🧑 博主简介:曾任某智慧城市类企业
算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)
💬 博主粉丝群介绍:① 群内初中生、高中生、本科生、研究生、博士生遍布,可互相学习,交流困惑。② 热榜top10的常客也在群里,也有数不清的万粉大佬,可以交流写作技巧,上榜经验,涨粉秘籍。③ 群内也有职场精英,大厂大佬,可交流技术、面试、找工作的经验。④ 进群免费赠送写作秘籍一份,助你由写作小白晋升为创作大佬。⑤ 进群赠送CSDN评论防封脚本,送真活跃粉丝,助你提升文章热度。有兴趣的加文末联系方式,备注自己的CSDN昵称,拉你进群,互相学习共同进步。

【机器学习案列-21】基于 LightGBM 的智能手机用户行为分类
一、项目背景与目标
在5G时代,智能手机用户的使用行为日益多样化,理解这些行为对于产品优化和个性化服务至关重要。通过分析用户行为数据,可以深入理解不同用户群体的使用模式,为手机制造商、应用开发者和运营商提供决策支持。本项目致力于构建一个高效、准确的用户行为分类模型。
二、数据集介绍
数据集包含以下字段:
- User ID:用户唯一标识符
- Device Model:智能手机型号
- Operating System:操作系统类型
- App Usage Time (min/day) :每日应用使用时间
- Screen On Time (hours/day) : 屏幕开启时间
- Battery Drain (mAh/day) : 电池消耗量
- Number of Apps Installed :安装的应用程序数量
- Data Usage (MB/day) :每日数据耗用量
- Age:用户年龄
- Gender:用户性别
- User Behavior Class:用户行为类别标签(1-5个等级)
三、完整代码实现
1. 环境准备与数据加载
python
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import classification_report, accuracy_score
# 加载数据
data = pd.read_csv("user_behavior_dataset.csv")2. 数据预处理
python
# 处理分类变量
categorical_columns = ['Device Model','Operating System','Gender']
data = pd.get_dummies(data, columns=categorical_columns)
# 划分特征与标签
X = data.drop(['User Behavior Class','User ID'], axis=1)
y = data['User Behavior Class']
# 分层抽样拆分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
stratify=y,
random_state=42
)3. LightGBM 模型构建与训练
python
# 创建 LightGBM 数据集
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# 设置模型参数
model = lgb.LGBMClassifier()
model.fit(X_train, y_train)4. 模型评估与预测
python
# 使用最佳参数训练模型
best_model = random_search.best_estimator_
best_model.fit(X_train, y_train)
# 预测
y_pred = best_model.predict(X_test)
y_pred = [round(i) for i in y_pred] # 将概率转换为类别
# 评估模型
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
5. 交叉验证优化
python
# 设置参数范围
param_dist = {
'boosting_type': ['gbdt', 'dart'], # 提升类型 梯度提升决策树(gbdt)和Dropouts meet Multiple Additive Regression Trees(dart)
'objective': ['binary', 'multiclass'], # 目标;二分类和多分类
'num_leaves': range(20, 150), # 叶子节点数量
'learning_rate': [0.01, 0.05, 0.1], # 学习率
'feature_fraction': [0.6, 0.8, 1.0], # 特征采样比例
'bagging_fraction': [0.6, 0.8, 1.0], # 数据采样比例
'bagging_freq': range(0, 80), # 数据采样频率
'verbose': [-1] # 是否显示训练过程中的详细信息,-1表示不显示
}
from sklearn.model_selection import train_test_split, RandomizedSearchCV
# 初始化模型
model = lgb.LGBMClassifier()
# 使用随机搜索进行参数调优
random_search = RandomizedSearchCV(estimator=model,
param_distributions=param_dist, # 参数组合
n_iter=100,
cv=5, # 5折交叉验证
verbose=2,
random_state=42,
n_jobs=-1)
# 模型训练
random_search.fit(X_train, y_train)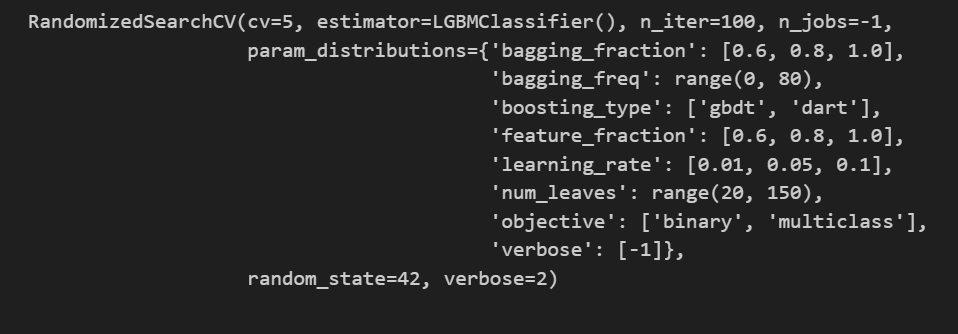
6. 输出最佳参数与评估
python
print("Best parameters found: ", random_search.best_params_)
# 使用最佳参数训练模型
best_model = random_search.best_estimator_
best_model.fit(X_train, y_train)
# 预测
y_pred = best_model.predict(X_test)
y_pred = [round(i) for i in y_pred] # 将概率转换为类别
# 评估模型
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))

7. 特征重要度可视化
python
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 获取特征重要度
feature_importance = best_model.feature_importances_
feature_names = X.columns
# 创建特征重要度 DataFrame
importance_df = pd.DataFrame({
'Feature': feature_names,
'Importance': feature_importance
})
# 按重要度排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# 绘制特征重要度
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('特征重要度分析')
plt.xlabel('重要度')
plt.ylabel('特征')
plt.show()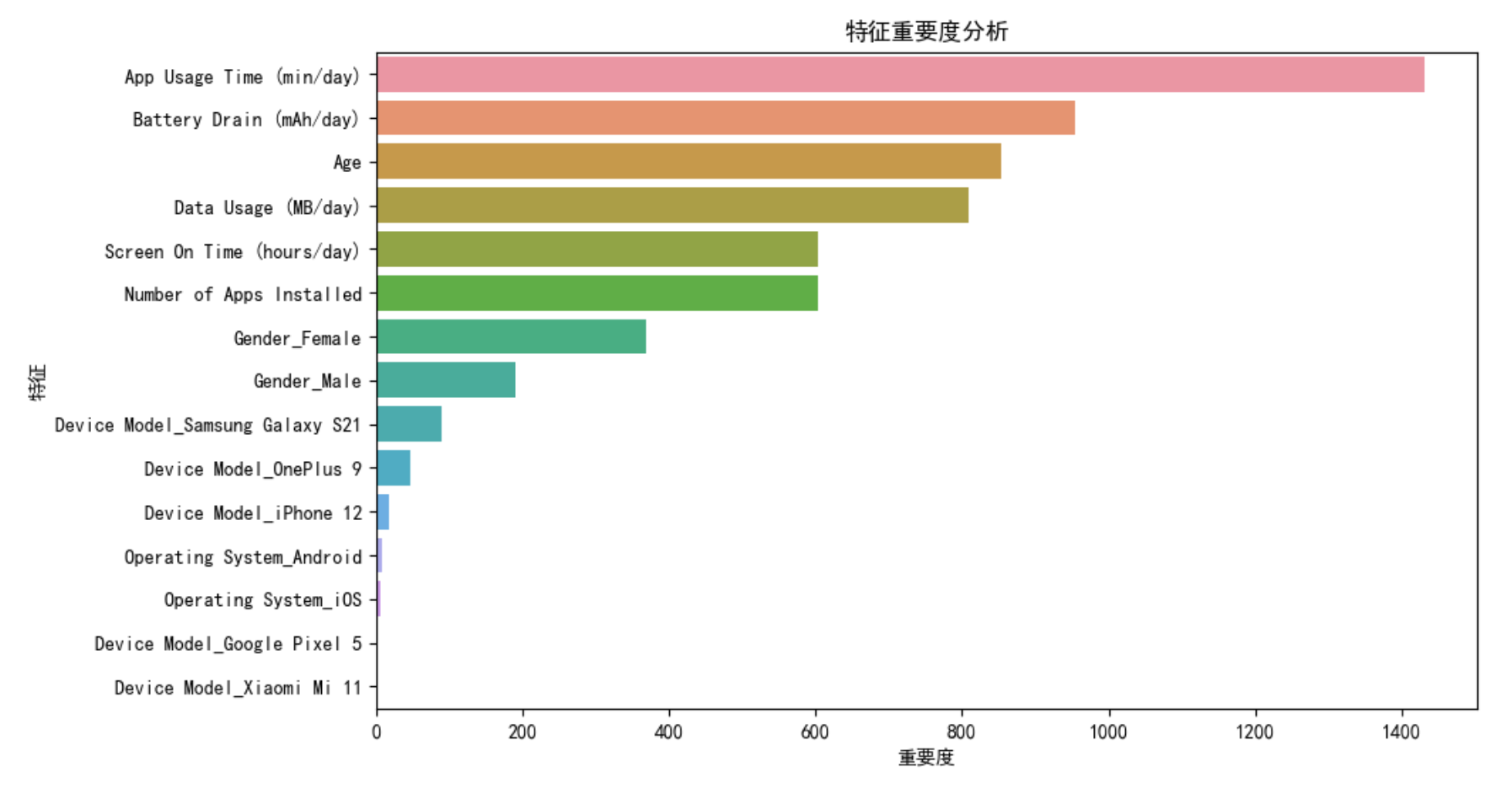
四、分析结论与业务洞见
关键发现
- 应用使用时间:用户在移动应用上的花费时间是区分不同行为类别的关键指标。
- 屏幕开启时间:屏幕开启时间越长,通常对应更活跃的用户行为。
- 安装应用数量:设备上安装的应用数量反映了用户的多样化使用习惯。
业务建议
- 个性化服务:根据用户行为类别提供个性化应用推荐。
- 产品优化:关注高活跃用户的使用痛点,优化产品体验。
- 精准营销:针对不同行为类别的用户制定差异化的营销策略。
五、优化方向与思考
模型优化
- 超参数调优:使用网格搜索或贝叶斯优化进一步调整模型参数。
- 特征工程:尝试构建更多有意义的特征组合,如应用使用时间和数据耗用量的比值。
通过基于 LightGBM 的用户行为分类模型,可以有效识别不同用户群体的使用模式,为业务决策提供有力支持。希望本文的代码和分析能为您的项目提供有价值的参考!
六、完整代码
python
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import classification_report, accuracy_score
# 加载数据
data = pd.read_csv("user_behavior_dataset.csv")
# 处理分类变量
categorical_columns = ['Device Model','Operating System','Gender']
data = pd.get_dummies(data, columns=categorical_columns)
# 划分特征与标签
X = data.drop(['User Behavior Class','User ID'], axis=1)
y = data['User Behavior Class']
# 分层抽样拆分数据集
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
stratify=y,
random_state=42
)
# 创建 LightGBM 数据集
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test)
# 设置模型参数
model = lgb.LGBMClassifier()
model.fit(X_train, y_train)
# 设置参数范围
param_dist = {
'boosting_type': ['gbdt', 'dart'], # 提升类型 梯度提升决策树(gbdt)和Dropouts meet Multiple Additive Regression Trees(dart)
'objective': ['binary', 'multiclass'], # 目标;二分类和多分类
'num_leaves': range(20, 150), # 叶子节点数量
'learning_rate': [0.01, 0.05, 0.1], # 学习率
'feature_fraction': [0.6, 0.8, 1.0], # 特征采样比例
'bagging_fraction': [0.6, 0.8, 1.0], # 数据采样比例
'bagging_freq': range(0, 80), # 数据采样频率
'verbose': [-1] # 是否显示训练过程中的详细信息,-1表示不显示
}
from sklearn.model_selection import train_test_split, RandomizedSearchCV
# 初始化模型
model = lgb.LGBMClassifier()
# 使用随机搜索进行参数调优
random_search = RandomizedSearchCV(estimator=model,
param_distributions=param_dist, # 参数组合
n_iter=100,
cv=5, # 5折交叉验证
verbose=2,
random_state=42,
n_jobs=-1)
# 模型训练
random_search.fit(X_train, y_train)
print("Best parameters found: ", random_search.best_params_)
# 使用最佳参数训练模型
best_model = random_search.best_estimator_
best_model.fit(X_train, y_train)
# 预测
y_pred = best_model.predict(X_test)
y_pred = [round(i) for i in y_pred] # 将概率转换为类别
# 评估模型
print('Accuracy: %.4f' % accuracy_score(y_test, y_pred))
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文字体
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 获取特征重要度
feature_importance = best_model.feature_importances_
feature_names = X.columns
# 创建特征重要度 DataFrame
importance_df = pd.DataFrame({
'Feature': feature_names,
'Importance': feature_importance
})
# 按重要度排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# 绘制特征重要度
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('特征重要度分析')
plt.xlabel('重要度')
plt.ylabel('特征')
plt.show()