前情提要
家里养了三只猫咪,其中一只布偶猫经常出入厕所。但因为平时忙于学业,没法时刻关注牠的行为。我知道猫咪的如厕频率和时长与健康状况密切相关,频繁如厕可能是泌尿问题,停留过久也可能是便秘或不适。为了更科学地了解牠的如厕习惯,我计划搭建一个基于视频监控和AI识别的系统,自动识别猫咪进出厕所的行为,记录如厕时间和停留时长,并区分不同猫咪。这样即使我不在家,也能掌握猫咪的健康状态,更安心地照顾它们。
已完成工作:
✅猫咪如厕检测与分类识别系统系列【一】 功能需求分析及猫咪分类特征提取
✅猫咪如厕检测与分类识别系统系列【二】多图上传及猫咪分类特征提取更新
✅猫咪如厕检测与分类识别系统系列【三】 融合yolov11目标检测
✅猫咪如厕检测与分类识别系统系列【四】融合检测日志输出及前端展示界面制作
✅猫咪如厕检测与分类识别系统系列【五】信息存储数据库改进+添加猫咪页面制作+猫咪躯体匹配算法架构更新
计划工作:
✅ 猫咪管理功能:已完成猫咪照片上传与名称登记模块。
🔄 多图上传与分类特征提取:已支持批量上传猫咪图像并自动更新个体特征库。优化中,更新特征提取器逻辑及代码
✅ 目标检测与事件识别集成(YOLOv11):功能开发中,正在实现猫咪行为自动识别。
⏳ 检测区域绘制功能:待开发,计划支持用户自定义如厕检测区域。
🔄 事件行为记录模块:进行中,将实现如厕进出时间、停留时长等事件记录功能。
⏳ 检测结果推流展示:待更新,计划支持算法结果实时推流。
⏳ 整体运行结果推流整合:待更新,计划集成检测图像与系统状态为统一视频流输出。
我们现在进行下面任务:
1.分类模型训练
2.matcher+目标检测混合检测分类
3.未知目标自动更新
分类模型训练
如果你已经将猫图按如下结构存放:
finetune_dataset/
├── Mimi/
│ ├── mimi_1.jpg
│ ├── mimi_2.jpg
├── Kaka/
│ ├── kaka1.jpg
│ └── kaka2.jpg
...
已经拥有一个标准的 分类数据集结构,我们可以直接用它训练一个猫个体识别模型 ✅
✅ 下一步:训练专属识别模型
我们将创建一个 PyTorch 训练脚本,功能包括:
🎯 训练目标:
-
模型结构:ResNet18(轻量、好用)
-
分类数:你的猫的数量(由文件夹个数自动决定)
-
输入图像:自动从
finetune_dataset/加载 -
输出模型:
.pt文件(后续可以接入系统)
python
# train_cat_classifier.py - 猫个体识别模型训练脚本(PyTorch)
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader, random_split
# 配置
DATA_DIR = r"C:\Users\Administrator\Desktop\cat"
BATCH_SIZE = 16
EPOCHS = 20
LR = 1e-4
MODEL_SAVE = "cat_classifier.pt"
IMG_SIZE = 224
# 数据增强与预处理
data_transforms = transforms.Compose([
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
# 加载数据
full_dataset = datasets.ImageFolder(DATA_DIR, transform=data_transforms)
class_names = full_dataset.classes
num_classes = len(class_names)
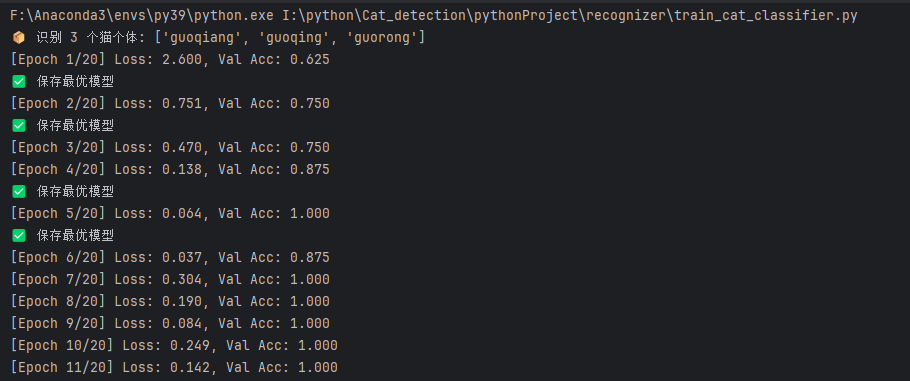
print(f"📦 识别 {num_classes} 个猫个体: {class_names}")
# 划分训练/验证集
val_size = int(0.2 * len(full_dataset))
train_size = len(full_dataset) - val_size
train_dataset, val_dataset = random_split(full_dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE)
# 加载预训练 ResNet18 模型
model = models.resnet18(pretrained=True)
model.fc = nn.Linear(model.fc.in_features, num_classes)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
# 训练循环
def train():
best_acc = 0.0
for epoch in range(EPOCHS):
model.train()
total_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
model.eval()
correct, total = 0, 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
acc = correct / total
print(f"[Epoch {epoch+1}/{EPOCHS}] Loss: {total_loss:.3f}, Val Acc: {acc:.3f}")
# 保存最佳模型
if acc > best_acc:
best_acc = acc
torch.save(model.state_dict(), MODEL_SAVE)
print("保存最优模型")
if __name__ == '__main__':
train()
print(f 训练完成,模型保存为 {MODEL_SAVE}")训练过程图:
🧠 功能亮点:
| 功能 | 说明 |
|---|---|
| 自动划分训练/验证集 | 80% 训练 + 20% 验证 |
| 使用 ResNet18 | 可识别多只猫个体 |
| 数据增强 | 随机水平翻转等 |
| 自动保存最优模型 | 保存为 cat_classifier.pt |
| 输出训练日志 | 每轮 loss + 验证准确率 |
🚀 运行方式:
bash
cd cat_monitor
python train_cat_classifier.py训练完成后,可以用这个模型来替换现在的特征提取+匹配方式,直接做分类。接下来我们将其集成到现有猫咪如厕系统中:
✅ 集成目标:
-
加载分类模型 (
ResNet18) -
对每只检测到的猫图裁剪图像进行分类
-
替换原来的特征提取 + 最近邻匹配逻辑
-
返回类别名(即猫名)
🔧 集成方式:
我们将创建一个新模块:
recognizer/classifier.py用于封装分类推理逻辑,支持:
-
加载
.pt模型 -
输入图像(BGR/路径/PIL)
-
输出预测猫名
但是现在存在一个问题,「当有新猫咪加入时,分类模型如何处理?」
❗问题本质:
当前训练的是一个 固定类别分类模型 (ResNet18,比如识别 3 只猫:guorong、guoqing、guoqiang)
🐾 如果你添加新猫,比如 guodong,这个模型无法识别 guodong,因为 guodong 没有出现在训练集中。
✅ 应对方案:
✅ 方案 A:继续使用 最近邻特征匹配方式
-
新猫加入时,只需添加新图 → 提特征 → 加入库
-
优点:支持 动态扩展,无需重训
-
缺点:识别准确率依赖于特征提取器 + 距离匹配
💡 推荐将 分类器作为主识别方式,最近邻匹配作为兜底 fallback
✅ 方案 B:训练时保留 旧数据,增量训练/微调
-
重新运行
prepare_dataset.py,把新猫的图也加进去 -
再跑一次
train_cat_classifier.py -
注意设置
num_workers=0/ seed 保证 reproducibility
✅ 方案 C(推荐组合):
| 识别方式 | 适合场景 |
|---|---|
| 分类器(准确) | 已知猫咪、数据稳定,主力识别 |
| 匹配器(灵活) | 新猫加入后立即可用,不中断使用 |
| → 组合:优先分类器,分类失败再 fallback 到最近邻匹配 |
🧠 总结推荐结构:
python
def recognize_cat(img_crop):
pred = classifier.predict(img_crop)
if pred == "Unknown":
pred = matcher.match(embedder.extract(img_crop))
return pred构建这种「双识别策略」模块,并判断识别置信度决定是否 fallback。
接下来工作:
-
✅ 实现 classifier 模块
-
✅ 在
main.py中接入 fallback 策略
只需上传新猫图即可自动加入特征库,无需重训,非常实用 🐱✨
✅ 分类器模块 classifier.py 已完成,具备以下功能:
🧠 功能说明:
-
加载你训练好的
cat_classifier.pt -
支持图像分类识别猫个体(支持 PIL 或图像路径)
-
低于置信度阈值(默认 0.6)则输出
"Unknown" -
可作为你系统中的主识别器
✅ 下一步我们将:
-
在
main.py中整合:-
加载 classifier 模块
-
优先调用 classifier 识别猫
-
若识别为
"Unknown",则 fallback 到matcher(最近邻匹配)
-
🧠 识别策略:
-
分类器优先识别 (使用
cat_classifier.pt模型) -
分类结果低于置信度阈值 → 自动 fallback 到最近邻匹配(
matcher) -
整体流程稳定灵活,支持动态添加新猫
测试存在问题:
-
name_map报错问题:我们现在自动从
data/embeddings/文件夹名中提取猫名作为分类器的类名,不再依赖db.name_map。 -
图片路径问题
之前错误原因是你传给
embedder.extract()的是PIL.Image,但它内部使用Image.open(),应该接收的是图像路径 。现在我们已经更新为直接传入PIL.Image对象,不再走Image.open(),因此你可以安全使用从视频中裁剪出的猫图进行识别了。
3.未知猫咪
当识别结果为 Unknown 且通过最近邻匹配出猫时:会自动将该猫的特征添加到数据库中(db.add_cat(cat_name, vec))。因此,无需手动上传图像,只要猫在摄像头中被成功识别过一次,系统就会记住它,并在下次更容易识别
python
\# main.py(集成分类器 + 匹配器双策略识别 + 日志与失败保存)
import cv2
import time
import numpy as np
from PIL import Image
from recognizer.embedder import CatEmbedder
from recognizer.database import CatDatabase
from recognizer.matcher import CatMatcher
from recognizer.classifier import CatClassifier
from toilet\_logger import ToiletLogger
from ultralytics import YOLO
import os
\# 初始化
model \= YOLO("yolov11.pt")
embedder \= CatEmbedder()
db \= CatDatabase()
matcher \= CatMatcher(db)
logger \= ToiletLogger()
\# 加载分类器(从 embeddings 文件夹获取类别名)
embedding\_dir \= "data/embeddings"
class\_names \= sorted({name.split("\_", 1)\[1\] for name in os.listdir(embedding\_dir) if os.path.isdir(os.path.join(embedding\_dir, name))})
classifier \= CatClassifier(model\_path\="cat\_classifier.pt", class\_names\=class\_names)
\# 摄像头设置
rtsp\_url \= "rtsp://192.168.0.102:554/stream1"
cap \= cv2.VideoCapture(rtsp\_url)
cap.set(cv2.CAP\_PROP\_BUFFERSIZE, 1)
\# 如厕区域
TOILET\_REGION \= (100, 100, 400, 400)
cat\_present \= False
entry\_time \= None
cat\_name \= "Unknown"
enter\_img \= ""✅ 系统现在支持以下功能:
🧠 推理日志保存
- 每次识别都会写入
recognition_log.txt,包含时间、识别猫名、使用的是分类器 or 匹配器。
📸 识别失败截图保存
- 当分类器输出为
"Unknown",将截图保存到web/static/fails/目录。
🏷️ 识别来源标记
- 在画面上显示识别来源(如
Mimi (classifier)或Mimi (matcher))
你现在可以查看:
-
recognition_log.txt查看历史记录 -
web/static/fails/看匹配器兜底识别的截图 -
画面上看到猫名+来源的标注