《Not All Tokens Are What You Need for Pretraining》
不是所有的词元都是预训练所需
摘要
先前的语言模型预训练方法通常对所有训练词元均匀地应用下一词预测损失。对此常规做法提出挑战,我们认为"语料库中的并非所有词元对于语言模型训练同等重要"。我们的初步分析考察了语言模型的词元级训练动态,揭示了不同词元的损失表现存在显著差异。基于这些洞见,我们提出了一种新的语言模型RHO-1。不同于传统语言模型对语料中的每个下一词进行学习,RHO-1采用选择性语言建模(Selective Language Modeling,SLM),仅在与目标分布匹配的有用词元上进行训练。该方法首先利用参考模型为词元打分,然后仅针对高分词元聚焦损失进行训练。在15B OpenWebMath语料上的持续预训练中,RHO-1在9个数学任务的少样本准确率上实现高达 30 % 30\% 30%的绝对提升。微调后,RHO-1-1B与7B模型在MATH数据集上分别达到 40.6 % 40.6\% 40.6%与 51.8 % 51.8\% 51.8%的最新水平------其训练词元数量仅为DeepSeekMath的3%。此外,在80B通用词元上的持续预训练中,RHO-1在15个多样任务上平均提升 6.8 % 6.8\% 6.8%,显著提高了数据效率和语言模型预训练表现。
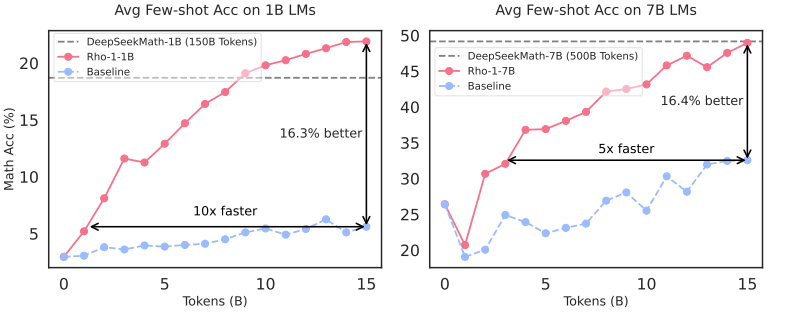
图1:我们对1B和7B语言模型使用15B OpenWebMath词元进行持续预训练。RHO-1应用我们提出的选择性语言建模(SLM),而基线模型则采用因果语言建模(CLM)。SLM在GSM8k和MATH数据集的平均少样本准确率提升超过16%,且达到基线性能的速度快5-10倍。
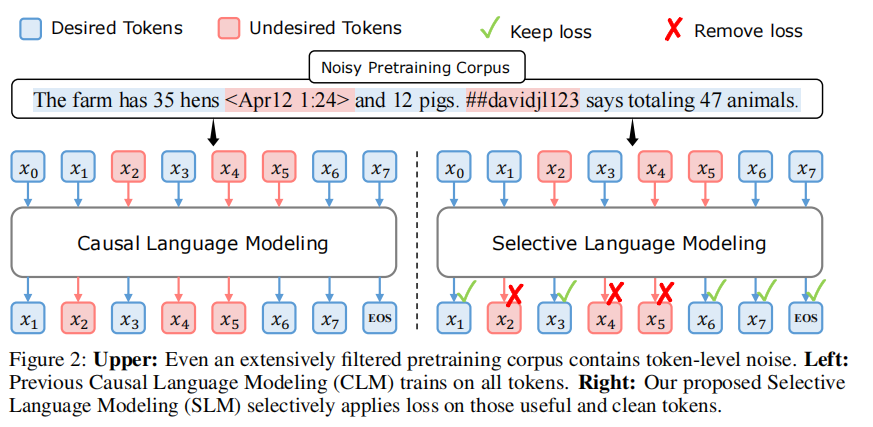
图2:上图:即使经过广泛过滤的预训练语料库依然包含词元级噪声。左图:先前的因果语言建模(CLM)在所有词元上训练。右图:我们提出的选择性语言建模(SLM)仅对有用且干净的词元施加损失。
1 引言
扩展模型参数和数据集规模持续提升大规模语言模型(LLM)的下一词预测准确率,推动人工智能取得显著进展 Kaplan 等,2020;Brown 等,2020;OpenAI,2023;Team 等,2023。然而,训练所有可用数据并非总是最优或可行。因此,数据过滤实践变得尤为重要,使用多种启发式和分类器 Brown 等,2020;Wenzek 等,2019 来筛选训练文档。这些技术显著提升了数据质量和模型表现。
但即便经过细致的文档级过滤,高质量数据集中仍含大量噪声词元,可能妨碍训练,见图2上图所示。去除这些词元可能改变文本含义,而过度严格的过滤会丢失有用数据 Welbl 等,2021;Muennighoff 等,2024 并带来偏差 Dodge 等,2021;Longpre 等,2023。研究显示,网页数据的分布并不完全匹配下游任务的理想分布 Tay 等,2022;Wettig 等,2023。例如,常见语料中的词元可能含有幻觉内容或难以预测的高度歧义部分。对所有词元施加相同损失,导致在非关键词元上的计算效率低下,或限制LLM向更高智能迈进的潜力。
为了探索语言模型如何在词元级别学习,我们首先观察了训练动态,尤其是预训练中词元损失的演变。在 § 2.1 \S 2.1 §2.1,我们评估了不同检查点模型的词元困惑度,并将词元归类为不同类型。结果显示,显著的损失减小仅集中于部分词元。"易学词元"已经被掌握,而部分"难学词元"表现为波动损失且难以收敛,导致大量无效梯度更新。
基于上述分析,我们提出了RHO-1模型,采用新颖的选择性语言建模(SLM)目标 3 ^{3} 3。如图4所示,该方法输入完整序列,并有选择地忽略不希望的词元损失。具体流程:首先,SLM在高质量语料上训练参考模型(Reference Model,RM),该模型为词元评分,实现对不干净及无关词元的自然筛除;其次,使用RM为语料中每个词元计算损失评分(§2.2);最后,仅训练那些训练模型损失明显高于RM的词元,即有较高"剩余损失"的词元,有选择地学习最有益的内容(§2.2)。
综合实验证明,SLM极大提升训练时的数据效率和下游任务表现。此外,我们发现SLM有效定位与目标分布相关的词元,进而改善困惑度表现。
3 { }^{3} 3 "RHO"代表选择性建模更高信息"密度( ρ \rho ρ)"的词元。
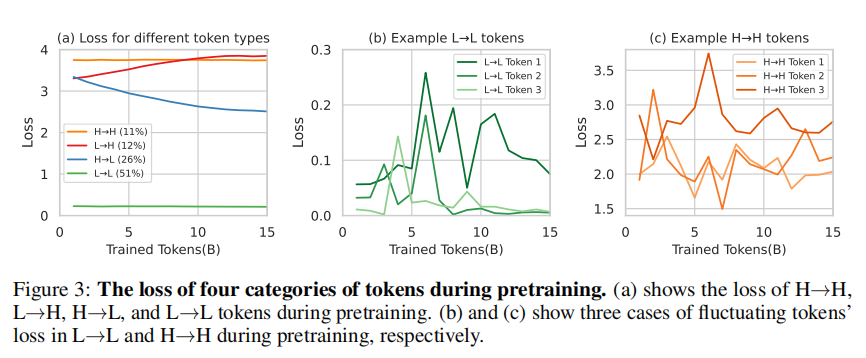
图3:预训练期间四类词元的损失变化。(a)展示了 H → H \mathrm{H} \rightarrow \mathrm{H} H→H、 L → H \mathrm{L} \rightarrow \mathrm{H} L→H、 H → L \mathrm{H} \rightarrow \mathrm{L} H→L和 L → L \mathrm{L} \rightarrow \mathrm{L} L→L词元的损失轨迹;(b)与(c)分别展示 L → L \mathrm{L} \rightarrow \mathrm{L} L→L与 H → H \mathrm{H} \rightarrow \mathrm{H} H→H词元损失波动的三种典型情况。
在数学持续预训练中(§3.2),1B和7B的RHO-1均较CLM基线在GSM8k和MATH任务中提升超过16%。图1显示,SLM以高达10倍的速度达到基线准确率。值得注意的是,RHO-1-7B仅用15B词元(选出10.5B词元)实现了与预训练了500B词元的DeepSeekMath-7B相当的性能,展现了极高效率。微调后,RHO-1-1B和7B在MATH上分别获得 40.6 % 40.6\% 40.6%和 51.8 % 51.8\% 51.8%。此外,§3.3验证SLM在通用持续预训练中的有效性:Tinyllama-1B在80B词元上预训练,SLM使15个基准平均性能提升 6.8 % 6.8\% 6.8%,其中代码与数学任务提升超10%。§3.4展示,在缺少高质量参考数据时,可基于自引用的SLM策略,带来下游任务均值最高 3.3 % 3.3\% 3.3%的提升。
2 选择性语言建模
2.1 并非所有词元同等重要:词元损失的训练动态}
我们首先深入考察单个词元在标准预训练中的损失变化。以Tinyllama-1B在OpenWebMath的15B词元持续预训练为例,每训练1B词元保存一个检查点。使用约32万词元的验证集测评各检查点的词元损失。图3(a)显示,词元分为四类:保持高损失 ( H → H ) (\mathrm{H} \rightarrow \mathrm{H}) (H→H)、损失上升 ( L → H ) (\mathrm{L} \rightarrow \mathrm{H}) (L→H)、损失下降 ( H → L ) (\mathrm{H} \rightarrow \mathrm{L}) (H→L)与持续低损失 ( L → L ) (\mathrm{L} \rightarrow \mathrm{L}) (L→L)(详细定义参见§D.1)。仅 26 % 26\% 26%词元表现显著损失下降,多数词元 ( 51 % ) (51\%) (51%)已被模型掌握。 11 % 11\% 11%词元持续难学,可能受固有不确定性驱动 Hüllermeier 和 Waegeman,2021。另外有 12 % 12\% 12%词元训练中损失意外上升。
第二,许多词元损失伴随训练呈现明显波动,难以收敛。图3(b)与©显示部分 L → L \mathrm{L} \rightarrow \mathrm{L} L→L及 H → H \mathrm{H} \rightarrow \mathrm{H} H→H词元损失存在高方差(§D.2对原因内容做了可视化分析,确认多数为噪声词元,支持我们的假设)。
由此可见,词元损失曲线非整体损失的平滑下降,训练动态复杂。若能选取模型需重点学习的词元,或可稳定训练过程,提升数据利用效率。

2.2 选择性语言建模
总体思路 受文档级过滤中参考模型的启发,我们提出了词元级数据选择管线"选择性语言建模(Selective Language Modeling, SLM)",流程如图4。首先在高质量语料上训练参考模型(RM),用于评估待训练语料中每一词元的损失得分。然后仅针对有较高"剩余损失"的词元训练语言模型。直觉为高剩余损失词元更具可学习性,且与目标分布更匹配,有效排除低质量或无关词元。下面详细介绍。
参考模型训练 选用代表期望目标分布的高质量语料,训练参考模型RM,采用标准交叉熵损失。基于RM计算预训练语料中每个词元 x i x_i xi的参考损失 L R M \mathcal{L}_{\mathrm{RM}} LRM,公式为:
L R M ( x i ) = − log P ( x i ∣ x < i ) (1) \mathcal{L}{\mathrm{RM}}(x_i) = -\log P(x_i | x{<i}) \tag{1} LRM(xi)=−logP(xi∣x<i)(1)
此评分反映词元在参考分布下的困难程度,供后续筛选使用。
选择性预训练 标准的因果语言建模(CLM)损失为:
L C L M ( θ ) = − 1 N ∑ i = 1 N log P ( x i ∣ x < i ; θ ) (2) \mathcal{L}{\mathrm{CLM}}(\theta) = -\frac{1}{N}\sum{i=1}^N \log P(x_i | x_{<i}; \theta) \tag{2} LCLM(θ)=−N1i=1∑NlogP(xi∣x<i;θ)(2)
其中 θ \theta θ为模型参数, N N N为序列长度, x i x_i xi为第 i i i个词元, x < i x_{<i} x<i为其之前的词元。
SLM区别于CLM,针对与RM差异较大的词元重点施加损失。定义当前训练模型在词元 x i x_i xi上的损失为 L θ ( x i ) \mathcal{L}_\theta(x_i) Lθ(xi),则余量损失为:
L Δ ( x i ) = L θ ( x i ) − L R M ( x i ) (3) \mathcal{L}\Delta(x_i) = \mathcal{L}\theta(x_i) - \mathcal{L}_{\mathrm{RM}}(x_i) \tag{3} LΔ(xi)=Lθ(xi)−LRM(xi)(3)
引入词元选择比例 k % k\% k%,只选取拥有最高余量损失的前 k % k\% k%词元参与训练,交叉熵损失计算为:
L S L M ( θ ) = − 1 N × k % ∑ i = 1 N I k % ( x i ) ⋅ log P ( x i ∣ x < i ; θ ) (4) \mathcal{L}{\mathrm{SLM}}(\theta) = -\frac{1}{N \times k\%} \sum{i=1}^N I_{k\%}(x_i) \cdot \log P(x_i | x_{<i}; \theta) \tag{4} LSLM(θ)=−N×k%1i=1∑NIk%(xi)⋅logP(xi∣x<i;θ)(4)
这里, I k % ( x i ) I_{k\%}(x_i) Ik%(xi)为指示函数:
$$I_{k%}(x_i) = \begin{cases}
1 & \text{若 } x_i \text{拥有前 } k% \text{ 最高评分} \
0 & \text{否则}
\end{cases} \tag{5}$$
默认情况下,我们使用 L Δ \mathcal{L}_\Delta LΔ作为评分函数 S S S,保证损失仅施加在模型学习最有益的词元上。实际中,可对一个批次词元按余量损失排序,只计算前 k % k\% k%词元损失,无额外预训练成本,实现高效整合。

3 实验}
我们在数学及通用领域均执行了持续预训练,并设计了消融实验及多维度分析验证SLM的有效性。
3.1 实验设置}
参考模型训练 数学参考模型使用0.5B高质量数学相关词元组成的语料,混合了基于GPT的合成数据 Yu 等,2024;Huang 等,2024 与人工筛选数据 Yue 等,2024;Ni 等,2024。通用参考模型则从开源数据集(如Tulu-v2 Ivison 等,2023、OpenHermes-2.5 Teknium,2023等)编纂1.9B词元语料。参考模型训练3轮,学习率:1B模型 5 e 5e 5e- 5 5 5,7B模型 1 e 1e 1e- 5 5 5,采用余弦衰减策略。最大序列长度1B模型设2048,7B模型设4096,批次中包含多个样本。主实验中持续预训练模型与参考模型均以相同基础模型初始化。
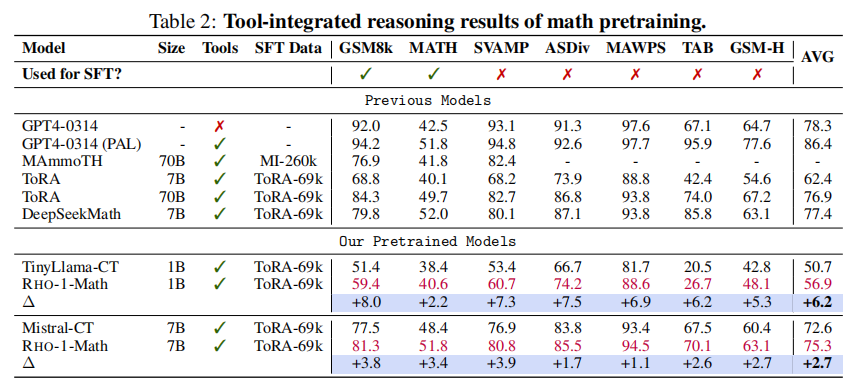
图4:选择性语言建模(SLM)管线示意。SLM通过聚焦预训练中的有价值且干净的词元,优化语言模型性能。主要三步包括:(步骤1) 在高质量数据上训练参考模型;(步骤2) 利用参考模型为语料中的每个词元评分;(步骤3) 只针对评分较高的词元进行训练。
预训练语料 数学领域采用OpenWebMath(OWM)数据集 Paster 等,2023,约14B词元,采自Common Crawl中数学相关网页。通用领域以SlimPajama Daria 等,2023和StarCoderData Li 等,2023a(均属于Tinyllama语料)联合OpenWebMath,共计训练80B词元,比例 6 : 3 : 1 6:3:1 6:3:1。
预训练配置 数学预训练基于Tinyllama-1.1B Zhang 等,2024和Mistral-7B Jiang 等,2023模型,学习率分别为 8 e 8e 8e- 5 5 5和 2 e 2e 2e- 5 5 5。1.1B模型在 32 × 32 \times 32× H100 80G GPU下,15B词元约需3.5小时,50B词元约12小时。7B模型训练15B词元约18小时。通用领域Tinyllama-1.1B学习率设 1 e 1e 1e- 4 4 4,在相同硬件下训练80B词元约19小时。批量大小统一为1M词元。词元选择比例,Tinyllama-1.1B为60%,Mistral-7B为70%。
基线设置 以采用常规因果语言建模的持续预训练模型(Tinyllama-CT和Mistral-CT)为主要基线。另与Gemma Team 等,2024、Qwen1.5 Bai 等,2023、Phi-1.5 Li 等,2023b、DeepSeekLLM DeepSeek-AI,2024、DeepSeekMath Shao 等,2024、CodeLlama Roziere 等,2023、Mistral Jiang 等,2023、Minerva Lewkowycz 等,2022、Tinyllama Zhang 等,2024、LLemma Azerbayev 等,2023及InternLM2-Math Ying 等,2024等知名强基线比较。微调结果对比包括MAmmoTH Yue 等,2024和ToRA Gou 等,2024。
评测配置 普通任务采用lm-eval-harness 4 { }^{4} 4 Gao 等,2023,数学任务自研评测套件 5 { }^{5} 5。推理加速采用vllm (v0.3.2) Kwon 等,2023。详见附录E。
3.2 数学预训练结果}
少样本链式思维推理 采用少样本链式思维(CoT)提示,遵循前沿工作 Wei 等,2022a;Lewkowycz 等,2022;Azerbayev 等,2023;Shao 等,2024。如表1,RHO-1-Math比直接持续预训练平均提升16.5%(1B模型)和10.4%(7B模型)。训练多轮后,平均少样本准确率进一步提升至40.9%。与基于500B数学词元预训练的DeepSeekMath-7B相比,RHO-1-7B使用仅15B词元(10.5B选中词元)实现了相当效果,彰显高效性。
工具集成推理 微调基于69k ToRA语料(含1.6万条GPT-4生成的工具集成推理轨迹和5.3万条LLaMA生成的答案增强样本)。结果见表2,RHO-1-1B与7B在MATH任务分别达到40.6%和51.8%的最新性能。部分未见训练任务(如TabMWP和GSM-Hard)RHO-1亦表现出良好的泛化能力,平均少样本准确率分别提升6.2%和2.7%。
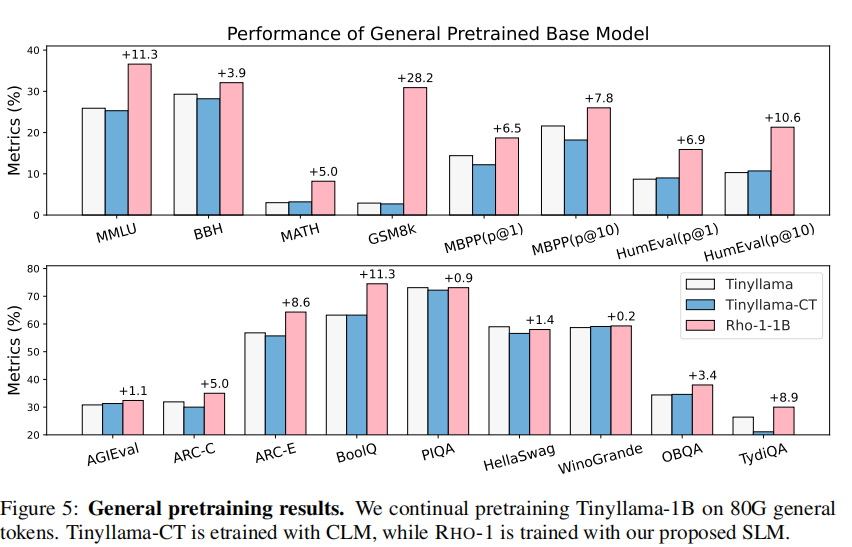
图5:通用预训练结果。持续预训练Tinyllama-1B共80G通用词元。Tinyllama-CT采用CLM训练,RHO-1采用我们提出的SLM训练。
3.3 通用预训练结果}
我们在80B通用词元上持续训练Tinyllama-1.1B验证SLM有效性。图5显示,尽管Tinyllama已就大部分词元充分训练,SLM仍比常规持续预训练平均提升6.8%(15个基准),代码和数学任务提升超10%。
3.4 自引用实验}
本节展示SLM无需额外高质量数据,仅凭预训练语料即可辅助模型训练效果提升。以OpenWebMath(OWM,Proof-Pile的子集)训练参考模型为例,评估OWM和PPile中词元,筛选后用于训练。此场景假定无下游相关数据,是常见现实情况。我们推测关键非评分准确性,而为过滤噪声词元。因此设计两种评分函数:参考模型损失 L R M \mathcal{L}{\mathrm{RM}} LRM与下一词信息熵 H R M \mathcal{H}{\mathrm{RM}} HRM(衡量下一词不确定度)。详情见附录H。
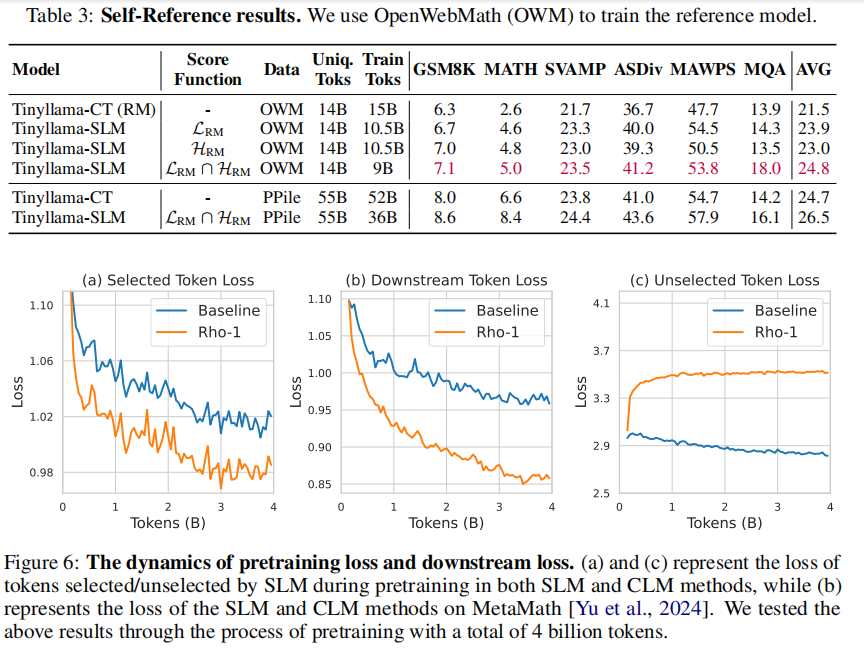
实验表明,使用仅OWM训练的参考模型亦可有效指导同语料预训练,平均下游性能提升 + 2.4 % +2.4\% +2.4%。单用信息熵作为评分函数获得类似结果。两种评分函数交集训练即筛选词元更精炼(减少40%)且性能更优,提升 + 3.3 % +3.3\% +3.3%。在仅用OWM训练参考模型情况下,SLM在PPile预训练仍带来 + 1.8 % +1.8\% +1.8%提升且用词元数减少30%。详见附录H。
3.5 消融与分析}
选择词元损失与下游性能更契合 我们利用参考模型筛词,并评估训练后验证集及下游损失。如图6所示,经过4B词元预训练统计,RHO-1在选中词元上的损失下降明显,较传统预训练对下游损失影响更显著,后者虽训练初期损失下降但对下游帮助有限。因此,选词训练更有效。
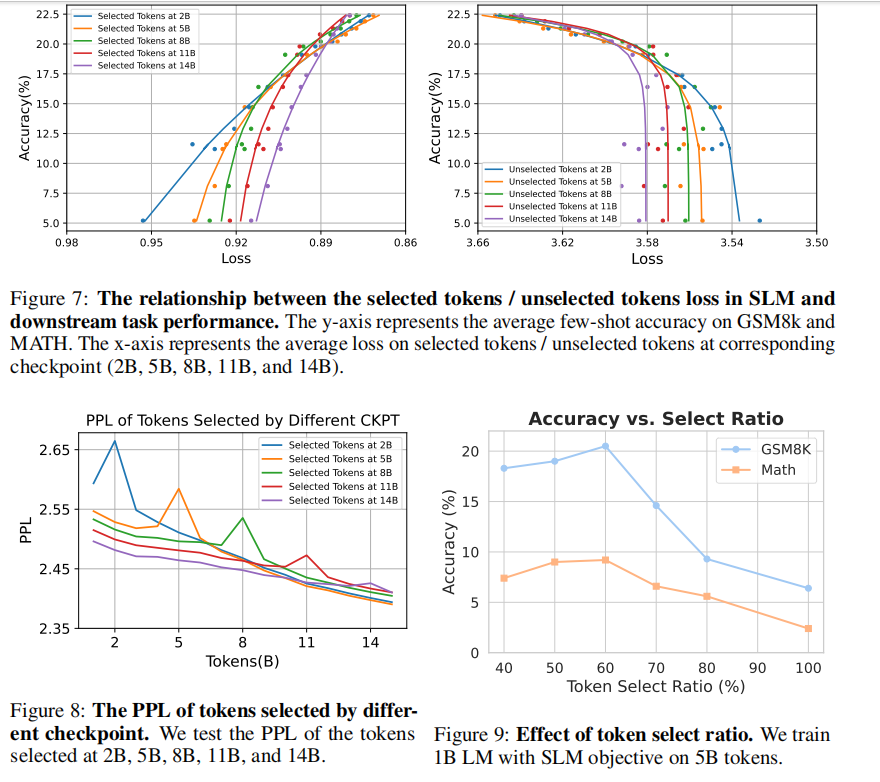
图6:(a)与©为SLM与CLM方法下预训练时,选中/未选词元的损失变化,(b)为SLM及CLM在MetaMath上的损失对比。训练4B词元。
图7揭示SLM选中词元损失与下游任务表现成幂律关系,验证 Gadre 等,2024 结果。SLM选中词元的损失下降促进性能提升,未选词元则负面影响模型表现,表明非所有词元损失均需降低方能获益。
图7:SLM中选中词元/未选词元损失与下游少样本准确率关系。纵轴为GSM8k与MATH平均准确率,横轴为相关检查点(2B、5B、8B、11B及14B)对应词元平均损失。
SLM筛选词元分析 为洞察SLM工作机制,我们可视化RHO-1训练中词元选择动态 (§G.1,蓝色表示实际被训练的词元)。观察表明,SLM筛选的词元与数学语义高度关联,令模型专注于语料中数学相关信息部分。
此外,我们分析不同训练检查点筛选词元差异,并测试词元在不同检查点上的困惑度。图8显示,后期筛选的词元训练后期困惑度趋高,早期困惑度较低,暗示模型优先优化未充分学习词元,提升学习效率。我们注意词元困惑度存在阶段性的"二次下降"现象 Nakkiran 等,2021,体现SLM依余量损失动态筛选最急需学习的词元。
图8:不同时期(2B、5B、8B、11B、14B)筛选词元的困惑度(PPL)随训练进程变化。
选词比例影响 我们探究SLM中词元选择比例对训练效果的影响。该比例多基于启发式定义,类似Masked Language Model (MLM) 的mask比例设定 Devlin 等,2019;Liu 等,2019。图9显示,约60%的词元被选中时,训练效果最佳。
图9:词元选择比例对1B模型在5B词元上训练性能影响。
4 结论
本文提出选择性语言建模(SLM)方法,通过选择更适合当前训练阶段的词元训练新的语言模型RHO-1。通过对预训练过程中词元损失的细致分析,发现词元价值存在显著差异,并非所有词元对模型训练同等重要。我们在数学及通用领域的实验和分析充分验证了SLM的有效性,强调了词元级别在LLM预训练中的关键地位。未来,从词元视角提升预训练效率与表现值得深入研究。
致谢
郑浩林、陈林感谢国家重点研发计划(编号2022ZD0160501)、国家自然科学基金(编号62372390、62432011)支持。耿志斌、杨宇久感谢深圳市科技计划(JCYJ20220818101001004)及平安科技(深圳)有限公司"图神经网络项目"支持。