
说明:本文图片较多,耐心等待加载。(建议用电脑)
注意所有打开的文件都要记得保存。本文的操作均在Master主机下进行
第一步:准备工作
本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。
准备我们的 Hive安装包文件和mysql jdbc 包
首先需要下载Hive安装包文件, Hive官网下载地址
也可以直接点击这里从百度云盘下载软件(提取码:ziyu)。进入百度网盘后,进入"软件"目录,找到apache-hive-3.1.2-bin.tar.gz文件,下载到本地。
https://dev.mysql.com/downloads/connector/j/mysql jdbc 包https://dev.mysql.com/downloads/connector/j/
我这里呢从网盘直接下载的,因为我从官网没有看到所需要的版本。大家可以找我拿,或者也从网盘下,也很快。
然后我们将下载好的两个文件放到之前的共享文件夹(之前都讲过,可以在第一章看到)
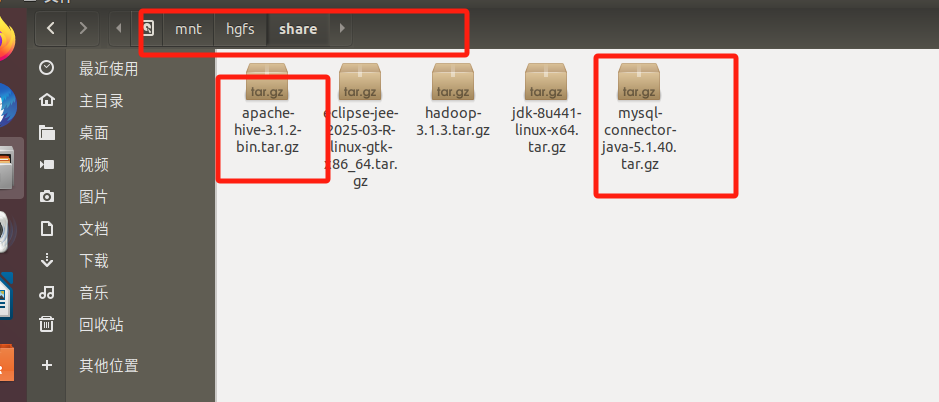
然后拖到下载里
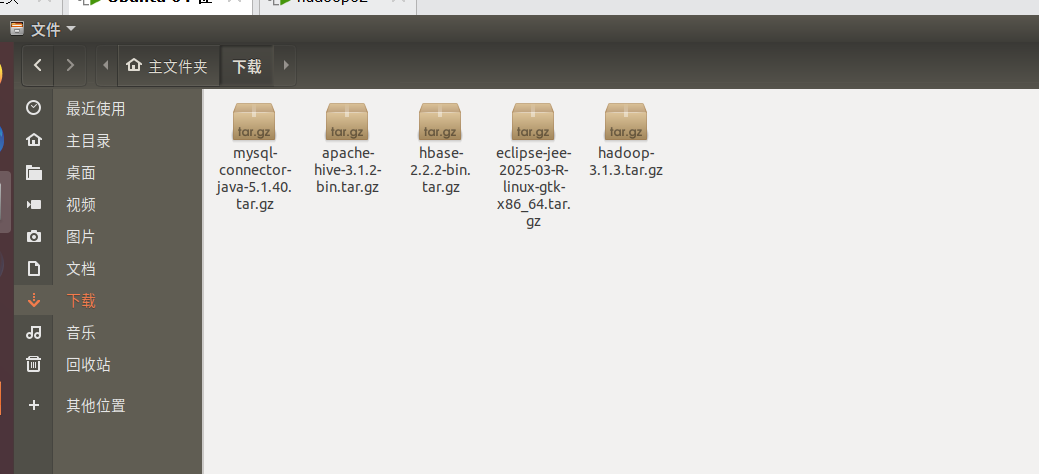
第二步:安装Hive3.1.2
1.将两台虚拟机都启动。
2.下载并解压Hive安装包
进去Master终端,(右键-》打开终端)(注意下面的最后一个命令是你自己的用户名)
注意中文版是下载,英文版是DownLoads)
bash
cd ~/下载
sudo tar -zxvf ./apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
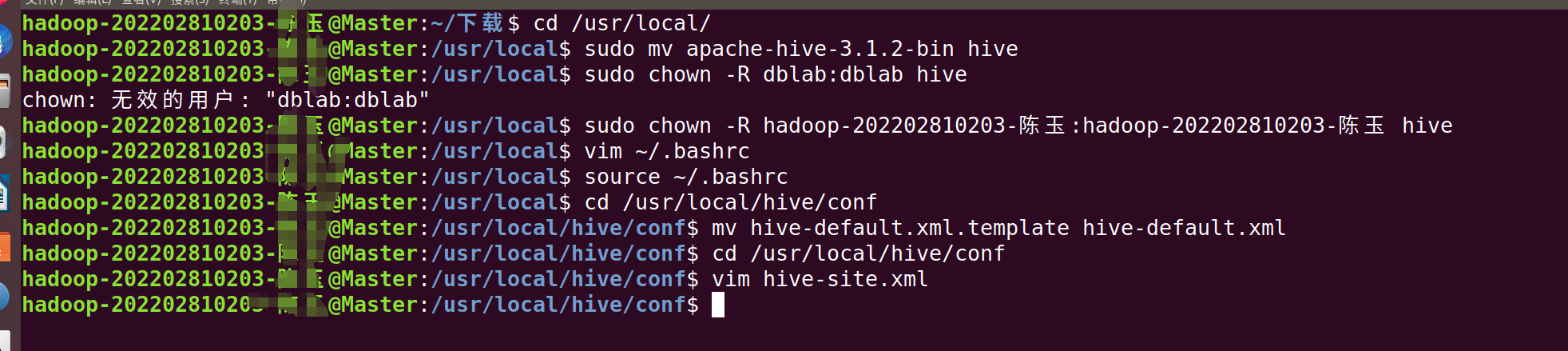
cd /usr/local/
sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
sudo chown -R hadoop-202202810203:hadoop-220202810203 hive 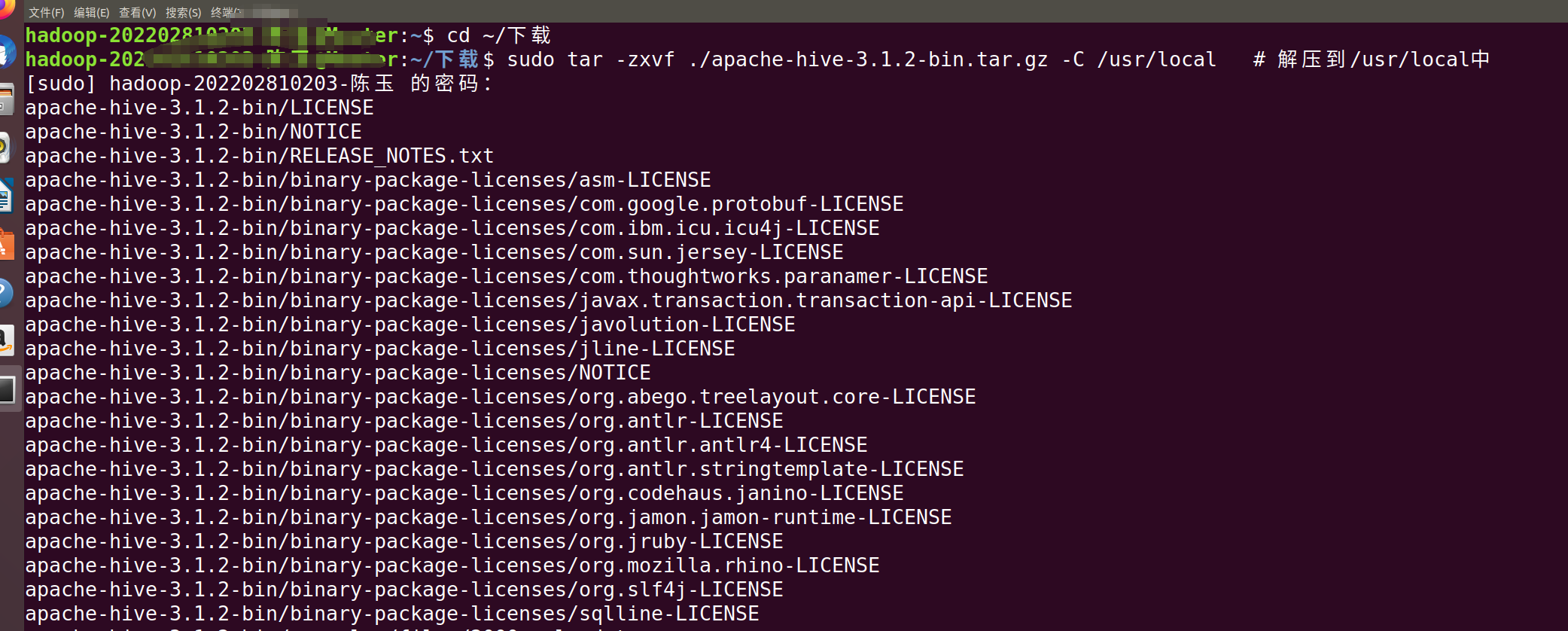
3. 配置环境变量
继续在终端输入以下命令
bash
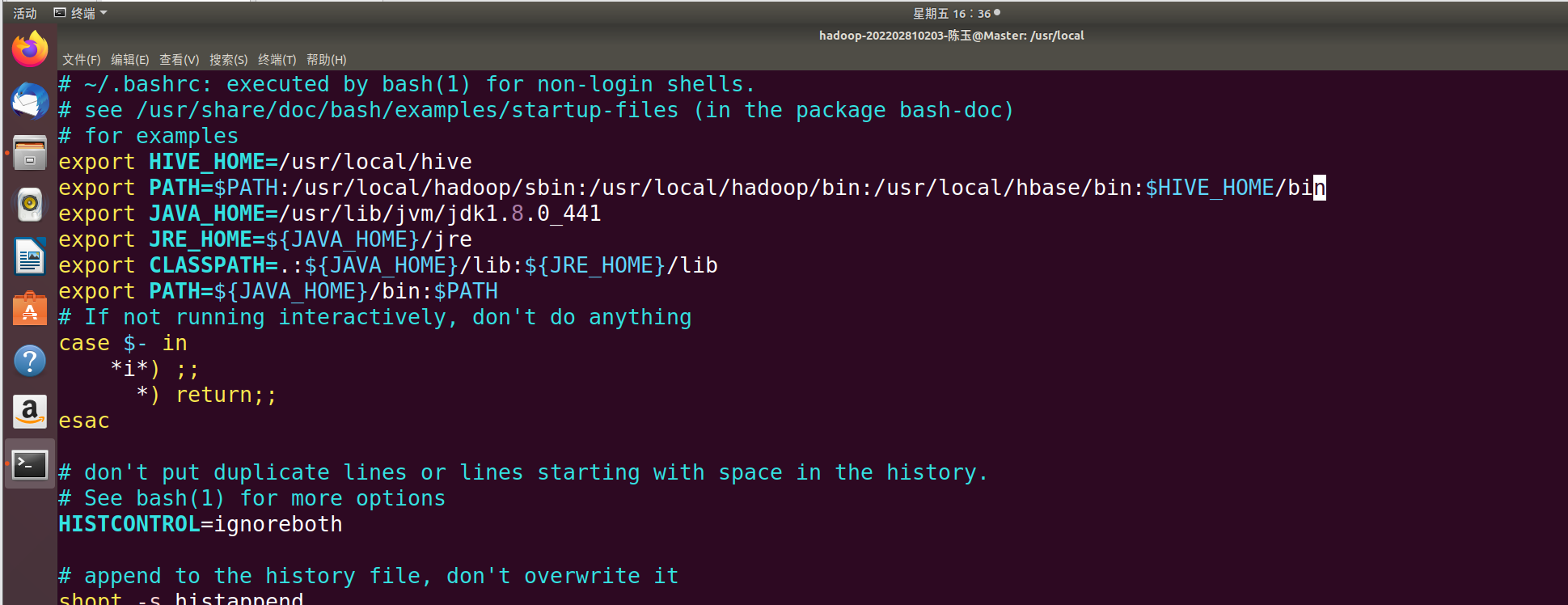
vim ~/.bashrcexport HIVE_HOME=/usr/local/hive
export PATH=PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin:/usr/local/hbase/bin:HIVE_HOME/bin
将之前的内容替换为以上内容。
保存退出,继续输入:
bash
source ~/.bashrc4.修改 /usr/local/hive/conf 下的hive-site.xml
继续输入以下内容"
bash
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml
bash
cd /usr/local/hive/conf
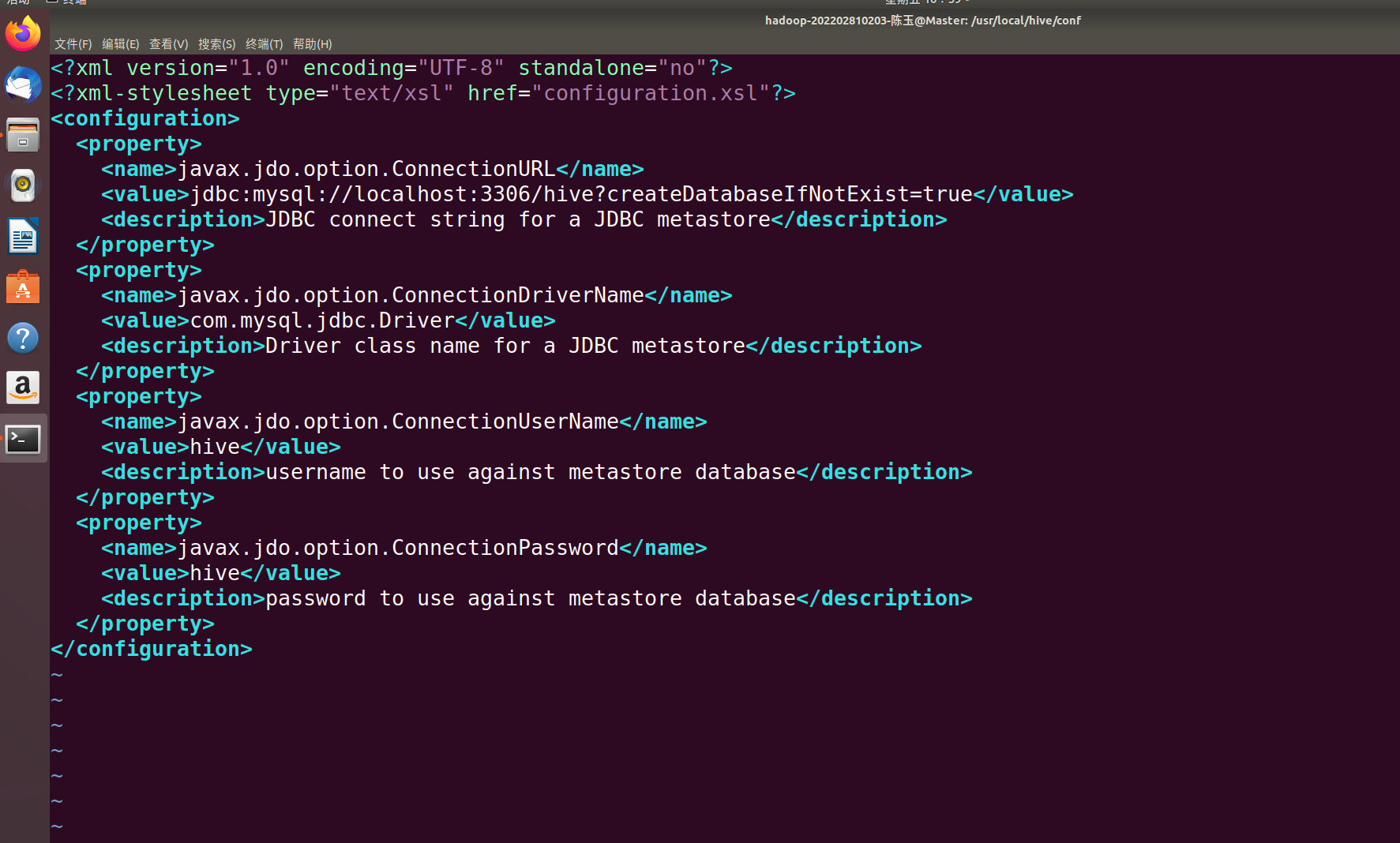
vim hive-site.xml在hive-site.xml中添加如下配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?useSSL=false&createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>
然后,按键盘上的"ESC"键退出vim编辑状态,再输入:wq,保存并退出vim编辑器。
第三步:安装并配置mysql
1.Ubuntu下mysql
在终端继续执行以下命令:
bash
cd ~
sudo apt update
sudo apt install mysql-server 按下Y回车
按下Y回车
安装完成后,启动mysql
bash
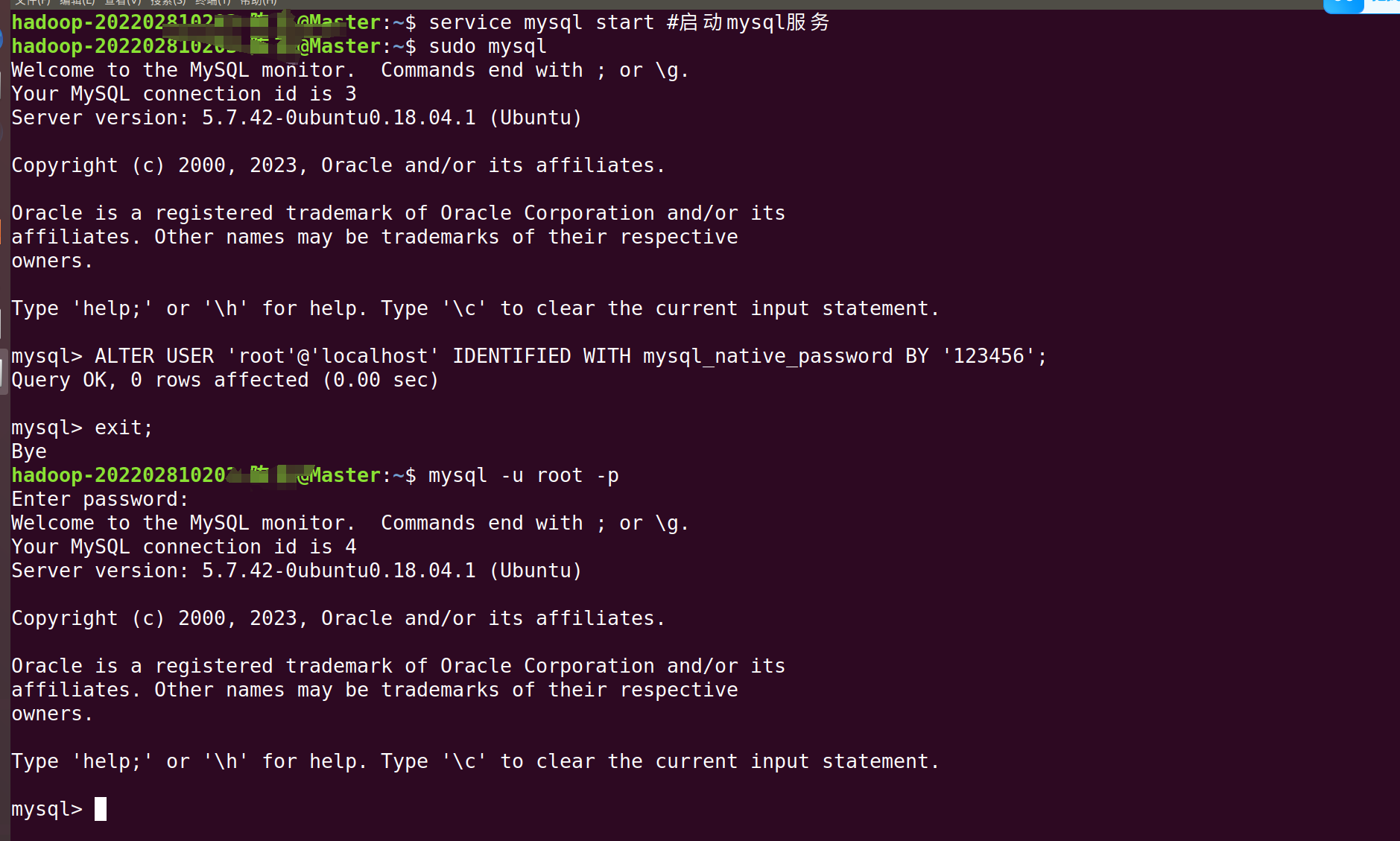
sudo systemctl start mysql为了方便之后的登录,我们先修改 MySQL 的 root 用户认证方式
1. 用 sudo 登录 MySQL:
bash
sudo mysql2. 修改 root 用户的验证方式为 mysql_native_password:
bash
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';4. 现在再用密码登录试试:(密码是我们刚刚设置的123456)
bash
mysql -u root -p然后输入你的密码123456。
 5.mysql jdbc 包
5.mysql jdbc 包
输入exit退出mysql
bash
exit;我们继续在终端输入以下命令(注意中文版是下载,英文版是DownLoads)
bash
cd ~/下载
tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib #将mysql-connector-java-5.1.40-bin.jar拷贝到/usr/local/hive/lib目录下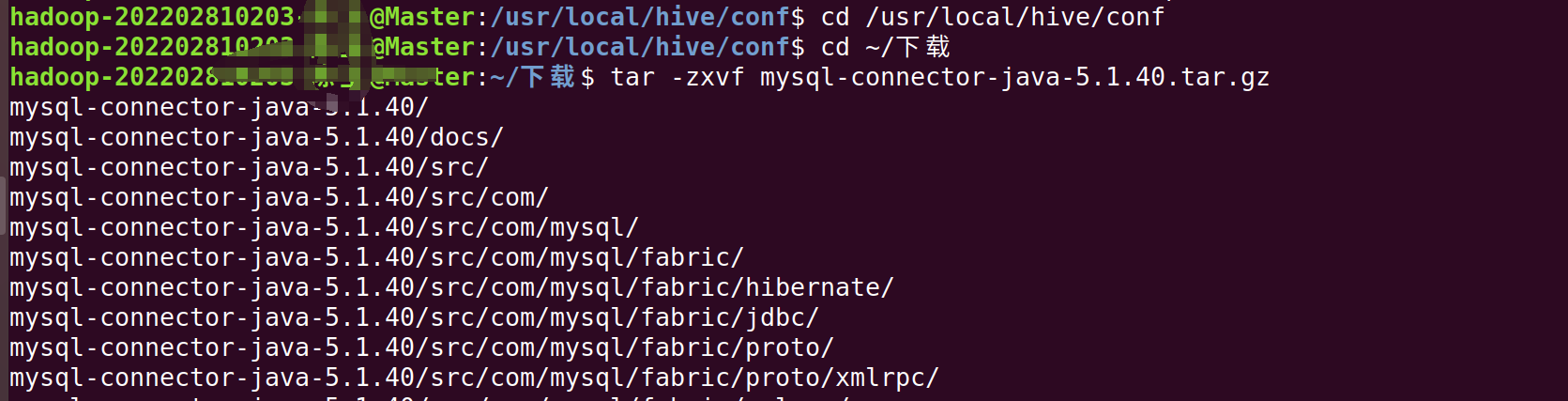
6.新建hive数据库 。
bash
mysql -u root -p 输入密码123456登录到mysql输入下面的命令
bash
create database hive; #这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据7.配置mysql允许hive接入:
继续在mysql输入以下内容:
bash
grant all on *.* to hive@localhost identified by 'hive'; #将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
bash
flush privileges; #刷新mysql系统权限关系表这里忘了截屏了,应该不会出错 ,然后记得Exit
8.启动hive
启动hive之前,请先启动hadoop集群。
1.进去Master终端,(右键-》打开终端),启动,并用jps检查是否成功启动
bash
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver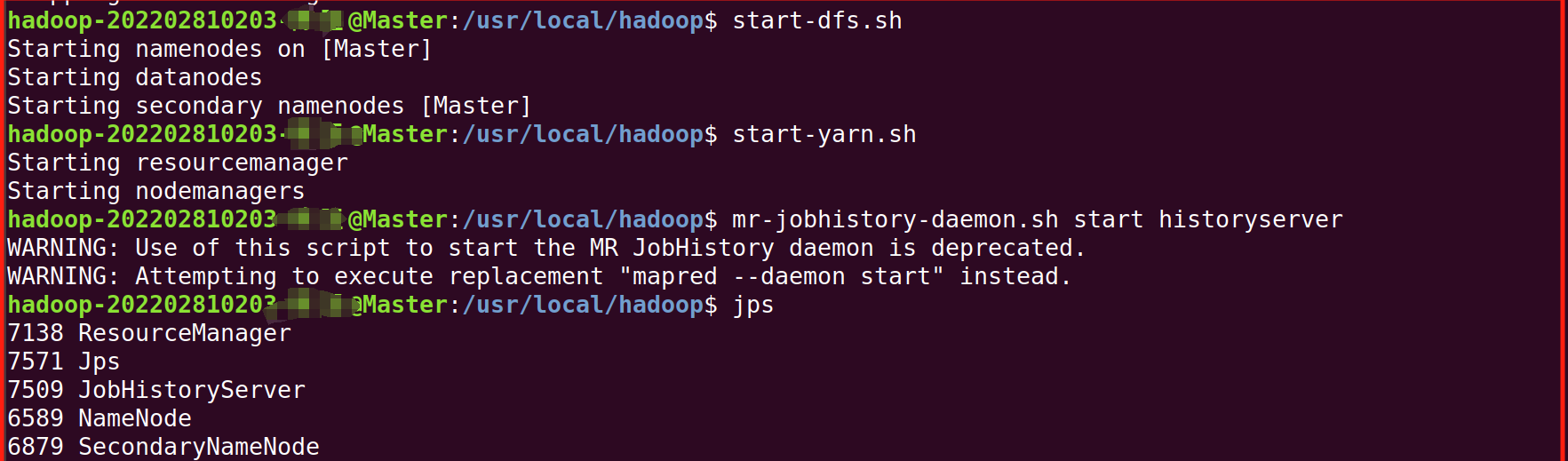
我们再启动是会报错,为了避免报错,我们进行如下操作
2. 在终端继续输入以下命令:
bash
find /usr/local/hive/ -name "guava*.jar"
find /usr/local/hadoop/ -name "guava*.jar"如果两个一样,你可以跳过这一步。 不一样就执行以下命令:(注意下面的版本号用自己的)
bash
rm /usr/local/hive/lib/guava-19.0.jar
bash
cp /usr/local/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /usr/local/hive/lib/3.在终端继续输入以下命令:
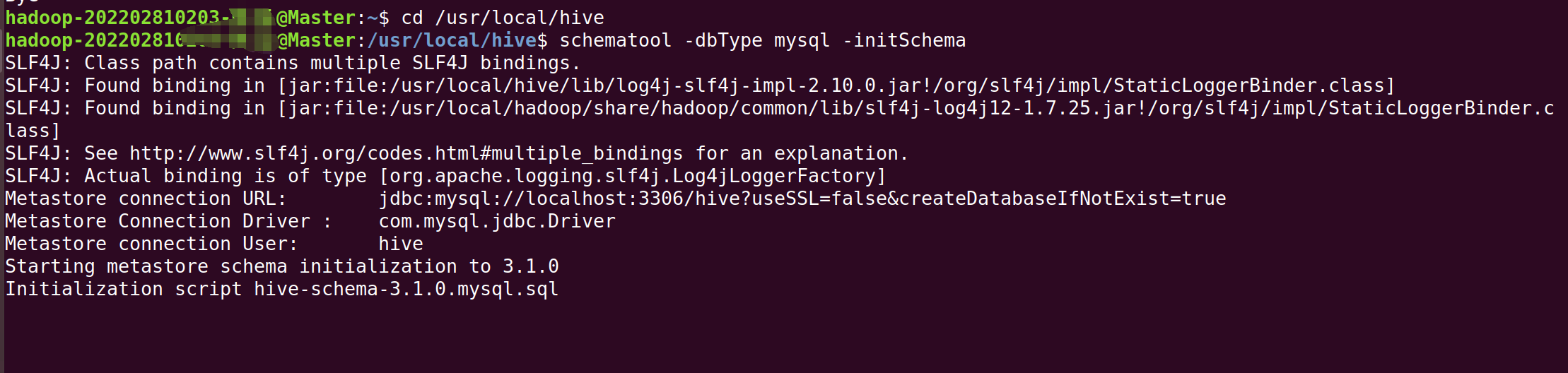
bash
cd /usr/local/hive
bash
schematool -dbType mysql -initSchema4.启动,在终端输入
bash
hive #启动hive启动进入Hive的交互式执行环境以后,会出现如下命令提示符:
bash
hive>第四步:Hive的常用HiveQL操作
这一个我单独成一章,大家可以在我的专栏里看到。我这里直接进行下一步。
第五步:Hive简单编程实践
退出上面的hive,(输入exit)在终端继续输入下面的命令
1. 1)创建input目录,output目录会自动生成。其中input为输入目录,output目录为输出目录。命令如下:
bash
cd /usr/local/hadoop
mkdir input2)然后,在input文件夹中创建两个测试文件file1.txt和file2.txt,命令如下:
bash
cd /usr/local/hadoop/input
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt为了后续区分,我们之前有好多文件都弄到一个目录里了,这里我们新创建 HDFS 目标目录
创建 HDFS 目标目录(如果未创建)
bash
hdfs dfs -mkdir -p /user/hadoop/input2
将本地文件上传到 HDFS
bash
hadoop fs -put /usr/local/hadoop/input/file1.txt /user/hadoop/input2/
hadoop fs -put /usr/local/hadoop/input/file2.txt /user/hadoop/input2/3)执行如下hadoop命令:
bash
cd ..
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/hadoop/input2 /user/hadoop/output2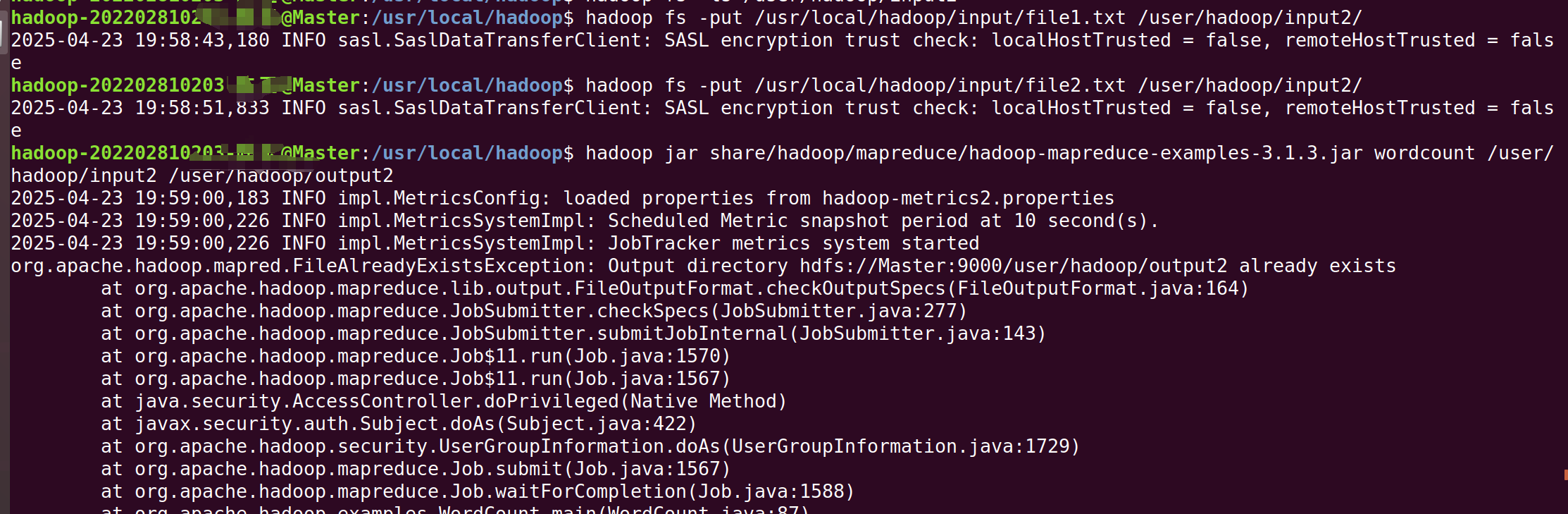
bash
./bin/hdfs dfs -cat /user/hadoop/output2/*
下面我们通过HiveQL实现词频统计功能,此时只要编写下面7行代码,而且不需要进行编译生成jar来执行。HiveQL实现命令如下:
我们先进入hive,直接启动
在终端输入
bash
hive1. 创建表 docs
首先创建一个表 docs,它将存储每一行文本
bash
create table docs(line string);2. 将文件数据加载到表中
然后,使用 LOAD DATA 命令将本地文件系统中的数据加载到 docs 表中。这里的路径 'file:///usr/local/hadoop/input' 是文件存放路径。
bash
load data inpath 'file:///usr/local/hadoop/input' overwrite into table docs;3. 创建表 word_count 并统计词频
在创建表 word_count 时,HiveQL 查询会:
-
使用
explode和split函数将每行文本按空格分割为单词,并将其作为word列。 -
对每个单词进行计数,并按字母顺序排序。
bash
create table word_count as select word, count(1) as count from (select explode(split(line, ' ')) as word from docs) w group by word order by word;详细步骤解释:
-
split(line, ' '):使用split函数将line列的每一行文本按空格切割成单词。 -
explode():explode将每个文本行拆分成多个单词,每个单词成为一行数据。 -
group by word:按word列分组,并使用count(1)来计算每个单词的出现次数。 -
order by word:按字母顺序对单词进行排序.
继续在终端输入:
bash
select * from word_count;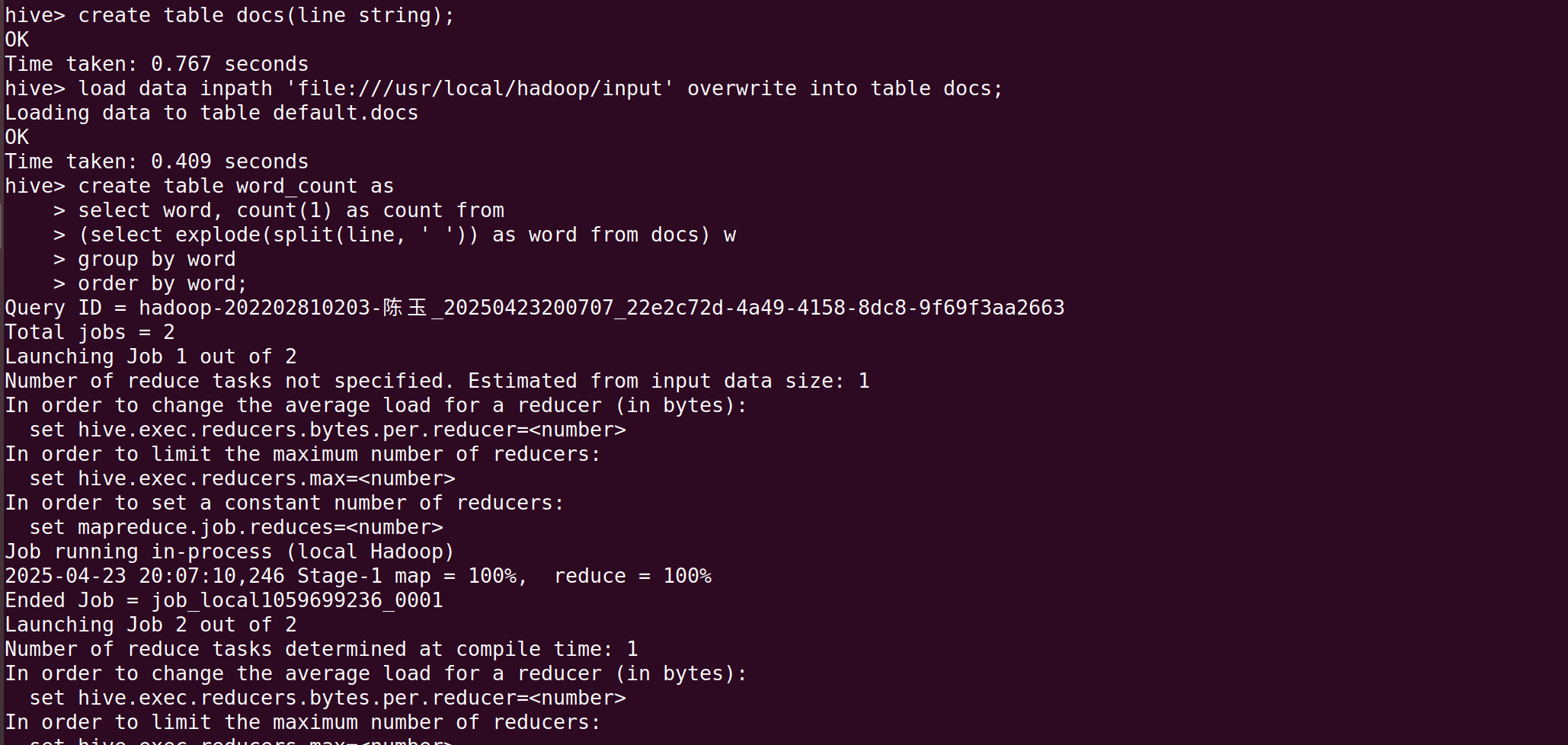
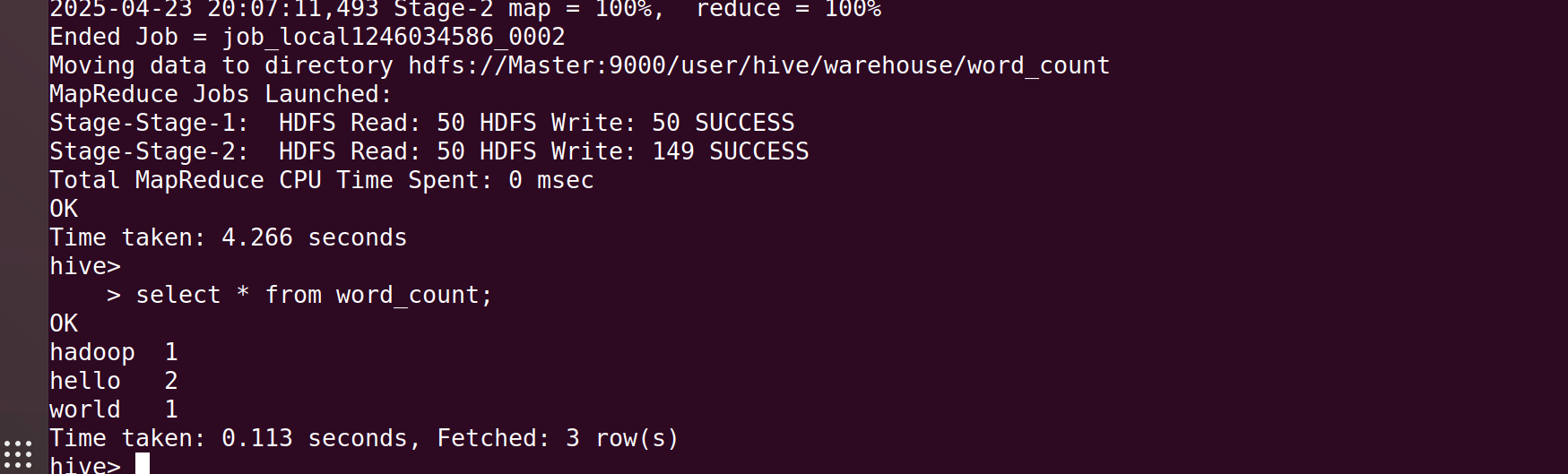
出现如上界面即为成功。