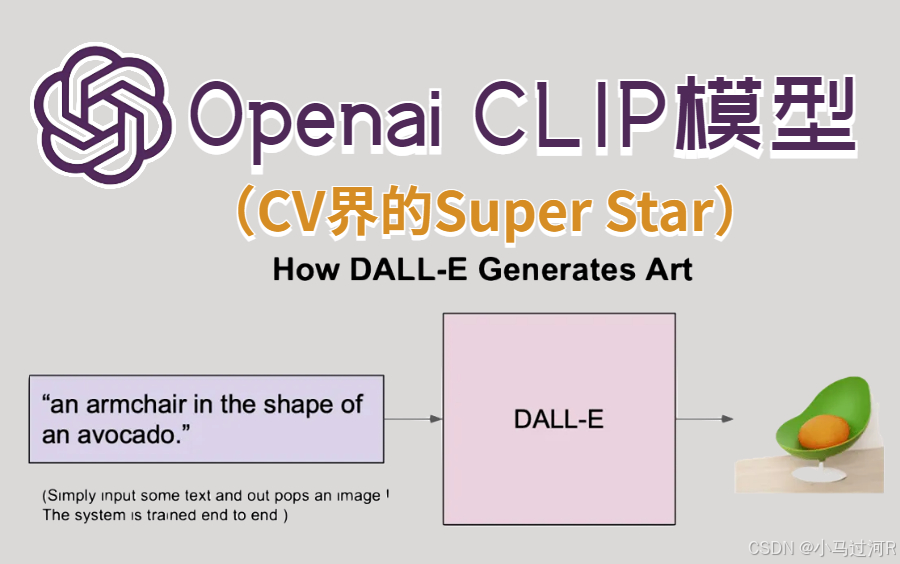
通俗地说就是,我们将图片和文本都进行embedding向量化,然后,图像和文本配对进行训练,例如输入pepper the aussie pup(描述一只小狗)和对应的小狗照片。模型的目标是将匹配的图像-文本对在语义空间中拉近,而将不匹配的图像-文本对推远 。模型通过对比学习进行预训练 ,这样我们就能得到一个能表示内容向量的模型。之后,图像和文本就映射到了同一语义空间,使得图像和文本可以直接进行相似性匹配,从而也实现了零样本分类。
没错,你看到的就是CLIP模型算法原理。
三、CLIP开源多模态模型
CLIP(Contrastive Language--Image Pretraining)是 OpenAI 在 2021 年发布的多模态模型,它通过跨模态对比学习,成功地将图像与文本在统一的语义空间中表示,能够让机器同时理解图片和文字,实现了跨模态理解并支持零样本任务,也是采用对比学习的文本-图像预训练模型。这意味着,CLIP 不仅能"看图",还能理解图像的"文字描述",帮助我们在图像和文本之间实现更智能的匹配。想进一步了解原理的可以看这里。
CLIP论文:Learning Transferable Visual Models From Natural Language Supervision
Github:https://github.com/OpenAI/CLIP
CLIP惊艳之处在于架构非常简洁且效果好到难以置信,在zero-shot文本-图像检索,zero-shot图像分类,文本→图像生成任务guidance,open-domain 检测分割等任务上均有非常惊艳的表现。
与向量数据库的结合之后,我们就能轻松实现相似度检索的匹配,找到文图或是图图相似匹配的内容。
成熟案例比如,企鹅云的向量数据库和 CLIP(Contrastive Language-Image Pre-Training)图像处理模型,构建一站式的图搜应用解决方案。
图片向量检索技术通过将图片转换为高维向量,并在向量空间内计算相似度,实现高效、精准的图像搜索。向量数据库以其高性能、高可用性、大规模数据处理能力、低成本和简单易用性等优势,为用户提供了强大的向量数据存储和检索能力。结合 CLIP 模型,可实现通过向量相似性检索的方式搜索图片,并提升图像搜索的准确性和效率,适用于电商推荐、内容审核、智能相册等多种图像处理任务。
- 不要为了彩蛋而彩蛋...