引入
在过去的几篇文章里,我们看到了大数据的流式处理系统是如何一步一步进化的。从最早出现的S4,到能够做到"至少一次"处理的Storm,最后是能够做到"正好一次"数据处理的MillWheel。我们会发现,这些流式处理框架,每一个都很相似,它们都采用了有向无环图一样的设计。但是在实现和具体接口上又很不一样,每一个框架都定义了一个属于自己的逻辑。
S4是无中心的架构,一切都是PE;Storm是中心化的架构,定义了发送数据的Spout和处理数据的Bolt;而MillWheel则更加复杂,不仅有Computation、Stream、Key这些有向无环图里的逻辑概念,还引入了Timer、State这些为了持久化状态和处理时钟差异的概念。
和我们在大数据的批处理看到的不同,S4、Storm以及MillWheel其实是某一个数据处理系统,而不是MapReduce这样高度抽象的编程模型。每一个流式数据处理系统各自有各自对于问题的抽象和理解, 很多概念不是从模型角度的"该怎么样"抽象出来,而是从实际框架里具体实现的"是怎么样"的角度,抽象出来的。
不过,我们也看到了这些系统有很多相似之处,它们都采用了有向无环图模型,也都把同一个Key的数据在逻辑上作为一个单元进行抽象。随着工业界对于流式数据处理系统的不断研发和运用,到了2015年,仍然是Google,发表了今天我们要看的这一篇 The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing 论文。
数据流模型:一种在大规模、无界、无序数据处理中平衡正确性、延迟和成本的实用方法
摘要
无界、无序的全球规模数据集在日常业务中越来越常见(例如网络日志、移动设备使用统计数据以及传感器网络数据)。与此同时,这些数据集的使用者产生了复杂的需求,除了对更快获取结果的迫切渴望之外,还包括事件时间排序以及依据数据自身特征进行窗口化处理等。然而,实际情况是,对于这类输入数据,永远无法在正确性、延迟和成本的所有维度上都做到完全优化。因此,数据处理从业者面临着如何调和这些看似相互矛盾的要求之间的矛盾这一难题,这往往导致出现各种各样不同的实现方式和系统。
我们认为,为了应对现代数据处理中这些不断演变的需求,有必要从根本上转变方法。作为一个领域,我们不应再试图将无界数据集整理成最终会变得完整的有限信息池,而应基于这样一种假设来开展工作:我们永远不知道是否或何时已经看到了所有数据,只知道会有新数据到来,旧数据可能会被撤回,而使这个问题变得易于处理的唯一方法是通过有原则的抽象,让从业者能够在感兴趣的维度(正确性、延迟和成本)上做出合适的权衡选择。
在本文中,我们提出了这样一种方法 ------ 数据流模型 1 ,同时详细审视了它所支持的语义,概述了指导其设计的核心原则,并通过促成其发展的实际经验对该模型本身进行了验证。
1: 我们使用 "数据流模型" 这一术语来描述谷歌云数据流(Google Cloud Dataflow 20)的处理模型,该模型基于来自 FlumeJava 12 和 MillWheel 2 的技术。
1. 引言
现代数据处理是一个既复杂又令人兴奋的领域。从 MapReduce 16 及其后继者(如 Hadoop 4、Pig 18、Hive 29、Spark 33)所实现的规模处理,到 SQL 领域内关于流处理的大量研究工作(如查询系统 1, 14, 15、窗口化处理 22、数据流 24、时间域 28、语义模型 9),再到最近在低延迟处理方面的尝试,如 Spark Streaming 34、MillWheel 和 Storm 5,现代数据使用者在将大规模无序数据整理成具有更高价值的有序结构方面拥有强大的能力。然而,现有的模型和系统在许多常见用例中仍存在不足。
考虑一个初始示例:一家流媒体视频提供商希望通过展示视频广告来实现其内容的货币化,并根据广告观看量向广告商收费。该平台支持内容和广告的在线和离线观看。视频提供商想知道每天向每个广告商收取多少费用,以及有关视频和广告的汇总统计信息。此外,他们希望能高效地对大量历史数据进行离线实验。
广告商 / 内容提供商想知道他们的视频被观看的频率和时长,与哪些内容 / 广告一起被观看,以及受众的人口统计信息。他们还想知道自己被收取 / 支付了多少费用。他们希望尽快获得所有这些信息,以便尽可能实时地调整预算和出价、改变目标定位、调整广告活动并规划未来方向。由于涉及资金,正确性至关重要。
尽管数据处理系统本质上很复杂,但视频提供商希望有一个简单且灵活的编程模型。最后,由于互联网极大地扩展了任何可以依托其架构开展的业务的覆盖范围,他们还需要一个能够处理全球规模离散数据的系统。
对于这样一个用例,必须计算的信息本质上是每次视频观看的时间和时长、观看者是谁以及与哪个广告或内容配对(即每个用户、每次视频观看会话)。从概念上讲,这很直接,但现有的模型和系统都无法满足上述要求。
诸如 MapReduce(及其 Hadoop 变体,包括 Pig 和 Hive)、FlumeJava 和 Spark 等批处理系统,存在在处理前将所有输入数据收集到一个批次中所固有的延迟问题。对于许多流处理系统而言,尚不清楚它们在大规模情况下如何保持容错能力(Aurora 1、TelegraphCQ 14、Niagara 15、Esper 17)。那些提供可扩展性和容错性的系统在表达能力或正确性方面有所欠缺。许多系统缺乏提供精确一次性语义的能力(Storm、Samza 7、Pulsar 26),这影响了正确性。其他一些系统则根本缺乏窗口化所需的时间原语 2 (Tigon 11),或者提供的窗口化语义仅限于基于元组或处理时间的窗口(Spark Streaming 34、Sonora 32、Trident 5)。大多数提供基于事件时间窗口化的系统,要么依赖排序(SQLStream 27),要么在事件时间模式下窗口触发 3 语义有限(Stratosphere/Flink 3, 6)。CEDR 8 和 Trill 13 值得注意,因为它们不仅通过标点符号 30, 28 提供了有用的触发语义,还提供了一个与我们在此提出的总体增量模型非常相似的模型;然而,它们的窗口化语义不足以表达会话,并且其周期性标点符号对于第 3.3 节中的某些用例来说是不够的。MillWheel 和 Spark Streaming 都具有足够的可扩展性、容错性和低延迟,可以作为合理的基础,但缺乏使事件时间会话计算变得简单直接的高级编程模型。
据我们所知,唯一支持像会话这样的非对齐窗口 4 高级概念的可扩展系统是 Pulsar,但如上文所述,该系统无法保证正确性。Lambda 架构 25 系统可以满足许多期望的要求,但由于必须构建和维护两个系统,在简单性方面有所不足。Summingbird 10 通过在单个接口后抽象底层批处理和流处理系统来改善这种实现复杂性,但这样做对可以执行的计算类型施加了限制,并且仍然需要两倍的操作复杂性。
2:这里 "windowing" 指窗口化操作,在数据处理中常用于按特定时间或数据特征对数据进行分组处理。
这里我们所说的窗口化,是指如 Li 22 中所定义的那样,即将数据切分成有限的数据块进行处理。更多内容见 1.2 节。
3:"window triggering" 指窗口触发,决定何时基于窗口内的数据进行计算或输出结果。这里我们所说的触发,是指在分组操作时促使特定窗口产生输出。更多内容见 2.3 节。
4:"unaligned windows" 指非对齐窗口,与基于固定时间间隔等规则对齐的窗口相对,非对齐窗口可根据数据自身特征等灵活定义。这里我们所说的非对齐窗口,是指并非跨越整个数据源,而仅跨越其一个子集的窗口,例如按用户划分的窗口。这本质上是 Whiteneck 31 中提出的帧(frames)概念。更多内容见 1.2 节。
这些缺点并非无法解决,而且正在积极开发的系统很可能在适当的时候克服它们。但我们认为,上述所有模型和系统(CEDR 和 Trill 除外)的一个主要缺点是,它们将输入数据(无论是否无界)视为在某个时刻会变得完整的东西。我们认为,当当今庞大且高度无序的数据集的现实与用户所要求的语义和及时性发生冲突时,这种方法从根本上就是有缺陷的。我们还认为,任何一种方法,若要在当今如此多样和繁杂的一系列用例(更不用说那些即将出现的用例)中具有广泛的实用价值,就必须提供简单而强大的工具,以便根据手头特定用例平衡正确性、延迟和成本。
最后,我们认为是时候超越由执行引擎决定系统语义的主流思维模式了;经过合理设计和构建的批处理、微批处理和流处理系统都能提供同等程度的正确性,并且这三种方式如今在无界数据处理中都得到了广泛应用。在一个具有足够通用性和灵活性的模型之下进行抽象,我们相信执行引擎的选择可以仅仅基于它们之间实际存在的差异:即延迟和资源成本方面的差异。
从这个角度来看,本文在概念上的贡献是一个单一的统一模型,该模型:
- 允许在无界、无序的数据源上,根据数据自身特征进行窗口化,计算按事件时间 5 排序的结果,并且正确性、延迟和成本可在广泛的组合范围内进行调整。
- 从四个相关维度分解管道实现,提供清晰性、可组合性和灵活性:
- 正在计算什么结果。
- 在事件时间的哪个点进行计算。
- 在处理时间的何时将结果具体化。
- 早期结果与后期细化结果之间的关系。
- 将数据处理的逻辑概念与底层物理实现分离,使得批处理、微批处理或流处理引擎的选择仅仅成为正确性、延迟和成本方面的选择。
具体而言,这一贡献通过以下方式得以实现:
- 一个窗口化模型,支持非对齐的事件时间窗口,并提供一个简单的 API 用于创建和使用这些窗口(第 2.2 节)。
- 一个触发模型,将结果的输出时间与管道的运行时特征绑定,并带有一个强大且灵活的声明式 API,用于描述所需的触发语义(第 2.3 节)。
- 一个增量处理模型,将撤回和更新集成到上述窗口化和触发模型中(第 2.3 节)。
- 在 MillWheel 流处理引擎和 FlumeJava 批处理引擎之上对上述内容进行可扩展的实现,并为 Google Cloud Dataflow 进行外部重新实现,包括一个与运行时无关的开源软件开发工具包(SDK)19(第 3.1 节)。
- 一组指导该模型设计的核心原则(第 3.2 节)。
- 简要讨论我们在谷歌进行大规模、无界、无序数据处理的实际经验,这些经验推动了该模型的开发(第 3.3 节)。
最后值得注意的是,这个模型并没有什么神奇之处。在现有的强一致性批处理、微批处理、流处理或 Lambda 架构系统中,那些在计算上不切实际的事情,在这个模型中依然如此,CPU、内存和磁盘的固有约束依然存在。它所提供的是一个通用框架,允许以一种独立于底层执行引擎的方式相对简单地表达并行计算,同时还能够根据手头数据和资源的实际情况,为任何特定问题领域精确调整延迟和正确性的程度。从这个意义上说,它是一个旨在便于构建实用的大规模数据处理管道的模型。
5:事件时间(event time)是指数据所描述事件实际发生的时间,与数据进入系统被处理的时间(处理时间,processing time)相对。在流数据处理中,区分这两种时间概念对于准确处理和分析数据很重要。
所谓事件时间,我们指的是事件实际发生的时间,而非事件被处理的时间。更多内容见 1.3 节。
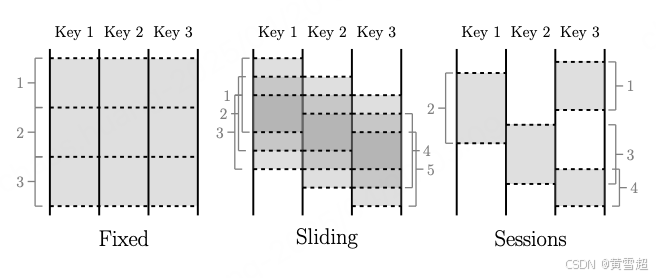
图 1:常见的窗口化模式
1.1 无界 / 有界与流处理 / 批处理
在描述无限 / 有限数据集时,我们更倾向于使用 "无界 / 有界" 这两个术语,而非 "流处理 / 批处理",因为后一组术语暗示了对特定类型执行引擎的使用。实际上,自无界数据集诞生以来,人们就一直通过重复运行批处理系统来处理它们,而且设计良好的流处理系统完全有能力处理有界数据。
从模型的角度来看,流处理或批处理的区分在很大程度上并不重要,因此我们仅将这些术语用于描述运行时执行引擎。
1.2 窗口化
窗口化 22 是将数据集切分成有限的数据块,以便作为一个组进行处理。在处理无界数据时,某些操作需要窗口化(在大多数形式的分组中划定有限边界,如聚合、外连接、有时限的操作等),而其他操作则不需要(过滤、映射、内连接等)。对于有界数据,窗口化本质上是可选的,不过在许多情况下它在语义上仍然是一个有用的概念(例如,对先前计算的无界数据源的部分进行大规模回填更新)。窗口化实际上始终是基于时间的;虽然许多系统支持基于元组的窗口化,但这本质上是在一个逻辑时间域上的基于时间的窗口化,其中按顺序排列的元素具有依次递增的逻辑时间戳。窗口可以是对齐的,即在相关的时间窗口内应用于所有数据;也可以是非对齐的,即在给定的时间窗口内仅应用于数据的特定子集(例如,按键划分)。图 1 突出显示了处理无界数据时遇到的三种主要窗口类型。
固定窗口(有时称为滚动窗口)由静态窗口大小定义,例如每小时窗口或每天窗口。它们通常是对齐的,即每个窗口在相应的时间段内应用于所有数据。为了将窗口完成的负载在时间上均匀分布,有时会通过将每个键的窗口相位偏移某个随机值来使其不对齐。
滑动窗口由窗口大小和滑动周期定义,例如每分钟开始的每小时窗口。周期可能小于窗口大小,这意味着窗口可能会重叠。滑动窗口通常也是对齐的;尽管在图中绘制的方式给人一种滑动的感觉,但图中的所有五个窗口将应用于所有三个键,而不仅仅是窗口 3。固定窗口实际上是滑动窗口的一种特殊情况,即窗口大小等于周期。
会话窗口是捕获数据子集上某段活动时间的窗口,在这种情况下是按键划分。通常,它们由超时间隔定义。在小于超时时间的时间段内发生的任何事件都被分组到一个会话中。会话窗口是非对齐窗口。例如,窗口 2 仅应用于键 1,窗口 3 仅应用于键 2,窗口 1 和窗口 4 仅应用于键 3。
1.3 时间域
在处理与时间事件相关的数据时,有两个固有的时间域需要考虑。尽管在各种文献(特别是时间管理 28 和语义模型 9,但也包括窗口化 22、无序处理 23、标点符号 30、心跳 21、水位线 2、帧 31)中都有涉及,但在脑海中清晰明确这些概念后,2.3 节中的详细示例会更容易理解。我们关注的两个时间域是:
- 事件时间:即事件本身实际发生的时间,也就是事件发生时(无论哪个系统生成该事件)系统时钟时间的记录。
- 处理时间:即事件在管道处理过程中任何给定点被观测到的时间,也就是根据系统时钟的当前时间。请注意,我们不对分布式系统内的时钟同步做任何假设。
给定事件的事件时间本质上永远不会改变,但随着每个事件在管道中流动且时间不断向前推进,其处理时间会不断变化。在稳健地分析事件发生的时间背景时,这是一个重要的区别。
在处理过程中,所使用系统的实际情况(通信延迟、调度算法、处理时间、管道序列化等)会导致这两个时间域之间存在固有的、动态变化的偏差。全局进度指标,如标点符号或水位线,为可视化这种偏差提供了一种好方法。就我们的目的而言,我们将考虑类似 MillWheel 的水位线,它是管道已处理事件时间的下限(通常通过启发式方法确定 6 )。正如我们上面已经明确指出的,完整性的概念通常与正确性不兼容,因此我们不会依赖水位线来确保完整性。然而,它们确实提供了一个有用的概念,即系统何时认为在事件时间的某个给定点之前的所有数据都可能已被观测到,因此不仅在可视化偏差方面有应用,还在监测整个系统的健康状况和进展方面有应用,并且在做出不需要完全准确的关于进展的决策时也有应用,例如基本的垃圾回收策略。
6:对于大多数现实世界中的分布式数据集,系统缺乏足够的信息来确定 100% 准确的水位线。例如,在视频会话用例中,考虑离线观看情况。如果有人带着移动设备进入荒野,系统实际上无法知晓他们何时会回到有网络的地方,重新建立连接,并开始上传那段时间的视频观看数据。因此,大多数水位线必须根据有限的可用信息通过启发式方法来定义。对于像日志文件这样能提供有关未观测数据元数据的结构化输入源,我们发现这些启发式方法非常准确,因此在许多用例中作为完成度估计实际上很有用。此外,重要的是,一旦通过启发式方法确定了水位线,它就可以像标点符号一样准确地在管道的其余部分向下游传播,尽管这个整体指标本身仍然是基于启发式的。
在理想情况下,时间域偏差始终为零;我们会在所有事件发生时立即处理它们。然而,现实并非如此理想,我们最终得到的情况往往更像图 2。大约从 12:00 开始,随着管道滞后,水位线开始偏离实时时间,在 12:02 左右又回到接近实时时间,然后到 12:03 时又明显滞后。这种偏差的动态变化在分布式数据处理系统中非常常见,并且在定义提供正确、可重复结果所需的功能方面将发挥重要作用。
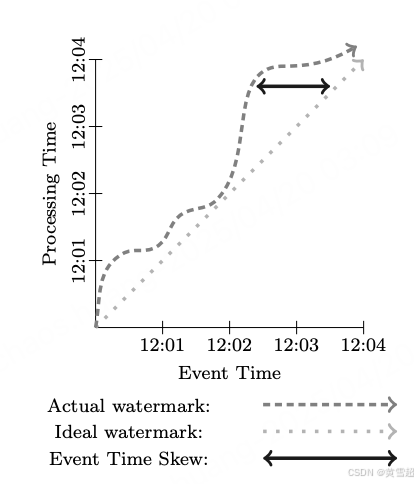
图 2:时间域偏差
2. 数据流模型
在本节中,我们将定义该系统的形式化模型,并解释为什么其语义具有足够的通用性,可以涵盖标准的批处理、微批处理和流处理模型,以及 Lambda 架构的混合流批处理语义。对于代码示例,我们将使用 Dataflow Java SDK 的简化变体,它本身是 FlumeJava API 的演进版本。
2.1 核心原语
首先,让我们考虑经典批处理模型中的原语。Dataflow SDK 有两个核心转换操作,作用于流经系统的(键,值)对 7 :
- ParDo :用于通用并行处理。每个要处理的输入元素(其本身可能是一个有限集合)被提供给一个用户定义的函数(在 Dataflow 中称为 DoFn),该函数每个输入可以产生零个或多个输出元素。例如,考虑一个扩展输入键所有前缀的操作,将值复制到这些前缀上:
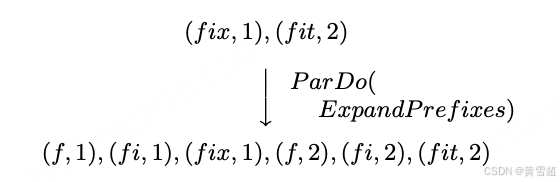
- GroupByKey :用于对(键,值)对进行按键分组:
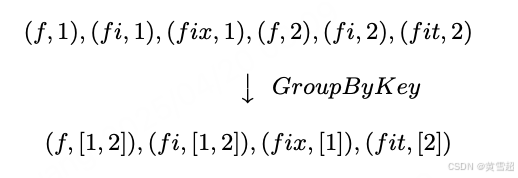
7:不失一般性,我们将系统中的所有元素都视为(键,值)对,尽管对于某些操作(如 ParDo)实际上并不需要键。大多数有意义的讨论都围绕着确实需要键的 GroupByKey 展开,所以假设键存在会更简单。
ParDo操作对每个输入元素按元素进行处理,因此自然适用于无界数据。另一方面,GroupByKey操作会在将数据发送到下游进行归约之前,先收集给定键的所有数据。如果输入源是无界的,我们无从知晓它何时结束。解决这个问题的常见方法是对数据进行窗口化处理。
2.2 窗口化
支持分组的系统通常将其 GroupByKey 操作重新定义为本质上的 GroupByKeyAndWindow 操作。我们在此的主要贡献是支持非对齐窗口,这基于两个关键见解。第一,从模型的角度来看,将所有窗口化策略都视为非对齐的处理方式更为简单,并允许底层实现在适用的情况下对对齐情况应用相关优化。第二,窗口化可以分解为两个相关操作:
- Set<Window> AssignWindows(T datum):将元素分配到零个或多个窗口。这本质上是 Li 22 中的桶操作符。
- Set<Window> MergeWindows(Set<Window> windows):在分组时合并窗口。这允许随着数据的到达和分组,随时间构建数据驱动的窗口。
对于任何给定的窗口化策略,这两个操作密切相关;滑动窗口分配需要滑动窗口合并,会话窗口分配需要会话窗口合并,等等。
请注意,为了原生支持事件时间窗口化,我们现在不再通过系统传递(键,值)对,而是传递(键,值,事件时间,窗口)四元组。元素带着事件时间戳(在管道的任何点也可以修改 8)被提供给系统,并且最初被分配到一个默认的全局窗口,该窗口覆盖所有事件时间,提供与标准批处理模型中默认设置相匹配的语义。
8:然而,请注意,某些时间戳修改操作与水位线等进度跟踪指标相悖;将时间戳移到水位线之后会使给定元素相对于该水位线而言成为迟到数据。
2.2.1 窗口分配
从模型的角度来看,窗口分配会在元素被分配到的每个窗口中创建该元素的一个新副本。例如,考虑对一个数据集按宽度为两分钟、周期为一分钟的滑动窗口进行窗口化,如图 3 所示(为简洁起见,时间戳以 HH:MM 格式给出)。

图 3:窗口分配
在这种情况下,两个(键,值)对中的每一个都被复制,以便存在于与元素时间戳重叠的两个窗口中。由于窗口直接与它们所属的元素相关联,这意味着窗口分配可以在管道中应用分组之前的任何位置进行。这一点很重要,因为分组操作可能隐藏在复合转换(例如 Sum.integersPerKey ())下游的某个位置。
2.2.2 窗口合并
窗口合并是 GroupByKeyAndWindow 操作的一部分,结合示例来解释最为合适。我们将使用会话窗口化,因为这是我们的主要用例。图 4 展示了四个示例数据,其中三个属于键 k1,一个属于键 k2,它们按会话窗口化,会话超时时间为 30 分钟。所有数据最初都由系统放置在默认的全局窗口中。AssignWindows 的会话实现将每个元素放入一个单独的窗口,该窗口在其自身时间戳之后延伸 30 分钟;这个窗口表示如果后续事件要被视为同一会话的一部分,它们可以落入的时间范围。然后我们开始 GroupByKeyAndWindow 操作,这实际上是一个由五个部分组成的复合操作:
- DropTimestamps:丢弃元素时间戳,因为从这一步开始只有窗口是相关的 9 。
- GroupByKey:按键对(值,窗口)元组进行分组。
- MergeWindows:合并当前为一个键缓冲的窗口集合。实际的合并逻辑由窗口化策略定义。在这种情况下,v1 和 v4 的窗口重叠,因此会话窗口化策略将它们合并为一个新的、更大的会话,如加粗部分所示。
- GroupAlsoByWindow:对于每个键,按窗口对值进行分组。在上一步合并之后,v1 和 v4 现在处于相同的窗口中,因此在这一步被分组在一起。
- ExpandToElements:将每个键、每个窗口的一组值扩展为(键,值,事件时间,窗口)元组,并带有新的每个窗口的时间戳。在这个示例中,我们将时间戳设置为窗口的结束时间,但任何大于或等于窗口中最早事件时间戳的时间戳,就水位线正确性而言都是有效的。

图 4:窗口合并
2.2.3 API
作为窗口化在实践中使用的一个简要示例,考虑以下 Cloud Dataflow SDK 代码,用于计算按键的整数总和:
Scala
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input
.apply(Sum.integersPerKey());要执行相同的操作,但像图 4 中那样窗口化为超时时间为 30 分钟的会话窗口,在启动求和操作之前添加一个单一的 Window.into 调用:
Scala
PCollection<KV<String, Integer>> input = IO.read(...);
PCollection<KV<String, Integer>> output = input
.apply(Window.into(Sessions.withGapDuration(
Duration.standardMinutes(30))))
.apply(Sum.integersPerKey());2.3 触发器与增量处理
构建非对齐的事件时间窗口的能力是一种改进,但现在我们还有另外两个缺点需要解决:
- 我们需要某种方式来支持基于元组和处理时间的窗口,否则相对于现有的其他系统,我们的窗口化语义会退化。
- 我们需要某种方式来知道何时为一个窗口发出结果。由于数据相对于事件时间是无序的,我们需要其他某种信号来告诉我们窗口何时完成。
我们将在 2.4 节解决窗口完整性问题之后,再处理基于元组和处理时间的窗口问题。至于窗口完整性,解决它的最初想法可能是使用某种全局事件时间进度指标,如水位线。然而,水位线本身在正确性方面有两个主要缺点:
- 它们有时太快,这意味着可能会有迟来的数据在水位线之后到达。对于许多分布式数据源,要得出完全完美的事件时间水位线是难以处理的,因此如果我们希望输出数据具有 100% 的正确性,就不可能仅仅依赖它。
- 它们有时太慢。因为它们是全局进度指标,水位线可能会因为单个缓慢的数据而被整个管道拖累。即使对于事件时间偏差变化不大的健康管道,偏差的基线水平可能仍然有几分钟甚至更多,这取决于输入源。因此,与例如可比的 Lambda 架构管道相比,仅使用水位线作为发出窗口结果的唯一信号可能会导致整体结果的延迟更高。
基于这些原因,我们假设仅靠水位线是不够的。解决完整性问题的一个有用见解是,Lambda 架构实际上回避了这个问题:它不是通过某种方式更快地提供正确答案来解决完整性问题;它只是提供流处理管道所能提供的结果的最佳低延迟估计,并承诺一旦批处理管道运行,最终会达到一致性和正确性 10 。
10:请注意,在现实中,只有在批处理作业运行时输入数据完整,批处理作业的输出才是正确的;如果数据随时间变化,必须检测到这种变化并重新执行批处理作业。
如果我们想在单个管道内(无论执行引擎是什么)做同样的事情,那么我们将需要一种方法为任何给定窗口提供多个答案(或窗格)。我们将此功能称为触发器,因为它们允许指定何时为给定窗口触发输出结果。
简而言之,触发器是一种响应内部或外部信号刺激 GroupByKeyAndWindow 结果产生的机制。它们与窗口化模型互补,因为它们各自沿着不同的时间轴影响系统行为:
- 窗口化决定在事件时间的哪个位置将数据分组在一起进行处理。
- 触发决定在处理时间的何时将分组结果作为窗格发出 11 。
11:特定的触发器,比如水位线触发器,在其提供的功能中会利用事件时间,但它们在管道内产生的效果仍是在处理时间轴上得以体现。
我们的系统提供预定义的触发器实现,用于在完成估计时触发(例如水位线,包括百分位水位线,当你更关心快速处理最小百分比的输入数据而不是处理每一个最后的数据时,它为处理批处理和流处理执行引擎中的掉队数据提供了有用的语义)、在处理时间的特定点触发,以及响应数据到达(计数、字节数、数据标点符号、模式匹配等)触发。我们还支持将触发器组合成逻辑组合(与、或等)、循环、序列以及其他此类结构。此外,用户可以利用执行运行时的底层原语(例如水位线定时器、处理时间定时器、数据到达、组合支持)以及任何其他相关外部信号(数据注入请求、外部进度指标、RPC 完成回调等)定义自己的触发器。
我们将在 2.4 节更详细地查看示例。
除了控制结果何时发出之外,触发器系统还通过三种不同的细化模式提供了一种控制同一窗口的多个窗格如何相互关联的方法:
- 丢弃模式:触发时,窗口内容被丢弃,后续结果与先前结果无关。这种模式在数据的下游消费者(无论是管道内部还是外部)期望来自各种触发事件的值相互独立的情况下很有用(例如,当注入到一个生成注入值总和的系统中时)。就缓冲的数据量而言,它也是最有效的,尽管对于可以建模为 Dataflow Combiner 的结合律和交换律操作,效率差异通常很小。对于我们的视频会话用例,这是不够的,因为要求我们数据的下游消费者拼接部分会话是不切实际的。
- 累积模式:触发时,窗口内容在持久状态中保持不变,后续结果成为先前结果的细化。当下游消费者期望在收到同一窗口的多个结果时用新值覆盖旧值时,这种模式很有用,实际上这是 Lambda 架构系统中使用的模式,其中流处理管道产生低延迟结果,然后在未来被批处理管道的结果覆盖。对于视频会话,如果我们只是计算会话,然后立即将它们写入某个支持更新的输出源(例如数据库或键值存储),这可能就足够了。
- 累积与撤回模式:触发时,除了累积语义之外,还会在持久状态中存储发出值的一个副本。当窗口在未来再次触发时,将首先发出先前值的撤回,然后是作为普通数据的新值 12 。在具有多个串行 GroupByKeyAndWindow 操作的管道中,撤回是必要的,因为单个窗口在后续触发事件中生成的多个结果在下游分组时可能最终落在不同的键上。在这种情况下,除非通过撤回通知第二个分组操作原始输出的影响应该被逆转,否则它将为这些键生成不正确的结果。也是可逆的 Dataflow Combiner 操作可以通过 uncombine 方法有效地支持撤回。对于视频会话,这种模式是理想的。例如,如果我们在会话创建的下游执行依赖于会话自身属性的聚合操作,例如检测不受欢迎的广告(例如在大多数会话中观看时间少于五秒的广告),随着时间推移输入数据发生变化,初始结果可能会无效,例如大量离线移动观众重新上线并上传会话数据。撤回为我们提供了一种在具有多个串行分组阶段的复杂管道中适应这些类型变化的方法。
12:撤回处理的一种简单实现需要确定性操作,但通过增加复杂性和成本,也可以支持非确定性操作;我们已经见过需要这种操作的用例,比如概率建模。
2.4 示例
我们现在将考虑一系列示例,这些示例突出了数据流模型支持的多种有用输出模式。我们将在 2.2.3 节整数求和管道的上下文中查看每个示例:
Scala
PCollection<KV<String, Integer>> output = input
.apply(Sum.integersPerKey());假设我们有一个输入源,从中观测到十个数据点,每个数据点都是较小的整数值。我们将在有界和无界数据源的两种情况下考虑这些数据。为简化图示,我们假定所有这些数据都属于同一个键;在实际的管道中,我们在此描述的操作类型会针对多个键并行发生。图 5 展示了这些数据如何在我们关注的两个时间轴上相互关联。X 轴绘制的是数据的事件时间(即事件实际发生的时间),而 Y 轴绘制的是数据的处理时间(即管道观测到数据的时间)。除非另有说明,所有示例均假定在我们的流处理引擎上执行。
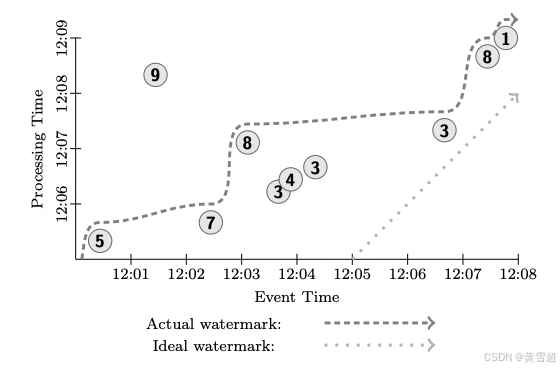
图 5:示例输入
许多示例还会依赖水位线,在这种情况下,我们会在图示中包含它们。我们将同时绘制理想水位线和一个实际水位线示例。斜率为 1 的直虚线代表理想水位线,即假设不存在事件时间偏差,且所有事件在发生时都由系统进行处理。鉴于分布式系统的复杂性,偏差是常见现象;图 5 中实际水位线的曲折路径就是例证,用较深的虚线表示。还需注意的是,这条水位线的启发式特性通过值为 9 的单个 "迟到" 数据体现出来,该数据出现在水位线之后。
如果我们要在经典批处理系统中使用上述求和管道处理这些数据,我们会等待所有数据到达,将它们归为一组(因为这些数据都属于同一个键),然后对它们的值求和,得到总计为 51 的结果。这个结果由图 6 中的深色矩形表示,其面积涵盖了求和所涉及的事件时间和处理时间范围(矩形顶部表示在处理时间中结果具体化的时间)。由于经典批处理不区分事件时间,结果包含在一个覆盖所有事件时间的单一全局窗口内。并且由于只有在接收到所有输入后才计算输出,结果涵盖了执行过程中的所有处理时间。
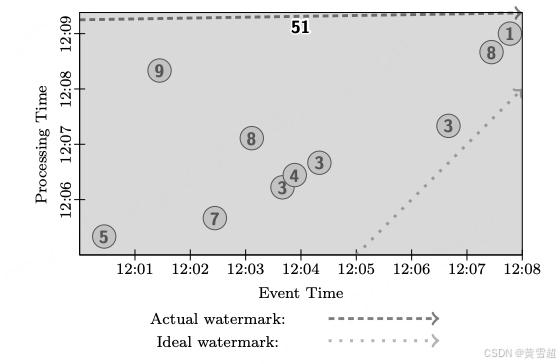
图6:经典批处理执行情况
请注意此图中包含了水位线。虽然水位线通常不用于经典批处理,但从语义上讲,水位线会保持在起始时间,直到所有数据都被处理完毕,然后推进到无穷大。需要注意的一个要点是,通过以这种方式推进水位线,在流处理系统中运行数据可以获得与经典批处理相同的语义。
现在假设我们想将此管道转换为在无界数据源上运行。在 Dataflow 中,默认的触发语义是当水位线经过窗口时发出窗口。但是,当对无界输入源使用全局窗口时,我们确定这种情况永远不会发生,因为全局窗口涵盖了所有事件时间。因此,我们需要通过除默认触发器之外的其他方式触发,或者使用除全局窗口之外的其他窗口方式。否则,我们将永远得不到任何输出。
我们首先来看更改触发器,因为这将使我们能够生成概念上相同的输出(随时间的全局按键总和),但会有定期更新。在这个例子中,我们应用一个 Window.trigger 操作,它在每分钟的处理时间周期边界上重复触发。我们还指定了累积模式,以便全局总和随时间细化(这假定我们有一个输出接收器,在其中我们可以简单地用新结果覆盖该键的先前结果,例如数据库或键值存储)。因此,在图 7 中,我们在每分钟的处理时间生成更新后的全局总和。请注意,半透明的输出矩形是如何重叠的,因为累积窗格通过合并处理时间的重叠区域在先前结果的基础上构建:
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.accumulating())
.apply(Sum.integersPerKey());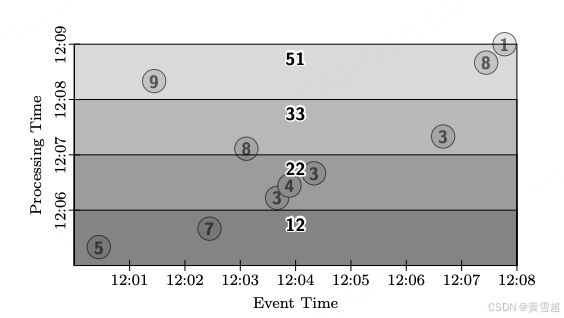
图7:全局窗口、按周期触发、累积模式
如果我们希望每分钟生成总和的增量,我们可以切换到丢弃模式,如图 8 所示。请注意,这实际上提供了许多流处理系统所提供的处理时间窗口语义。输出窗格不再重叠,因为它们的结果包含来自独立处理时间区域的数据。
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtPeriod(1, MINUTE)))
.discarding())
.apply(Sum.integersPerKey());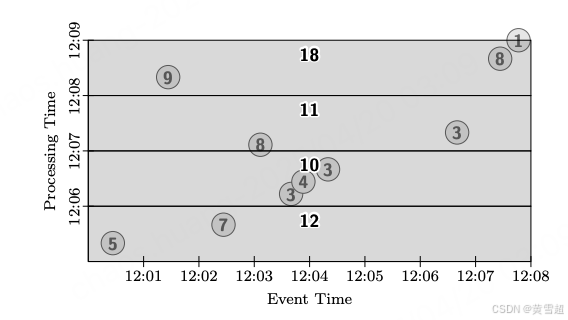
图 8:全局窗口、按周期触发、丢弃模式
另一种更可靠的提供处理时间窗口语义的方法是在数据进入时简单地将到达时间指定为事件时间,然后使用事件时间窗口化。使用到达时间作为事件时间的一个好处是,系统完全知晓传输中的事件时间,因此可以提供完美的(即非启发式的)水位线,且不会有迟到数据。对于真实事件时间并非必要或不可用的用例,这是一种处理无界数据的有效且经济高效的方式。
在我们更深入研究其他窗口选项之前,让我们考虑对此管道的触发器再做一个更改。我们希望建模的另一种常见窗口模式是基于元组的窗口。我们可以通过简单地更改触发器,使其在一定数量(比如说两个)的数据到达后触发,来提供这种功能。在图 9 中,我们得到五个输出,每个输出包含两个相邻(按处理时间)数据的总和。更复杂的基于元组的窗口方案(例如滑动基于元组的窗口)需要自定义窗口策略,但在其他方面是受支持的。
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.trigger(Repeat(AtCount(2)))
.discarding())
.apply(Sum.integersPerKey());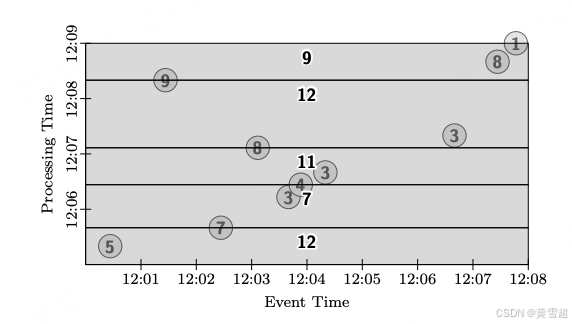
图 9:全局窗口、按计数触发、丢弃模式
现在让我们回到支持无界源的另一个选项:放弃全局窗口化。首先,让我们将数据窗口化为固定的、两分钟的累积窗口:
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES)
.accumulating())
.apply(Sum.integersPerKey());在未指定触发策略的情况下,系统将使用默认触发器,实际上就是:
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(Repeat(AtWatermark())))
.accumulating())
.apply(Sum.integersPerKey());当水位线经过相关窗口的末尾时,水位线触发器会触发。批处理和流处理引擎都实现了水位线,如 3.1 节所详述。触发器中的 Repeat 调用用于处理迟到数据;如果有任何数据在水位线之后到达,它们将实例化重复的水位线触发器,由于水位线已经经过,该触发器将立即触发。
图 10 - 12 分别描述了此管道在不同类型运行时引擎上的情况。我们首先观察此管道在批处理引擎上的执行情况。根据我们当前的实现,数据源必须是有界的,所以与上述经典批处理示例一样,我们会等待批处理中的所有数据到达。然后我们将按事件时间顺序处理数据,随着模拟水位线的推进发出窗口,如图 10 所示:
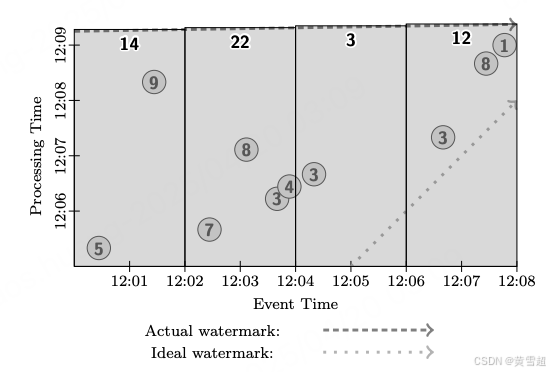
图 10:固定窗口,批处理模式
现在想象在这个数据源上使用一分钟微批次运行微批处理引擎。系统会收集一分钟的输入数据,进行处理,然后重复这个过程。每次,当前批次的水位线将从起始时间开始推进到结束时间(严格来说,会瞬间从批次的结束时间跳到时间的结束,因为在该时间段内不存在数据)。因此,每一轮微批次我们都会得到一个新的水位线,以及自上一轮以来内容发生变化的所有窗口的相应输出。这在延迟和最终正确性之间提供了很好的平衡,如图 11 所示:
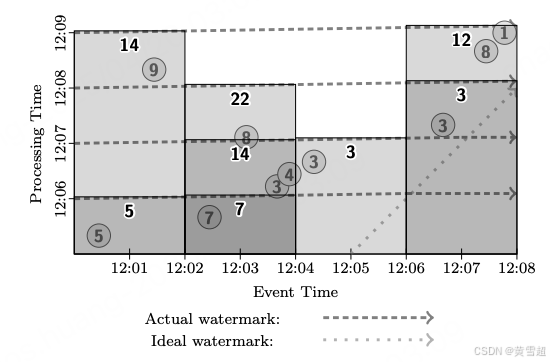
图11:固定窗口,微批处理模式
接下来,考虑此管道在流处理引擎上执行的情况,如图 12 所示。大多数窗口在水位线经过时发出。然而请注意,值为 9 的数据相对于水位线实际上是迟到的。由于某种原因(移动输入源离线、网络分区等),系统没有意识到该数据尚未注入,因此,在观测到值为 5 的数据后,允许水位线推进到最终会被值为 9 的数据占据的事件时间点之后。因此,一旦值为 9 的数据最终到达,它会导致第一个窗口(事件时间范围为 [12:00, 12:02))重新触发,并更新总和:
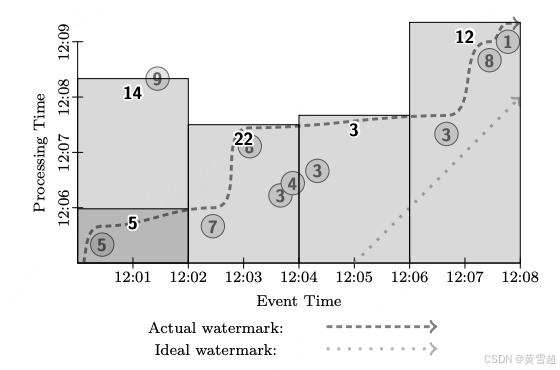
图 12:固定窗口,流处理模式
这种输出模式很好,因为每个窗口大致有一个输出,在迟到数据的情况下有一次细化。但由于必须等待水位线推进,结果的整体延迟明显比微批处理系统更差;这就是 2.3 节中提到的水位线太慢的情况。
如果我们希望通过为所有窗口提供多个部分结果来降低延迟,我们可以添加一些额外的基于处理时间的触发器,以便在水位线实际经过之前定期提供更新,如图 13 所示。这比微批处理管道的延迟略好,因为数据在到达时会累积在窗口中,而不是以小批次进行处理。对于强一致性的微批处理和流处理引擎,它们之间的选择(以及微批大小的选择)实际上就变成了延迟与成本之间的权衡,这正是我们使用此模型要实现的目标之一。
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(SequenceOf(
RepeatUntil(
AtPeriod(1, MINUTE),
AtWatermark()),
Repeat(AtWatermark())))
.accumulating())
.apply(Sum.integersPerKey());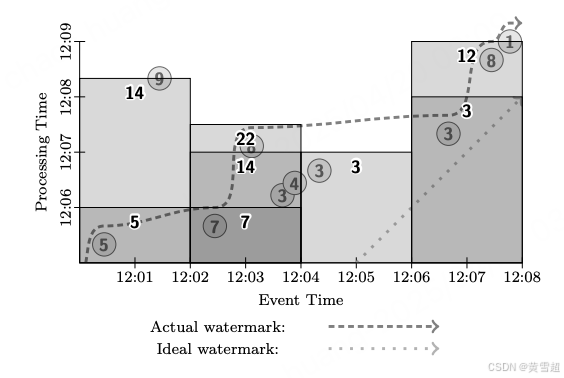
图13:固定窗口、流处理、部分结果模式
作为最后一个练习,让我们更新示例以满足视频会话的要求(为保持图示一致性,仍使用求和作为聚合操作;切换到其他聚合操作很简单),更新为超时时间为一分钟的会话窗口化并启用撤回功能。这突出了将模型分解为四个部分(计算什么、在事件时间的何处计算、在处理时间的何时观测答案以及这些答案与后续细化的关系)所提供的可组合性,同时也说明了撤销先前值的作用,否则这些先前值可能与作为替代提供的值无关。
Scala
PCollection<KV<String, Integer>> output = input
.apply(Window.into(Sessions.withGapDuration(1, MINUTE))
.trigger(SequenceOf(
RepeatUntil(
AtPeriod(1, MINUTE),
AtWatermark()),
Repeat(AtWatermark())))
.accumulatingAndRetracting())
.apply(Sum.integersPerKey());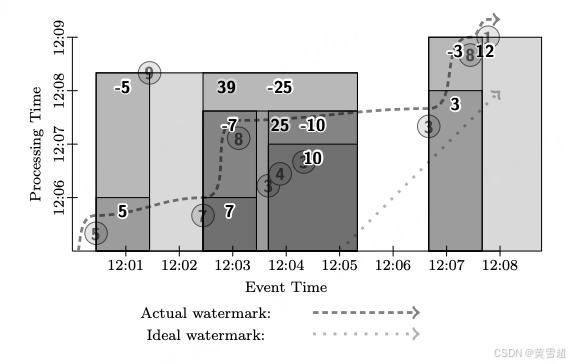
图 14:会话窗口、可撤回模式
在这个例子中,在第一个一分钟处理时间边界,我们输出值为 5 和 7 的初始单例会话。在第二个分钟边界,我们输出值为 10 的第三个会话,它由值 3、4 和 3 组成。当最终观测到值为 8 的数据时,它将值为 7 和 10 的两个会话合并。当水位线经过这个新合并会话的末尾时,会发出值为 7 和 10 的会话的撤回信息,以及值为 25 的新会话的正常数据。类似地,当值为 9 的数据(迟到)到达时,它将值为 5 的会话与会值为 25 的会话合并。重复的水位线触发器随后立即发出值为 5 和 25 的撤回信息,接着是值为 39 的合并会话。对于值 3、8 和 1 也会发生类似的情况,最终以值为 3 的初始会话的撤回信息结束,接着是值为 12 的合并会话。
3.实现与设计
3.1 实现
我们已在 FlumeJava 内部实现了该模型,在流模式下将 MillWheel 用作底层执行引擎;此外,在撰写本文时,针对 Cloud Dataflow 的外部重新实现已基本完成。由于先前文献中已对这些内部系统进行过描述,且 Cloud Dataflow 已公开可用,为简洁起见,此处省略实现细节。一个有趣的点是,核心的窗口化和触发代码具有很强的通用性,其中很大一部分在批处理和流处理实现中是共享的;该系统本身值得在未来的工作中进行更详细的分析。
3.2 设计原则
尽管我们的大部分设计灵感来自于下文 3.3 节中详细介绍的实际经验,但也受到一组核心原则的指导,我们认为我们的模型应体现这些原则:
- 绝不依赖任何关于完整性的概念。
- 保持灵活性,以适应已知和未来可能出现的各种用例。
- 在每个设想的执行引擎环境中,不仅要有意义,还要有价值。
- 鼓励清晰的实现。
- 支持在数据产生的上下文中对数据进行稳健的分析。
虽然以下经验影响了模型的特定功能,但这些原则决定了模型的整体形态和特征,我们相信最终会得到一个更全面、通用的结果。
3.3 实际经验启发
在设计 Dataflow 模型时,我们考虑了多年来在 FlumeJava 和 MillWheel 方面的实际经验。运行良好的部分,我们确保在模型中体现;运行不太好的部分则促使我们改变方法。以下是一些影响我们设计的经验简述。
3.3.1 大规模回填与 Lambda 架构:统一模型
多个团队在 MillWheel 上运行日志合并管道。一个特别大的日志合并管道默认在 MillWheel 上以流模式运行,但有一个单独的 FlumeJava 批处理实现用于大规模回填。更好的设置是使用统一模型编写一个单一实现,无需修改即可在流模式和批处理模式下运行。这成为了统一批处理、微批处理和流引擎的最初动机用例,并在图 10 - 12 中有所体现。
统一模型的另一个动机来自于 Lambda 架构的经验。尽管谷歌的大多数数据处理用例由批处理或流系统单独处理,但有一个 MillWheel 客户以弱一致性模式运行他们的流管道,并通过每晚的 MapReduce 生成真实数据。他们发现随着时间推移,客户不再信任弱一致性结果,因此围绕强一致性重新实现了他们的系统,以便提供可靠、低延迟的结果。这一经验进一步促使我们希望在执行引擎之间实现灵活选择。
3.3.2 非对齐窗口:会话
从一开始,我们就知道需要支持会话;实际上,这是我们的窗口模型相对于现有模型的主要贡献。会话在谷歌内部是一个极其重要的用例(实际上也是创建 MillWheel 的原因之一),并在包括搜索、广告、分析、社交和 YouTube 等多个产品领域中使用。几乎任何关心在一段时间内关联原本不相关的用户活动突发情况的人,都会通过计算会话来实现。因此,在我们的设计中,对会话的支持至关重要。如图 14 所示,在 Dataflow 模型中生成会话很简单。
3.3.3 计费:触发、累积与撤回
两个基于 MillWheel 构建计费管道的团队遇到了一些问题,这些问题推动了模型部分内容的设计。当时的推荐做法是使用水印作为完成指标,并采用临时逻辑处理延迟数据或源数据的变化。由于缺乏更新和撤回的原则性系统,一个处理资源利用率统计信息的团队最终离开了我们的平台,构建了一个定制解决方案(其模型最终与我们同时开发的模型非常相似)。另一个计费团队在处理输入中的拖后腿数据导致的水印滞后方面遇到了重大问题。这些缺点成为我们设计中的主要动机,并影响了关注点从追求完整性向随着时间推移的适应性转变。结果有两方面:触发机制,它允许简洁灵活地指定结果何时具体化,如图 7 - 14 中同一数据集上可能出现的各种输出模式所示;以及通过累积(图 7 和图 8)和撤回(图 14)提供增量处理支持。
3.3.4 统计计算:水印触发
许多 MillWheel 管道计算聚合统计信息(例如延迟平均值)。对于这些管道,不需要 100% 的准确性,但需要在合理时间内对数据有一个大致完整的视图。鉴于我们使用水印对日志文件等结构化输入源能达到较高的准确性,此类客户发现水印在触发每个窗口的单个、高精度聚合方面非常有效。水印触发在图 12 中突出显示。
许多滥用检测管道在 MillWheel 上运行。滥用检测是另一个用例示例,快速处理大部分数据比更慢地处理 100% 的数据更有用。因此,它们大量使用 MillWheel 的百分位水印,这也是模型中能够支持百分位水印触发的一个强烈动机案例。
相关地,批处理作业的一个痛点是拖后腿的任务会导致执行时间变长。虽然动态重新平衡可以帮助解决这个问题,但 FlumeJava 有一个自定义功能,允许根据总体进度提前终止作业。批处理模式统一模型的好处之一是,现在这种提前终止标准可以自然地使用标准触发机制来表达,而不需要自定义功能。
3.3.5 推荐系统:处理时间触发
我们考虑的另一个管道在谷歌的一个大型属性上构建用户活动树(本质上是会话树)。然后使用这些树来构建针对用户兴趣的推荐。这个管道值得注意的是,它使用处理时间定时器来驱动输出。这是因为对于他们的系统,定期更新的部分数据视图比等待水印通过会话结束后获得大致完整的视图更有价值。这也意味着由于少量慢速数据导致的水印进度滞后不会影响其余数据输出的及时性。因此,这个管道促使我们在图 7 和图 8 中加入处理时间触发。
3.3.6 异常检测:数据驱动和复合触发
在 MillWheel 论文中,我们描述了一个用于跟踪谷歌网页搜索查询趋势的异常检测管道。在开发触发机制时,他们的差异检测系统启发了数据驱动触发。这些差异检测观察查询流,并计算是否存在峰值的统计估计。当它们认为出现峰值时,会发出开始记录,当认为峰值停止时,会发出停止记录。虽然你可以使用像 Trill 的标点符号这样的周期性内容来驱动差异输出,但对于异常检测,理想情况下你希望一旦确定发现异常就尽快输出;使用标点符号本质上会将流系统转换为微批处理,引入额外延迟。虽然对于许多用例来说是实用的,但最终并不完全适合这个用例,因此促使我们支持自定义数据驱动触发。这也是触发组合的一个动机案例,因为在现实中,系统同时运行多个差异检测,并根据一组明确定义的逻辑对它们的输出进行复用。图 9 中使用的 AtCount 触发就是数据驱动触发的示例;图 10 - 14 使用了复合触发。
4.结论
数据处理的未来在于无界数据。尽管有界数据始终会有重要且有用的地位,但从语义上讲,它被无界数据所包含。此外,无界数据集在现代商业中的扩散程度惊人。与此同时,处理后数据的消费者日益精明,要求诸如事件时间排序和非对齐窗口等强大的构造。当今存在的模型和系统为构建未来的数据处理工具提供了出色的基础,但我们坚信,为了使这些工具能够全面满足无界数据消费者的需求,整体思维方式的转变是必要的。
基于我们多年在谷歌内部处理真实世界、大规模、无界数据的经验,我们相信这里提出的模型朝着这个方向迈出了良好的一步。它支持现代数据消费者所需的非对齐、事件时间排序窗口。它提供灵活的触发以及集成的累积和撤回功能,将方法的重点从在数据中寻找完整性转变为适应现实世界数据集中始终存在的变化。它抽象掉了批处理、微批处理和流处理之间的区别,使管道构建者能够在它们之间更灵活地选择,同时使他们免受针对单个底层系统的模型中不可避免出现的特定于系统的构造的影响。其整体灵活性使管道构建者能够适当地平衡正确性、延迟和成本等维度以适应他们的用例,鉴于存在的需求多样性,这一点至关重要。最后,它通过分离正在计算什么结果、在事件时间的何处计算、在处理时间的何时具体化以及早期结果与后期细化之间的关系等概念,使管道实现更加清晰。我们希望其他人会发现这个模型有用,因为我们都在继续推动这个迷人且极其复杂领域的技术发展。
6.参考文献
1 D. J. Abadi et al. Aurora: A New Model and Architecture for Data Stream Management. The VLDB Journal, 12(2):120--139, Aug. 2003.
2 T. Akidau et al. MillWheel: Fault-Tolerant Stream Processing at Internet Scale. In Proc. of the 39th Int.Conf. on Very Large Data Bases (VLDB), 2013.
3 A. Alexandrov et al. The Stratosphere Platform for Big Data Analytics. The VLDB Journal,23(6):939--964, 2014.
4 Apache. Apache Hadoop.http://hadoop.apache.org, 2012.
5 Apache. Apache Storm.http://storm.apache.org, 2013.
6 Apache. Apache Flink.http://flink.apache.org/, 2014.
7 Apache. Apache Samza.http://samza.apache.org, 2014.
8 R. S. Barga et al. Consistent Streaming Through Time: A Vision for Event Stream Processing. In Proc.of the Third Biennial Conf. on Innovative Data Systems Research (CIDR), pages 363--374, 2007.
9 Botan et al. SECRET: A Model for Analysis of the Execution Semantics of Stream Processing Systems.Proc. VLDB Endow., 3(1-2):232--243, Sept. 2010.
10 O. Boykin et al. Summingbird: A Framework for Integrating Batch and Online MapReduce Computations. Proc. VLDB Endow., 7(13):1441--1451, Aug. 2014.
11 Cask. Tigon. http://tigon.io/, 2015.
12 C. Chambers et al. FlumeJava: Easy, Efficient Data-Parallel Pipelines. In Proc. of the 2010 ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI), pages 363--375, 2010.
13 B. Chandramouli et al. Trill: A High-Performance Incremental Query Processor for Diverse Analytics. In Proc. of the 41st Int. Conf. on Very Large Data Bases (VLDB), 2015.
14 S. Chandrasekaran et al. TelegraphCQ: Continuous Dataflow Processing. In Proc. of the 2003 ACM SIGMOD Int. Conf. on Management of Data(SIGMOD), SIGMOD '03, pages 668--668, New York,NY, USA, 2003. ACM.
15 J. Chen et al. NiagaraCQ: A Scalable Continuous Query System for Internet Databases. In Proc. of the 2000 ACM SIGMOD Int. Conf. on Management of Data (SIGMOD), pages 379--390, 2000.
16 J. Dean and S. Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. In Proc. of the Sixth Symposium on Operating System Design and Implementation (OSDI), 2004.
17 EsperTech. Esper.http://www.espertech.com/esper/, 2006.
18 Gates et al. Building a High-level Dataflow System on Top of Map-Reduce: The Pig Experience. Proc.VLDB Endow., 2(2):1414--1425, Aug. 2009.
19 Google. Dataflow SDK. https://github.com/GoogleCloudPlatform/DataflowJavaSDK, 2015.
20 Google. Google Cloud Dataflow. https://cloud.google.com/dataflow/, 2015.
21 T. Johnson et al. A Heartbeat Mechanism and its Application in Gigascope. In Proc. of the 31st Int. Conf. on Very Large Data Bases (VLDB), pages 1079--1088, 2005.
22 J. Li et al. Semantics and Evaluation Techniques for Window Aggregates in Data Streams. In Proceedings og the ACM SIGMOD Int. Conf. on Management of Data (SIGMOD), pages 311--322, 2005.
23 J. Li et al. Out-of-order Processing: A New Architecture for High-performance Stream Systems.Proc. VLDB Endow., 1(1):274--288, Aug. 2008.
24 D. Maier et al. Semantics of Data Streams and Operators. In Proc. of the 10th Int. Conf. on Database Theory (ICDT), pages 37--52, 2005.
25 N. Marz. How to beat the CAP theorem. http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html, 2011.
26 S. Murthy et al. Pulsar -- Real-Time Analytics at Scale. Technical report, eBay, 2015.
27 SQLStream. http://sqlstream.com/, 2015.
28 U. Srivastava and J. Widom. Flexible Time Management in Data Stream Systems. In Proc. of the 23rd ACM SIGMOD-SIGACT-SIGART Symp. on Princ. of Database Systems, pages 263--274, 2004.
29 A. Thusoo, J. S. Sarma, N. Jain, Z. Shao, P. Chakka, S. Anthony, H. Liu, P. Wyckoff, and R. Murthy. Hive: A Warehousing Solution over a Map-reduce Framework. Proc. VLDB Endow., 2(2):1626--1629, Aug. 2009.
30 P. A. Tucker et al. Exploiting punctuation semantics in continuous data streams. IEEE Transactions on Knowledge and Data Engineering, 15, 2003.
31 J. Whiteneck et al. Framing the Question: Detecting and Filling Spatial- Temporal Windows. In Proc. of the ACM SIGSPATIAL Int. Workshop on GeoStreaming (IWGS), 2010.
32 F. Yang and others. Sonora: A Platform for Continuous Mobile-Cloud Computing. Technical Report MSR-TR-2012-34, Microsoft Research Asia.
33 M. Zaharia et al. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. In Proc. of the 9th USENIX Conf. on Networked Systems Design and Implementation (NSDI), pages 15--28, 2012.
34 M. Zaharia et al. Discretized Streams: Fault-Tolerant Streaming Computation at Scale. In Proc. of the 24th ACM Symp. on Operating Systems Principles, 2013.