优化分页功能
目录
1.封装分页代码
2.解决分页时覆盖搜索参数的bug
3.优化分页功能
上一篇文章我们讲到了搜索功能和分页展示数据功能。那这篇文章, 在上篇文章的基础上, 会去优化这些功能并解决搜索功能和分页功能不能一起使用的bug。
一、封装分页代码
原本我们的assets.py里面的assets函数是这么写的:
python
def assets(request):
# assets_list = models.Assets.objects.all()
# 搜索信息
dict_data = {}
# 获取搜素框里的内容, 就是获取网址里面的search参数的值
value = request.GET.get('search')
if value:
# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__contains
dict_data["mobile__contains"] = value
# assets_list = models.Assets.objects.filter(**dict_data)
# 获取分页组件里面选中的页码, 也是获取网址里面的page参数的值
page = int(request.GET.get('page', 1))
# 每一页查询10条数据
page_size = 10
# 当前页开始的数据
start = (page - 1) * page_size
# 当前页结尾的数据
end = page_size * page
# 利用切片, 实现分页查询, 查询出当页数据
assets_list = models.Assets.objects.filter(**dict_data)[start:end]
# 统计表当中的总个数
data_asset_count = models.Assets.objects.filter(**dict_data).count()
# 求得表中的总个数都需要多少页来展示, page_num代表总页数, div代表剩余的数据还有多少条
page_count, div = divmod(data_asset_count, page_size)
if div:
page_count += 1
# 我们需要在分页组件里面展示五个页码。
# 当我们选中的页数, 和最左边最右边显示的页数相差2, 所以我们将plus设置为2, 比如我选择第三页, 那最左边显示的页码是1最右边显示的页码是5。
plus = 2
# 我们想要分页功能, 展示其中5个页码, 如果想要展示不同个页数的页码, 自己可以调整。
# 当总页数不超过5页的时候, 1 + 2 * plus意思是当前选择的页, 加上左边还有两页, 右边也还有两页, 总共是5页。
if data_asset_count <= 1 + 2 * plus:
# 开始页数为1
start_page = 1
# 结束位置就是总页数
end_page = data_asset_count
# 这里面全是总页数大于5页的情况
else:
# 如果我目前选择的页码, 小于等于3
if page <= plus + 1:
# 开始页还是1
start_page = 1
# 结束页是5, 1 + 2 * plus这个意思上面有注释。
end_page = 1 + 2 * plus
# 如果我目前选择的页码加上2能够大于总页数, 那就说明分页组件里面的页码是最后五页数据了, 比如总页数为20, 我选择的是第19页, 19+2=21>20
elif page + plus > page_count: # 这里写>=也可以
# 开始页为总页数减去两倍的plus, 比如总共有20页, 当我们分页组件显示的页码是最后五页的时候, 最左边应该显示的是16。所以正好是总页数-两倍的plus
start_page = page_count - 2 * plus
# 结尾页展示的就是总页数
end_page = page_count
# 如果我们目前选择的页码就在正中间, 排除1, 2, 3, 19, 20页的其它所有页数。
else:
# 开始页数就是当前分页组件选择的页数-plus
start_page = page - plus
# 结束页数就是当前分页组件选择的页数+plus
end_page = page + plus
# 创建一个列表, 用于存储html代码, 以字符串来保存到列表中
html_list = []
# 分页组件返回到首页功能
html_list.append(f"""<li><a href="?page=1">首页</a></li>""")
# 如果当前选择的页码>1, 可以往前退一页, 否则不能在往前退了。在li标签上加class="disabled"代表禁用
if page > 1:
html_list.append(f"""<li><a href="?page={page - 1}"><span aria-hidden="true"><<</span></a></li>""")
else:
html_list.append(f"""<li class="disabled"><span aria-hidden="true"><<</span></li>""")
# 分页组件的中间翻页的内容, 点击第几页就到第几页, 在分页组件当中, 选中的页码会有背景色。li标签里面的class='active'代表选中了那个页码, 会出现背景色
for page_num in range(start_page, end_page + 1):
if page_num == page:
html_list.append(f"<li class='active'><a href='?page={page_num}'>{page_num}</a></li>")
else:
html_list.append(f"<li><a href='?page={page_num}'>{page_num}</a></li>")
# 如果当前选择的页码<总页数, 可以往前进一页, 否则不能在往进退了。在li标签上加class="disabled"代表禁用
if page < page_count:
html_list.append(f"""<li><a href="?page={page + 1}"><span aria-hidden="true">>></span></a></li>""")
else:
html_list.append("""<li class="disabled"><span aria-hidden="true">>></span></li>""")
# 分页组件进入到尾页功能
html_list.append(f"""<li><a href="?page={page_count}">尾页</a></li>""")
# join就是将列表当中所有的内容全部拼接在一起为字符串。mark_safe函数的作用是将字符串里面的内容, 转换为html元素。
# mark_safe也是django框架里面的函数, 需要手动导入, 导入语句为from django.utils.safestring import mark_safe
page_string = mark_safe("".join(html_list))
# 不能忘记将page_string传给前端。
return render(request, "assets/assets_list.html", {"assets_list": assets_list, "page_string": page_string})接下来, 我们对以上代码进行封装:
我们在project_one文件夹下面新建一个utils文件夹, 创建PageData.py:
PageData.py代码:
python
from copy import deepcopy
from django.utils.safestring import mark_safe
class PageData(object):
def __init__(self, request, queryset, page_size=10, plus=2, page_param="page"):
get_query_dict = deepcopy(request.GET)
self.query_dict = get_query_dict
self.page_param = page_param
page = request.GET.get(self.page_param, "1")
# 判段当前page首部是纯数字
# 为了严谨性, 多加个判断, 如果url里面的page参数里面的值是文字的话, 那程序就会报错, 所以这里需要判断, 如果判断出page的值不是纯数字的话, 那就给page默认赋值为1。
if page.isdecimal():
page = int(page)
else:
page = 1
self.page = page
self.start = (self.page - 1) * page_size
self.end = self.page * page_size
self.page_queryset = queryset[self.start: self.end]
page_count = queryset.count()
page_count, div = divmod(page_count, page_size)
if div:
page_count += 1
self.page_count = page_count
self.plus = plus其实这些就是把上面分页的代码, 变为面向对象的代码来进行封装。
不过要注意的是, get_query_dict = deepcopy(request.GET)这行代码用的是深拷贝, 深拷贝需要导入相应的包:from copy import deepcopy, page.isdecimal()用于判断当前page首部是否是纯数字, 其它的内容大差不差, 就是不要忘记在变量前面加上self, 因为有些变量到后面还要在用, self.page_queryset = queryset[self.start: self.end]是为之后再asserts.py里面需要调用page_queryset做准备的。
二、解决分页是覆盖搜索参数的bug
产生这种现状的原因很简单, 因为我们在分页的时候, 把搜索参数给覆盖掉了, 导致点击分页的时候无法与搜索功能一起实现。为了解决这种问题, 其实不难, 在接下来的代码里面也会体现出来。
我们继续写PageData.py里面的代码, 把功能都封装到page_html函数里面。
代码:
python
def page_html(self):
if self.page_count <= 2 * self.plus + 1:
start_page = 1
end_page = self.page_count
else:
# 如果当前点击的页面是小于3的
if self.page <= self.plus:
start_page = 1
end_page = 2 * self.plus + 1
else:
# 后五页
if (self.page + self.plus) > self.page_count:
start_page = self.page_count - self.plus * 2
end_page = self.page_count
else:
# 大于前五页,小于后五也的其他页面
start_page = self.page - self.plus
end_page = self.page + self.plus
page_str_list = []
# 首页
self.query_dict.setlist(self.page_param, [1])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">首页</a></li>')
# 上一页
if self.page > 1:
self.query_dict.setlist(self.page_param, [self.page - 1])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true"><<</span></a></li>')
else:
page_str_list.append(f'<li class="disabled"><span aria-hidden="true"><<</span></li>')
for page_num in range(start_page, end_page + 1):
if page_num == self.page:
self.query_dict.setlist(self.page_param, [page_num])
page_str_list.append(f'<li class="active"><a href="?{self.query_dict.urlencode()}">{page_num}</a</li>')
else:
self.query_dict.setlist(self.page_param, [page_num])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">{page_num}</a></li>')
# 下一页
if self.page < self.page_count:
self.query_dict.setlist(self.page_param, [self.page + 1])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true">>></span></a></li>')
else:
page_str_list.append(f'<li class="disabled"><span aria-hidden="true">>></span></li>')
# 尾页
self.query_dict.setlist(self.page_param, [self.page_count])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">尾页</a></li>')这里面的self.query_dict.setlist(self.page_param, [page_num])这种写法, 就是拼接url参数的, 我们在前面self.page_queryset = queryset[self.start: self.end]这段代码中, 它已经是包含着搜索功能再把参数传进来, 所以我们只需要拼接page参数即可, 这个self.page_param指的就是page这个参数, 方括号里面的内容, 就是页码。
三、优化分页功能
page_html函数里面的代码:
python
def page_html(self):
............
search_page = """
<li>
<div style="float: right">
<form method="get">
<div class="input-group" style="width: 100px;float: right">
<input type="text" class="form-control" name="page">
<span class="input-group-btn">
<button class="btn btn-success" type="submit">跳转</button>
</span>
</div>
</form>
</div>
</li>
"""
page_str_list.append(search_page)
page_string = mark_safe("".join(page_str_list))
return page_stringsearch_page里面的代码, 我们可以去bootstrap里面找, 打开bootstrap网页:
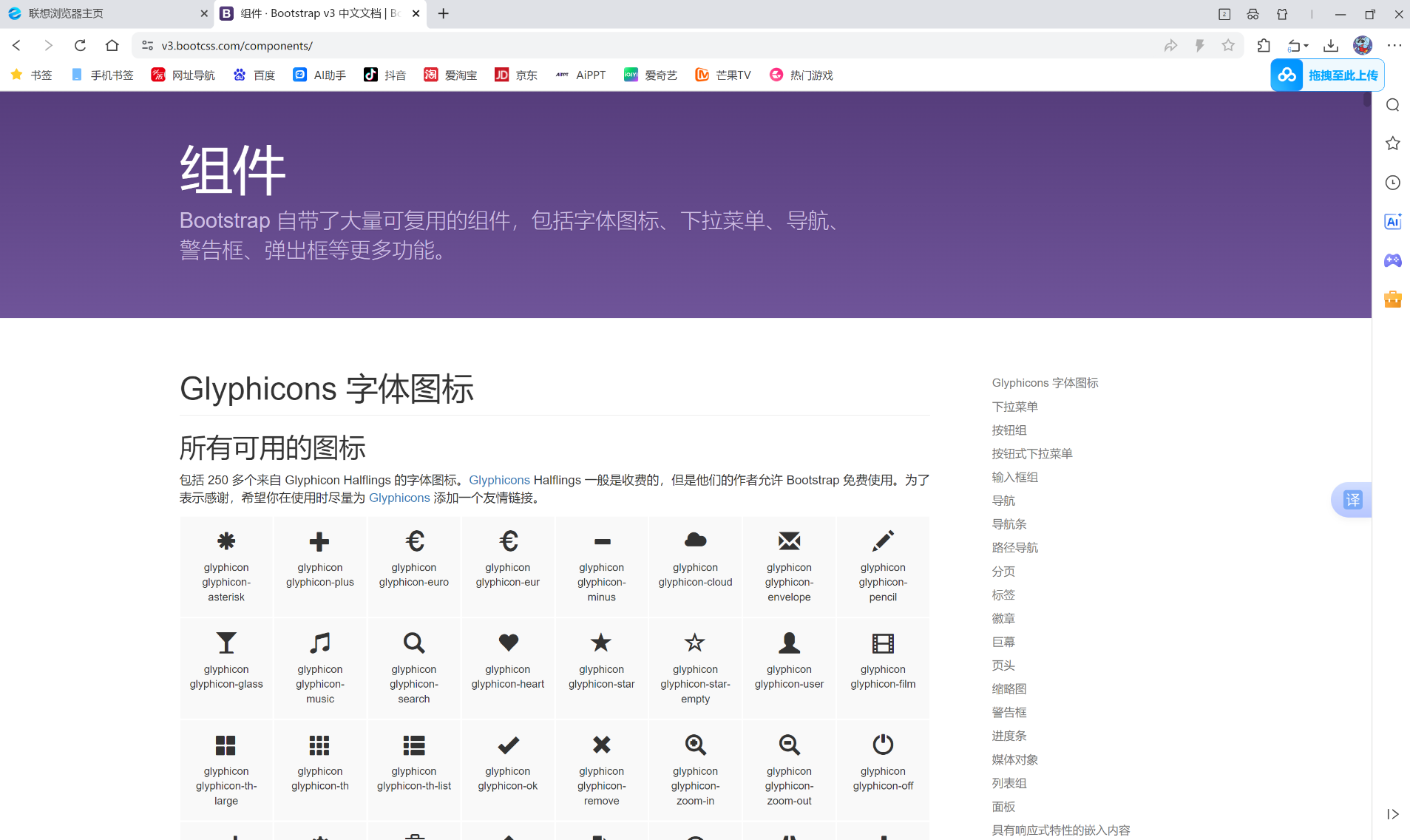
点击右侧的输入框组, 然后再找到作为额外元素的多选框和单选框然后找到相应的代码复制到pycharm即可。
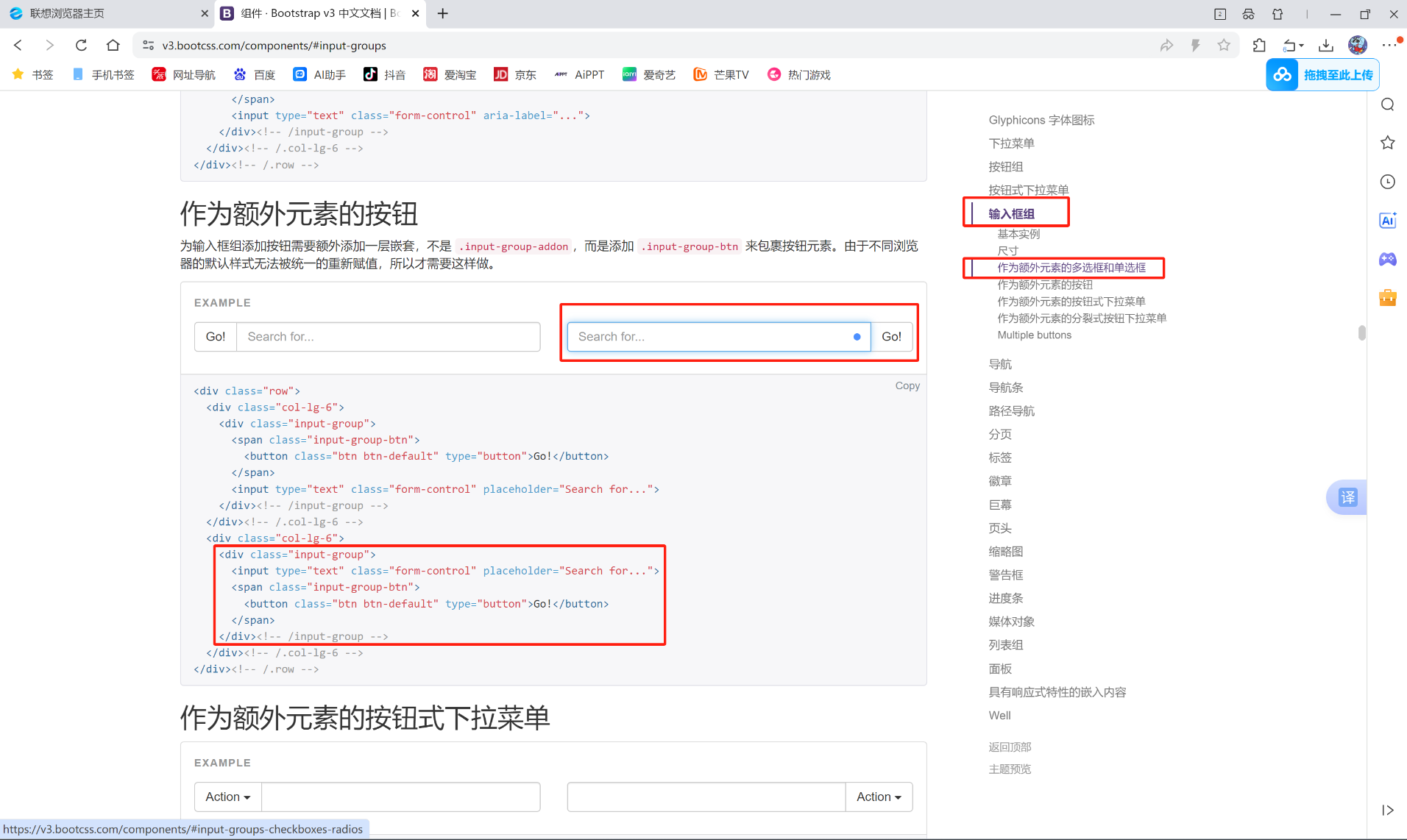
但是再search_page里面, 不要忘记加form表单, 是get请求, 将这个跳转页面功能放到分页的右边, 所以最外面再写一个float: right。
python
from copy import deepcopy
from django.utils.safestring import mark_safe
"""
对以下的分页代码进行封装:
def assets(request):
# assets_list = models.Assets.objects.all()
# 搜索信息
dict_data = {}
# 获取搜素框里的内容, 就是获取网址里面的search参数的值
value = request.GET.get('search')
if value:
# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__contains
dict_data["mobile__contains"] = value
# assets_list = models.Assets.objects.filter(**dict_data)
# 获取分页组件里面选中的页码, 也是获取网址里面的page参数的值
page = int(request.GET.get('page', 1))
# 每一页查询10条数据
page_size = 10
# 当前页开始的数据
start = (page - 1) * page_size
# 当前页结尾的数据
end = page_size * page
# 利用切片, 实现分页查询, 查询出当页数据
assets_list = models.Assets.objects.filter(**dict_data)[start:end]
# 统计表当中的总个数
data_asset_count = models.Assets.objects.filter(**dict_data).count()
# 求得表中的总个数都需要多少页来展示, page_num代表总页数, div代表剩余的数据还有多少条
page_count, div = divmod(data_asset_count, page_size)
if div:
page_count += 1
# 我们需要在分页组件里面展示五个页码。
# 当我们选中的页数, 和最左边最右边显示的页数相差2, 所以我们将plus设置为2, 比如我选择第三页, 那最左边显示的页码是1最右边显示的页码是5。
plus = 2
# 我们想要分页功能, 展示其中5个页码, 如果想要展示不同个页数的页码, 自己可以调整。
# 当总页数不超过5页的时候, 1 + 2 * plus意思是当前选择的页, 加上左边还有两页, 右边也还有两页, 总共是5页。
if data_asset_count <= 1 + 2 * plus:
# 开始页数为1
start_page = 1
# 结束位置就是总页数
end_page = data_asset_count
# 这里面全是总页数大于5页的情况
else:
# 如果我目前选择的页码, 小于等于3
if page <= plus + 1:
# 开始页还是1
start_page = 1
# 结束页是5, 1 + 2 * plus这个意思上面有注释。
end_page = 1 + 2 * plus
# 如果我目前选择的页码加上2能够大于总页数, 那就说明分页组件里面的页码是最后五页数据了, 比如总页数为20, 我选择的是第19页, 19+2=21>20
elif page + plus > page_count: # 这里写>=也可以
# 开始页为总页数减去两倍的plus, 比如总共有20页, 当我们分页组件显示的页码是最后五页的时候, 最左边应该显示的是16。所以正好是总页数-两倍的plus
start_page = page_count - 2 * plus
# 结尾页展示的就是总页数
end_page = page_count
# 如果我们目前选择的页码就在正中间, 排除1, 2, 3, 19, 20页的其它所有页数。
else:
# 开始页数就是当前分页组件选择的页数-plus
start_page = page - plus
# 结束页数就是当前分页组件选择的页数+plus
end_page = page + plus
# 创建一个列表, 用于存储html代码, 以字符串来保存到列表中
html_list = []
# 分页组件返回到首页功能
html_list.append(f"<li><a href="?page=1">首页</a></li>")
# 如果当前选择的页码>1, 可以往前退一页, 否则不能在往前退了。在li标签上加class="disabled"代表禁用
if page > 1:
html_list.append(f"<li><a href="?page={page - 1}"><span aria-hidden="true"><<</span></a></li>")
else:
html_list.append("<li class="disabled"><span
aria-hidden="true"><<</span></li>")
# 分页组件的中间翻页的内容, 点击第几页就到第几页, 在分页组件当中, 选中的页码会有背景色。li标签里面的class='active'代表选中了那个页码, 会出现背景色
for page_num in range(start_page, end_page + 1):
if page_num == page:
html_list.append(f"<li class='active'><a href='?page={page_num}'>{page_num}</a></li>")
else:
html_list.append(f"<li><a href='page={page_num}'>{page_num}</a></li>")
# 如果当前选择的页码<总页数, 可以往前进一页, 否则不能在往进退了。在li标签上加class="disabled"代表禁用
if page < page_count:
html_list.append(f"<li><a href="?page={page + 1}"><span aria-hidden="true">>></span></a></li>")
else:
html_list.append("<li class="disabled"><span
aria-hidden="true">>></span></li>")
# 分页组件进入到尾页功能
html_list.append(f"<li><a href="?page={page_count}">尾页</a></li>")
# join就是将列表当中所有的内容全部拼接在一起为字符串。mark_safe函数的作用是将字符串里面的内容, 转换为html元素。
# mark_safe也是django框架里面的函数, 需要手动导入, 导入语句为from django.utils.safestring import mark_safe
page_string = mark_safe("".join(html_list))
# 不能忘记将page_string传给前端。
return render(request, "assets/assets_list.html", {"assets_list": assets_list, "page_string": page_string})
"""
class PageData(object):
def __init__(self, request, queryset, page_size=10, plus=2, page_param="page"):
get_query_dict = deepcopy(request.GET)
self.query_dict = get_query_dict
self.page_param = page_param
page = request.GET.get(self.page_param, "1")
# 判段当前page首部是纯数字
if page.isdecimal():
page = int(page)
else:
page = 1
self.page = page
self.start = (self.page - 1) * page_size
self.end = self.page * page_size
self.page_queryset = queryset[self.start: self.end]
page_count = queryset.count()
page_count, div = divmod(page_count, page_size)
if div:
page_count += 1
self.page_count = page_count
self.plus = plus
def page_html(self):
if self.page_count <= 2 * self.plus + 1:
start_page = 1
end_page = self.page_count
else:
# 如果当前点击的页面是小于3的
if self.page <= self.plus:
start_page = 1
end_page = 2 * self.plus + 1
else:
# 后五页
if (self.page + self.plus) > self.page_count:
start_page = self.page_count - self.plus * 2
end_page = self.page_count
else:
# 大于前五页,小于后五也的其他页面
start_page = self.page - self.plus
end_page = self.page + self.plus
page_str_list = []
# 首页
self.query_dict.setlist(self.page_param, [1])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">首页</a></li>')
# 上一页
if self.page > 1:
self.query_dict.setlist(self.page_param, [self.page - 1])
page_str_list.append(
f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true"><<</span></a></li>')
else:
page_str_list.append(f'<li class="disabled"><span aria-hidden="true"><<</span></li>')
for page_num in range(start_page, end_page + 1):
if page_num == self.page:
self.query_dict.setlist(self.page_param, [page_num])
page_str_list.append(f'<li class="active"><a href="?{self.query_dict.urlencode()}">{page_num}</a></li>')
else:
self.query_dict.setlist(self.page_param, [page_num])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">{page_num}</a></li>')
# 下一页
if self.page < self.page_count:
self.query_dict.setlist(self.page_param, [self.page + 1])
page_str_list.append(
f'<li><a href="?{self.query_dict.urlencode()}"><span aria-hidden="true">>></span></a></li>')
else:
page_str_list.append(f'<li class="disabled"><span aria-hidden="true">>></span></li>')
# 尾页
self.query_dict.setlist(self.page_param, [self.page_count])
page_str_list.append(f'<li><a href="?{self.query_dict.urlencode()}">尾页</a></li>')
search_page = """
<li>
<div style="float: right">
<form method="get">
<div class="input-group" style="width: 100px;float: right">
<input type="text" class="form-control" name="page">
<span class="input-group-btn">
<button class="btn btn-success" type="submit">跳转</button>
</span>
</div>
</form>
</div>
</li>
"""
page_str_list.append(search_page)
page_string = mark_safe("".join(page_str_list))
return page_string注意, 不要忘记返回page_string。
最后再回到assets.py里面:
assets.py文件里面的asserts函数的内容做个修改, 我们需要去除之前写的那一大堆逻辑, 然后再调用我们已经封装好的函数。
python
def assets(request):
# assets_list = models.Assets.objects.all()
# 搜索信息
dict_data = {}
# 获取搜素框里的内容, 就是获取网址里面的search参数的值
value = request.GET.get('search')
if value:
# 在表格中搜素包含输入框当中的数据, 这里搜素的是手机号, key为mobile__contains
dict_data["mobile__contains"] = value
assets_list = models.Assets.objects.filter(**dict_data)
page_object = PageData(request, assets_list)
# 调用我们自己写的page_html函数, 在PageData类当中。
page_string = page_object.page_html()
# 不能忘记将page_string传给前端。
return render(request, "assets/assets_list.html",
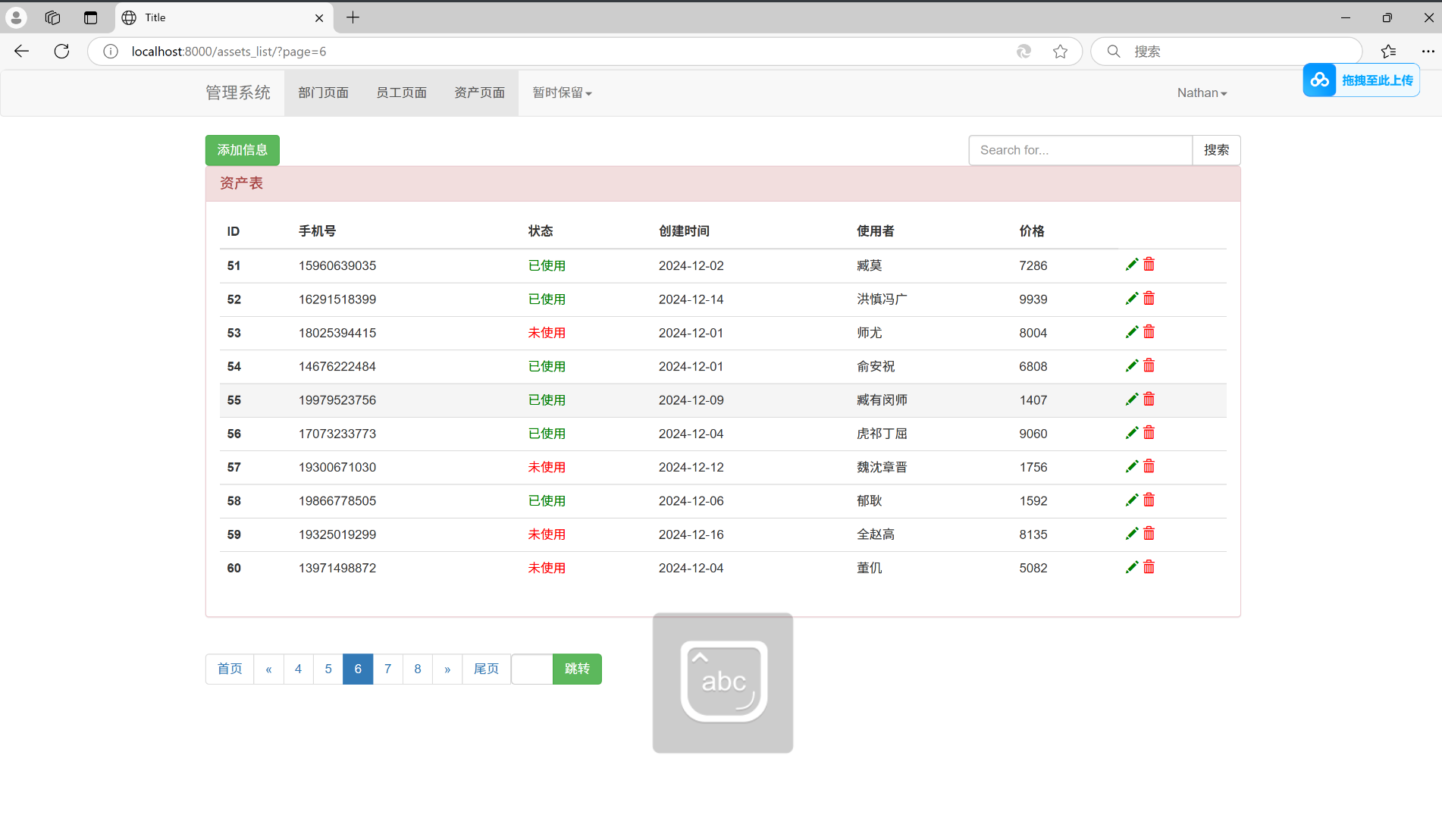
{"assets_list": page_object.page_queryset, "page_string": page_string})运行结果:
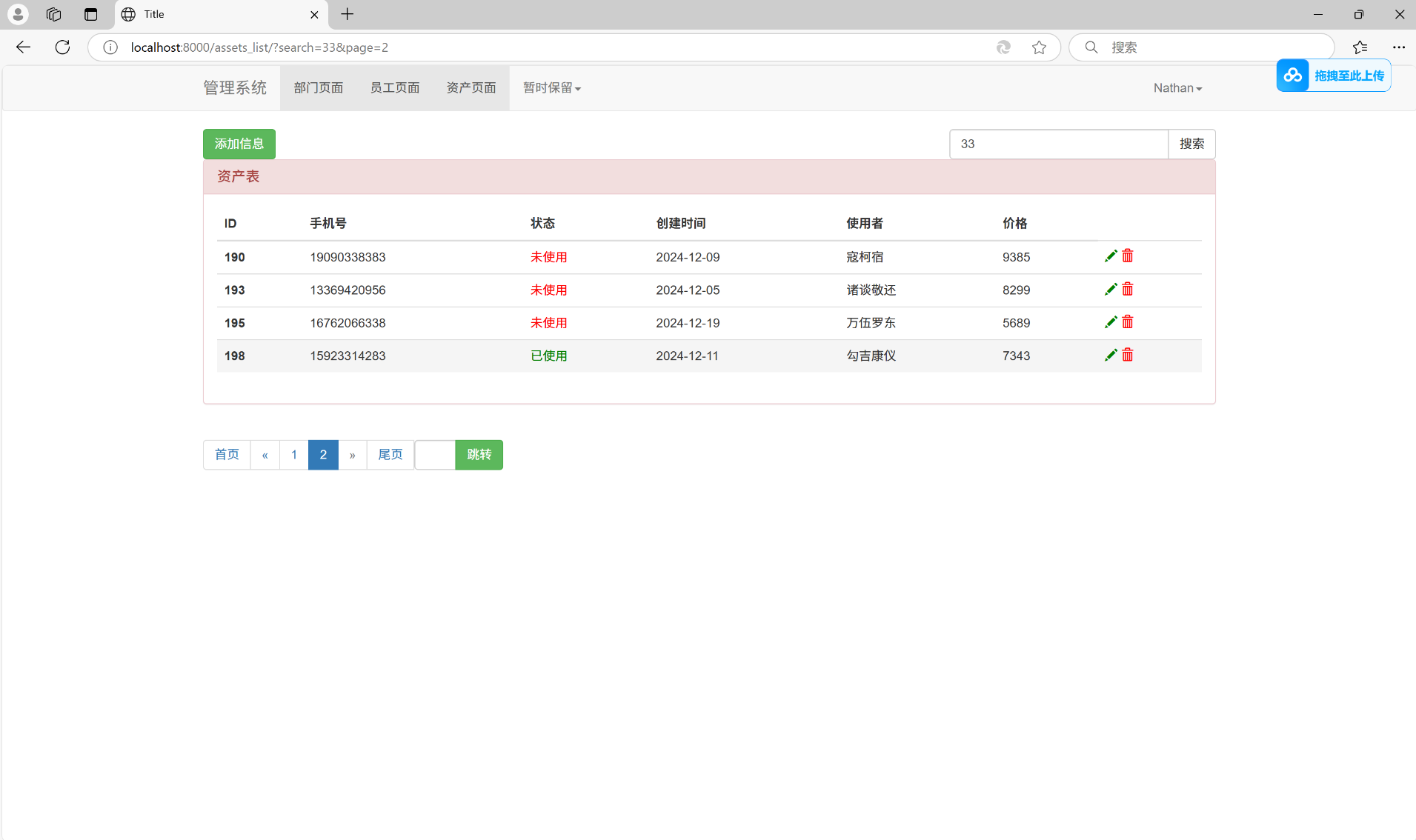
跳转页面功能:
搜索加跳转页面功能:
跳转页面功能:
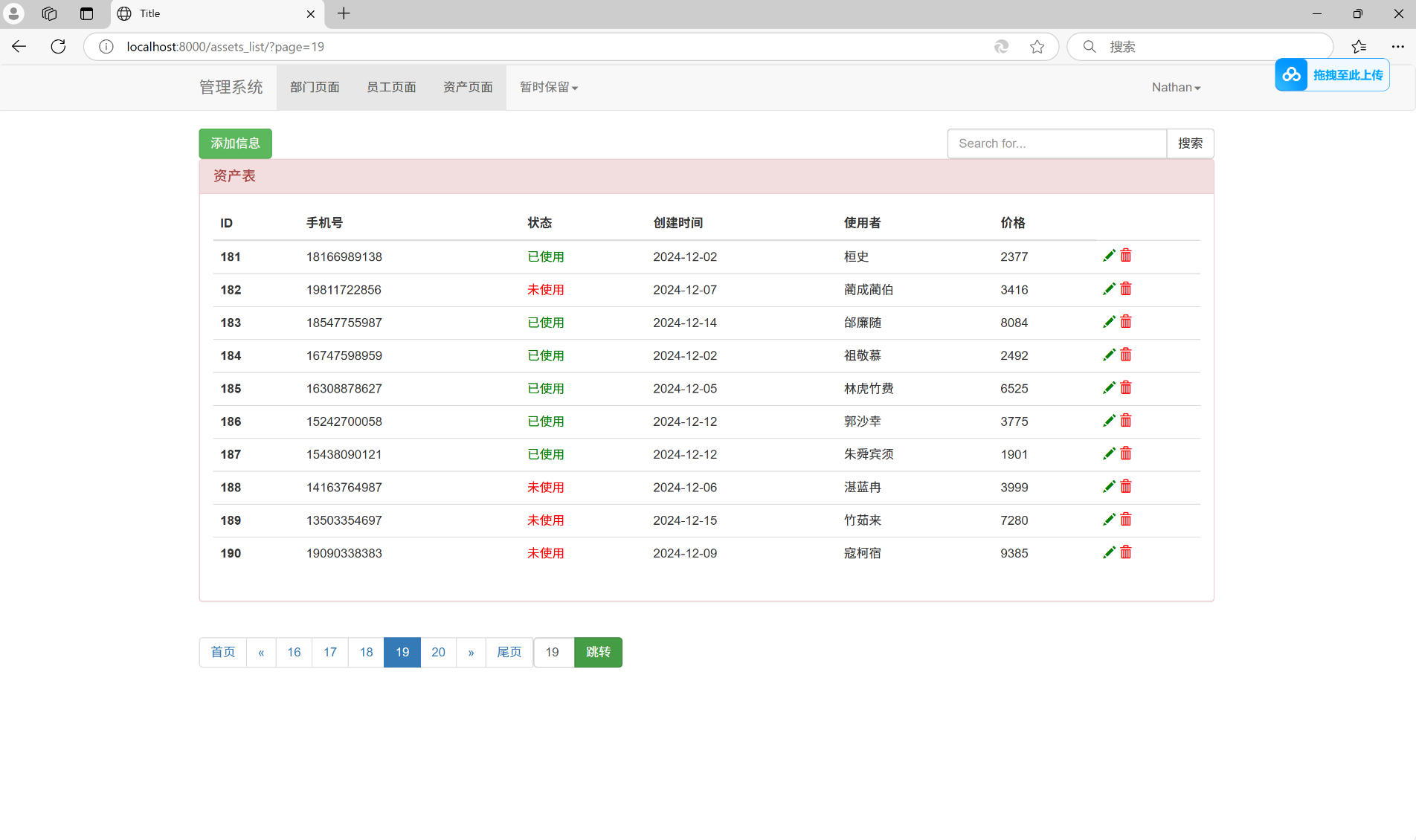
OK, 大功告成!!!
以上就是Django优化分页功能的所有内容了, 如果有哪里不懂的地方,可以把问题打在评论区, 欢迎大家在评论区交流!!!
如果我有写错的地方, 望大家指正, 也可以联系我, 让我们一起努力, 继续不断的进步.
学习是个漫长的过程, 需要我们不断的去学习并掌握消化知识点, 有不懂或概念模糊不理解的情况下,一定要赶紧的解决问题, 否则问题只会越来越多, 漏洞也就越老越大.
人生路漫漫, 白鹭常相伴!!!