Transformer四模型回归打包(内含NRBO-Transformer-GRU、Transformer-GRU、Transformer、GRU模型)
目录
预测效果
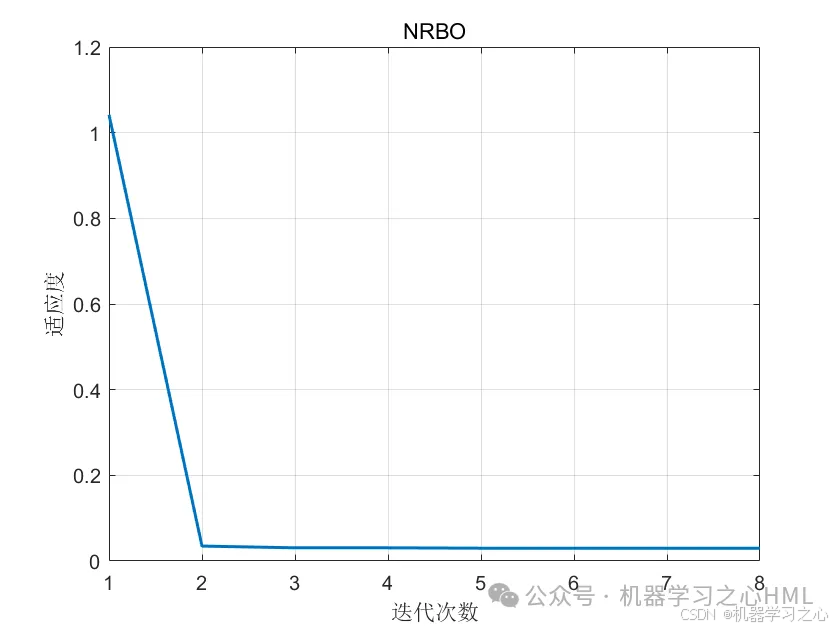
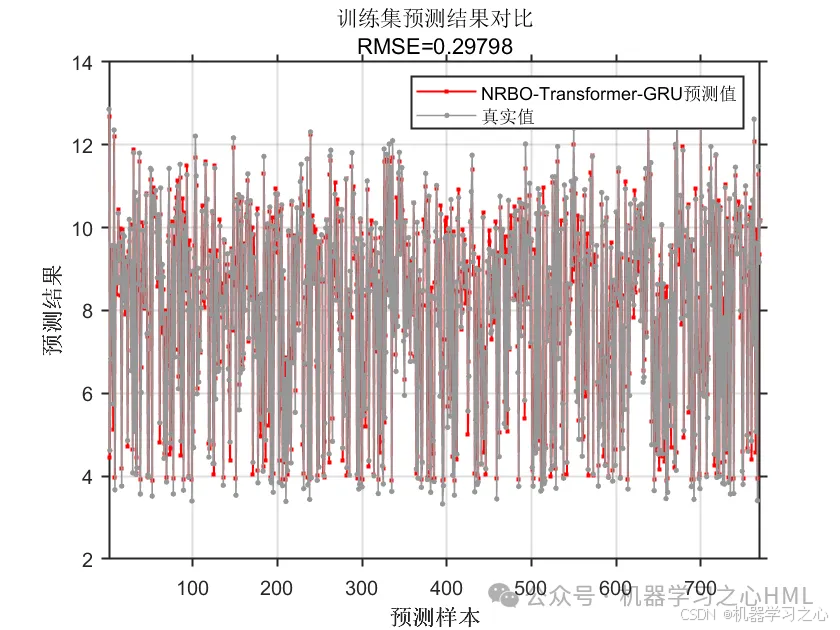

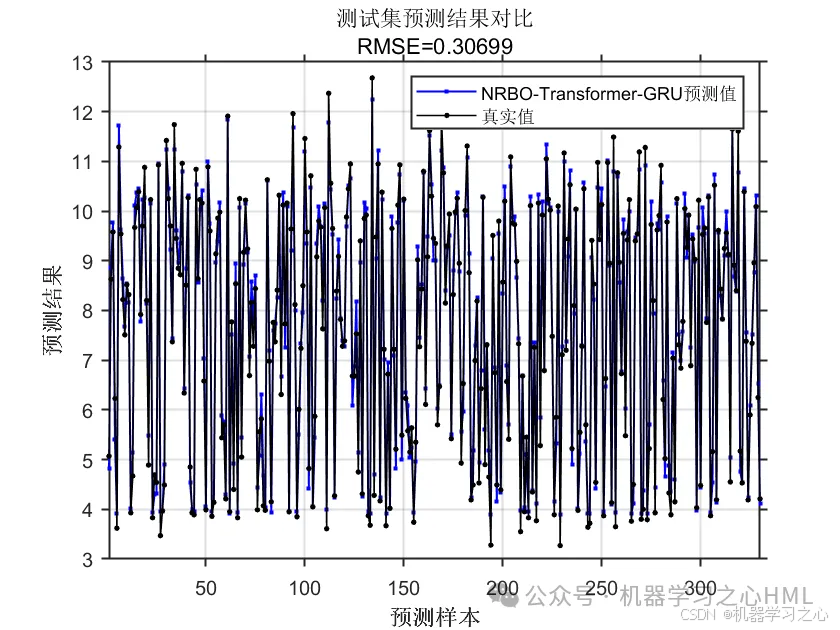
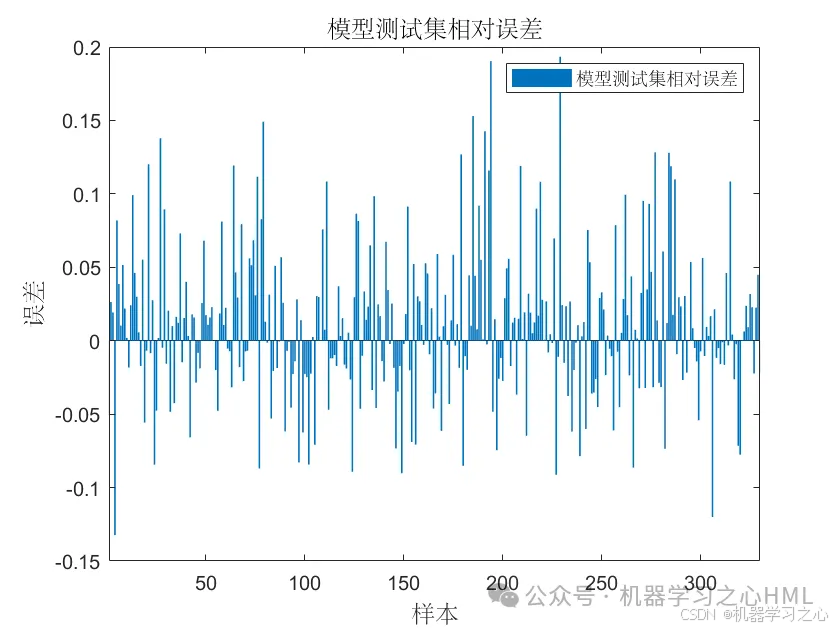
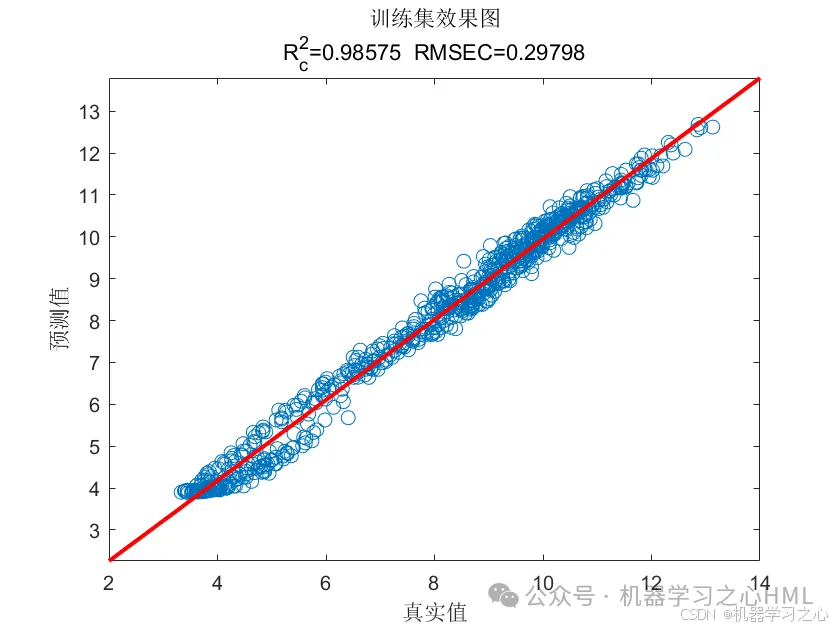
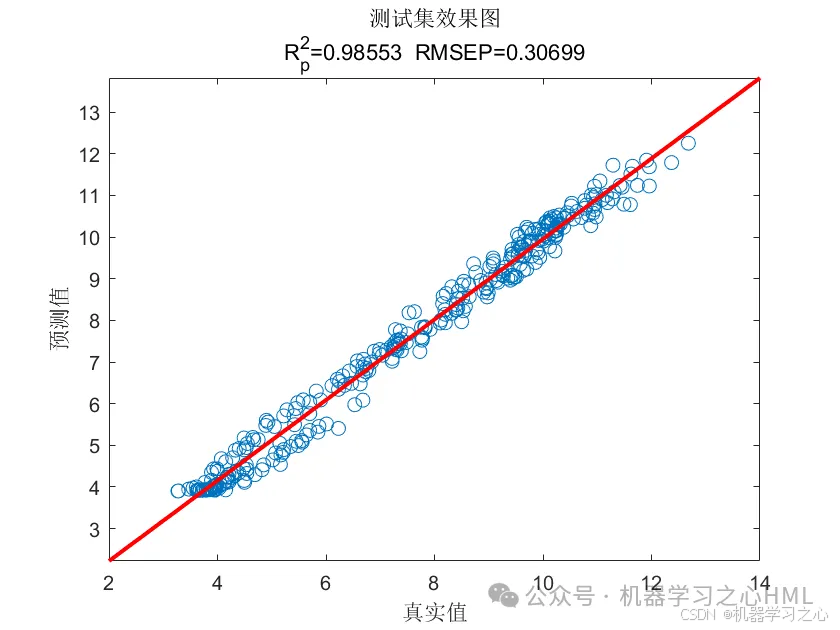
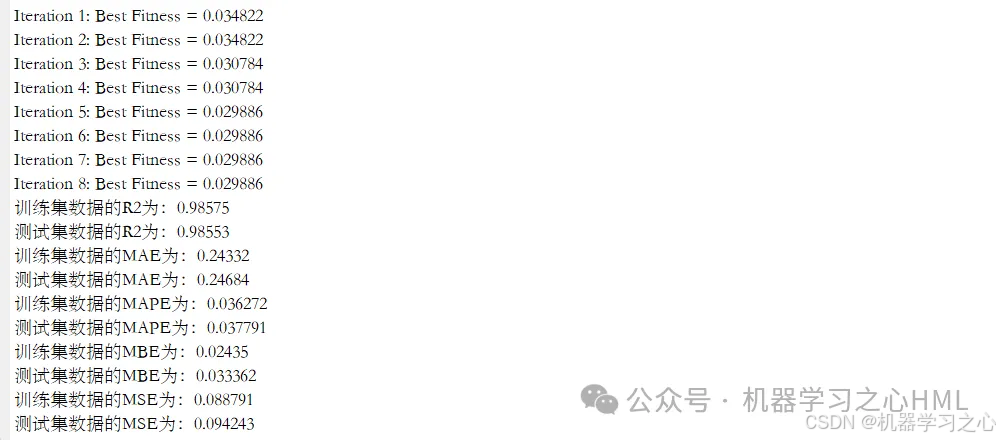
基本介绍
1.【JCR一区级】Matlab实现NRBO-Transformer-GRU多变量回归预测,牛顿-拉夫逊算法优化Transformer-GRU组合模型(程序可以作为JCR一区级论文代码支撑,目前尚未发表);
2.优化参数为:学习率,隐含层节点,正则化参数,运行环境为Matlab2023b及以上;
3.data为数据集,输入多个特征,输出单个变量,多变量回归预测,main.m为主程序,运行即可,所有文件放在一个文件夹;
4.命令窗口输出R2、MSE、RMSE、MAE、MAPE、MBE等多指标评价。
程序设计
- 完整源码和数据获取方式:私信博主回复Transformer四模型回归打包(内含NRBO-Transformer-GRU、Transformer-GRU、Transformer、GRU模型)。
clike
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
%% 导入数据
res = xlsread('data.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
%% 数据归一化
[P_train, ps_input] = mapminmax(P_train, 0, 1);
P_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 参数设置
options = trainingOptions('adam', ... % ADAM 梯度下降算法
'MiniBatchSize', 30, ... % 批大小,每次训练样本个数30
'MaxEpochs', 100, ... % 最大训练次数 100
'InitialLearnRate', 1e-2, ... % 初始学习率为0.01
'LearnRateSchedule', 'piecewise', ... % 学习率下降
'LearnRateDropFactor', 0.5, ... % 学习率下降因子
'LearnRateDropPeriod', 50, ... % 经过100次训练后 学习率为 0.01 * 0.5
'Shuffle', 'every-epoch', ... % 每次训练打乱数据集
'Plots', 'training-progress', ... % 画出曲线
'Verbose', false);参考资料
1 https://blog.csdn.net/kjm13182345320/category_11003178.html?spm=1001.2014.3001.5482
2 https://blog.csdn.net/kjm13182345320/article/details/117378431
3 https://blog.csdn.net/kjm13182345320/article/details/118253644