一、模型概述
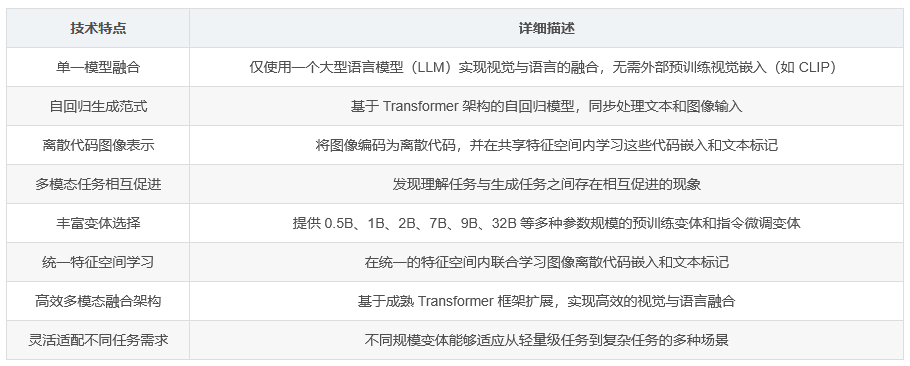
Liquid 是一种创新的自回归生成范式,其核心优势在于能够无缝整合视觉理解与内容生成。该模型通过将图像转化为离散代码,并在统一的特征空间内同时学习这些代码嵌入和文本标记,从而实现了视觉与语言的深度融合。与传统多模态大型语言模型(MLLM)不同,Liquid 仅依赖单一的大型语言模型(LLM),完全摒弃了对外部预训练视觉嵌入(例如 CLIP)的依赖。
研究团队对这种多模态混合模型的扩展规律进行了深入探索,并发现了理解任务与生成任务之间相互促进的独特现象,即模型在执行视觉理解任务时能够提升生成任务的性能,反之亦然。
二、技术细节
Liquid 的技术架构基于成熟的 Transformer 框架进行扩展,延续了自回归模型的特性。在模型训练过程中,文本和图像数据被同步输入到模型中。图像部分经过特殊的编码处理转化为离散代码,这些代码与文本标记共同在共享的特征空间内进行学习,使得模型能够捕捉到视觉与语言之间的深层关联。
这种创新的融合方式使得 Liquid 在处理多模态任务时表现出了更高的效率和更强的适应性。模型通过联合学习的方式,能够更自然地理解图像内容,并基于这种理解生成相关的文本描述,或者根据文本指令生成相应的图像内容。
三、模型变体
Liquid 提供了丰富多样的变体以满足不同场景的需求,参数规模涵盖 0.5B、1B、2B、7B、9B、32B 等多个级别。其中,预训练变体提供了从 0.5B 到 32B 参数规模的完整家族,而指令微调变体则以 7B 参数规模为代表,基于 GEMMA 进行了专门优化。
这些不同规模的变体使得 Liquid 能够灵活适应各种计算资源限制和任务复杂度要求。较小规模的变体适合资源受限环境下的快速部署和轻量级任务处理,而较大规模的变体则能够在复杂任务中提供更深层次的理解和更高质量的生成结果。