GPUStack 是一个专为运行 AI 模型设计的开源 GPU 集群管理器 ,致力于支持基于任何品牌的异构 GPU 构建统一管理的算力集群。无论这些 GPU 运行在 Apple Mac 、Windows PC 还是 Linux 服务器 上,GPUStack 都能将它们纳入统一的算力集群中。管理员可以轻松地从 Hugging Face 等流行的模型仓库中部署 AI 模型,开发人员则能够通过 OpenAI 兼容的 API 访问这些私有模型服务,就像使用 OpenAI 或 Microsoft Azure 提供的公共模型服务 API 一样便捷。
GPUStack 一直致力于以最简单易用的方式,帮助用户快速纳管异构 GPU 资源并运行所需的 AI 模型,从而支撑 RAG、AI Agents 以及其他生成式 AI 落地场景。为用户打造绝佳的使用体验是我们始终坚持的目标。在最新发布的 v0.5 版本以及接下来的版本中,我们将全方位强化和改善整体的用户体验。
GPUStack v0.5 版本的核心更新包括:
- 新增模型 Catalog:提供经过验证的模型集合,简化模型部署流程,大幅降低用户的认知负担,提升部署效率。
- 增强 Windows 和 macOS 模型支持:将 VLM 多模态模型支持和 Tool Calling 能力扩展到 Windows 和 macOS 平台,不再局限于 Linux 环境。
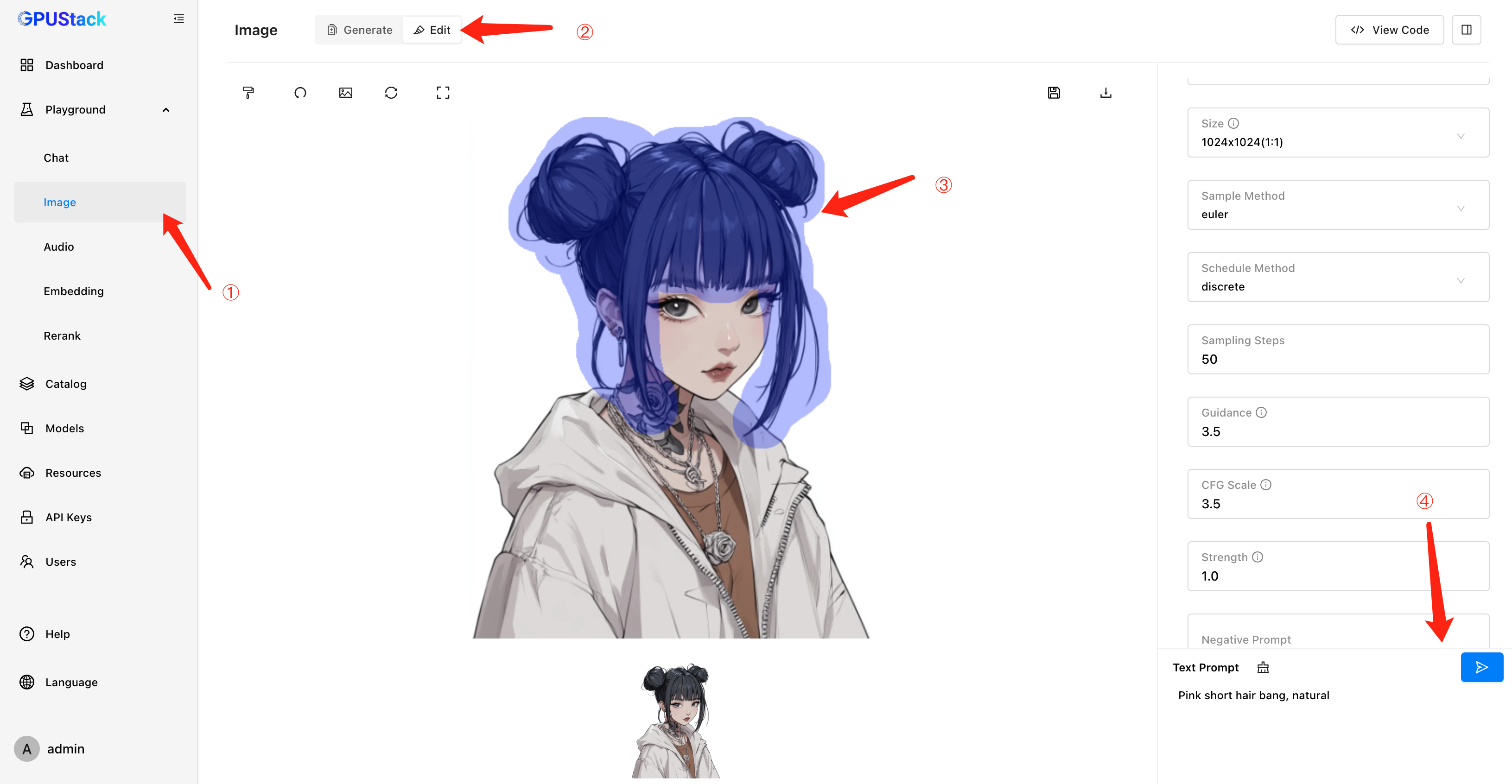
- 支持图生图功能:为 Image 模型新增图生图(图像编辑)功能,同时提供对应的 API 和 Playground UI,支持更丰富的应用场景。
- 模型管理优化:新增模型启动检查功能、支持模型的停止和启动操作,还有支持对无法自动识别的模型进行手动分类,便于分类和使用。
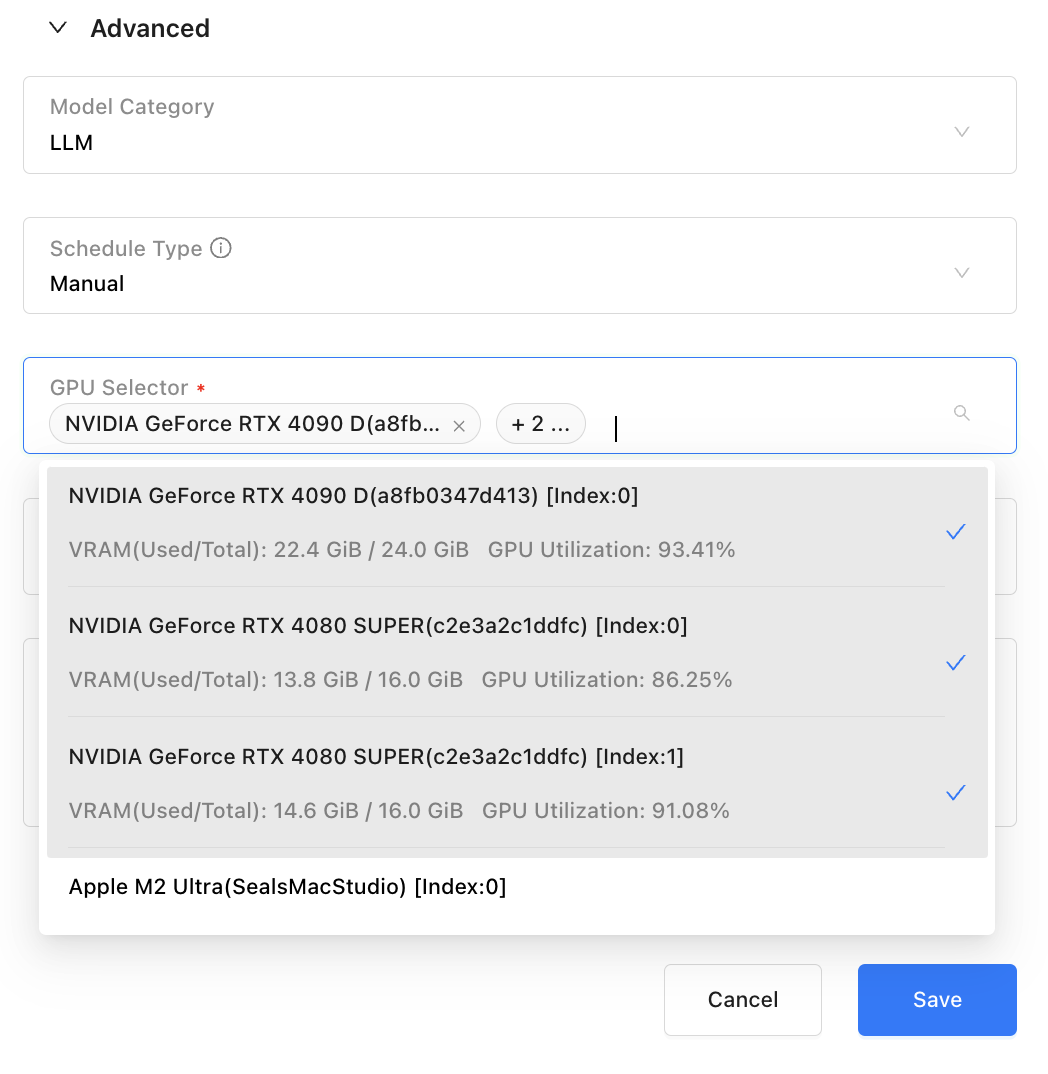
- 调度优化:优化自动调度优先级,将分布式推理的优先级调整至高于 CPU 推理。还增强了手动调度选卡功能,支持选择多卡,包括单机多卡(vLLM)和多机多卡(llama-box),资源分配更加自由。
- 扩展集成能力:增加了 AMD GPU 支持,为 Dify 的 GPUStack Provider 添加了 STT 和 TTS 语音模型支持。还提供了 RAGFlow 的 GPUStack Provider,修复了与 FastGPT 集成的问题。
这一版本包含 60 多项增强、修复、稳定性改进和用户体验优化,全面提升了 GPUStack 的易用性与功能,为用户提供更强大的应用场景支持。
有关 GPUStack 的详细信息,可以访问:
GitHub 仓库地址: https://github.com/gpustack/gpustack
GPUStack 用户文档: https://docs.gpustack.ai
重点特性介绍
新增模型 Catalog
GPUStack 支持直接从 Hugging Face 和 ModelScope 的公共模型仓库中搜索模型并进行部署。结合自定义推理引擎版本的功能,用户无需升级 GPUStack 就能随时部署体验新发布的前沿模型。
这种模式可能会给一些新上手的用户带来额外的负担。Hugging Face 和 ModelScope 上有多种多样的模型,用户往往难以确定该选择哪个模型进行部署。为改善用户的部署体验,GPUStack 在 v0.5 版本中新增了模型 Catalog。在 Catalog 中,我们提供了一组经过验证的模型,并对部署流程进行了简化,从而大幅降低用户在部署模型时的认知负担:
- 聚合同类模型为一个模型族,用户可以根据自身需求选择模型族进行部署,权重大小、量化精度等配置作为可选项,进一步简化模型部署流程。
- 无需用户手动选择下载源,GPUStack 会根据 Hugging Face 和 ModelScope 的下载速度自动选择最优下载源。
- 提供预置参数配置,对于运行模型所需的各种配置参数,GPUStack 会针对每个模型按需预设运行参数。例如,针对支持 Tool Calling 的模型,自动配置启用 Tool Calling 的相关参数。

在接下来的 v0.6 及后续版本中,GPUStack 将持续增强和优化 Catalog,提升模型部署的效率和成功率。通过减少用户的试错环节,帮助用户更加省时、省力、省心地完成所需模型的部署。
增强 Windows 和 macOS 模型支持
在此前的版本中,VLM 多模态模型和模型 Tool Calling 能力的支持依赖于 vLLM 后端,因此仅限于 Linux 环境。为了覆盖更多场景和环境,满足 Windows 和 macOS 用户的需求,我们对 llama-box 后端进行了增强。
无论用户使用的是 Linux、Windows 还是 macOS,现在都可以无缝体验跨平台的 VLM 多模态模型支持 ,在这些平台轻松部署如 Qwen2-VL、MiniCPM-V、MiniCPM-o 等多模态模型。同时,llama-box 还会自动为支持 Tool Calling 的模型启用该能力,让用户在多平台环境中享受一致的模型体验。
支持图生图
GPUStack 在 v0.4 版本中引入了文生图模型支持,为用户提供图像生成能力。在 v0.5 版本中,我们进一步升级了这一功能,新增了图生图(图像编辑)支持。用户不仅可以通过 Image Edit API 调用这一功能,还可以使用直观的 Playground UI 进行图像编辑的调试。这项增强拓展了图像模型的应用场景,满足了用户更多样化的需求,为创意生成和图像应用提供了相应的技术支持。

模型管理优化
在 GPUStack 中,模型的部署和管理是核心功能之一。为了进一步提升用户体验,v0.5 版本新增了模型启动检查功能。现在,GPUStack 会在模型完全启动并确认能够正常推理后,才会允许用户在 Playground 中使用该模型,避免了用户因模型未启动完成而出现的使用问题。
对于用户反馈通过将副本数调整为零来停止模型实例的操作不够清晰的问题,v0.5 版本也做出了优化。现在,GPUStack 直接支持更加直观的模型停止和启动操作,用户可以通过简单的按钮操作来管理模型实例,操作更加简单易懂。
此外,在 v0.5 中,我们还解决了部分模型无法自动识别分类的问题,完善了自动识别逻辑,而对于那些依然无法自动识别的模型,GPUStack 也支持用户手动为模型分类:

调度优化
针对用户在模型部署和调度中的实际场景需求,同时经过详细的测试验证了分布式推理的性能和稳定性,GPUStack v0.5 对自动调度的优先级进行了优化,将分布式推理的优先级调整至高于 CPU 推理。现在自动调度的优先级为:
单机单卡推理 > 单机多卡推理 > 多机多卡分布式推理 > CPU & GPU 混合推理 > 纯 CPU 推理
这项优化确保了优先使用高性能资源运行模型,更好地保证推理性能与效率。

为了更加灵活地控制 GPU 资源分配,GPUStack v0.5 对手动调度选卡功能进行了增强,支持了选择多卡,包括单机多卡(vLLM)和多机多卡(llama-box)。现在用户可以根据实际需求精细化分配 GPU 资源,为用户提供更高的调度自由度和场景适配能力,满足多样化的场景需求。
扩展集成能力
GPUStack 始终致力于实现与各种第三方应用和框架的无缝集成,为生成式 AI 应用落地提供强大的模型能力支持。与各类生成式 AI 应用框架例如 Dify、RAGFlow 和 FastGPT 等上层项目的集成一直是我们在重点推进的工作之一。
在 GPUStack 新增对语音模型(STT 和 TTS)的支持后,我们进一步增强了 Dify 的 GPUStack Provider 功能。用户现在可以通过 Dify 的 GPUStack Provider 无缝对接 GPUStack 部署的语音模型。GPUStack 与 Dify 的结合可以在生成式 AI 场景中提供多样化的应用能力。

我们也在 RAGFlow 的最新版本中添加了 GPUStack Provider,支持接入 GPUStack 部署的多种模型,包括 LLM、Embedding、Reranker,以及 STT 和 TTS 模型,为构建高效的 RAG 流程提供了更多可能性。
当前 RAGFlow 已发布的 v0.15.1 版本还未支持,可以安装 RAGFlow 的
nightly版本或等待新版本发布

同时,在 v0.5 版本中我们还修复了与 FastGPT 的集成问题,FastGPT 用户可以通过 OneAPI 集成 GPUStack 部署的模型服务。
对于其他大模型应用框架(如 LangChain、LlamaIndex 等),GPUStack 提供了标准的 OpenAI 兼容 API,便于这些框架的接入。如果用户在集成 GPUStack 时遇到任何问题,也欢迎随时与我们反馈。
扩展支持范围
GPUStack v0.5 版本新增了对 AMD GPU 的支持!请参考教程进行配置:https://docs.gpustack.ai/latest/tutorials/running-inference-with-amd-gpus/
GPUStack 提供了多种加速框架的离线容器镜像,包括 NVIDIA CUDA、AMD ROCm、昇腾 CANN、摩尔线程 MUSA,以及适用于 CPU 推理的容器镜像(x86 架构需支持 AVX2,ARM64 架构需支持 NEON)。这些镜像允许用户在不同类型的设备上按需运行对应的推理环境,从而灵活组建异构 GPU 资源池,满足多样化模型运行需求。

我们正在持续扩展 GPUStack 的支持范围,目前正在推进对海光 DCU 和寒武纪 MLU 等硬件的支持工作。
GPUStack 当前依赖 Pyhon >= 3.10,若主机的 Python 版本低于 3.10,建议使用 Conda 创建符合版本要求的 Python 环境。
其他特性和修复
GPUStack v0.5.0 版本还针对用户使用 GPUStack 的阻碍点和反馈的问题点进行了大量改进和修复,例如:
- 提供对 NVIDIA、AMD、昇腾、摩尔线程 GPU/NPU 的容器安装指引
- 自动根据下载速度选择下载源下载运行所需的 tools,不再需要用户手动指定
- 固定内置的 vLLM 与 vox-box 版本,在多节点安装、再次安装等场景提供版本一致性
- 修复 vLLM 后端自动调度计算分配的卡并行数量不正确问题
- 修复 vLLM 后端部署 GPTQ 和AWQ 量化模型时对显存资源的预估不准确问题
- 解决 llama-box 后端在 GPU 环境进行纯 CPU 推理仍然需要分配一小部分显存问题
等等。这些改进增强了 GPUStack 的易用性和稳定性,进一步改善了用户的使用体验。
其他增强和修复请查看完整变更日志:
https://github.com/gpustack/gpustack/releases/tag/v0.5.0
参与开源
想要了解更多关于 GPUStack 的信息,可以访问我们的仓库地址:https://github.com/gpustack/gpustack。如果你对 GPUStack 有任何建议,欢迎提交 GitHub issue 。在体验 GPUStack 或提交 issue 之前,请在我们的 GitHub 仓库上点亮 Star ⭐️关注我们,也非常欢迎大家一起参与到这个开源项目中!
如果觉得对你有帮助,欢迎点赞 、转发 、关注。