一. 数据加载与保存
1. 数据加载:
spark.read.load 是加载数据的通用方法。
spark.read.format("...").option("...").load("...")
1)format("..."):指定加载的数据类型。
2)load("..."):格式下需要传入加载数据的路径。
3)option("..."):在"jdbc"格式下需要传入 JDBC 相应参数。如:url、user、password 和 dbtable
2. 保存数据
df.write.save 是保存数据的通用方法。
df.write.format("...").option("...").save("...")
format("..."):指定保存的数据类型
save ("..."):格式下需要传入保存数据的路径。
option("..."):在"jdbc"格式下需要传入 JDBC 相应参数,如:url、user、password 和 dbtable
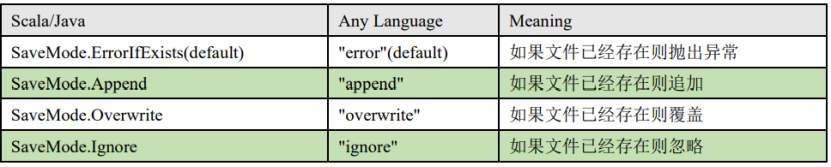
保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置
Parquet
Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式
存储格式。数据源为 Parquet 文件时,Spark SQL 可以方便的执行所有的操作,不需要使用 format。修改配置项 spark.sql.sources.default,可修改默认数据源格式。
JSON
Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 DatasetRow. 可以通过 SparkSession.read.json()去加载 JSON 文件。注意: Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串
CSV
Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为数据列。
3. MySQL
Spark-SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对
DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。
IDEA通过JDBC对MySQL进行操作:
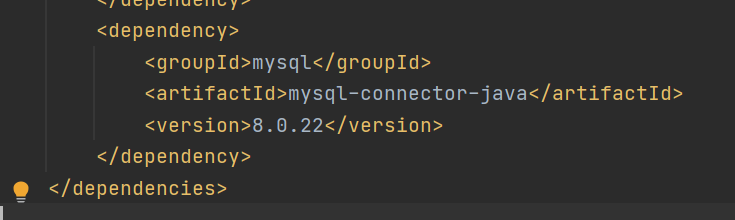
- 在pop.xml中导入依赖
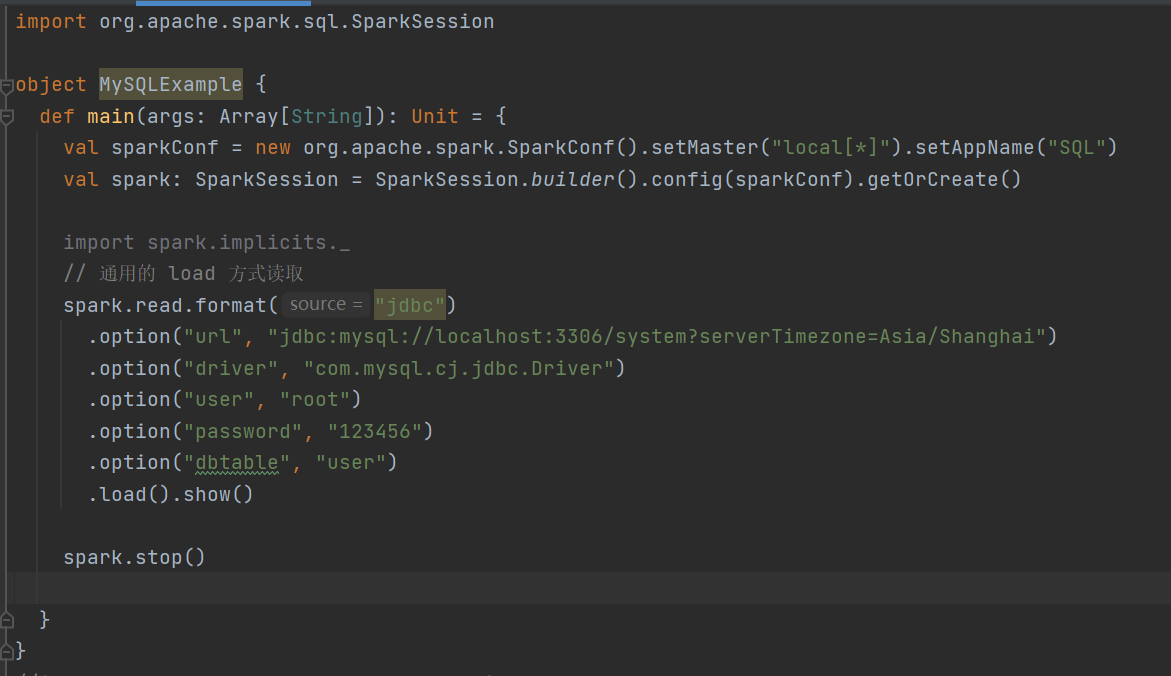
2)读取数据
通过load读取有两种方式
方式一:
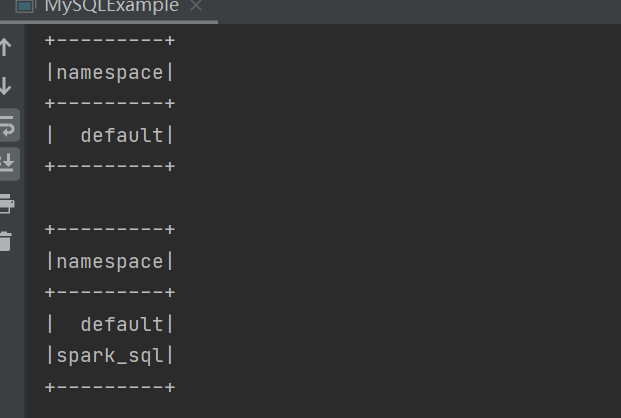
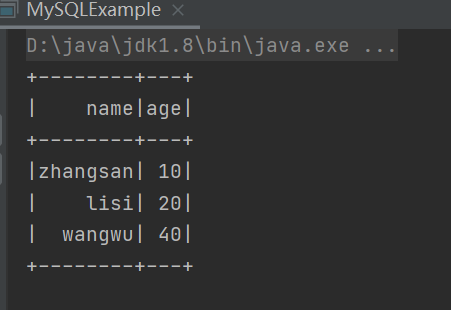
案例演示
读取结果
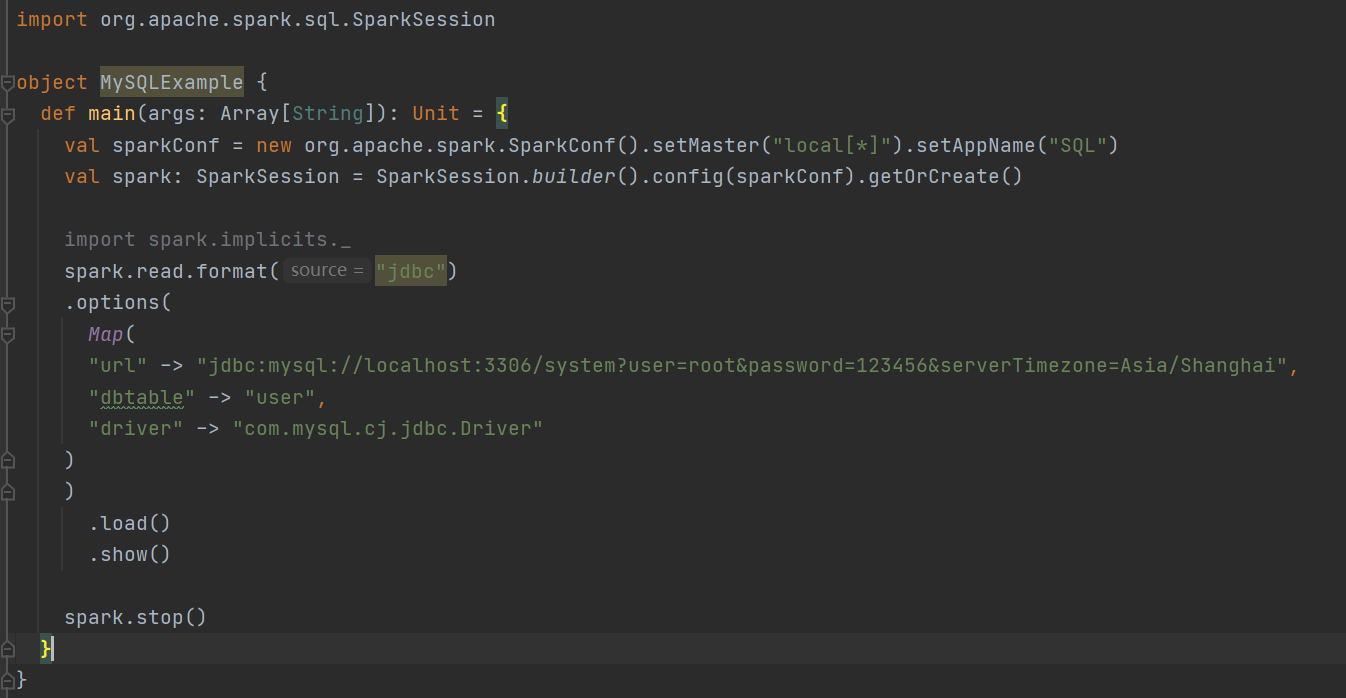
方式二:
案例演示
读取结果
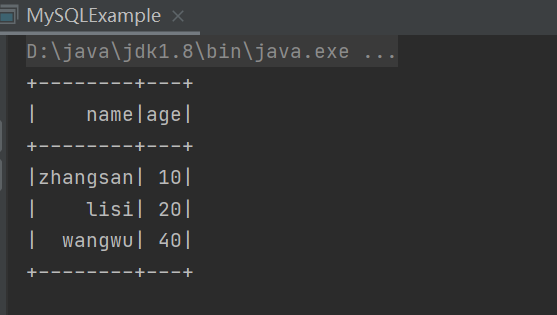
通过JDBC读取数据
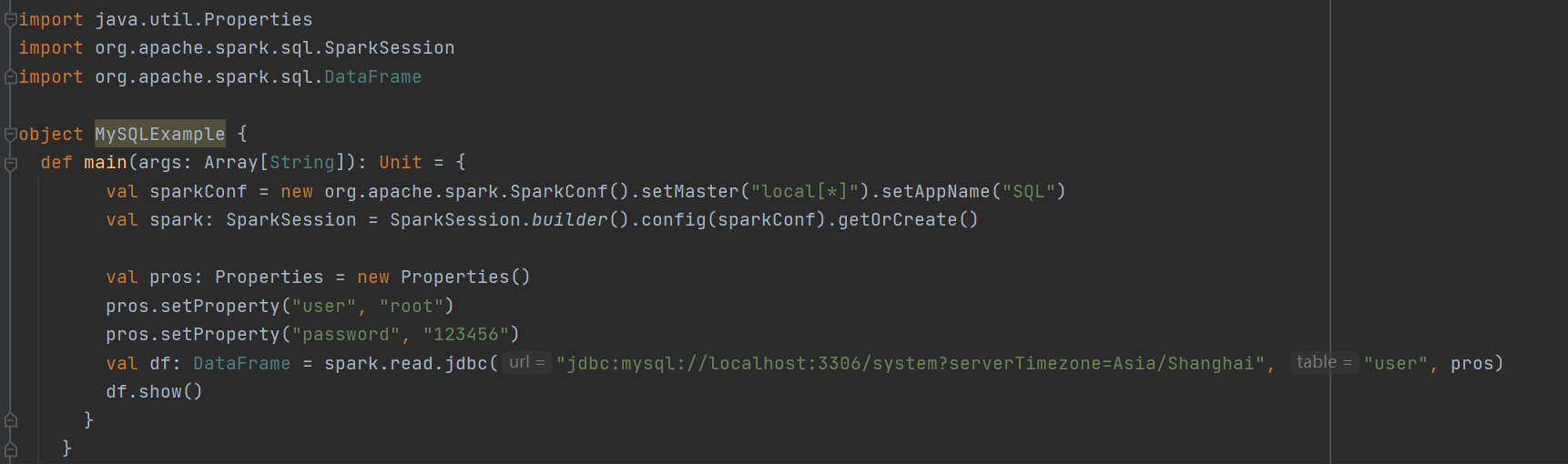
读取结果
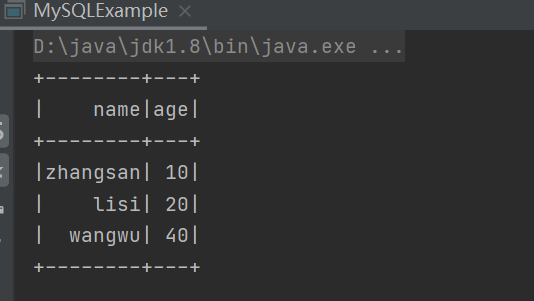
3)写入数据
案例演示
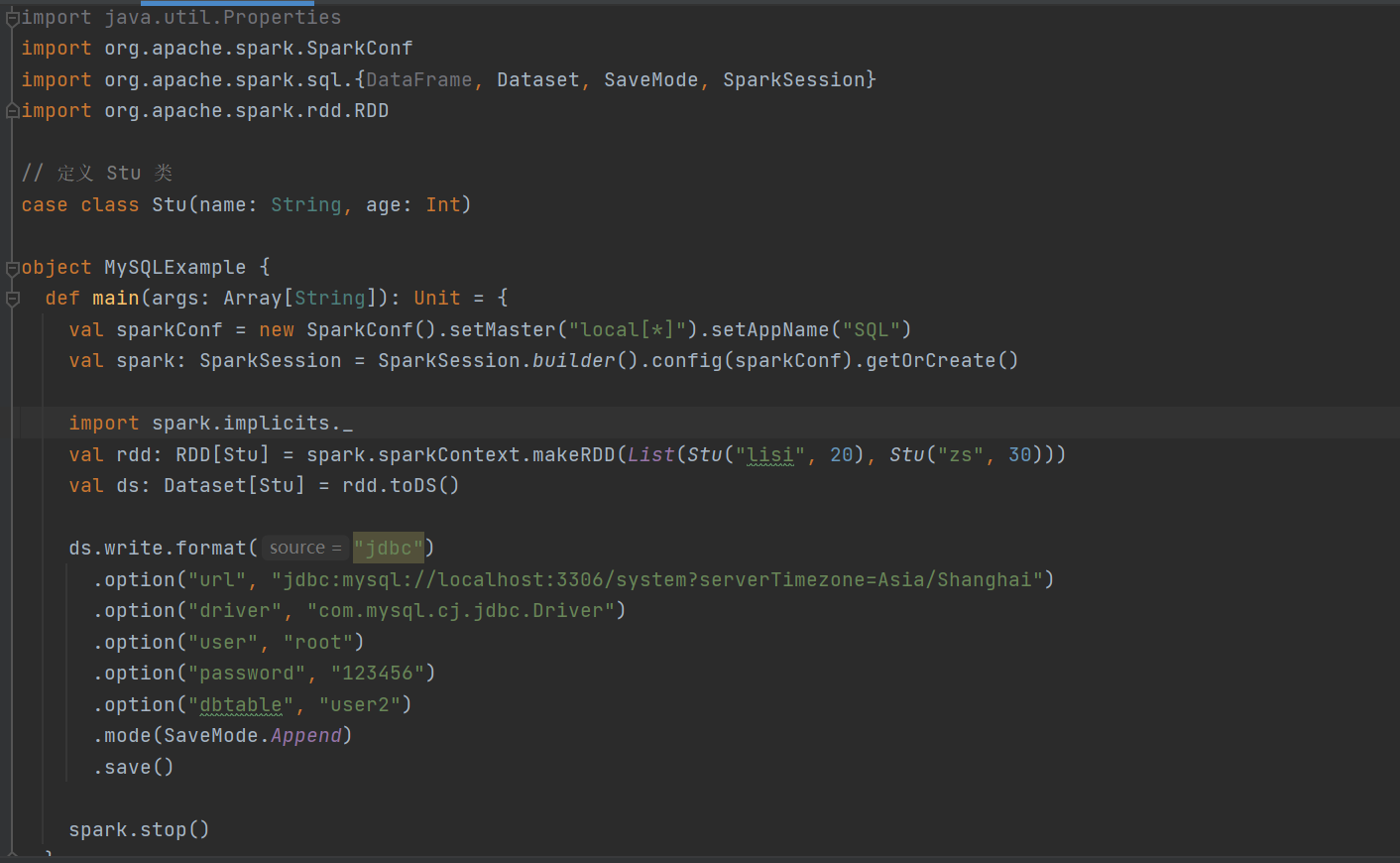
运行成功
可以看到数据已经写入

二 Spark-SQl连接hive
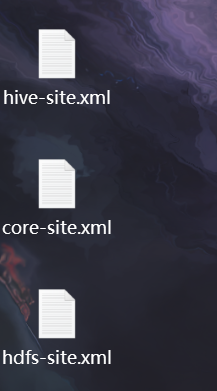
1. 在虚拟机中下载以下文件
2.修改hive-site.xml文件
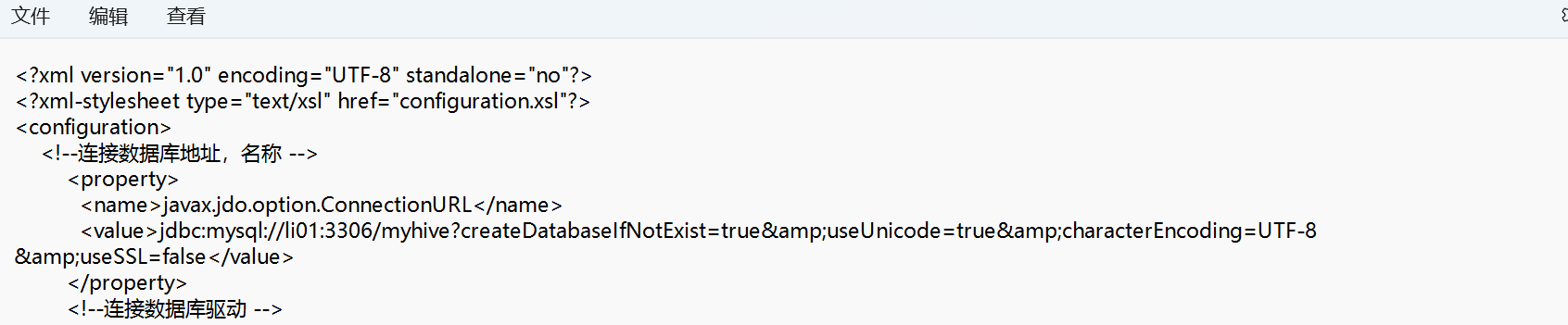 3. 将在虚拟机下载的文件放到conf目录下
3. 将在虚拟机下载的文件放到conf目录下
4. mysql驱动复制到jars目录下
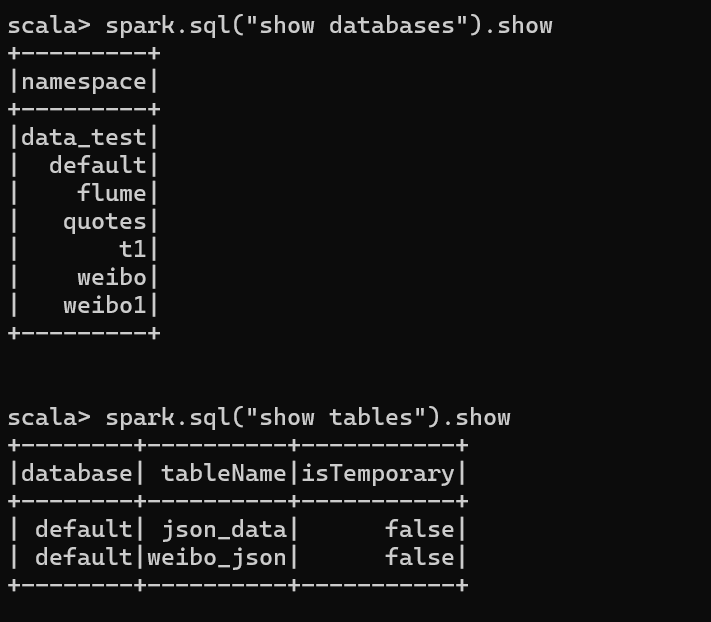
- 重启spark-shell验证命令
三 在idea中操作Hive
1)导入依赖
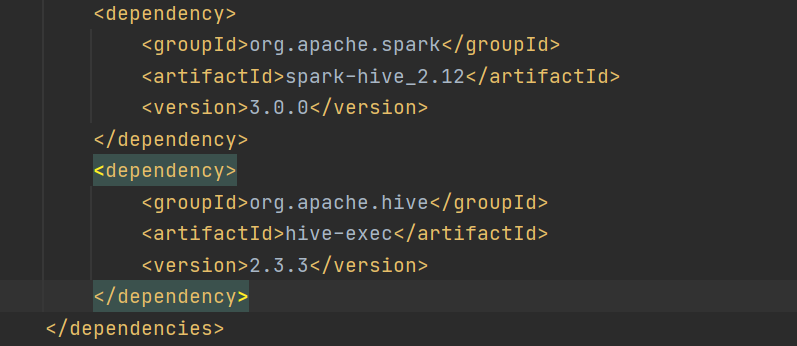
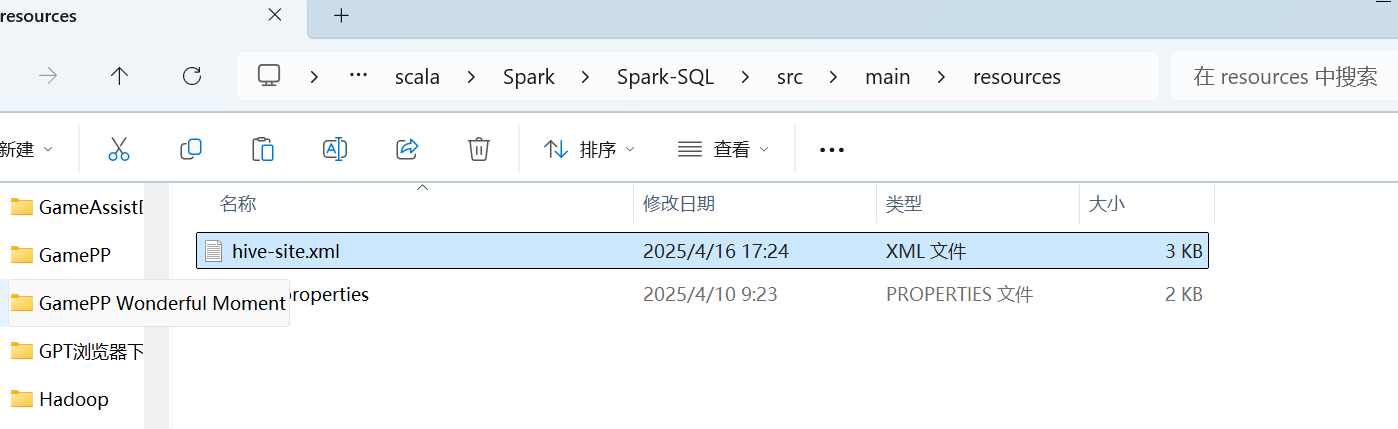
2)将hive-site.xml 文件拷贝到项目的 resources 目录中
案例演示
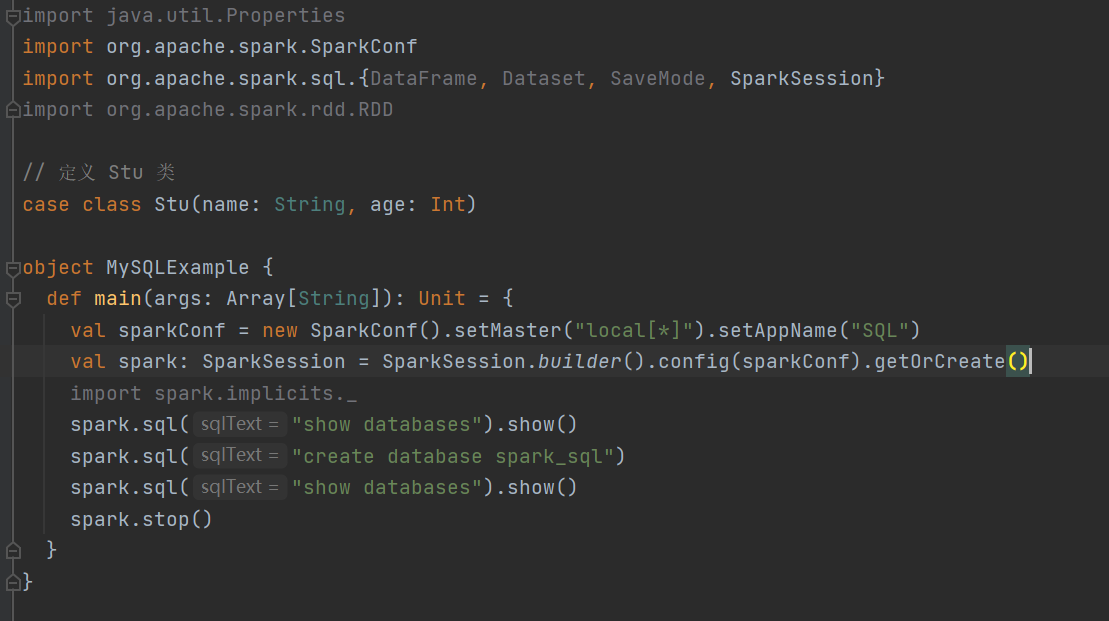
运行结果