1.简介
RAG(Retrieval-Augmented Generation)是一种结合了检索(Retrieval)和生成(Generation)的自然语言处理模型架构。 它旨在解决传统生成模型在面对复杂任务时可能出现的生成内容缺乏准确性和多样性的不足。在RAG模型中,首先会有一个检索模块,它会在一个庞大的外部知识库中检索与输入文本相关的片段或文档。这个知识库可以是预先构建的语料库,也可以是实时从互联网等来源获取的信息。**RAG模型通过检索模块引入外部知识,使得生成的内容能够更好地结合实际的背景知识,从而提高生成结果的质量和准确性。**例如在回答问题任务中,RAG可以通过检索找到与问题相关的具体信息,从而生成更准确的答案。
在实际应用中,RAG模型虽然表现优异,但由于其检索模块和生成模块的复杂性,可能会导致模型的训练和推理速度较慢,尤其是在处理大规模数据时。
随着研究的深入和技术的发展,人们在RAG的基础上进行了改进和优化,提出了LightRAG模型。LightRAG是对RAG模型的一种轻量化改进,旨在提高模型的效率和可扩展性,同时尽量保持RAG模型的性能优势。LightRAG通过优化检索模块的检索策略和生成模块的架构,减少了模型的计算量和参数规模。例如,它可能会采用更高效的检索算法来快速定位相关知识片段,或者对生成模块的解码器进行简化,减少不必要的计算。通过这些改进,LightRAG能够在保持较好生成质量的同时,显著提高模型的运行效率,使其更适合于实际的工业应用和在线服务场景,例如在需要快速响应的智能客服系统中,LightRAG能够更高效地生成准确的回答,提升用户体验。
在本博客中,我将基于Qwen2.5-3B和DeepSeek-R1-Distill-Qwen-32B(基于deepseek蒸馏的qwen模型),分别演示如何在单卡和多卡上部署LightRAG系统,并演示基于API(阿里云和Deepseek)如何构建LightRAG系统。
基本流程:
- 部署一个大模型(第2章),也可以直接调用云端大模型的API(第4章)
- 部署一个向量模型(第3章),也可以直接调用云端向量模型的API(第4章)
- 本地部署LightRAG(第4章),由LightRAG向大模型和向量模型发送请求,然后把结果返回给用户
显卡占用参考:
- 单卡24G部署可以跑起来7B的模型,但其上下文长度受限,建议使用3B模型或者7B的量化版本
- 8卡4090Ti 可以部署32B的模型,上下文可以拉满(32768),速度也很快。
- 如果需要部署DeepSeek v3 Int4量化版本,预估需要380G显存,8卡A100可高效部署
- 如果大模型是调用API的,本地只部署LightRAG,不会占用太大显存。
API费用参考:一次naive调用大约1w tokens,一次local调用约2w tokens
注意事项:
- RAG对上下文需求非常高,建议优先满足上下文的显存需求(如虽然单卡3090能跑7B模型,但其上下文受限)
- RAG对模型的理解能力要求较高,建议越强的越好。如果模型不够强,可能只能使用基本的naive模式,不过影响不大
阅读注意事项:
- 如果读者打算本地部署大模型,需阅读2-4章全部内容
- 如果读者打算使用API调用大模型 ,如阿里云百炼、DeepSeek,**可以直接阅读第四章,**跳过2-3章

LightRAG的github地址:https://github.com/HKUDS/LightRAG
参考博客:https://learnopencv.com/lightrag/#aioseo-legal-document-analysis-with-lightrag
2.基于vllm部署大模型
参考文档
vllm官方文档 :Engine Arguments --- vLLM
去年写的部署文章,供读者参考:Vllm进行Qwen2-vl部署(包含单卡多卡部署及爬虫请求)-CSDN博客
华为设备部署vllm,使用deepseek,官方文档:Multi-Node (DeepSeek) --- vllm-ascend
https://github.com/vllm-project/vllm-ascend/blob/main/README.zh.md
环境安装
我使用的是Python3.10的虚拟环境,注意下载好权重,不需要下载github代码。
首先安装torch、transformers等依赖库
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121
pip install transformers -U # 4.50.2
pip install accelerate==0.26.0接着安装vllm,我这里使用早期版本,读者可以尝试安装最新版本。
pip install vllm==0.6.3下载权重,这里以Qwen2.5-3B-Instruct和Qwen2.5-7B-Instruct为例:https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct
准备就绪后,可使用如下代码查看大模型是否能正常使用:(注意模型权重位置)
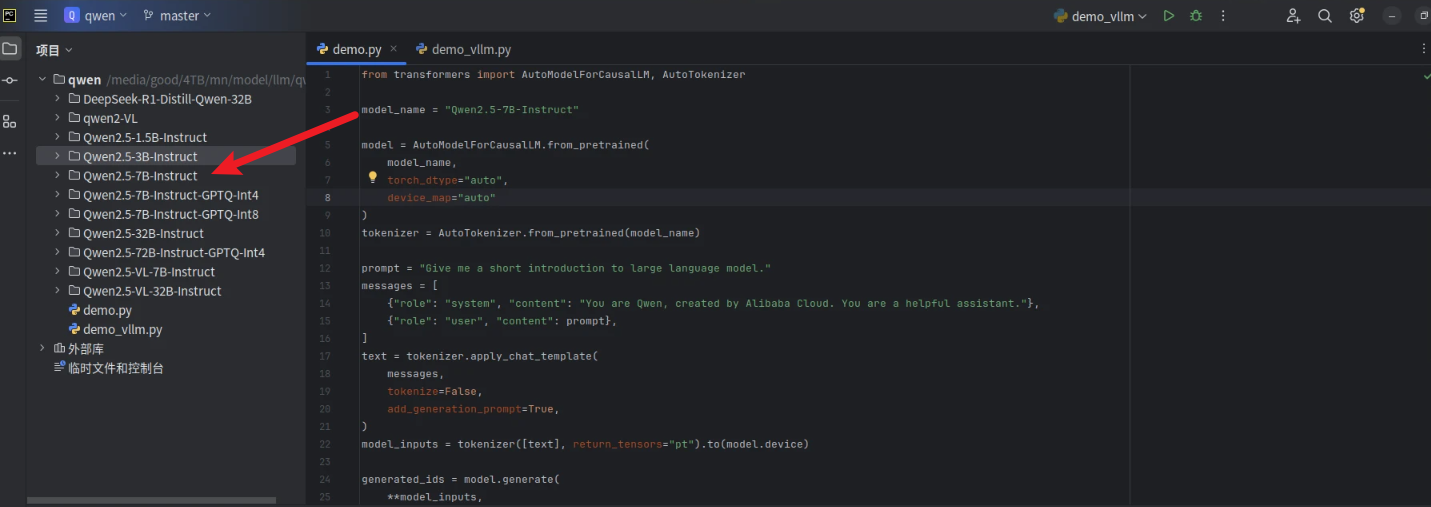
python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen2.5-3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)如果返回结果,表示安装成功。
准备就绪后即可启动vllm
单卡部署
我们可以在命令行输入以下命令
python
vllm serve Qwen2.5-3B-Instruct --dtype auto --port 8000 --gpu-memory-utilization 0.7 --max_model_len 32768出现以下界面,说明运行成功: 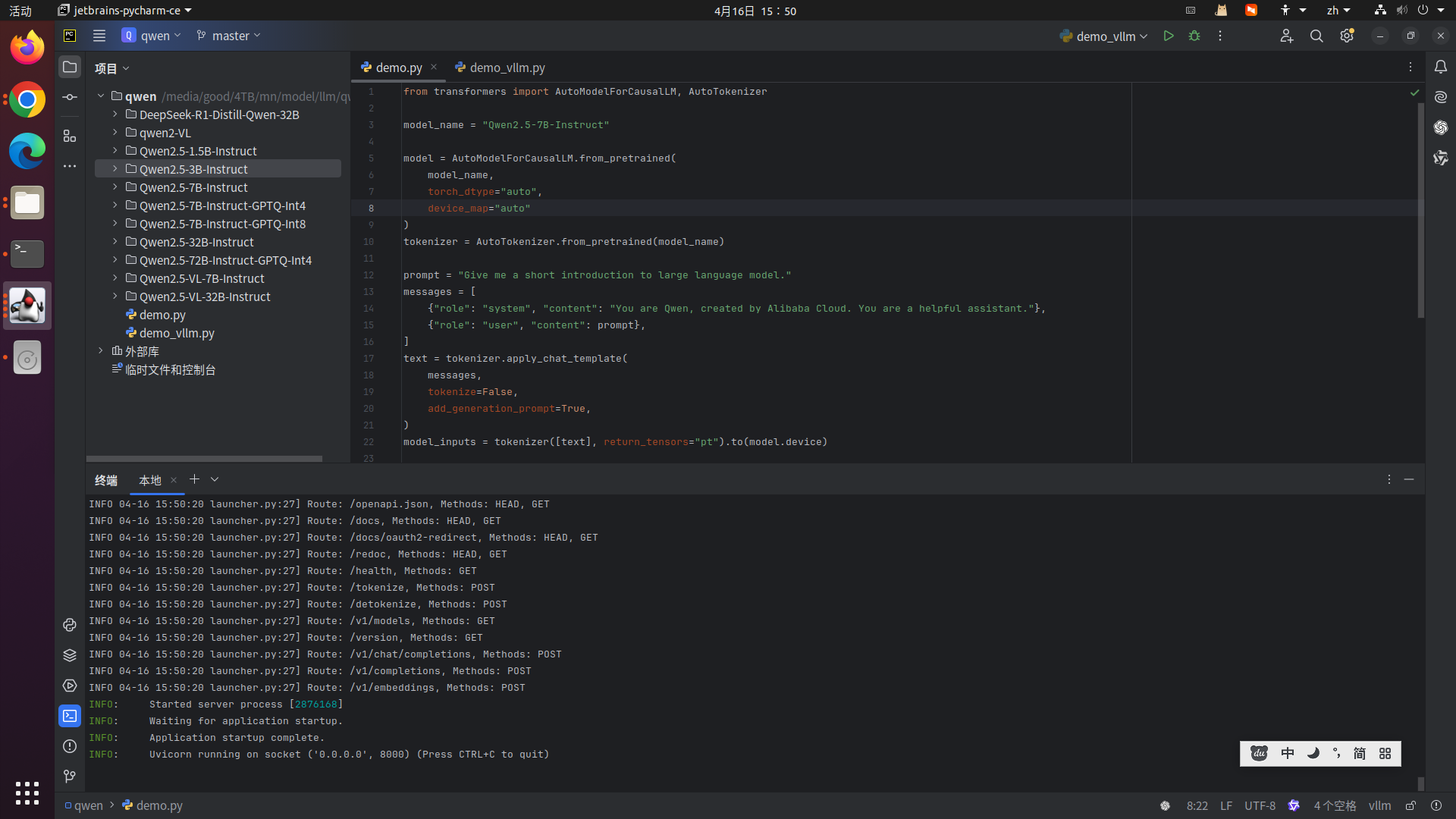
参数解释:
- Qwen2.5-3B-Instruct:模型权重位置
- dtype:数据类型,一般直接auto就可以了,低版本的显卡可能需要自己设置,如2080要设置为half
- port:端口号
- max_model_len:每次请求最大的token长度,爆显存了就改小,建议至少1w,RAG对长度需求较高
- gpu_memory_utilization:GPU最大利用率,爆显存了就改小,我现在一般设置为0.7-0.8
其他参数的文档:Engine Arguments --- vLLM
可以使用以下代码检查vllm是否能正常使用:(下面的代码中只需改URL和model即可)
python
import requests
import json
from PIL import Image
import base64
# 1.url
url = 'http://0.0.0.0:8000/v1/chat/completions' # 你的IP
# 2.data
data = {
"model": "Qwen2.5-3B-Instruct",
"messages": [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
# 系统命令,一般不要改
{"role": "user",
"content": "什么是大语言模型"}], # 用户命令,一般改这里
"temperature": 0.7, "top_p": 0.8, "repetition_penalty": 1.05, "max_tokens": 1024}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json_payload, headers=headers)
# 5.打印响应内容
# print(response.json().get("choices", [])[0].get("message", []).get("content", [])) # 命令行启动,用这个打印
print(response.json())多卡部署
在命令行中输入:
python
vllm serve Qwen2.5-32B-Instruct --dtype auto --port 8000 --tensor-parallel-size 4 --pipeline-parallel-size 2 --gpu-memory-utilization 0.7 --max_model_len 32768参数解释:
- tensor-parallel-size:模型的权重将被分割成n部分分布在GPU上。
- pipeline-parallel-size:设置流水线并行的大小为k,意味着模型的不同层将被分布到k个GPU上。
- 保证n*k=8,正好等于您拥有的GPU数量。
如果需要指定在某些卡上使用,可以使用如下命令:
python
CUDA_VISIBLE_DEVICES=4,5,6,7 vllm serve DeepSeek-R1-Distill-Qwen-32B --dtype auto --port 8000 --tensor-parallel-size 4 --pipeline-parallel-size 2 --gpu-memory-utilization 0.7 --max_model_len 1000032B可在4张4090卡上部署,但其上下文受限。
3.基于Fastchat部署向量模型
环境安装
在RAG领域,向量模型将文本数据(包括用户输入的查询和文档库中的内容)转换为向量形式,这些向量能够捕捉文本的语义信息,使得语义相似的文本在向量空间中距离更近。在检索阶段,向量模型通过计算用户查询向量与文档库中各个文档向量之间的相似度,快速找到与用户查询语义最相关的文档片段,这些向量化的上下文信息帮助生成模型更好地理解用户意图和背景知识,从而生成更准确、更有信息量的回答。
这里我们使用Fastchat部署向量模型,首先下载代码和权重:
fastchat:https://github.com/lm-sys/FastChat
向量模型权重:二选一即可,注意不要混用
- 单卡使用bge-large-zh-v1.5 :https://huggingface.co/BAAI/bge-large-zh-v1.5
- 多卡或大显存可以使用更好的bge-m3:https://huggingface.co/BAAI/bge-m3
位置如下:
安装依赖包:
python
pip3 install "fschat[model_worker,webui]"
pip install pydantic_settings模型部署
将如下脚本,保存为fastchat.sh:
python
#!/bin/bash
# 启动控制器
python -m fastchat.serve.controller --host 0.0.0.0 --port 21003 &
# 启动模型
python -m fastchat.serve.model_worker --model-path ./bge-large-zh-v1.5 --model-names gpt-4 --num-gpus 1 --controller-address http://0.0.0.0:21003 &
# 启动openai API服务器
python -m fastchat.serve.openai_api_server --host 0.0.0.0 --port 8200 --controller-address http://0.0.0.0:21003在命令行输入以下命令:
python
sh fastchat.sh出现以下界面说明运行成功:
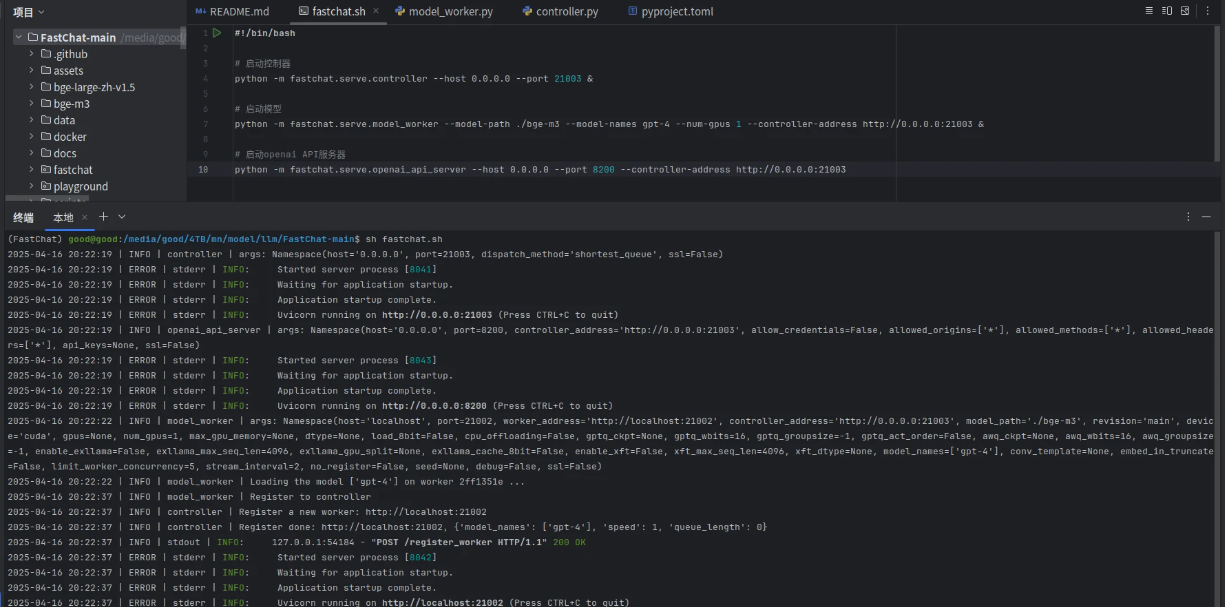
4.LightRAG部署
环境安装
python
# Both platforms
pip install -r requirements.txt
pip install nest_asyncio
pip install fastapi
pip install python-multipart
pip install uvicorn接着你要知道模型部署端或LightRAG部署端的IP地址,Linux通过ifconfig查看,如下红框中的就是你的IP地址:(本机使用可以直接0.0.0.0)

使用本地模型
examples/lightrag_api_openai_compatible_demo.py
需要设置大约36行处的参数:
python
LLM_MODEL = "Qwen2.5-3B-Instruct" # 你所使用的模型
EMBEDDING_MODEL = "gpt-4" # 不要改,只是起了一个名字,不影响任何东西
API_KEY = "666" # 本地模型没有 key,随便写一个
BASE_URL = "http://0.0.0.0:8000/v1" # 大模型的URL
EMBEDDING_URL = "http://0.0.0.0:8200/v1" # 向量模型的URL
EMBEDDING_MAX_TOKEN_SIZE = 32768 # 模型最大长度,根据模型和显存来设置
EMBEDDING = 1024 # 向量模型的向量维度,如bge是1024
MAX_ASYNC=10 # 最大并发数,根据显存和需求来设置,(超过了客户端会报错,但服务端还能继续执行,空闲后客户端可继续发请求)在第94行处,将RAG初始化代码更改为(不做更改也可运行,这里主要是设置了并发数限制):
python
async def init():
embedding_dimension = await get_embedding_dim()
embedding_dimension = EMBEDDING
rag = LightRAG(
working_dir=WORKING_DIR,
llm_model_func=llm_model_func,
llm_model_max_async=MAX_ASYNC,
max_parallel_insert=10, # 插入新文档时的并发数,根据设备自行设置
embedding_func=EmbeddingFunc(
embedding_dim=embedding_dimension,
max_token_size=EMBEDDING_MAX_TOKEN_SIZE,
func=embedding_func,
),
)
await rag.initialize_storages()
await initialize_pipeline_status()然后运行examples/lightrag_api_openai_compatible_demo.py即可
使用API调用云端大模型
使用API调用大模型就不用上述步骤,如果你没有设备,且数据不敏感,可以考虑直接调用API,方法如下:
阿里云百炼平台
获取API Key ,参考官方文档:https://bailian.console.aliyun.com/?tab=api#/api
选择模型 :https://bailian.console.aliyun.com/?tab=model#/model-market
(只需关注其中的文本模型和向量模型即可,在下面的配置中只需要更改LLM_MODEL和EMBEDDING_MODEL即可)
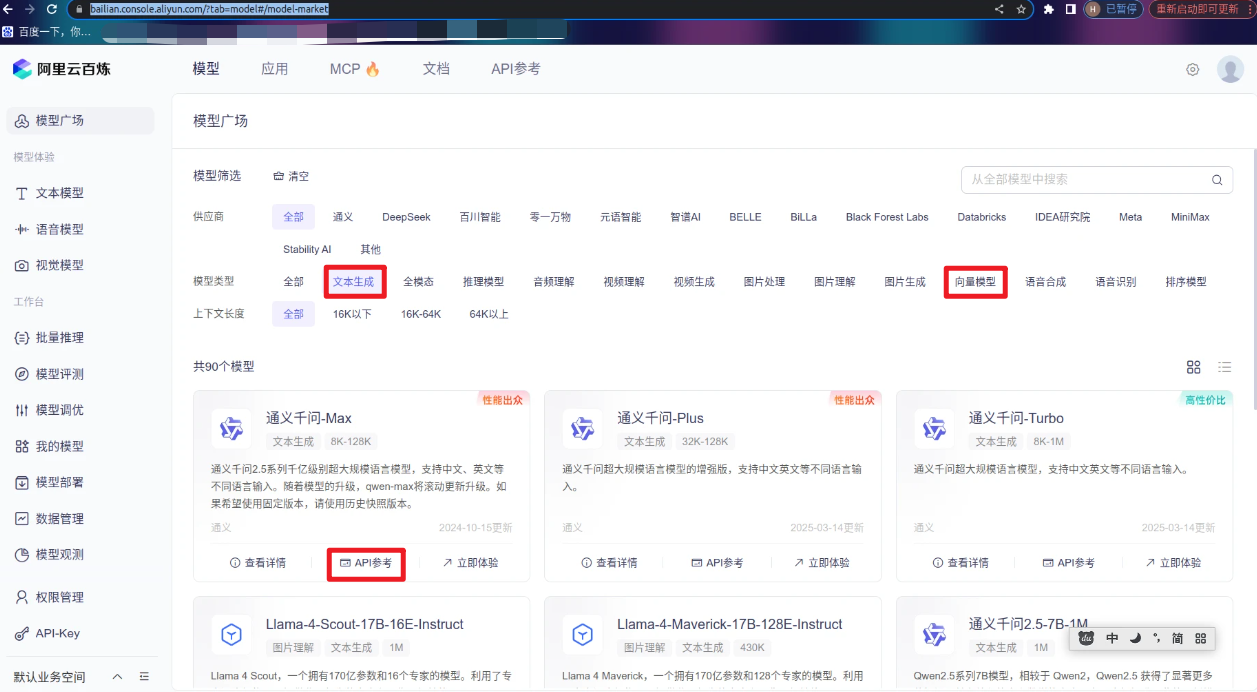
点击API参考 ,比如我们选择qwen-plus,仿照下图找到模型的名字,把这个改到下面的代码中的LLM_MODEL和EMBEDDING_MODEL即可
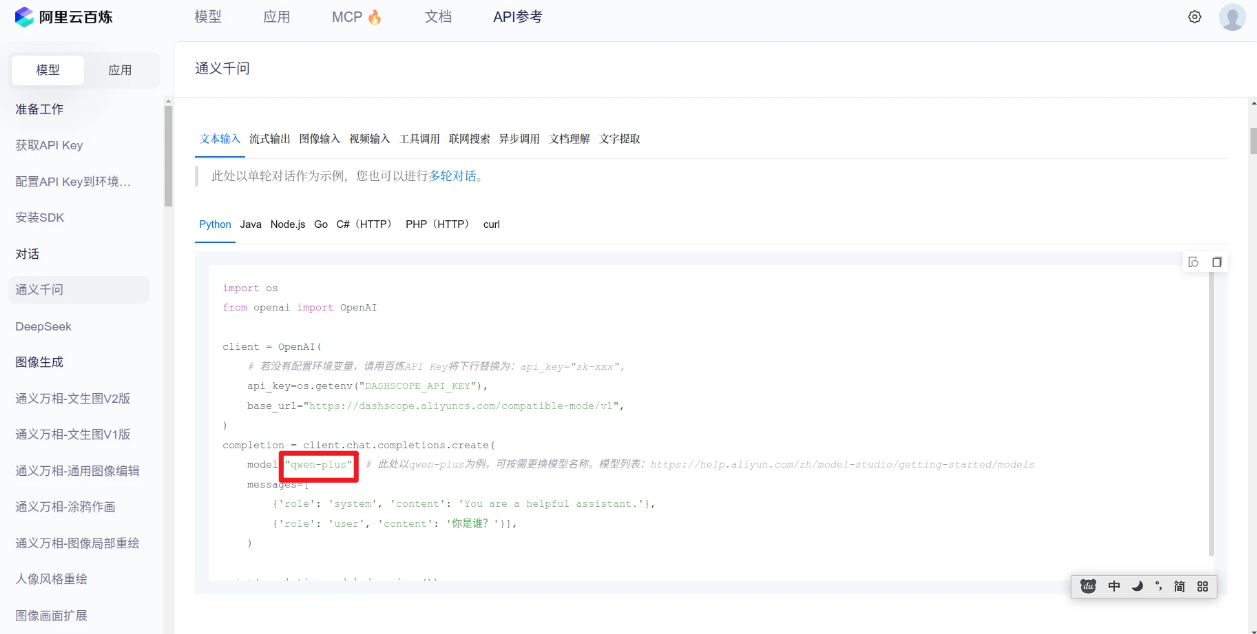 -
-
Deepseek
获取API key:DeepSeek
文档:首次调用 API | DeepSeek API Docs
使用阿里云,设置大约36行的参数为:
python
LLM_MODEL = "qwen-plus"
BASE_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云
API_KEY = "sk-XXXX"
EMBEDDING_MODEL = "text-embedding-v3"
EMBEDDING_URL = BASE_URL或DeepSeek:
需注意,DeepSeek没有向量模型,需另外找一个,不管本地部署还是云端模型
python
LLM_MODEL = "deepseek-chat" # deepseek
BASE_URL = "https://api.deepseek.com/v1" # deepseek
API_KEY = "sk-XXXXXXXXXXX" # Deepseek然后运行examples/lightrag_api_openai_compatible_demo.py即可
调用方法
首先运行examples/lightrag_api_openai_compatible_demo.py,如果使用本地模型,需先启动vllm,再启动fastchat,最后启动lightrag。
在使用过程中,我们需遵循以下步骤:
- 先使用insert或insert_file插入文档或文本
- 再使用query提问。
提问 query
使用如下代码即可,您只需要修改URL为LightRAG的服务器地址,然后修改query和mode即可
- mode包括:naive、local、global、hybrid,
- naive是标准rag
- local是使用图结构增强的RAG,其中图节点是具体的名词,
- global是使用图结构增强的RAG,其中图节点是抽象的名词
- hybrid是混合了local和global的结果
注意:小模型对于后三种模式的理解能力极差,小模型建议只使用naive
python
import requests
import json
import time
start_time = time.time()
# 1.url
url = 'http://0.0.0.0:8020/query' # 你的IP
# 2.data
# history [{"role": "user/assistant", "content": "message"}].
data = {"query": "江南大学是211吗?", "mode":"naive"}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json_payload, headers=headers)
# 5.打印响应内容
print(response.json().get("data", [])) # 用这个打印
# print(response.json())
print(f"耗时{time.time()-start_time}")结果演示:
是的,江南大学是一所"211工程"重点建设高校。作为中国教育部直属的全国重点大学,江南大学不仅被列入国家"211工程",还进入了"双一流"建设高校行列,体现了其在全国高等教育体系中的重要地位。
### 江南大学的背景
- **"211工程"**:该计划旨在重点支持一批高校发展成为国内高水平大学。江南大学因其在食品科学与工程、轻工技术与工程等领域的突出贡献而入选。
- **"双一流"建设**:江南大学在新一轮国家高等教育发展战略中被列为"世界一流学科建设高校",进一步巩固了其在国内和国际学术界的影响力。
### 学科优势
江南大学尤其以其食品科学与工程学科闻名,该学科在全球范围内具有很高的声誉。根据最新排名,江南大学的食品科学与工程学科连续多年位居世界第一(依据"软科世界一流学科排名")。
### 参考信息
以下是从知识库中提取的相关信息:
- 江南大学入选了国家"211工程"重点建设项目,表明其在全国高校中的重要地位。
- 学校还参与了"985工程优势学科创新平台"建设,并在多个领域取得了显著成就。
---
### References
1. [KG] 江南大学是"211工程"重点建设高校 (File: library/江南大学.txt)
2. [KG] 江南大学入选"双一流"建设高校 (File: library/江南大学.txt)
{'status': 'success', 'data': '是的,江南大学是一所"211工程"重点建设高校。作为中国教育部直属的全国重点大学,江南大学不仅被列入国家"211工程",还进入了"双一流"建设高校行列,体现了其在全国高等教育体系中的重要地位。\n\n### 江南大学的背景\n- **"211工程"**:该计划旨在重点支持一批高校发展成为国内高水平大学。江南大学因其在食品科学与工程、轻工技术与工程等领域的突出贡献而入选。\n- **"双一流"建设**:江南大学在新一轮国家高等教育发展战略中被列为"世界一流学科建设高校",进一步巩固了其在国内和国际学术界的影响力。\n\n### 学科优势\n江南大学尤其以其食品科学与工程学科闻名,该学科在全球范围内具有很高的声誉。根据最新排名,江南大学的食品科学与工程学科连续多年位居世界第一(依据"软科世界一流学科排名")。\n\n### 参考信息\n以下是从知识库中提取的相关信息:\n- 江南大学入选了国家"211工程"重点建设项目,表明其在全国高校中的重要地位。\n- 学校还参与了"985工程优势学科创新平台"建设,并在多个领域取得了显著成就。\n\n---\n\n### References\n1. [KG] 江南大学是"211工程"重点建设高校 (File: library/江南大学.txt)\n2. [KG] 江南大学入选"双一流"建设高校 (File: library/江南大学.txt)', 'message': None}
耗时0.013264656066894531包含历史记录(即多轮对话)的调用
官方代码支持多轮对话,但其lightrag_api_openai_compatible_demo.py没有写,所以我们需要先修改代码:
首先修改examples/lightrag_api_openai_compatible_demo.py第131行:
python
class QueryRequest(BaseModel):
query: str
mode: str = "hybrid"
only_need_context: bool = False
history_messages: list = []修改第151行:
python
@app.post("/query", response_model=Response)
async def query_endpoint(request: QueryRequest):
try:
loop = asyncio.get_event_loop()
# result = await loop.run_in_executor(
# None,
# lambda: rag.query(
# request.query,
# param=QueryParam(
# mode=request.mode, only_need_context=request.only_need_context
# ),
# ),
# )
history_messages = request.history_messages if request.history_messages else []
result = await rag.aquery(
request.query,
param=QueryParam(
mode=request.mode,
conversation_history=history_messages
),
)
return Response(status="success", data=result)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))接着我们就可以使用以下代码进行包含历史信息的调用
python
# 历史记录
start_time = time.time()
# 1.url
url = 'http://0.0.0.0:8020/query' # 你的IP
# 2.data
data_list = ["介绍一下江南大学?", "该校有什么强势学科吗?", "该学科的历史?"]
history_messages = []
for d in data_list:
# history [{"role": "user/assistant", "content": "message"}].
data = {"query": d, "mode": "naive", "history_messages": history_messages}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json_payload, headers=headers)
history_messages.append({"role": "user", "content": d})
history_messages.append({"role": "assistant", "content": response.json().get("data", [])})
# 5.打印响应内容
print(response.json().get("data", [])) # 命令行启动,用这个打印
print(response.json())
print("-"*50)
print(f"耗时{time.time()-start_time}")insert插入文本
insert可以直接往知识库中插入一段文本:
python
import requests
import json
from PIL import Image
import base64
# 1.url
# url = 'http://0.0.0.0:8020/insert' # 你的IP
# 2.data
data = {"text": "湖南大学图书馆特藏分馆它是长沙市近现代保护建筑,也是湖南大学九大"国保建筑"之一,前身可远溯至创建于北宋年间的岳麓书院御书楼,1929年12月学校开始兴建新图书馆,1933年竣工,但1938年毁于日军侵华战火,仅剩下几根残破的石柱,有两根就伫立在湘江边"湖南大学"的石刻旁,湖南大学老图书馆由蔡泽奉教授设计,是湖南大学定名后第一座现代意义的图书馆,亦是当时华中华南最大的图书馆,故宫国宝南迁时曾寄存于此。1947年,湖南大学策划重建老图书馆,由中国近现代建筑师、建筑教育家柳士英先生设计,于1949年竣工,此后,1951年进行了扩建,与原馆完全融为一体,总面积约2400平方米,成为我们今日所见的特藏分馆。被载入长沙市近现代建筑保护名单,1985年,湖南大学新建的总图书馆竣工,老图书馆则作为工商管理学院院楼使用,至2006年恢复作为图书馆的使用功能",}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json_payload, headers=headers)
# 5.打印响应内容
# print(response.json().get("choices", [])[0].get("message", []).get("content", [])) # 命令行启动,用这个打印
print(response.json())返回结果为以下时,说明成功:
{'status': 'success', 'data': None, 'message': 'Text inserted successfully'}insert_file插入文档
txt文档可以直接使用insert_file进行插入,而pdf文档需要借助如pdfplumber或textract进行解析,再插入其中,示例代码如下:只需更改URL和file_path即可
python
import requests
import pdfplumber
import json
import os
import time
# 定义上传文件的接口地址
url = "http://0.0.0.0:8020/"
# 定义要上传的文件路径
file_path = "library/江南大学.txt"
# file_path = "library/重庆大学_百度百科.pdf"
if file_path.split(".")[-1] == "txt": # 如果是txt文件,则直接上传文件
# 打开文件并发送 POST 请求
with open(file_path, "rb") as f:
files = {"file": (file_path, f)} # "file" 是接口期望的字段名
response = requests.post(url+"insert_file", files=files)
elif file_path.split(".")[-1] == "pdf": # 如果是pdf文件,则先提取pdf中的文本,然后上传文件
pdf_text = ""
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
pdf_text += page.extract_text() + "\n"
data = {
"text": pdf_text,
"file_name": [file_path.split(".")[-2]]}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url+"insert", data=json_payload, headers=headers)
# 打印响应内容
print(response.status_code)
print(response.text)
# print(pdf_text)注意:也可使用lightrag_openai_compatible_demo.py先插入文档内容,插入后再部署RAG
包含文献来源的插入
首先修改examples/lightrag_api_openai_compatible_demo.py第187行代码:(这个修改主要是为了增加文档名字file_name,即RAG中文献来源的)
python
@app.post("/insert_file", response_model=Response)
async def insert_file(file: UploadFile = File(...)):
try:
file_content = await file.read()
file_name = file.filename
# Read file content
try:
content = file_content.decode("utf-8")
except UnicodeDecodeError:
# If UTF-8 decoding fails, try other encodings
content = file_content.decode("gbk")
# Insert file content
loop = asyncio.get_event_loop()
await loop.run_in_executor(None, lambda: rag.insert(content, file_paths=file_name))
return Response(
status="success",
message=f"File content from {file.filename} inserted successfully",
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))如果需要对insert插入文件来源,操作如下:
更改138行:
python
class InsertRequest(BaseModel):
text: str
file_name: str = None更改178行
python
@app.post("/insert", response_model=Response)
async def insert_endpoint(request: InsertRequest):
try:
loop = asyncio.get_event_loop()
await loop.run_in_executor(None, lambda: rag.insert(request.text, file_paths=request.file_name))
return Response(status="success", message="Text inserted successfully")
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))下面的代码只改pdf的部分,因为txt部分上传文档,只需要服务端处理即可。
python
import requests
import pdfplumber
import json
import os
import time
# 定义上传文件的接口地址
url = "http://0.0.0.0:8020/"
# 定义要上传的文件路径
file_path = "library/江南大学.txt"
# file_path = "library/重庆大学_百度百科.pdf"
if file_path.split(".")[-1] == "txt": # 如果是txt文件,则直接上传文件
# 打开文件并发送 POST 请求
with open(file_path, "rb") as f:
files = {"file": (file_path, f)} # "file" 是接口期望的字段名
response = requests.post(url+"insert_file", files=files)
elif file_path.split(".")[-1] == "pdf": # 如果是pdf文件,则先提取pdf中的文本,然后上传文件
pdf_text = ""
with pdfplumber.open(file_path) as pdf:
for page in pdf.pages:
pdf_text += page.extract_text() + "\n"
data = {
"text": pdf_text,
"file_name": [file_path.split(".")[-2]]}
# 3.将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 4.发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url+"insert", data=json_payload, headers=headers)
# 打印响应内容
print(response.status_code)
print(response.text)
# print(pdf_text)经过上述修改后,知识库中就会有文档来源等相关信息,模型也会返回参考文献的名字,帮助用户进一步检索相关文档。如下:
"chunk-d7df3bb3d2949b3cbea9291c6fa24a8f": {
"tokens": 300,
"content": "部卷动的波浪也像一摞书籍,可谓"书山有路勤为径,学海无涯苦作舟",体现了江南大学人"笃学尚行、止于至善"的精神。\n校标的标准色名为"江南绿",象征雨丝浸润下的江南水色。沉稳的基调符合江南大学严谨的、以工科为主体的治学、办学特色。\n校标上的江南大学校名,字体采用毛体"江南大学"("学"字为简体),英文名字采用"江南"两字音译方案,即定名为"Jiangnan University"。中英文对照融世界性眼光和传统化特色为一体,表达了江南大学立足传统,面向世界,开拓未来的理念,寓意着创建国内外知名的特色鲜明高水平大学的决心。\n校旗\n学校校旗为白色长方形旗帜,中央分别印有江南绿色、规定字体的"江南大学"校名、校名英译全称和校标。\n吉祥物\n学校吉祥物为"太湖神鼋",源于太湖地区"震泽神鼋",象征着坚韧执着、勇于拼搏、奋发向上的精神。",
"chunk_order_index": 4,
"full_doc_id": "doc-3cfdc1b74c6aaf7b99bc05b7d806f0a9",
"file_path": "library/江南大学.txt"
},缓存目录
我在lightrag_api_openai_compatible_demo.py中设置了工作目录,如下:
python
DEFAULT_RAG_DIR = "dickens"
# Configure working directory
WORKING_DIR = os.environ.get("RAG_DIR", f"{DEFAULT_RAG_DIR}")在dickens文件夹下,我们可以看到如下结构:
python
dickens
--graph_chunk_entity_relation.graphml # 抽取的图结构
--kv_store_doc_status.json # 文档状态
--kv_store_full_docs.json # 完整文档内容
--kv_store_llm_response_cache.json # LLM返回结果的缓存
--kv_store_text_chunks.json # 文档切分结果
--vdb_chunks.json # 向量数据库
--vdb_entities.json # 向量数据库
--vdb_relationships.json # 向量数据库建议重点关注以下几个:
kv_store_doc_status.json记录了插入文本的状态,其中:
- processed:已处理完
- pending:排队中
- processing:处理中
kv_store_full_docs.json记录了插入文本的完整内容
kv_store_llm_response_cache.json记录了大语言模型的回答的缓存,已有问题直接掉缓存,不需要大模型回答。
通用设置
在lightrag/prompt.py下,将部分内容更改为中文:
更改大约第8行处:
python
PROMPTS["DEFAULT_LANGUAGE"] = "中文"更改大约194行处:
python
PROMPTS["fail_response"] = (
"对不起,我无法回答这个问题。【知识库中没有相关内容!】"
)在lightrag/llm/openai.py下大约275行,改为,防止超出长度报错:
python
response = await openai_async_client.embeddings.create(
model=model, input=[i[:500] if len(i) > 500 else i for i in texts], encoding_format="float"
)交互界面
我使用gradio写了一个交互界面,供大家参考。
python
import json
import requests
import threading
import gradio as gr
# 定义后端 URL
url = 'http://0.0.0.0:8020/query' # 你的IP
# url = 'http://10.7.13.23:8020/query' # 你的IP
# 定义查询函数
def query_model(user_input, mode, history_messages):
mode_dict = {
"标准": "naive",
"局部": "local",
"全局": "global",
"混合": "hybrid"
}
# 构造请求数据
data = {"query": user_input, "mode": mode_dict[mode], "history_messages": history_messages}
# 将字典转换为 JSON 字符串
json_payload = json.dumps(data)
# 发送 POST 请求
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json_payload, headers=headers)
# 获取响应内容
response_data = response.json().get("data", [])
# 更新历史消息
history_messages.append({"role": "user", "content": user_input})
history_messages.append({"role": "assistant", "content": response_data})
# 返回助手的回复和更新后的历史记录
return response_data, history_messages
# 定义 Gradio 界面
with gr.Blocks() as demo:
gr.Markdown("# 模型问答界面")
gr.Markdown("在这个界面中,你可以与模型进行交互,并自由切换不同的模式。\n")
gr.Markdown("标准模式是标准RAG,能够快速响应问题;局部提取局部(实体级)关键词;全局提取全局(主题级)关键词;混合模式提取局部和全局提示词")
chatbot = gr.Chatbot(label="对话记录")
history_state = gr.State([]) # 用于存储每个用户的会话历史
with gr.Row():
user_input = gr.Textbox(label="输入你的问题", placeholder="请输入问题...", scale=4)
mode_selector = gr.Dropdown(
choices=["标准", "局部", "全局", "混合"],
value="标准",
label="选择模式",
scale=2
)
submit_button = gr.Button("提交", scale=1)
def update_chat(history, user_message, mode, history_state):
# 使用多线程处理请求
def process_request():
nonlocal history, history_state
assistant_response, updated_history = query_model(user_message, mode, history_state)
history.append((user_message, assistant_response))
history_state = updated_history
# 创建并启动线程
thread = threading.Thread(target=process_request)
thread.start()
thread.join() # 等待线程完成(如果需要异步效果,可以去掉这行)
return history, history_state
submit_button.click(
fn=update_chat,
inputs=[chatbot, user_input, mode_selector, history_state],
outputs=[chatbot, history_state]
)
# 启动 Gradio 应用
demo.launch()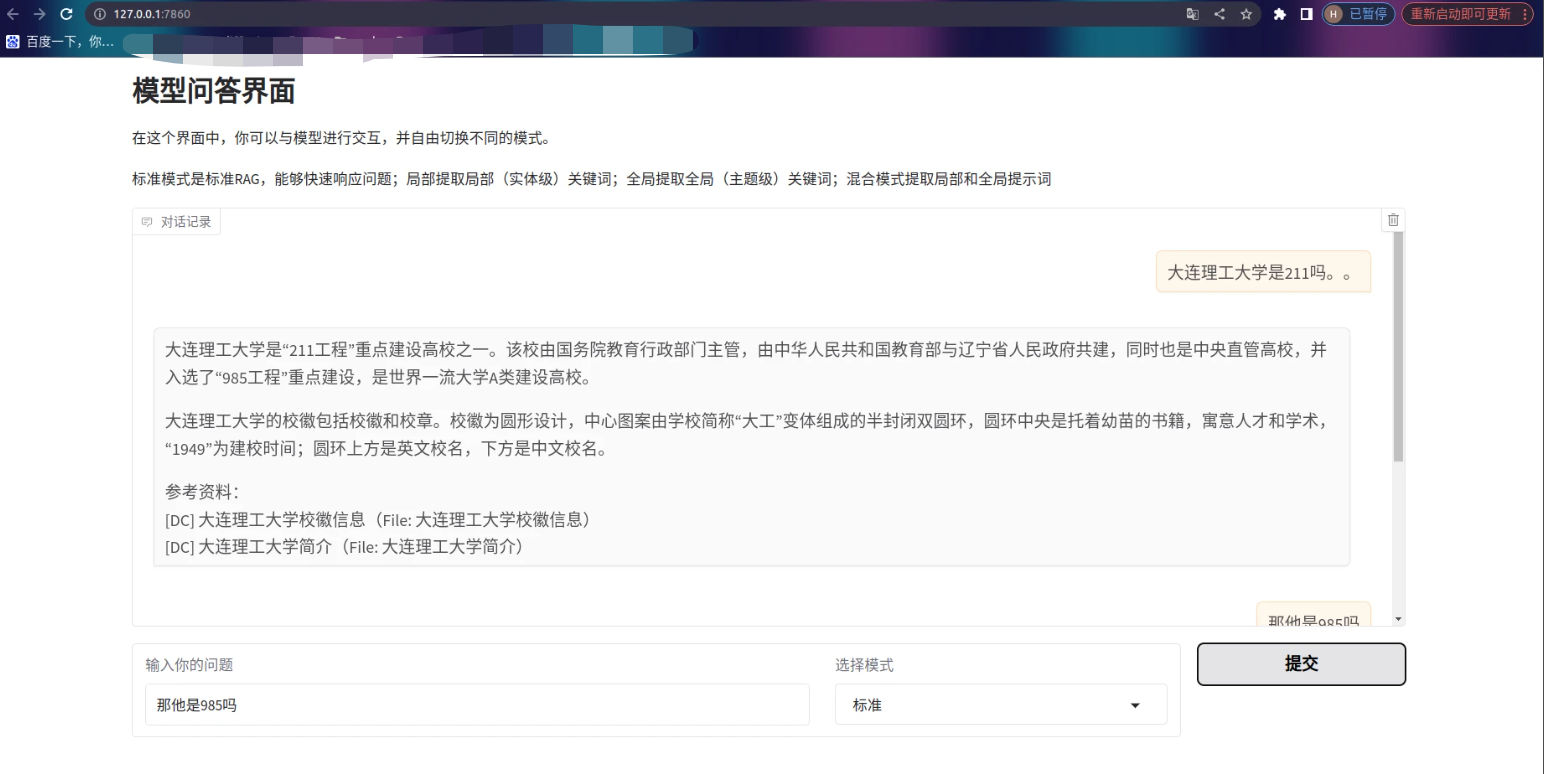
总结
本地部署RAG(Retrieval-Augmented Generation)系统具有诸多显著优势,这些优势主要体现在以下几个方面:
- 从数据安全和隐私保护的角度来看,本地部署能够确保数据在本地环境中进行处理和存储,避免了数据传输到云端或第三方平台可能带来的泄露风险。这对于处理敏感信息或受法律严格监管的数据(如医疗记录、金融数据等)尤为重要。企业或机构可以完全掌控数据的访问和使用权限,从而更好地满足数据合规性要求。
- 在性能优化方面,本地部署可以根据具体的应用场景和硬件环境进行定制化配置。通过优化检索算法和调整模型参数,可以实现更高效的检索和生成性能,减少延迟,提高系统的响应速度。此外,本地部署还可以根据实际需求灵活扩展硬件资源,以应对不同的负载需求,从而更好地满足业务的性能要求。
- 成本控制也是本地部署的一大优势。虽然初期需要投入一定的硬件和软件成本,但长期来看,本地部署可以避免因使用云端服务而产生的持续订阅费用。对于大规模数据处理和高频率的模型调用场景,本地部署的成本效益尤为明显。同时,企业还可以根据实际使用情况合理配置资源,避免资源浪费,进一步降低运营成本。
- 本地部署还提供了更高的灵活性和可定制性。企业可以根据自身的业务需求对RAG系统进行深度定制,包括对检索模块的优化、对生成模型的微调以及对整体架构的调整等。这种灵活性使得系统能够更好地适应特定领域的应用场景,例如在医疗、法律、金融等专业领域,可以根据行业特点和用户需求进行针对性的优化,从而提供更精准、更有价值的服务。
- 此外,本地部署便于进行系统的维护和管理。企业可以自主安排维护时间,快速响应可能出现的技术问题,及时进行系统更新和优化。这种自主性使得企业能够更好地掌控系统的稳定性和可靠性,减少因外部因素导致的系统中断或故障风险。
- 最后,本地部署RAG系统能够更好地支持离线应用。在一些网络条件不稳定或无法联网的环境中,本地部署的系统可以独立运行,不受网络限制。这对于一些需要在特定环境下(如偏远地区、军事设施等)使用RAG技术的应用场景具有重要意义,确保了系统的可用性和可靠性。
综上所述,本地部署RAG系统在数据安全、性能优化、成本控制、灵活性、维护管理以及离线应用支持等方面具有显著的优势,能够为企业和机构提供更加可靠、高效和定制化的解决方案,满足多样化的业务需求。
如果你喜欢我的内容,记得点赞、关注、收藏哦!你的支持是我不断进步的动力,也让我更有信心继续创作。点赞是对我努力的认可,关注是对我持续分享的信任,收藏则是方便你随时回顾。感谢有你,让我们一起成长!🎉💖📚