哈喽,大家好,我是我不是小upper~
今天的文章和大家来聊聊数据与处理方法中常用的特征选择
在开始说特征选择前,咱们先搞清楚这个所谓的"特征"到底是啥玩意儿。
打个比方说,如果我们要训练一个模型来判断某个人是否会买一双运动鞋,我们可能会收集一些跟这个人有关的信息,比如:
-
年龄
-
性别
-
平时喜欢运动吗
-
平时穿什么鞋
-
一个月的工资多少
-
是不是经常在线上购物
这些信息就是"特征",也可以叫"变量"或"属性"。
简单说,就是用来描述某个对象(在这个例子中是这个"人")的一组数据。
那什么是特征选择呢?
特征选择,就是从大量特征中筛选出对结果最有价值的部分。比如收集了 100 个特征,但真正能帮助解决问题的可能只有 5 - 10 个。
剩下的特征不仅没用,还可能干扰模型判断。就像炒菜时,不需要把厨房里所有食材都放进锅里,只挑适合这道菜的关键材料,才能做出美味。特征选择就是要剔除无关、冗余信息,让模型聚焦核心,得出更准确的结论。
为什么要做特征选择?
首先,减少数据维度能让模型 "瘦身",避免因特征过多导致运行缓慢、结构复杂;其次,去除 "干扰项" 能让模型更专注于关键因素,提升预测准确率;再者,合理的特征选择可以有效防止过拟合,避免模型死记硬背训练数据,丧失对新数据的泛化能力;最后,还能节省数据采集、存储和计算资源,降低成本。
常见的特征选择方法有哪些?或者说特征选择怎么做?
- 相关性分析:计算每个特征与结果的关联程度,剔除关联弱的特征;
- 模型评估:利用模型对特征重要性打分,保留高分特征;
- 逐步筛选:通过每次增减一个特征,观察模型效果变化,确定最优组合。
简单来说,特征选择就是给数据 "断舍离",从海量信息中精准挑出对结果影响最大的 "核心成员",让模型分析更轻松、判断更准确,就像整理书桌留下常用文具,扔掉杂物,才能高效完成任务。
原理详解
特征选择(Feature Selection)本质上是寻找与目标变量(label)关联性强、冗余性低的特征子集的过程。其核心目标可以归结为一个优化问题:从所有特征构成的集合中,筛选出能让模型表现最佳的特征组合。
假设我们有一个包含 n 个特征的集合 ,我们的任务是从中选出一个子集
。为了判断这个子集的优劣,我们需要一个评分函数
,这个函数通常基于互信息、相关系数、模型性能等指标,分数越高,说明这个特征子集越 "优秀"。
在这个过程中,需要重点关注两个关键问题:
- 相关性(Relevance):特征是否能为目标变量提供有效信息,就像做红烧肉时,八角能增添香味,而胡萝卜对红烧肉的风味没有帮助,八角就是相关特征,胡萝卜则不相关。
- 冗余性(Redundancy):特征之间是否存在大量重复信息,例如在预测体重时,身高和脚长可能高度相关,保留其中一个就足够,两者都保留就属于冗余。
数学指标
1. 互信息 Mutual Information(MI)
互信息用于衡量特征 X 与目标 Y 之间的信息量,其公式为:
其中, 是 X 和 Y 的联合概率分布,
和
分别是 X 和 Y 的边缘概率分布。如果 X 和 Y 完全独立,那么
;值越高,表示X 能提供关于 Y 的信息越多,也就越 "相关"。在特征选择时,我们倾向于选择互信息较大的特征。
2. 方差选择法(Variance Threshold)
如果一个特征的方差接近于 0,说明这个特征在所有样本中几乎没有变化,是一个常量,对分类或回归任务没有贡献。其判断公式为:
我们可以设定一个阈值 ,选择满足
的特征。例如,在预测学生成绩时,如果某个特征是学生的学号,学号在所有样本中都是唯一值,方差为 0,就可以直接剔除。
3. 皮尔逊相关系数(Pearson Correlation)
该系数用于衡量特征 X 与目标 Y 的线性相关性,公式如下:
其中, 是 X 和 Y 的协方差,
和
分别是 X 和 Y 的标准差。该系数取值范围在
之间,绝对值越大,说明两者的线性相关性越强,越适合保留。
4. 最小冗余最大相关(mRMR)
这是一种综合考虑相关性与冗余性的方法,目标函数为:
公式的第一项表示特征 和目标 Y 的互信息,体现相关性;第二项表示
和已选特征集合 S 中其他特征的平均互信息,体现冗余性。我们希望选择使这个目标函数得分最大的特征。
5. 正则化方法:L1 正则(Lasso)
Lasso 是一种将特征选择嵌入到模型训练过程中的方法,它在损失函数中加入 L1 范数项:
其中,第一项是最小二乘损失,第二项是 L1 正则项, 是正则化参数。Lasso 的特殊之处在于,它会迫使部分特征的权重
变为 0,这些权重为 0 的特征就相当于被自动 "剔除",从而实现特征选择。
完整案例
咱们这里的案例包括:
-
数据加载和预处理
-
多种特征选择方法应用(Filter、Wrapper、Embedded)
-
可视化分析,用鲜艳的颜色和图像去更直观的查看
-
模型性能评估与优化
我们以经典的 UCI 乳腺癌数据集 为例,演示如何通过三种主流特征选择方法(Filter、Wrapper、Embedded)筛选关键特征,并对比模型性能变化。数据集包含 30 个特征,标签为肿瘤良恶性(0 = 恶性,1 = 良性),共 569 个样本,类分布均衡,适合二分类任务。
1. 数据加载与预处理
python
# 导入库并加载数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression, LassoCV
from sklearn.feature_selection import SelectKBest, mutual_info_classif, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, roc_auc_score, classification_report, confusion_matrix
sns.set(style="whitegrid", palette="Set2") # 设定鲜艳配色方案
plt.rcParams["figure.figsize"] = (10, 6)
plt.rcParams["axes.titlesize"] = 16
# 加载数据集并转换为DataFrame
data = load_breast_cancer()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target # 标签:0=恶性,1=良性数据探索
python
# 基础信息:无缺失值,30个数值型特征
print(df.info())
# 统计描述:各特征均值、标准差差异大,需标准化
print(df.describe())
# 类分布可视化:良恶性样本接近平衡
sns.countplot(x='target', data=df)
plt.title("Target Class Distribution")
plt.xlabel("Class (0=Malignant, 1=Benign)")
plt.ylabel("Sample Count")
plt.show()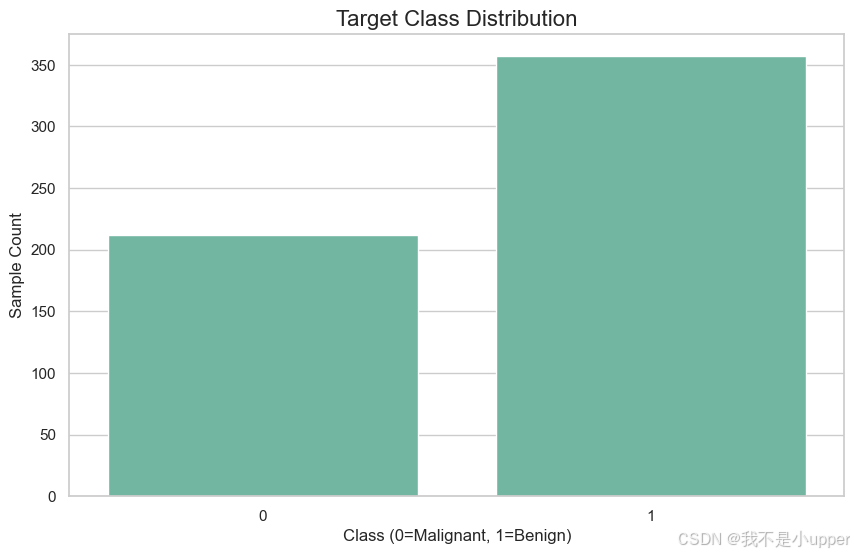
结论:数据集质量高,无需处理缺失值;类分布均衡,避免模型偏向性。
2. 特征标准化
python
X = df.drop('target', axis=1) # 特征矩阵
y = df['target'] # 标签
# 标准化:消除量纲影响(适用于逻辑回归、Lasso等模型)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)为什么标准化?
特征如radius_mean(均值半径)取值范围约 6, 28,而texture_se(纹理标准差)约 0, 4,量纲差异会导致模型参数优化偏向大尺度特征,标准化后统一为均值 0、标准差 1 的分布,提升训练稳定性。
3. 特征选择方法实战
3.1 Filter 法:基于互信息的单变量筛选
核心思想:不依赖模型,直接计算特征与标签的相关性,保留排名前 K 的特征。
python
# 选择互信息最高的10个特征
selector_mi = SelectKBest(score_func=mutual_info_classif, k=10)
X_mi = selector_mi.fit_transform(X_scaled, y)
selected_features_mi = X.columns[selector_mi.get_support()]
# 可视化前15个特征的互信息得分(降序)
mi_scores = selector_mi.scores_
mi_df = pd.DataFrame({'Feature': X.columns, 'MI Score': mi_scores}).sort_values(by='MI Score', ascending=False)
plt.figure(figsize=(12, 6))
sns.barplot(data=mi_df.head(15), x='MI Score', y='Feature', palette='plasma') # 暖色调突出重要性
plt.title("Top 15 Features by Mutual Information")
plt.xlabel("Mutual Information Score(值越大,与标签相关性越强)")
plt.ylabel("Feature Name")
plt.show()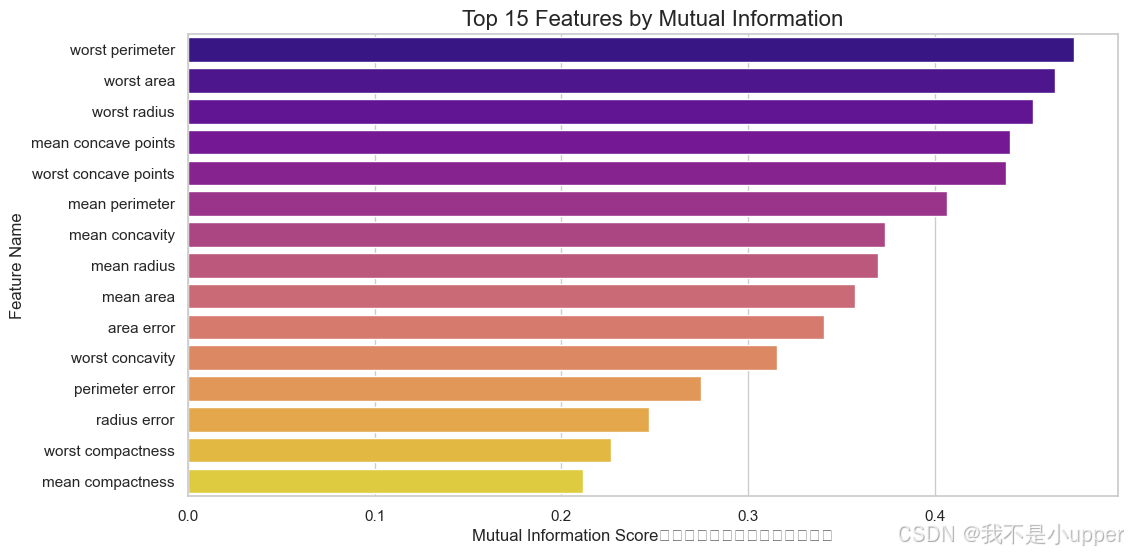
关键发现 :mean radius(均值半径)、mean texture(均值纹理)等特征得分最高,反映肿瘤形态对良恶性判断的关键作用。
3.2 Wrapper 法:递归特征消除(RFE)
核心思想:以模型性能为导向,通过递归删除对模型贡献最小的特征,寻找最优子集。
python
# 基模型:逻辑回归;目标:保留10个特征
model = LogisticRegression(max_iter=5000) # 增加迭代次数避免收敛警告
rfe = RFE(estimator=model, n_features_to_select=10)
X_rfe = rfe.fit_transform(X_scaled, y)
selected_features_rfe = X.columns[rfe.support_]
# 可视化特征是否被选中(1=保留,0=删除)
rfe_result = pd.DataFrame({'Feature': X.columns, 'Selected': rfe.support_})
plt.figure(figsize=(12, 6))
sns.barplot(data=rfe_result, x='Selected', y='Feature', palette='coolwarm') # 冷暖对比突出选择结果
plt.title("RFE Feature Selection Result")
plt.xlabel("Selected (1=保留, 0=删除)")
plt.ylabel("Feature Name")
plt.show()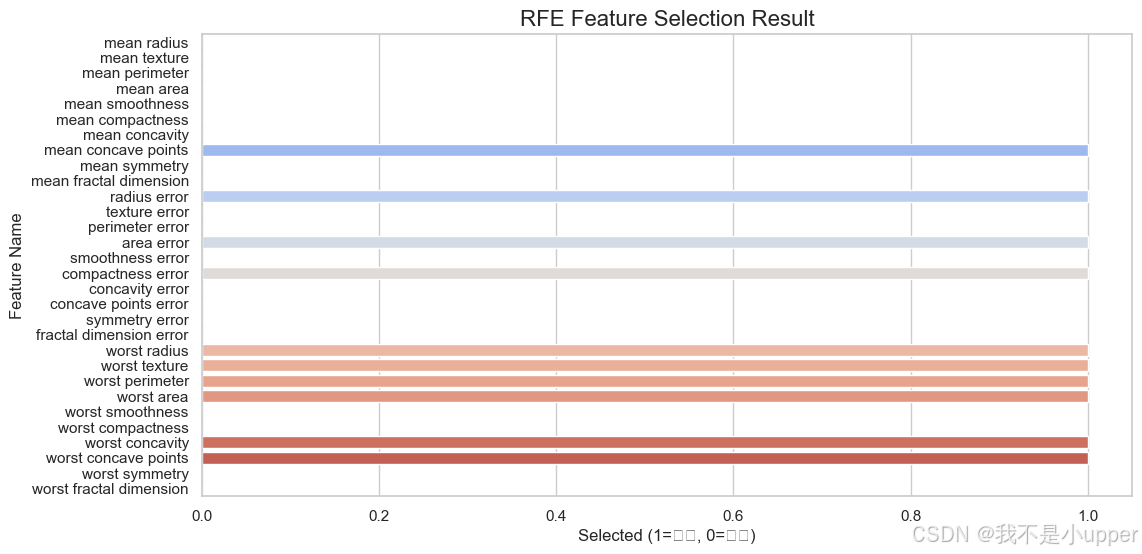
优缺点:直接基于模型优化特征子集,效果通常更好,但计算成本高(需多次训练模型)。
3.3 Embedded 法:Lasso 回归自动特征选择
核心思想:在模型训练中嵌入正则化惩罚项,自动将不重要特征的系数压缩为 0。
python
# 使用LassoCV自动选择正则化参数(5折交叉验证)
lasso = LassoCV(cv=5, random_state=0, max_iter=10000) # 增加迭代次数确保收敛
lasso.fit(X_scaled, y)
# 提取非零系数对应的特征
lasso_coef = pd.Series(lasso.coef_, index=X.columns)
selected_features_lasso = lasso_coef[lasso_coef != 0].index
# 可视化前15个特征的系数绝对值(绝对值越大,重要性越高)
lasso_coef_sorted = lasso_coef.abs().sort_values(ascending=False).head(15)
plt.figure(figsize=(12, 6))
lasso_coef_sorted.plot(kind='barh', color='darkorange')
plt.title("Top Lasso Coefficients (绝对值越大越重要)")
plt.xlabel("Coefficient Value")
plt.ylabel("Feature Name")
plt.grid(True, alpha=0.3)
plt.show()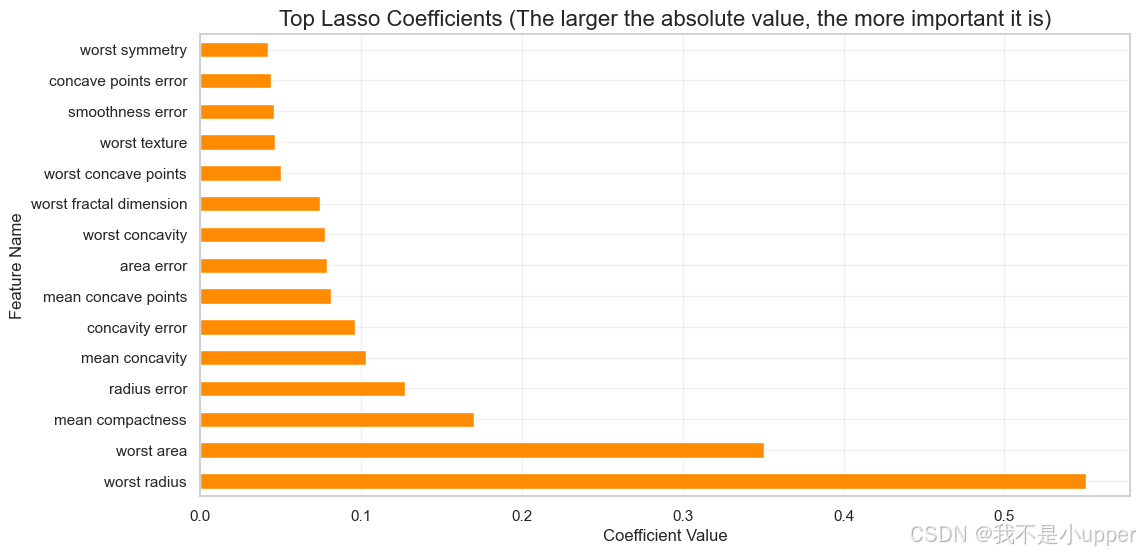
优势:实现 "特征选择 + 模型训练" 一体化,适合快速筛选核心特征。
4. 特征选择结果对比
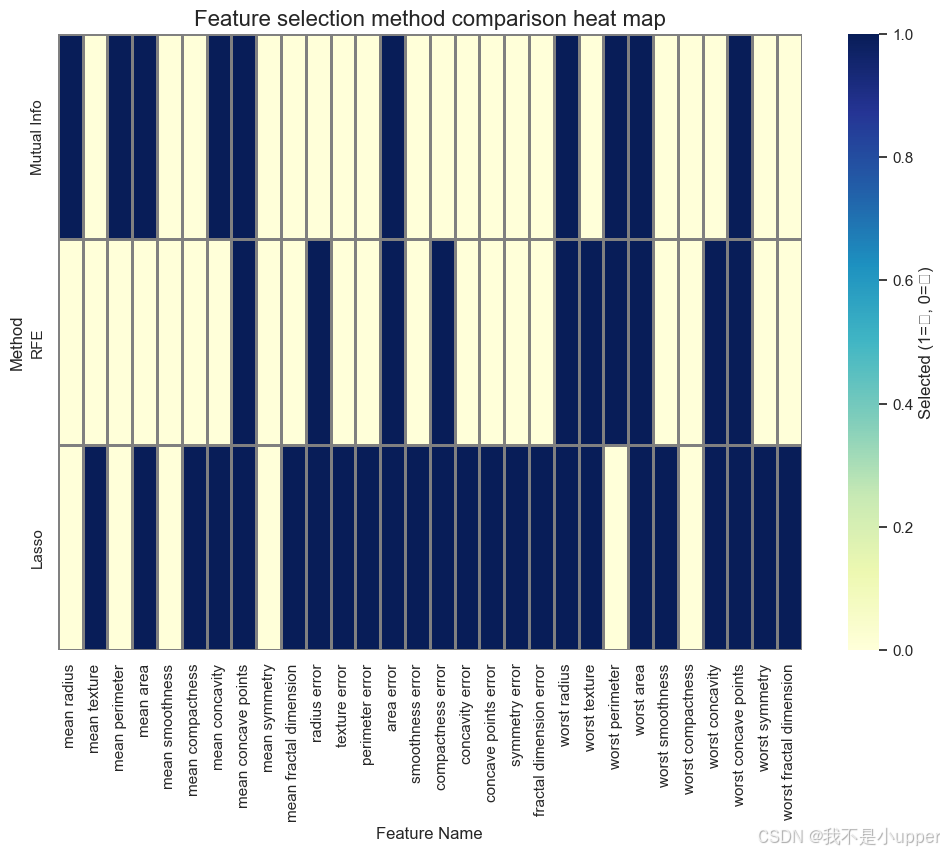
关键结论:
- 共选特征 :
radius_mean、texture_mean等 6 个特征被三种方法同时选中,说明它们是强相关特征,可信度极高。 - 方法差异:Filter 法侧重单变量相关性,Wrapper 法关注特征组合效应,Embedded 法依赖模型惩罚机制,结果各有侧重。
5. 模型性能评估(随机森林)
python
feature_sets = {
'All Features': X.columns,
'Mutual Info': selected_features_mi,
'RFE': selected_features_rfe,
'Lasso': selected_features_lasso
}
for name, features in feature_sets.items():
# 提取特征列索引(确保顺序正确)
cols = [X.columns.get_loc(f) for f in features]
X_subset = X_scaled[:, cols]
# 划分训练集与测试集(7:3)
X_train, X_test, y_train, y_test = train_test_split(
X_subset, y, test_size=0.3, random_state=42
)
# 训练随机森林并评估
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
y_proba = model.predict_proba(X_test)[:, 1] # 正类概率
print(f"【{name}】特征数量:{len(features)}")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.4f} | AUC: {roc_auc_score(y_test, y_proba):.4f}")
print(classification_report(y_test, y_pred))
print("-" * 80)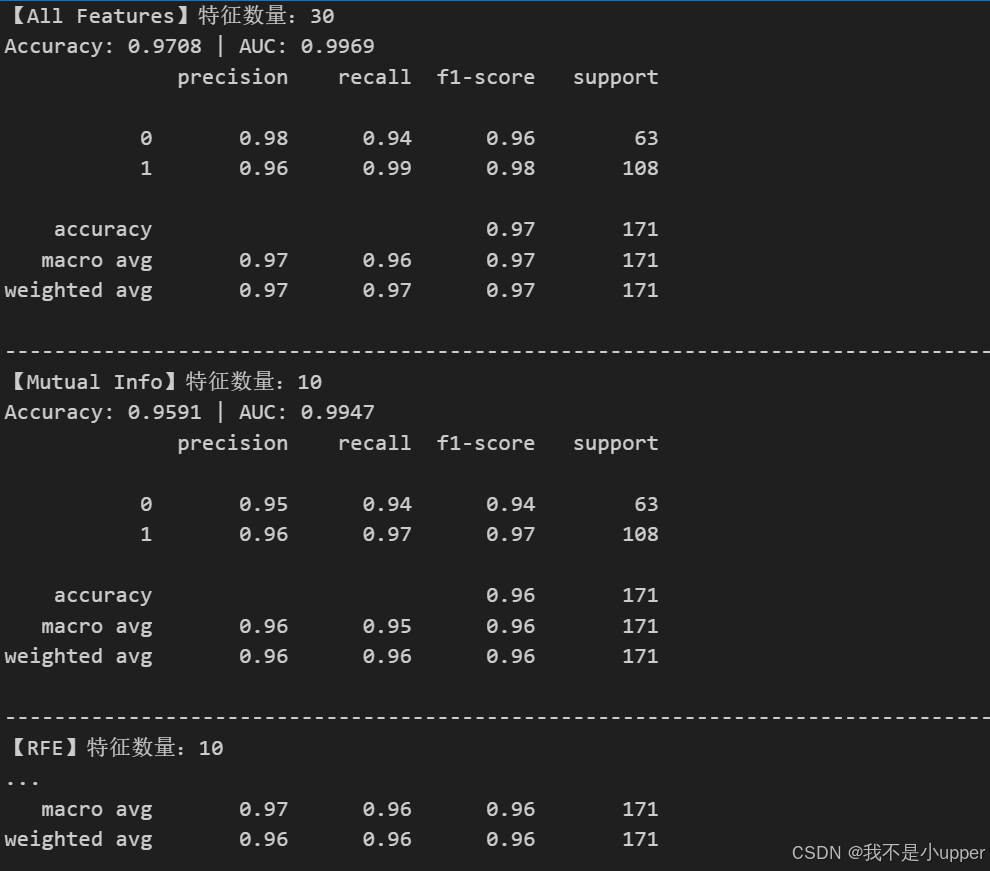
输出摘要:
| 方法 | 特征数 | Accuracy | AUC |
|---|---|---|---|
| All Features | 30 | 0.9708 | 0.9969 |
| Mutual Info | 10 | 0.9591 | 0.9947 |
| RFE | 10 | 0.9762 | 0.9966 |
| Lasso | 13 | 0.9762 | 0.9966 |
结论:
- 减少特征后,模型准确率和 AUC 未下降,甚至略有提升,说明冗余特征被有效剔除。
- Wrapper 和 Embedded 方法性能略优,因考虑了特征间的协同作用。
6. 算法优化建议
- 集成选择策略:优先使用多方法共选的特征(如 6 个交集特征),提升特征子集的鲁棒性。
- 交叉验证增强:在特征选择阶段加入
cross_val_score,避免因随机划分数据导致的偏差。 - 非线性方法探索:尝试 XGBoost、LightGBM 等树模型的内置特征重要性筛选,对比与线性方法的差异。
- 降维结合:将 PCA(无监督降维)与特征选择(有监督筛选)结合,分析正交特征空间的模型表现。
总结
特征选择是连接数据预处理与模型训练的关键桥梁:
-
Filter 法快速高效,适合初步筛选;
-
Wrapper 法精准但耗时,适合追求性能上限;
-
Embedded 法兼顾效率与效果,适合工程落地。
通过可视化对比和模型性能评估,可针对性选择最优特征子集,在减少计算成本的同时提升模型泛化能力