概述
自 Ultralytics 发布 YOLOV5 之后,YOLO 的应用方向和使用方式变得更加多样化且简单易用。从图像分类、目标检测、图像分割、目标跟踪到关键点检测,YOLO 几乎涵盖了计算机视觉的各个领域,似乎已经成为计算机视觉领域的"万能工具"。
YOLOV8 姿态估计
人体姿态估计(Human Pose Estimation,简称 HPE)是计算机视觉中的一个重要任务,它旨在检测图像或视频中人体的关键点位置,如头部、四肢和躯干等部位的坐标。YOLO 官方针对 HPE 的模型会在名称后加上 "-pose",例如 YOLOv8n-pose。目前提供的 HPE 预训练模型是基于 COCO 数据集的 17 个关键点训练而成,具体如下图所示:
COCO 数据集的关键点分布如下:
- 头部和面部:鼻子、左眼、右眼、左耳、右耳,共 5 个关键点。
- 上肢:左肩、右肩、左肘、右肘、左腕、右腕,共 6 个关键点。
- 下肢:左髋、右髋、左膝、右膝、左踝、右踝,共 6 个关键点。
- 躯干:左髋和右髋连接到肩膀,形成躯干的轮廓。
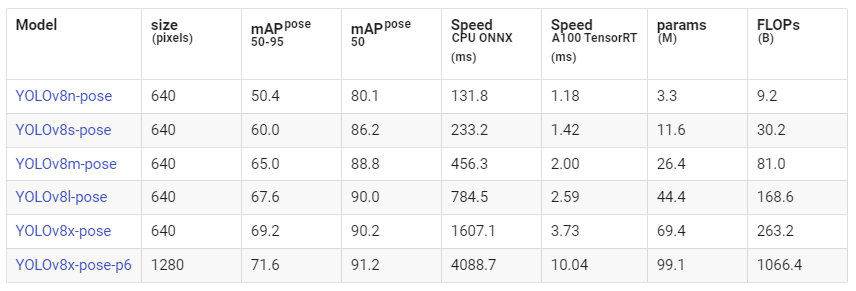
目前 YOLOV8 提供的最大尺寸模型为 YOLOV8X-p6,其输入图像尺寸为 1280×1280,mAP(平均精度)较高,但参数量比 YOLOV8 大了近 30 倍,计算量增加了 118 倍。这种模型虽然精度高,但在实际应用中需要权衡计算资源和实时性。
训练自己的 HPE 模型
Ultralytics 将姿态估计的训练过程封装得非常简单,使得用户可以轻松地训练自己的 HPE 模型。如果需要训练自己的 HPE 模型,可以参考 COCO 数据集中关键点的标注方法,并添加自己的标注图像。COCO 数据集的 17 个关键点标注规则如下:
- 单数编号:表示身体的左侧部位(如左肩、左肘等)。
- 双数编号:表示身体的右侧部位(如右肩、右肘等)。
训练示例代码
以下是使用 Ultralytics 提供的 YOLOV8 进行姿态估计模型训练的示例代码:
python
from ultralytics import YOLO
# 三种训练方式
# 训练一个全新的 YOLOV8N HPE 模型
model = YOLO('yolov8n-pose.yaml')
# 载入预训练模型进行训练(推荐方式)
model = YOLO('yolov8n-pose.pt')
# 与上一种方式相同,先加载配置文件再加载预训练权重
model = YOLO('yolov8n-pose.yaml').load('yolov8n-pose.pt')
# 开始训练
model.train(data='coco8-pose.yaml', epochs=100, imgsz=640)在训练过程中,需要指定数据集的配置文件(如 coco8-pose.yaml),其中包含数据集的路径、类别信息等。epochs 参数表示训练的轮数,imgsz 参数表示输入图像的尺寸。
直接使用预训练模型进行推理
YOLOV8 官方发布的预训练模型已经能够提供非常不错的目标检测和姿态估计效果。以下是如何直接使用这些预训练模型进行推理的示例。
官方推理示例
python
from ultralytics import YOLO
# 加载模型
model = YOLO('yolov8n-pose.pt') # 加载官方预训练模型
# model = YOLO('path/to/best.pt') # 加载自定义训练的模型
# 使用模型进行推理
results = model('https://ultralytics.com/images/bus.jpg') # 对图像进行推理获取关键点的详细信息
如果需要获取推理结果中各个关键点的详细信息,可以参考以下代码:
python
# 定义关键点索引与名称的对应关系
dic_points = {
0: 'nose', 1: 'left_eye', 2: 'right_eye', 3: 'left_ear', 4: 'right_ear',
5: 'left_shoulder', 6: 'right_shoulder', 7: 'left_elbow', 8: 'right_elbow',
9: 'left_wrist', 10: 'right_wrist', 11: 'left_hip', 12: 'right_hip',
13: 'left_knee', 14: 'right_knee', 15: 'left_ankle', 16: 'right_ankle'
}
# 加载模型并进行推理
model = YOLO('yolov8n-pose.pt')
results = model('path/to/image.jpg')
# 遍历检测结果
for r in results:
boxes = r.boxes # 获取边界框
kps = r.keypoints # 获取关键点
# 遍历每个检测到的人体实例
for p in kps:
list_p = p.data.tolist() # 将关键点数据转换为列表
# 遍历每个关键点
for i, point in enumerate(list_p):
# 打印关键点的索引和坐标
print(f"Keypoint {i} ({dic_points[i]}): ({int(point[0])}, {int(point[1])})")关键点的可视化
为了更直观地展示姿态估计的结果,可以通过绘制关键点和连接线来可视化人体姿态。以下是一些示例代码,展示如何绘制头部、躯干、上肢、下肢和脊椎的关键点。
头部关键点
头部的关键点包括双耳、眼睛和鼻子,共 5 个点。以下代码展示了如何绘制这些关键点及其连接线:
python
import cv2
import numpy as np
def draw_head(img, list_p):
# 绘制耳朵、眼睛和鼻子的关键点
for p in list_p[:5]:
cv2.circle(img, (int(p[0]), int(p[1])), 8, (0, 255, 0), -1)
# 绘制眼睛之间的连接线
start = (int(list_p[1][0]), int(list_p[1][1]))
end = (int(list_p[2][0]), int(list_p[2][1]))
cv2.line(img, start, end, (0, 0, 255), 2)
# 绘制鼻子到眼睛中点的连接线
start = (int((list_p[1][0] + list_p[2][0]) / 2), int((list_p[1][1] + list_p[2][1]) / 2))
end = (int(list_p[0][0]), int(list_p[0][1]))
cv2.line(img, start, end, (0, 0, 255), 2)
# 绘制耳朵之间的连接线
start = (int(list_p[3][0]), int(list_p[3][1]))
end = (int(list_p[4][0]), int(list_p[4][1]))
cv2.line(img, start, end, (0, 0, 255), 2)
return img躯干关键点
躯干的关键点包括肩膀和臀部,共 4 个点。以下代码展示了如何绘制这些关键点及其连接线:
python
def draw_body(img, list_p):
points = []
# 绘制肩膀和臀部的关键点
for p in [list_p[5], list_p[6], list_p[11], list_p[12]]:
cv2.circle(img, (int(p[0]), int(p[1])), 12, (0, 255, 0), -1)
point = (int(p[0]), int(p[1]))
points.append(point)
# 将关键点连接成多边形
points = np.array(points)
points =
points.reshape((-1, 1, 2))
isClosed = True
color = (0, 0, 255)
thickness = 3
img = cv2.polylines(img, [points], isClosed, color, thickness)
return img上肢关键点
上肢的关键点包括肩膀、手肘和手腕,共 6 个点。以下代码展示了如何绘制这些关键点及其连接线:
python
def draw_upper(img, list_p):
# 绘制左上肢的关键点和连接线
for i, p in enumerate([list_p[5], list_p[7], list_p[9]]):
cv2.circle(img, (int(p[0]), int(p[1])), 8, (0, 255, 0), -1)
lines = [(5, 7), (7, 9)]
for n in lines:
start = (int(list_p[n[0]][0]), int(list_p[n[0]][1]))
end = (int(list_p[n[1]][0]), int(list_p[n[1]][1]))
cv2.line(img, start, end, (0, 0, 255), 3)
# 绘制右上肢的关键点和连接线
for i, p in enumerate([list_p[6], list_p[8], list_p[10]]):
cv2.circle(img, (int(p[0]), int(p[1])), 8, (0, 255, 0), -1)
lines = [(6, 8), (8, 10)]
for n in lines:
start = (int(list_p[n[0]][0]), int(list_p[n[0]][1]))
end = (int(list_p[n[1]][0]), int(list_p[n[1]][1]))
cv2.line(img, start, end, (0, 0, 255), 3)
return img下肢关键点
下肢的关键点包括臀部、膝盖和脚踝,共 6 个点。以下代码展示了如何绘制这些关键点及其连接线:
python
def draw_lower(img, list_p):
# 绘制左下肢的关键点和连接线
for i, p in enumerate([list_p[11], list_p[13], list_p[15]]):
cv2.circle(img, (int(p[0]), int(p[1])), 8, (0, 255, 0), -1)
lines = [(11, 13), (13, 15)]
for n in lines:
start = (int(list_p[n[0]][0]), int(list_p[n[0]][1]))
end = (int(list_p[n[1]][0]), int(list_p[n[1]][1]))
cv2.line(img, start, end, (0, 0, 255), 3)
# 绘制右下肢的关键点和连接线
for i, p in enumerate([list_p[12], list_p[14], list_p[16]]):
cv2.circle(img, (int(p[0]), int(p[1])), 8, (0, 255, 0), -1)
lines = [(12, 14), (14, 16)]
for n in lines:
start = (int(list_p[n[0]][0]), int(list_p[n[0]][1]))
end = (int(list_p[n[1]][0]), int(list_p[n[1]][1]))
cv2.line(img, start, end, (0, 0, 255), 3)
return img脊椎关键点
脊椎的关键点可以通过连接鼻子、肩膀中心和臀部中心来表示。以下代码展示了如何绘制这些关键点及其连接线:
python
def draw_spine(img, list_p):
# 计算肩膀中心点
shoulder_center = ((list_p[5][0] + list_p[6][0]) / 2, (list_p[5][1] + list_p[6][1]) / 2)
# 计算臀部中心点
hip_center = ((list_p[11][0] + list_p[12][0]) / 2, (list_p[11][1] + list_p[12][1]) / 2)
# 绘制关键点
cv2.circle(img, (int(shoulder_center[0]), int(shoulder_center[1])), 12, (0, 255, 0), -1)
cv2.circle(img, (int(hip_center[0]), int(hip_center[1])), 12, (0, 255, 0), -1)
# 绘制连接线
cv2.line(img, (int(list_p[0][0]), int(list_p[0][1])), (int(shoulder_center[0]), int(shoulder_center[1])), (0, 0, 255), 3)
cv2.line(img, (int(shoulder_center[0]), int(shoulder_center[1])), (int(hip_center[0]), int(hip_center[1])), (0, 0, 255), 3)
return img应用场景
将所有关键点和连接线绘制在一起,可以得到完整的人体姿态估计结果,如下图所示:

这种姿态估计技术可以应用于多种场景,例如:
- 人员识别:在监控视频中识别人员的行走姿态,即使面部模糊或较小,也能通过姿态特征进行识别。
- 运动分析:分析运动员的动作,帮助教练进行技术指导。
- 康复治疗:辅助医生评估患者的康复情况,通过姿态变化监测康复进度。
总结
通过 YOLOV8 的姿态估计功能,我们可以轻松地检测图像或视频中人体的关键点,并将其可视化。这为计算机视觉领域的多种应用提供了强大的支持。未来,我们可以进一步探索如何利用这些关键点信息来提高人员识别的准确性,或者将其应用于其他更具挑战性的任务中。