SatLM: Satisfiability-Aided Language Models Using Declarative Prompting
原文代码
标题翻译:SATLM:使用声明式提示的语言模型SAT辅助
1. 简介
1.1. 研究问题
文章提出了SATLM方式,使用LLM生成声明性任务规范,而不是命令式程序,并利用现成的自动定理证明器推导最终答案
1.2. SAT问题
SAT(可满足性问题 )通常涉及布尔变量 (Boolean Variables)和逻辑运算符(Logical Operators),问题的核心是找到一组变量赋值,使整个公式成立。
SAT问题广泛应用于逻辑推理、硬件验证、软件验证、组合优化和密码分析。
1.3. 命令式&声明式
解决一个复杂的推理问题涉及三个概念成分:
- 解析:将自然语言描述解析为问题的表示
- 规划:推导出解决问题的方案
- 执行:并执行该方案以获得答案

- CoT 方法是一种命令式(imperative)的推理方式 ,主要流程如下:
- LLM解析问题,将自然语言问题转换为一系列推理步骤
- LLM规划推理过程,决定如何分步求解问题(例如数学计算或逻辑推理)
- LLM执行推理步骤,依次执行计算并得到最终答案
这其中存在的问题:
- 规划错误(Planning Errors):LLM可能错误地设计推理步骤导致错误答案
- 计算错误(Execution Errors):LLM在计算过程中可能出错
- 作者提出的SATLM 采用声明式(declarative)方法 ,核心思想是让LLM只负责解析问题,不做推理计算 :
- LLM解析问题:从自然语言输入中提取出逻辑约束(constraints)
- LLM生成声明式任务规格:将问题转换为一个SAT逻辑公式(布尔约束)
- 利用SAT求解器进行推理,减少了使用LLM推理的错误率
这样就能大大减少规划错误的问题(并没有完全避免,解析过程的错误(如生成的逻辑约束不完全或不准确)仍然可能导致规划错误),而且加上使用求解器完全避免了计算错误
2. 方法
2.1. 总流程
推理任务是关于一组关于某些对象的自然语言描述事实集合Φ(命题或约束),以及与这些对象相关的查询问题Q。目标是找到可以从Φ中提供的信息中推断出Q的答案。
在论文中,研究者提出Satisfiability-Aided Language Modeling(SATLM),即:
- 用LLM解析自然语言问题,生成布尔逻辑公式(SAT约束)。
- 用SAT求解器(如 Z3) 解决该约束问题,确保推理正确性。
- 避免LLM的规划和计算错误,提高逻辑推理的精确度。
2.2. 方法对比

- 传统Chain-of-Thought (CoT ) 方法:
- LLM解析问题,直接生成逐步推理过程
- LLM规划求解步骤,一步步解出答案
- LLM执行计算,得到最终答案
规划和计算过程都有可能出错
- ProgramLM 采用LLM + 代码执行器的方式(PAL):
- LLM解析问题,将自然语言转换为程序代码(Python 代码)
- 代码执行器执行这段代码,计算出答案
如果LLM解析转换代码出现错误,程序仍然会执行错误的逻辑,得到错误答案
- SATLM 方法的整体框架:
- 仅使用LLM解析问题,转换成SAT逻辑公式
- 规划 + 执行采用SAT求解器来进行
由于SAT求解器的推理过程是符号化的,因此不会犯LLM计算错误,只要LLM解析正确,SATLM的最终答案一定是正确的
3. 实验
评估SATLM在8个数据集上的表现,涵盖4类任务 :算术推理,逻辑推理,符号推理,正则表达式合成
3.1. 实验配置
-
基线:
- standard prompting:LLM直接给答案
- COT
- PROGLM
-
数据集:
- GSM和GSM-SYS:用于算术推理,特别是代数问题和方程求解
- ALGEBRA:包含来自数学教材的代数题目,用于测试代数推理能力
- LSAT:模拟法学院入学考试,测试逻辑推理和复杂推理问题
- BOARDGAMEQA:涉及棋类和策略推理,测试对规则和约束的推理能力
- CLUTRR:用于测试多步推理,特别是家族关系和因果推理
- PROOFWRITER:需要构建复杂的推理证明,用于评估推理的深度和准确性
- COLOR:符号推理数据集,用于测试模型在抽象推理和约束推理中的能力,任务通常涉及根据给定的约束条件在一组彩色物体中进行推理,解决颜色分配或元素匹配等问题
- STRUCTUREDREGEX:用于正则表达式的合成,从自然语言描述生成正则表达式
-
解码方式:
- 贪婪解码
- 自我一致性解码

-
评测指标:
- 准确率(Accuracy):正确答案的比例
- 选择性准确率(Selective Accuracy):在只选择自信答案的情况下,模型的准确率
- 错误分析(Error Breakdown):分析不同类型的错误,如计算错误、规划错误
3.2. 实验结果
3.2.1. SATLM vs. CoT vs. ProgramLM
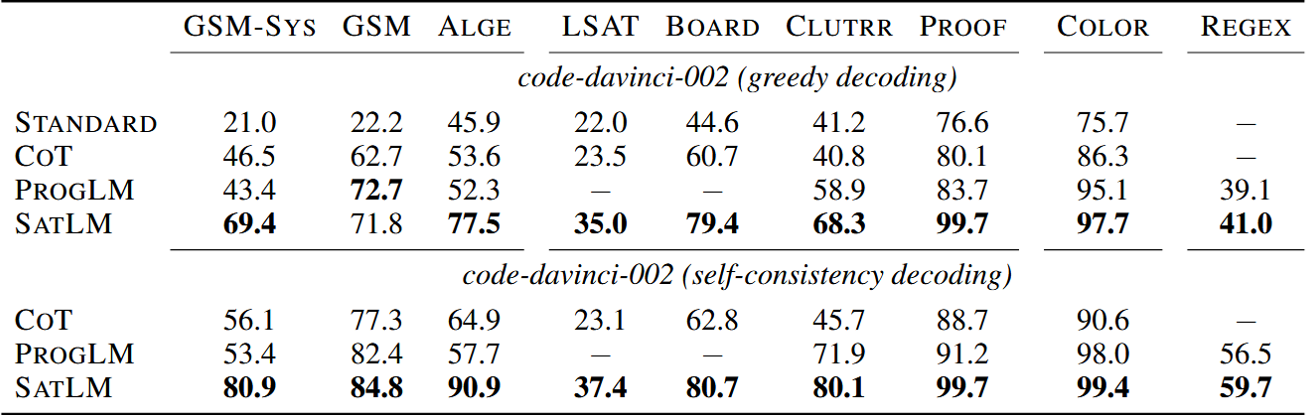
- SATLM 在所有数据集上都优于 CoT 方法,尤其在LSAT、BOARDGAMEQA、CLUTRR 这些逻辑推理任务上提升显著
- ProgramLM 在 GSM 上表现较好,但在更复杂的逻辑推理任务(如 LSAT)无法使用,因为代码执行器不适用于符号推理。
- SATLM 在 GSM-SYS 上提升了 23%,说明 SAT 求解器能有效解决涉及多个变量的数学问题。
- 在 REGEX 任务上,SATLM 和 ProgramLM 性能相近,说明 SAT 适用于某些字符串操作任务。
3.2.2. 消融实验
作者主要通过消融实验评估了以下两个方面:
- SAT 求解器的作用:通过去除 SAT 求解器来检验它对推理过程的影响。
- 声明式提示的效果:通过去除声明式提示(仅使用 CoT 风格的提示)来检验声明式方法的有效性。

结论:
- 去掉SAT求解器:只保留 LLM 解析问题并生成逻辑约束求解,准确率下降,效果和standard prompting差不多
- CoT + SAT 公式:将提示从声明式变为命令式,即让LLM不仅解析问题成SAT公式,还尝试根据自然语言推理步骤来解决问题。COT对比起直接出答案能提升一点效果,而且转换成SAT公式后能提升一定程度的COT推理能力
SATLM 在不同 LLM 上的泛化能力
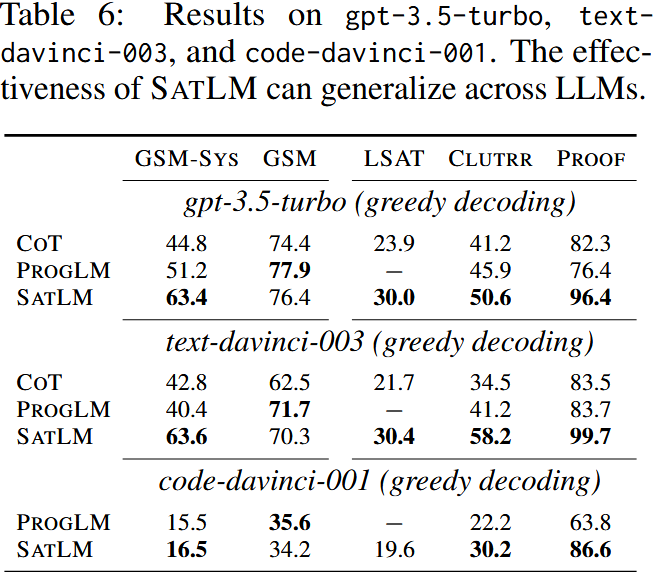
结论:SATLM在不同的 LLM 上都比 CoT 更强,说明声明式提示(Declarative Prompting)是通用方法。
4. 总结
SATLM框架将广泛的推理任务转化为SAT问题,并统一形式化,使用LLM将自然语言查询解析为声明性规范,并利用SAT求解器得出最终答案
限制 :
严重依赖SAT求解器,并且继承了求解器的一些限制:求解器只能处理可满足性问题且计算资源需求较大;对于一些复杂的推理问题(如包含大量连续变量、非线性约束、概率推理等),求解器可能不适用