摘要
本酷狗音乐爬虫大数据分析可视化系统采用B/S架构,数据库是MySQL,网站的搭建与开发采用了先进的Java语言、Hadoop、爬虫技术进行编写,使用了Spring Boot框架。该系统从两个对象:由管理员和用户来对系统进行设计构建。前台主要功能包括:用户注册、登录、浏览音乐信息、进行个人中心管理等,并进行在线听音乐等操作。本系统在一般音乐推荐网站的基础上增加了爬虫技术和可视化技术,让管理员可以快速获取音乐信息,非常方便。 本系统采用的数据库是MySQL,使用Java、Hadoop、爬虫技术技术开发。在设计过程中,很好地发挥了该开发方式的优势,让实现代码有了良好的可读性,而且使代码的更新和维护更加的方便,操作方便,对以后的维护减少了很多麻烦。系统的顺利开发和实现,对于酷狗音乐爬虫大数据分析可视化管理这一方面提供巨大的便利服务,无论是用户还是管理员,都带来了极大的便利,方便大众,为社会的进步与发展提供了一些动力。
绪论
1.1背景及意义 随着社会的快速发展,计算机的影响是全面且深入的。目前,社会的各种类型的网站越来越多,但是有些类型的网站附加了太多的商业元素和虚假信息,而且,用户在搜索相关信息时需访问多个网站和大量垃圾广告,这无疑影响了信息搜索效率且降低了用户的使用体验,使用户很难快速地浏览或查询到自己所需要的相关信息。电子计算机在现代管理中的应用使电子、计算机变成了人类运用现代信息技术的主要工具。可以更高效的处理人类获取信息中精细化、全面化的问题,从而提高了效率2。本系统使用具有独特且和资源相对优势的管理方式,来提供一个优秀的酷狗音乐爬虫大数据分析可视化系统,用户可以在网站浏览音乐信息,进行音乐试听等操作。而随着互联网的应用,互联网也以一种巨大变革力的新形象出现于商务关系领域。 探究根本课题,就是希望能够实现用户和所需信息双方的双向选择,便于用户查找相应信息的同时也可以节省管理员在管理中花费的人力和物力。
1.2 国内外研究概况 在当前飞速发展的时代,无论是国内还是国外,发展都是突飞猛进的,经济形势也是一片明朗。在这种背景下,互联网的这一块的市场成为了各个国家想要争夺的香饽饽。于是无论是国内还是国外一些公司把目光投向了互联网这块市场,越来越多的人对互联网有所了解,具备了一些网络意识。在这种互联网大浪潮的不断冲刷下,各种各样的系统被开发出来。计算机技术无论是在国内还是国外中应用普遍,使计算机这一新型工具成为人们耳熟能详、妇孺皆知的新技术。计算机和互联网的广泛应用,让国内外的距离变"近"了,这个庞大的地球家园一下变成了地球村。国内国外的互联网发展也存在一些差距,我国近些年的互联网发展迅速,跻身于世界前列。 本系统采用B/S架构、采用的数据库是MySQL,使用Java技术开发。该系统的开发方式无论在国内还是国外都比较常见,而且开发完成后使用普遍,可以给用户提供大量的便利3。该系统在国内外前景较为良好。
1.3 研究的内容 酷狗音乐爬虫大数据分析可视化系统是一个便于用户浏览音乐信息而进行管理的平台。因此本文主要阐述了系统实现的功能和完整开发的过程,结合Web开发技术实现了一个酷狗音乐爬虫大数据分析可视化系统。本系统以软件工程理论作为开发的理论基础,4以专业的计算机编程语言实现系统的功能与开发。 该选题原则上力求采用标签模块分类等方法,来完成注册、登录、对音乐信息管理、用户管理、对页面的设置和对后台数据库中数据的增删查改等一系列的操作和运行等。在这一系列模块分类的功能下,达到对酷狗音乐爬虫大数据分析可视化系统信息的高效执行和规范管理。
相关技术
2.1 Java简介 Java主要使用了CORBA技术和安全模型,主要是在网络使用的信息保障上。它还带来了对EJB(Enterprise Java Beans)的完全支援6,Java SERVLET API,JSP(Java Server Pages),还有XML技术等多进步。因此,当在打开蜘蛛纸牌休闲一下玩游戏时,还可以打开一个音乐播放器来播放自己想要听的歌,于是,既可以一遍玩蜘蛛纸牌放松,也可以挑选播放自己想要听的歌,两者来回切换,两者同时进行无需等待。因为似乎他们都在自己的主机上一起为自己工作。但事实是,对于某个CPU来说,它只是在特定时点进行了某个程序。CPU在这些程序中间,不断地"跳跃"。而为何人们却看不到什么破坏呢?这是因为,和人的感应一样,它的速度太快了。所以,即使人们发现一些同步操作,其实对电脑而言,也只是在特定时点运行了某个进程,除非的电脑是多CPU的。
2.2 Spring Boot框架 现如今后台开源框架主流的有SSH、SSM、Spring Boot,但是SSH、SSM框架的环境配置项较多,而Spring Boot主要的设计思想就是约定大于配置,故而SpingBoot在设计时几乎达到零配置。Spring Boot整合了业界上的开源框架。具体采用技术框架描述如下: (1)Mybatis:Mybatis:提供自动映射,动态SQL,级联,缓存,注解,代码和SQL分离等特性,使用方便,同时也对SQL进行优化10。 (2)SpringMVC:通过一套MVC注解,让POJO成为处理请求的控制器,无需实现任何接口,同时,SpringMVC还支持REST风格的URL请求11。 (3)Spring Boot:从本质上来说,Spring Boot就是Spring,它做了那些没有它你也会去做的Spring Bean配置12。 Spring Boot是一款非常强大后台框架,因为Spring Boot开发时可以基本不用写配置文件,所以使用Spring Boot搭建网站的后台环境,在Spring Boot的yml配置文件中写入项目启动端口,项目就可以启动。项目的Java文件还有静态文件都是由Spring Boot来管理。
2.3 Idea开发环境 IDEA 全称IntelliJ IDEA,是用于java语言开发的集成环境(也可用于其他语言),IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、 创新的GUI设计等方面的功能可以说是超常的8。 2.4 Hadoop技术 1. Hadoop Common:Hadoop体系最底层的模块(基础模块),为Hadoop各子项目提供系统配置工具Configuration、远程过程调用RPC、序列化机制和日志操作等。 2. HDFS:Hadoop Distributed File System是具有高度容错性的文件系统,适合部署在廉价机器上。HDFS提供高吞吐量的数据访问,非常适合大规模数据集上的应用。 3. YARN:Yet Another Resource Negotiator是统一资源管理和调度平台,解决了上一代Hadoop资源利用率低和不兼容异构计算框架等多种问题,提供资源隔离方案和双调度器的实现。 4. MapReduce:一种编程模型,利用函数式编程思想,将数据集处理过程分为Map和Reduce两个阶段,非常适合进行分布式计算。支持Java、C++、Python、PHP等多种语言。
2.5 MySQL数据库 MySQL是一种关系型的数据库管理系统,属于Oracle旗下的产品。MySQL的语言是非结构化的,使用的用户可以在数据上进行工作。这个数据库管理系统一经问世就受到了社会的广泛关注。在各个方面,与同等的数据库相比,MySQL的优点极为突出,它的运行速度快,适用的范围广泛,而且数据库的安全性这一方面独树一帜。在语言a结构方面,MySQL的语言简单,其他数据库需要一大段代码来实现的操作,MySQL仅需要一小部分代码甚至几行。综上所述,MySQL这种关系型数据库管理系统,已经成为了开发者进行项目的数据开发、存储的不二之选。MySQL的功能也多种多样,如数据操纵和数据库的建立维护等。而且该数据库的数据共享性高、冗余度低而且容易扩充。MySQL在安全性这一方面也具有自身的特点,它应用了用户的标识和鉴别技术,对试图和数据进行加密,确保资料信息的可靠性。介于数据库系统的功能与强大等性质之间,本数据库系统的设计中主要使用了MySQL实现对数据的处理。基于Web的酷狗音乐爬虫大数据分析可视化系统运用MySQL数据库,在Web应用这一块,MySQL是最好的选择。对于该系统整个的开发、搭建、运行和维护具有极其重要的作用9。
2.6 网络爬虫简介 网络爬虫是一种很好的自动采集数据的通用手段。它主要分为4种类型,分别是:聚焦网络爬虫、增量抓取、表层网页、深层网页。 ①聚焦网络爬虫是"面向特定主题需求"的一种爬虫程序,而通用网络爬虫则是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分,主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 ②增量抓取意即针对某个站点的数据进行抓取,当网站的新增数据或者该站点的数据发生变化后,自动地抓取它新增的或者变化后的数据。 Web页面按存在方式可以分为表层网页(surface Web)和深层网页(deep Web,也称invisible Web pages或hidden Web)。 ③表层网页是指传统搜索引擎可以索引的页面,即以超链接可以到达的静态网页为主来构成的Web页面。 ④深层网页是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的Web页面。 本次使用的爬虫技术是聚焦网络爬虫,通过搜索引擎,抓取相关音乐信息,下载到本地,形成互联网内容的镜像备份,提供用户浏览、查看。
系统整体功能图
用户注册界面图
用户登录界面图
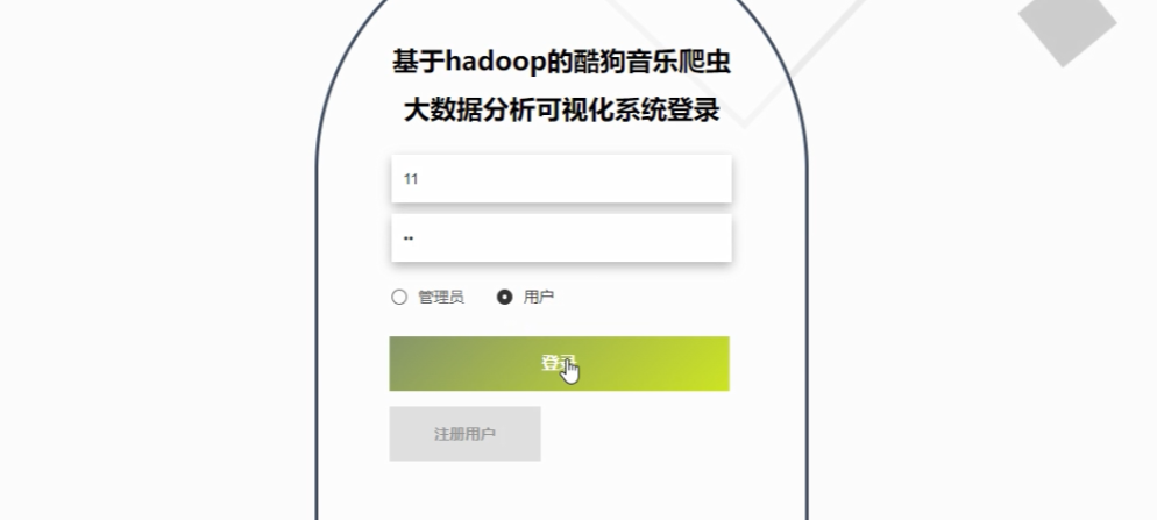
用户功能界面图
管理员登录界面图
管理员功能界面图
部分数据库表
|---------------|-----------|------------|------|----|-------------------|
| 字段名称 | 类型 | 长度 | 字段说明 | 主键 | 默认值 |
| id | bigint | | 主键 | 主键 | |
| addtime | timestamp | | 创建时间 | | CURRENT_TIMESTAMP |
| laiyuan | varchar | 200 | 来源 | | |
| yinyueming | varchar | 200 | 音乐名 | | |
| fengmian | longtext | 4294967295 | 封面 | | |
| chuzi | varchar | 200 | 出自 | | |
| shoucangliang | varchar | 200 | 收藏量 | | |
| fenxiangliang | varchar | 200 | 分享量 | | |
| pinglunshu | int | | 评论数 | | |
| biaoqian | varchar | 200 | 标签 | | |
| detail | longtext | 4294967295 | 介绍 | | |
|----------------|-----------|------------|------|----|-------------------|
| 字段名称 | 类型 | 长度 | 字段说明 | 主键 | 默认值 |
| id | bigint | | 主键 | 主键 | |
| addtime | timestamp | | 创建时间 | | CURRENT_TIMESTAMP |
| yonghuzhanghao | varchar | 200 | 用户账号 | | |
| mima | varchar | 200 | 密码 | | |
| yonghuxingming | varchar | 200 | 用户姓名 | | |
| xingbie | varchar | 200 | 性别 | | |
| lianxifangshi | varchar | 200 | 联系方式 | | |
| touxiang | longtext | 4294967295 | 头像 | | |
结论
经过这几个月的努力,在老师和同学的帮助与指导下,对系统顺利完成。对于该系统的研究和开发虽然没有耗费大量的时间,但为了成功完成该酷狗音乐爬虫大数据分析可视化系统,消耗了大量的精力和汗水去了解学习这方面涉及到的专业知识以及开发环境的应用。 该系统的设计与实现,是经过了很长时间的分析、观察、调研和研究分析并整理资料实施的。酷狗音乐爬虫大数据分析可视化系统采用B/S架构、Java开发语言、爬虫、Hadoop技术、Spring Boot框架以及MySQL数据库等技术开发与设计。该系统主要分为用户和管理员个角色。该酷狗音乐爬虫大数据分析可视化系统分为管理员和用户两大部分。用户主要功能是浏览音乐信息,进行音乐试听、管理个人信息和登录密码等。后端的主要任务是对数据的一些准备处理的工作,对于用户和管理员两者的数据属性的添加、维护和修改。每个功能在完成各自任务的同时也相互合作,一起来处理各个任务以及进程。 尽管该系统对用户可以满足一些基本的酷狗音乐爬虫大数据分析可视化系统的需求,但该系统还存在寻多问题和有待完善的地方。主要分为以下两点:
(1)该音乐推荐系统的适用面比较局限。页面的设置还是过于繁琐,不够简洁。加上社会方面的飞速发展,用户的条件也在发生新的变化。该系统还存在大数据下的并发和并行操作的不稳定性,当一个时间段内或者同一时刻时,过量的用户访问该网站会让网站的服务器出现崩溃的现象,一些操作无法正常的运行。种种原因使得该系统存在一些局限性。 (2)需要人工来处理的数据模块太多,需要减少大量的人工操作。在对音乐推荐系统信息处理的程序中,难免会出现各种各样的错误数据或者是异常数据,一旦这些数据大量积累存在过多时,系统自我调节修复能力有限就不得不需要人工的干预了。但是人工如果经常去进行操作的话,就会造成该系统的运行速度变慢,对其余正确的数据产生干扰,而且有可能对正确数据的损害以及泄露,从而将会减少该系统的稳定性。对于人力和财力都造成了不必要的浪费。 从上述可以看出该音乐推荐系统还有很多不足之处,在日后要结合具体项目问题进行修改和研究。