前言
python作为一款不怎么关注数据类型的语言,不同类型的数据 可以往同一个变量 中放置
这也就直接导致,作为熟悉C++这种一个变量只有一个类型的程序员来说,在解读python程序时,想搞清楚变量中到底存的是什么数据类型的时候时常很头疼
所以说,良好的编程习惯真的很重要
虽然上面的话跟这篇文章关系不大,但是我就是想吐槽一下 ;p
下面是我优化某个python项目的其中某个模块的内存时,对python中的numpy/pandas库调研得出的一些优化操作,在此分享给大家
注:有的地方我理解的也不是很透彻 ,在此仅作为心得记录 ,有任何不对的地方欢迎在评论区进行指正
一、通用优化操作
1. 指定合适的数据类型
如果数据的值域可以限制在较小的范围内,可手动指定其dtype类型进行限制
2. 避免copy
1)切片/索引层面
切片或其他索引方式中是否涉及拷贝,这部分就主要决定于各个库中具体实现细节了,可看下面对应章节部分
-
原生python拷贝数组时注意的一个小细节:
pythonlist1 = [...] 1.类似浅拷贝/引用,操作对象为同一个,无copy,操作list2就是操作list1: list2 = list1 2.类似深拷贝,涉及copy,list2与list1不是同一个对象: list2 = list1[:]
2)计算过程层面
如果输入数据可以"原地 "处理 ,且可以把计算过程拆分成"原地"处理的步骤,或是库里提供了可以"原地"计算的函数,则尽量进行拆分和替换"原地"处理的函数
下面是数组归一化时,将步骤进行拆分节省内存的一个例子:
-
简单的实现,但是会产生临时数组的内存开销
pythondef Normalize(lst : list): lst_range = lst.max - lst.min return (lst - lst.min) / lst_range -
拆分步骤,每一步都是"原地"操作
pythondef Normalize(lst : list): lst_range = lst.max - lst.min lst -= lst.min lst /= lst_range
3. 文件读取
- chunk读取:这个也算是流程优化的一部分
读取文件时是否是一次性读取完毕?分块读取是否会影响到流程?如果可以分块读取,那么读取接口是否有提供类似chunksize的参数?
一次读取的内容过多,一方面是会直接影响到IO内存,另一方面也是考虑到,大部分情况下实际要处理的数据并没有那么多,所以不如限制每次读取的数据大小,够用即可,用完再取 - index索引:如果输入数据是有组织有结构地进行存储,那么通常可以通过建索引的方式记录数据的关键信息,在需要取用的时候就能通过索引快速取用自己所需的部分,一方面加速处理速度,另一方面内存也能更低
4. 数据结构的选取
主要是选用跟实际需求更匹配的数据结构,比如dict会浪费至少30%以上的内存,如果条件允许,可以通过一系列的方式对其进行优化
- 换用自定义class
- class +
__slots__:加上限定,能省略class内的一些隐性内存开销 - namedtuple:同样是限定,但与tuple类似不可更改
- recordclass:基于namedtuple的可变变体(使用方式可看这里)
二、numpy相关
1. 使用sparse array
虽然ndarray适用于存储大量数据,但如果其中大部分数据都是空时,用稀疏矩阵能更省空间
2. 检查库方法的内部实现
库提供的方法为了泛用性,内部一般会对输入数据的类型进行限定,如果输入数据的类型与其预期不符,可能会造成更大的内存消耗
比如:一个库方法内部会将输入数据转为int64进行操作,如果输入的是int16,那么消耗内存会是int16 + int64,可能还不如把输入数据直接设置为int64并设置"原地"操作
3. indexing / slicing
numpy中有两种indexing方式,不同的方式返回值不同:可能返回view(类似浅拷贝/引用),也可能返回copy
-
判断view/copy方式:可以简单地通过
.base属性是否为None来判断 -
basic indexing:
[]中为slice/integer或一个元组(仅 包含slice/integer)时触发
与python原生list切片不同,返回view -
Advanced indexing:
[]中为非元组sequence / ndarray( of integer/bool)或一个元组(包含至少一个sequence/ndarray)时触发
返回copy
示例:python>>> import numpy as np >>> data1 = np.arange(9).reshape(3, 3) # reshape returns a view at most time >>> data1 array([[0, 1, 2], [3, 4, 5], [6, 7, 8]]) >>> data1.base array([0, 1, 2, 3, 4, 5, 6, 7, 8]) >>> >>> data2 = data1[[1, 2]] # data2 is a copy >>> data2 array([[3, 4, 5], [6, 7, 8]]) >>> data2.base >>> >>> data1[[1, 2]]=[[10, 11, 12], [13, 14, 15]] # change data1 >>> data1 # 可能在 = 左边时不是copy?所以data1被改变了? array([[ 0, 1, 2], [10, 11, 12], [13, 14, 15]]) >>> data2 # data2 not changed array([[3, 4, 5], [6, 7, 8]]) -
.reshape():在大部分情况下,如果可以通过修改步长的方式来重建数组则会返回view;如果数组变得不再连续了(即修改步长重建不了了,比如ndarray.transpose)则会返回copy
特殊情况:structured array
当ndarray的dtype使用named field时,该数组变成一个有结构的数组(类似DataFrame一样有名字,而且给每一列指定不同的dtype)
python
>>> x = np.array([('Rex', 9, 81.0), ('Fido', 3, 27.0)],
dtype=[('name', 'U10'), ('age', 'i4'), ('weight', 'f4')])
>>> x
array([('Rex', 9, 81.), ('Fido', 3, 27.)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f4')])-
Individual field:返回view
python>>> x['age'] array([9, 3], dtype=int32) >>> x['age'] = 5 >>> x array([('Rex', 5, 81.), ('Fido', 5, 27.)], dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f4')]) -
Multiple fields:返回copy(版本<=1.15)或view(版本> 1.15)
4. 文件处理
numpy读取文件时可使用memmap对磁盘上的文件数据不读取到内存的同时当作ndarray一样去处理,但这个操作也存在一些限制:
- 如果读取内容很大,那么这可能会成为程序的瓶颈,因为磁盘操作始终比内存操作要慢
- 如果需要不同维度的索引/切片,那么只有符合默认结构的索引/切片会快,其余的会非常慢
解决方案:可选用其他文件读取库(如Zarr/HDF5)
三、pandas相关
1. 使用sparse array
与numpy类似,DataFrame同样可以设置成稀疏矩阵方式存储数据
2. pyarrow
pandas内部实际是使用numpy.ndarray来表示数据 ,但其对于 字符串 或 缺失值 的处理并不友好
而在pandas版本2.1以后(至少2.0以后),引入的pyarrow可以极大地优化这两方面的处理
- 原本numpy中是用一组
PyObject*存储数据,额外空间开销大;而pyarrow中使用连续的char*数组存储,对于大量短字符串的优化效果尤其明显 - 原本pandas中对于不同类型的缺失值有不同表示方式,而且对于整形的缺失值会自动转成浮点型,比较麻烦;而
pyarrow中对不同类型都一套实现,数据的表示进行了统一
使用方式:实际使用时只需要在原本数据类型后面加上[pyarrow]即可。如:
string->string[pyarrow]int64->int64[pyarrow]- 读取接口处可以指定
dtype_backend="pyarrow",有的还需指定engine="pyarrow"
3. indexing / slicing
非常重要的一点:pandas无法保证 索引操作返回的是copy还是view
官方文档Copy on Write (CoW)的 previous behavior 小节第一句用了tricky to understand ,可见它是有多难懂了
该页面主要介绍了让操作结果更加 predictable 的策略CoW,主要思路就是禁止在一行代码中更新多个对象
这样如果有多个对象实际指向同一份数据时,如果尝试更新其中一个对象的数据会触发copy,这样能保证另一份数据不会被影响;而且因为是更新时触发,尽量延缓了内存增加的时间
那么之前的代码中如果存在下面的操作时需格外注意,后续更新pandas版本后,结果可能与预期不符:
-
chained indexing
一般表现为df[first_cond][second_cond] = ...,即对两个连续索引的结果进行更新
因为df[first_cond]得到的不确定为copy还是view,所以这里实际不确定操作的是一个还是两个对象(具体可看Why does assignment fail when using chained indexing)
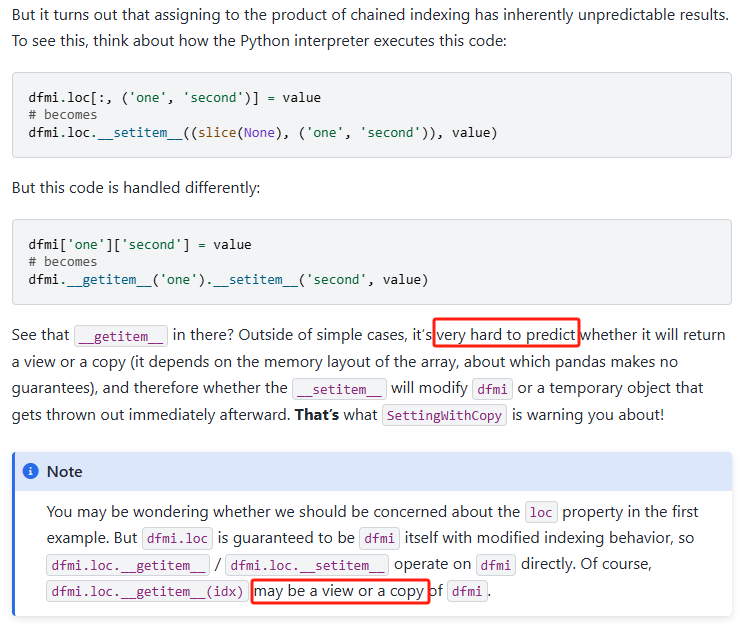
注:可能还有其他形式的 chained indexing 需要格外注意,比如CoW中还提到下面的形式:pythondf[col].replace(..., inplace=True) -
解决办法:使用
.loc取代多个索引(因为.loc操作能保证操作数据本身),或是将多个操作整合到一步操作中pythondf.replace(col:{conditions}, inplace=True) or df[col] = df[col].replace(conditions)注:如果DataFrame是
Multi-Index的,那么两个连续索引相当于是使用.loc了,但是仍旧推荐使用.loc
4. 代码优化
- 按行迭代:用
itertuples替换iterrows(速度更快) - 循环操作:用
.apply/.applymap替换循环 - 大数据计算:使用
pd.eval,在大数据 上的较复杂计算才有速度优化效果