25年3月来自加拿大 Mila AI研究院、蒙特利尔大学、蒙特利尔理工、普林斯顿、加拿大 CIFAR AI Chair 计划和 Torc 机器人公司的论文"Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments"。
Scenario Dreamer,是一个完全数据驱动的自动驾驶汽车规划生成模拟器,它可以生成初始交通场景(包括车道图和智体边框)和闭环智体行为。现有的生成驾驶模拟环境方法将初始交通场景编码为光栅化图像,因此需要参数繁重的网络,这些网络由于光栅化场景中存在许多空像素而执行不必要的计算。此外,采用基于规则智体行为的现有方法缺乏多样性和真实感。Scenario Dreamer 采用一种矢量化潜扩散模型进行初始场景生成,该模型直接对矢量化场景元素进行操作,并使用自回归 Transformer 进行数据驱动的智体行为模拟。Scenario Dreamer 还支持通过扩散修复进行场景外推,从而能够生成无界模拟环境。大量实验表明,Scenario Dreamer 在真实感和效率方面均超越现有的生成式模拟器:与最强大的基线相比,矢量化的场景生成基础模型实现卓越的生成质量,参数数量减少约 2倍,生成延迟降低 6倍,GPU 训练时长减少 10倍。其证明强化学习规划智体在 Scenario Dreamer 环境中比传统的非生成式模拟环境面临更大的挑战(尤其是在长途和对抗性驾驶环境中),证实其实用性。
本文将生成式驾驶模拟任务分解为初始场景生成和行为模拟。
问题设置
初始场景生成。初始场景生成涉及在固定视野 (FOV) 内生成初始 BEV 目标边框状态和底层地图结构。根据 11 中的方案,生成一个以自智体为中心并旋转至自智体的 64m×64m 视野。将生成的 64m×64m 区域表示为 F,将自智体前方和后方的 32m×64m 区域分别表示为 F_P 和 F_N。初始场景生成器的任务是从初始场景的分布 p(I_F) 中进行采样,其中初始场景 I_F = {O, M} 包含视场角 (FOVF) 内的一组目标 O 和地图结构 M。
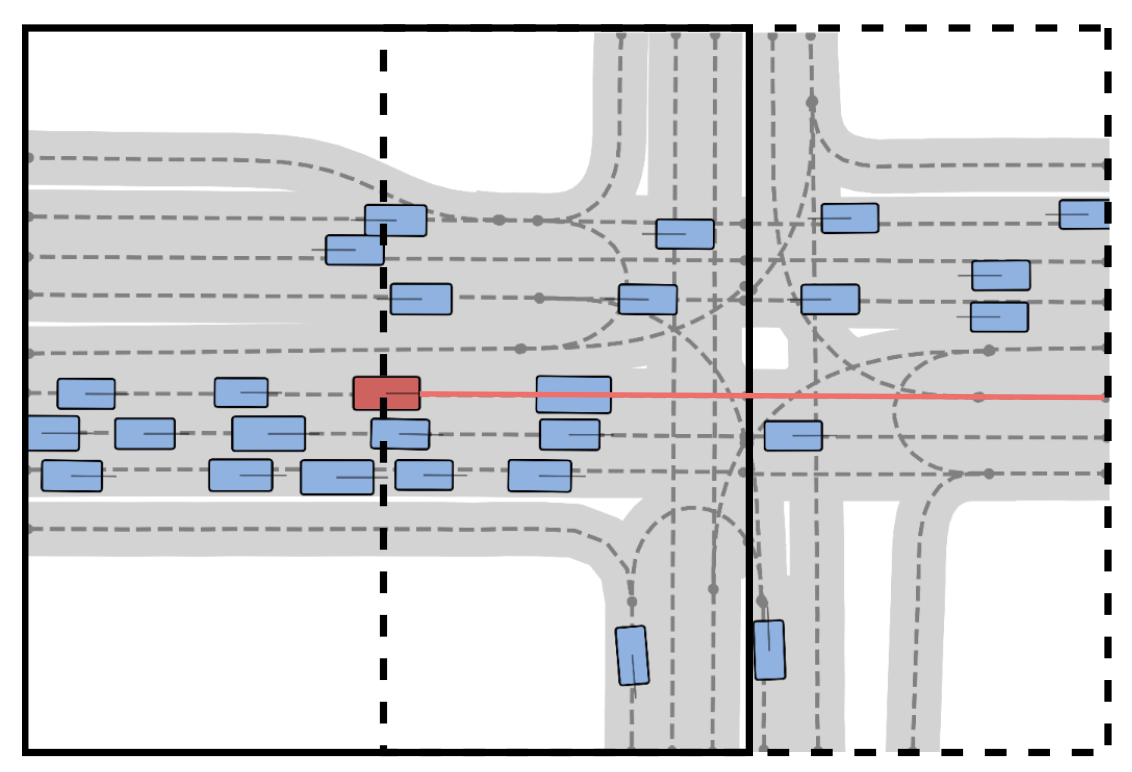
定义 O = {o_i} 为一个包含 N_o 个目标的集合,其中包括交通参与者(例如,自智体、车辆、行人、骑行者)和静态目标(例如,交通锥),其中 o_i 是一个 8 维向量,包含二维位置、速度、航向的余弦和正弦、边框的长度、宽度和目标类别。生成一个类似于 11 的地图表示 M,其中 M = {L, A} 包含一个由 N_l 条中心线组成的集合 L = {l_i},其中每个 l_i 是一个 20×2 的中心线位置序列,A ∈ {0, 1} 将相关的中心线连通性定义为四个邻接矩阵的堆栈,分别描述后继、前驱、左邻和右邻连接。初始场景生成器还必须支持从条件分布 p(I_F_P |I_F_N) 进行采样,因为这可以通过将新生成的区域 F_P 和现有区域 F_N 拼接在一起来采样任意长的场景(参见下图恢复能力)。
行为模拟给定初始场景生成器规定的初始场景配置,行为模拟任务包括对场景中动态目标随时间的行为进行建模。具体而言,给定初始物体边框状态集合 S_0 := O 和车道结构 M,行为模型采用多智体驾驶策略 π(A_t|S_t, M) 和前向转移模型 P (S_t+1 |S_t , A_t),其中 A_t 是时间步 t 所有动态目标动作的集合。
矢量化潜扩散模型
初始场景生成器旨在从 p(I_F) 中进行采样。为了实现此目标,其使用扩散模型,基于真实驾驶数据学习一个近似值 p ̃(I_F) ≈ p(I_F),因为扩散模型具有捕捉高度复杂分布的强大能力 1, 55。
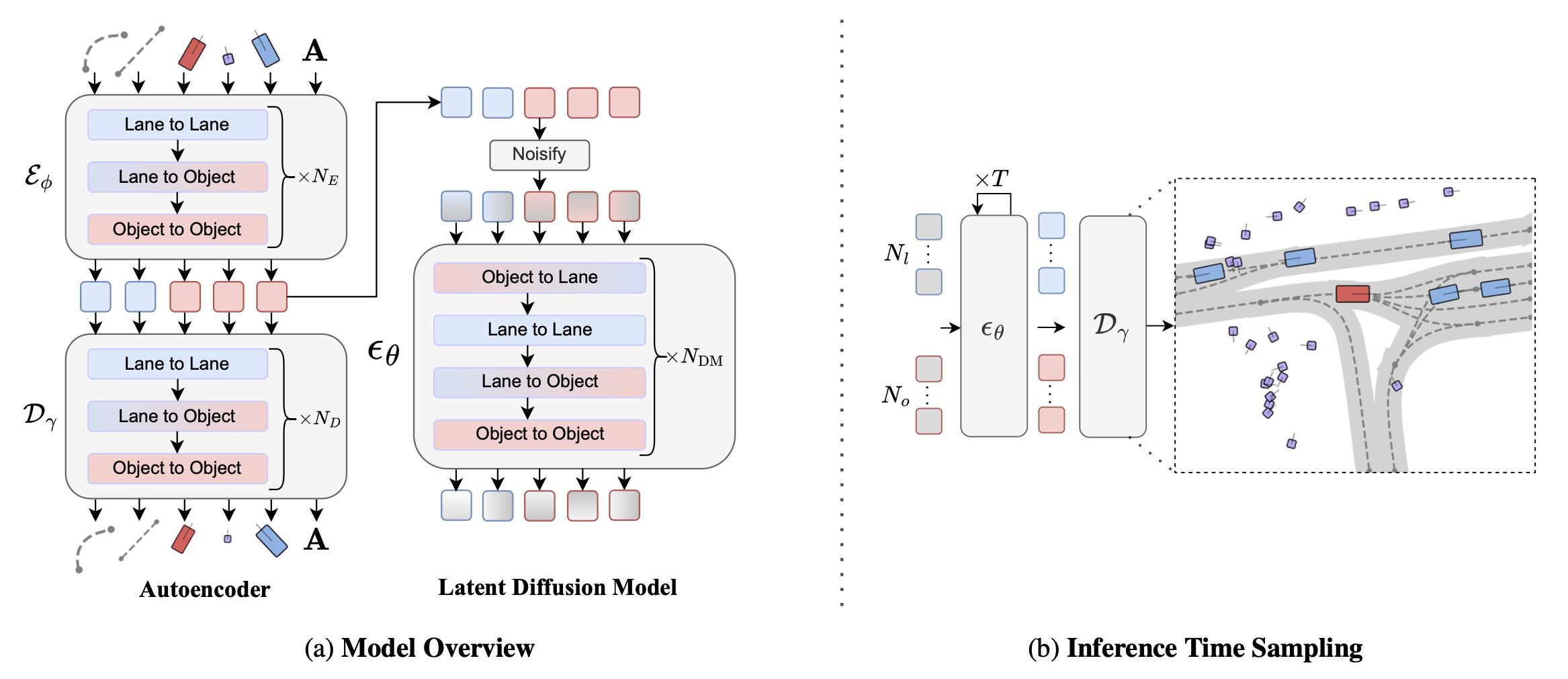
采用两阶段训练流程:首先,通过低 β 变分自编码器23学习 N_o 个目标 {h_iO} 和 N_l 条中心线 {h_iL} 的紧凑潜表示;接下来,训练一个扩散模型,从分布 p(H) := p({h_iO}, {h_i^L}) 中进行采样。该架构如图所示:
自动编码器
自动编码器由基于 Transformer 的 69 编码器 E_φ 和解码器 D_γ 组成,它们直接对矢量化的场景元素进行操作------相比之下,先前的研究 11 将驾驶场景编码为光栅化图像。
编码器。编码器 E_φ 首先将 N_o + N_l 个矢量元素嵌入到每个矢量的多层感知器 (MLP) 中,此外,还将车道连接类型 c_ij 的独热表示嵌入到所有中心线段对 i 和 j 的多层感知器 (MLP) 中。然后,E_φ 将一系列 N_E 个分解后的注意模块应用于 N_o + N_l 个嵌入的场景元素,其中每个分解后的注意模块包含一个车道-到-车道、车道-到-物体和物体-到-物体的多头注意层 20, 42, 49。车道间注意机制捕捉中心线段之间的空间关系,其中嵌入的车道连接性被额外融合到注意机制的 K 和 V 中。车道间注意机制将地图上下文融入目标嵌入中,而目标间注意机制则捕捉目标之间的空间关系。在 N_E 分解的注意模块之后,编码器将每个目标和车道嵌入分别映射到潜维度 K_o 和 K_l,均值和方差均如在变分自编码器 (VAE) 中一样进行参数化 36。重要的是,设计 E_φ,使得车道潜维度不依赖于目标特征(即没有目标间注意机制),从而允许在推理过程中生成基于车道条件的目标。
解码器。解码器 D_γ 从编码器参数化的潜分布 {{h_O}, {h_L}} ∼ E_φ 中进行采样,并通过一系列 ND 分解的注意模块处理嵌入的车道和物体潜信息。在这些模块之后,解码器在 l_2 损失函数的监督下,重建连续的车道和物体向量输入。对于车道连通性预测,将每对车道嵌入连接起来,并通过 MLP 传递,以预测连通性类型的分类分布,并使用交叉熵损失函数进行训练。Scenario Dreamer 自编码器采用标准证据下限 (ELBO) 目标函数和低-β 正则化进行训练。
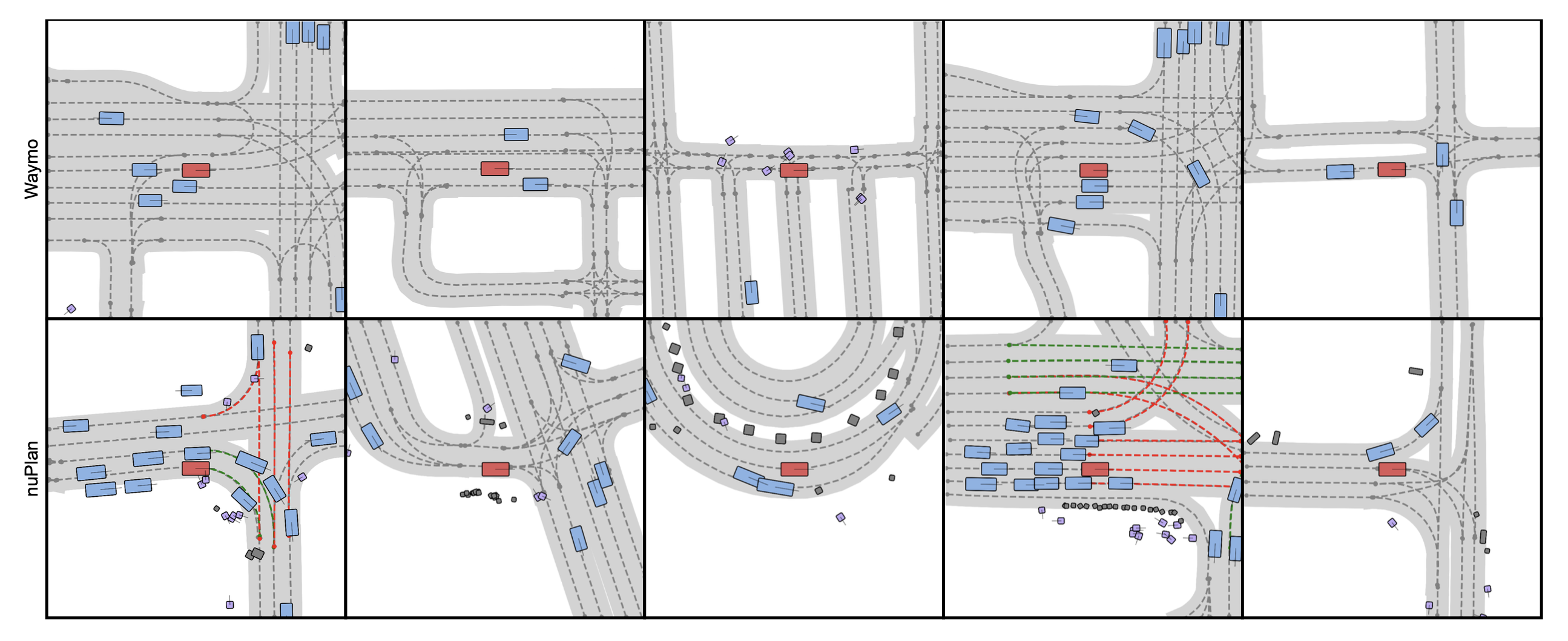
如图所示:Scenario Dreamer 产生的矢量化环境。
潜扩散采样
训练一个潜扩散模型,从自编码器的潜分布 p(H) 中采样,该分布分解为:
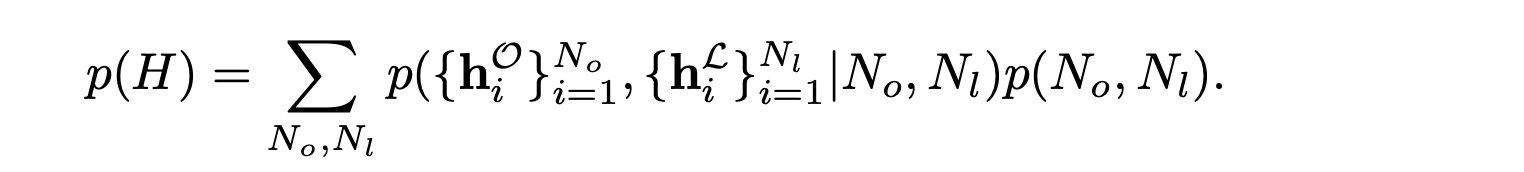
此处,条件分布 p_θ (·|N_o, N_l) 由一个权重为 θ 的扩散模型参数化,该模型对 N_o 个目标潜样本和 N_l 个车道潜样本进行采样。与基于图像的模型不同,p_θ 必须适应可变的潜样本大小,因此设计一个基于 AdaLN-Zero 条件的定制 Transformer 架构 52。该架构与自编码器类似,由一系列 NDM 分解式注意模块组成,其中包含连续的目标-到-车道、车道-到-车道、车道-到-目标和目标-到-目标的注意层。这种分解式处理方法允许每一层对特定层的交互进行建模,同时允许目标和车道标记具有不同的隐藏维度。值得注意的是,由于真实车道生成需要高度的空间推理和细节,车道 tokens 需要更大的隐藏维度,而目标 tokens 则能有效地用较小的维度表示,这使得扩散模型整体上更高效。采用标准 DDPM 目标函数来训练 p_θ,其中 p_θ 被参数化为噪声预测网络 ε_θ,该网络学习预测不同噪声水平下带噪声车道和目标潜特征的噪声:
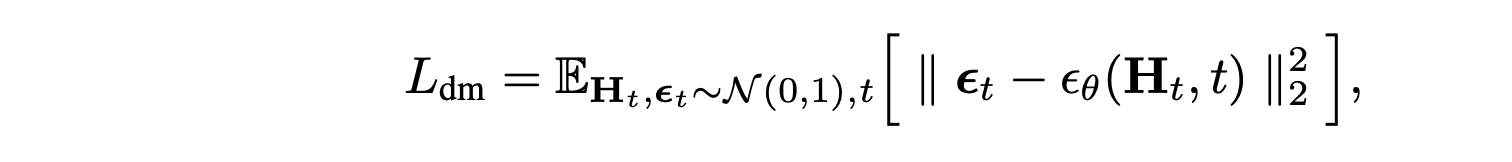
排列模糊性。与具有自然网格结构的图像不同,Scenario Dreamer 中的集合结构化数据对扩散模型提出独特的挑战。具体而言,出现一种称为排列模糊性 8 的现象:训练期间噪声充足的向量元素会丢失足够的底层结构,导致模型无法可靠地推断出应该回归的真值信号排列。在基于图像的 Transformer 扩散方法(例如 DiT)中,通过对每个网格块应用位置编码来解决此问题。为了类似地解决模型中的排列模糊性问题,本文在分解注意模块之前对潜 tokens 引入正弦位置编码。
位置编码方案涉及在训练期间定义 token 的排序(每种 token 类型),从而使模型能够更好地推断带噪声 token 的可能相对空间位置,从而推断出模型应该回归的真实信号。为此,其提出一个递归排序程序:token 按最小 x 值排序,如果 x 值的差异小于 ε 米,则依次按最小 y 值、最大 x 值和最大 y 值排序。值得注意的是,初始按 x 值排序有利于图像修复,因为 IFN 中的 tokens 构成一个连续的有序 token 子序列,这些子序列位于 IFP 中的 token 之前。
场景生成
Scenario Dreamer 潜扩散模型在单个训练模型中支持多种场景生成模式:初始场景生成,从 p(I_F) 中采样 64m × 64m 的场景;车道条件目标生成,以已知地图 M 为条件采样物体边框 O;场景修复,从 p(I_F_P |I_F_N) 中采样。
初始场景生成。Scenario Dreamer 首先从训练数据中的联合分布中采样 (N_o, N_l) ∼ p(N_o, N_l),生成新的初始驾驶场景 IF,并对 N_o 和 N_l 设置数据集相关的限制,以确保真实的场景密度。或者,用户可以直接指定 (N_o,N_l),从而控制场景密度。设置 (N_o,N_l) 后,从扩散模型中采样潜向量 {h_i^O}, {h_i^L},经过 T = 100 个扩散步骤,并使用自编码器解码器将潜向量解码为矢量化的场景元素。
车道条件化目标生成 (Lane-conditioned Object Generation) 包括使用 E_φ 对给定映射 M 的矢量化元素进行编码,然后从扩散模型中采样 N_o ∼ p(N_o|N_l) 个目标潜向量,这些潜向量在每个去噪时间步长上对编码后的映射潜向量进行条件化处理,并进行扩散。得到的目标潜向量可以用 D_γ 解码为目标边框配置。
场景修复。遵循 11,将从 P (I_F_P |I_F_N) 中进行条件采样定义为修复任务。与网格结构图像不同,在网格结构图像中,区域(例如 I_F_P 和 I_F_N)之间的边界是自然定义的(例如,沿 x = 0),而设置中的车道向量可以不受限制地跨越此边界。为了解决这个问题,将数据集预处理为两种场景类型:分区场景(在 x = 0 处人为分割)和非分区场景(其中车道向量可能跨越 x = 0)。训练自动编码器以重建这两种场景类型,而扩散模型通过使用条件标签来区分它们,从而生成这两种场景。为了进一步提高修复质量,在训练期间,扩散模型以分区场景的 I_F_N 编码潜变量为条件,从而明确地训练它进行修复。这显著提升了修复性能,因为模型可以学习利用 I_F_N 中的相关场景上下文,确保车道几何形状在 x = 0 边界上保持空间一致性。
Scenario Dreamer 需要指定新的车道和目标向量的数量,以填充新的 32x64 区域 I_F_P,从而有效地从 p(N_oF_P, N_lF_P | I_lF_N) 中进行采样。虽然可以通过训练统计数据从 p(N_oF_P, N_lF_P | N_oF_Nv, N_l^F_N) 进行近似采样,但 p(N_l^F_P | IF_N) 高度依赖于几何形状。为了解决这个问题,训练一个分类器 f_φ (N_l^F_P | M_F_N) 和 E_φ,以基于上下文 I_F_N 预测 I_F_P 中的车道数量,该分类器仅在分区场景上进行训练。
具体来说,一个可学习的查询向量在 E_φ 的每个分解注意模块中与 I_F_N 中的车道 token 进行交叉关注,输出一个在 N_oF_P 上经过交叉熵损失训练的分类分布。在推理阶段,首先对 N_lF_P∼ f_φ 进行采样,然后对 N_oF_P ∼ p(N_o^F_P |N_o^F_N ,N_l^F_N + N_l^F_P ) 进行采样。采样 (N_o^F_P, N_o^F_P) 后,对 I_F_N 的潜向量进行编码,并生成 N_o^F_P 和 N_l^F_P 个新 tokens,并初始化为高斯噪声。然后应用标准扩散修复 11,其中 I_F_N 中的带噪 tokens 在每个去噪步骤中被设置为其编码的潜向量。对得到的潜信息进行解码,以生成 I_F_P 中的新场景元素。
行为模拟
从潜扩散模型生成的初始场景 I 开始,扩展 CtRL-Sim 58(一个基于 Transformer 的自回归行为模型),以控制多种智体类型(例如,车辆、行人和骑行者)。为了支持多种智体类型,使用 Philion 提出的 k 盘 方案 53。CtRL-Sim 是一个基于回报条件的多智体策略,专为行为模拟而设计。调整 CtRL-Sim 架构,该架构参数化未来回报 G_t 和动作 A_t 的联合分布,分解为 p_θ (A_t, G_t | S_t) = π_θ (A_t | S_t, G_t) p_θ (G_t | S_t)。这种分解的一个关键优势在于其回报条件,这使得学习的回报模型在推理过程中能够呈指数级倾斜38,从而生成良好或对抗性的驾驶行为。在scenario dreamer 框架中,目标是创建对抗性场景,专门挑战自动驾驶汽车 (AV) 规划器。为此,设计一个奖励函数,用于惩罚与自车的碰撞,并基于 H = 2s 范围内的累积奖励,对折扣回报 G_t = sum (r_t) 进行建模。与对完整回报进行建模相比,这具有更好的可控性。
模拟框架
基于 Scenario Dreamer,描述提出的模拟框架独特属性。首先,Scenario Dreamer 支持在其生成模拟环境中对自动驾驶汽车规划器进行任意长模拟时长的评估。为自动驾驶汽车规划器定义一条要遵循的路线,并使用 CtRL-Sim 模拟其他智体。遵循 Nocturne 70 和 GPUDrive 34 中采用的 Waymo 数据集过滤方案,以确保场景对于模拟有效(例如,没有交通信号灯,即没有带注释的交通信号灯状态)。为了确保 Scenario Dreamer 生成的场景对于模拟有效,Scenario Dreamer 在训练期间以二进制指标为条件,该指标指示训练场景是否通过 Nocturne 过滤方案。在推理阶段,利用分类器引导从模拟兼容场景中进行采样。