LLaMA-Factory
经过一段时间的探索,从手动编写训练代码到寻求框架辅助训练,遇到了各种各样的问题。前面我介绍了dify的部署,但是并没有详细介绍使用方式,是因为我在尝试利用dify的时候碰到了很多困难,总结下来首先就是他的环境和端口通信问题比较难以解决,所以我就没有去讲。这几天我又尝试了使用国产的训练框架LLaMa-Factory,发现它更容易上手,环境配置更简单,并且经过尝试已经初步得出的成果,所以这篇文章我会为大家讲解从部署开始如何使用LLaMa-Factory训练自己的大模型的流程
LLaMA-Factory支持市面上各种各样的开源大模型,并且内置多种微调方式,比如lora、full、freeze,丰富的微调参数可供调整。提供了简洁的UI界面,并且支持验证、简单对话等功能
源码地址 https://github.com/hiyouga/LLaMA-Factory
部署LLaMA-Factory
1.首先保证已经安装了git,通过git拉取项目
bash
git clone https://github.com/hiyouga/LLaMA-Factory.git2.为了方便管理和环境隔离,我为其创建一个独立的环境,我这里使用的anaconda
bash
# 创建环境
conda create -n tuning python=3.10
#激活环境
conda activate tuning
# 进入目录
cd LLaMa-Factory3.安装必要依赖
bash
pip install -e .[torch,metrics]4.启动UI界面
bash
export CUDA_VISIBLE_DEVICES=0
python3 src/webui.py启动完成后,浏览器会自动访问到默认7860端口,有以下界面
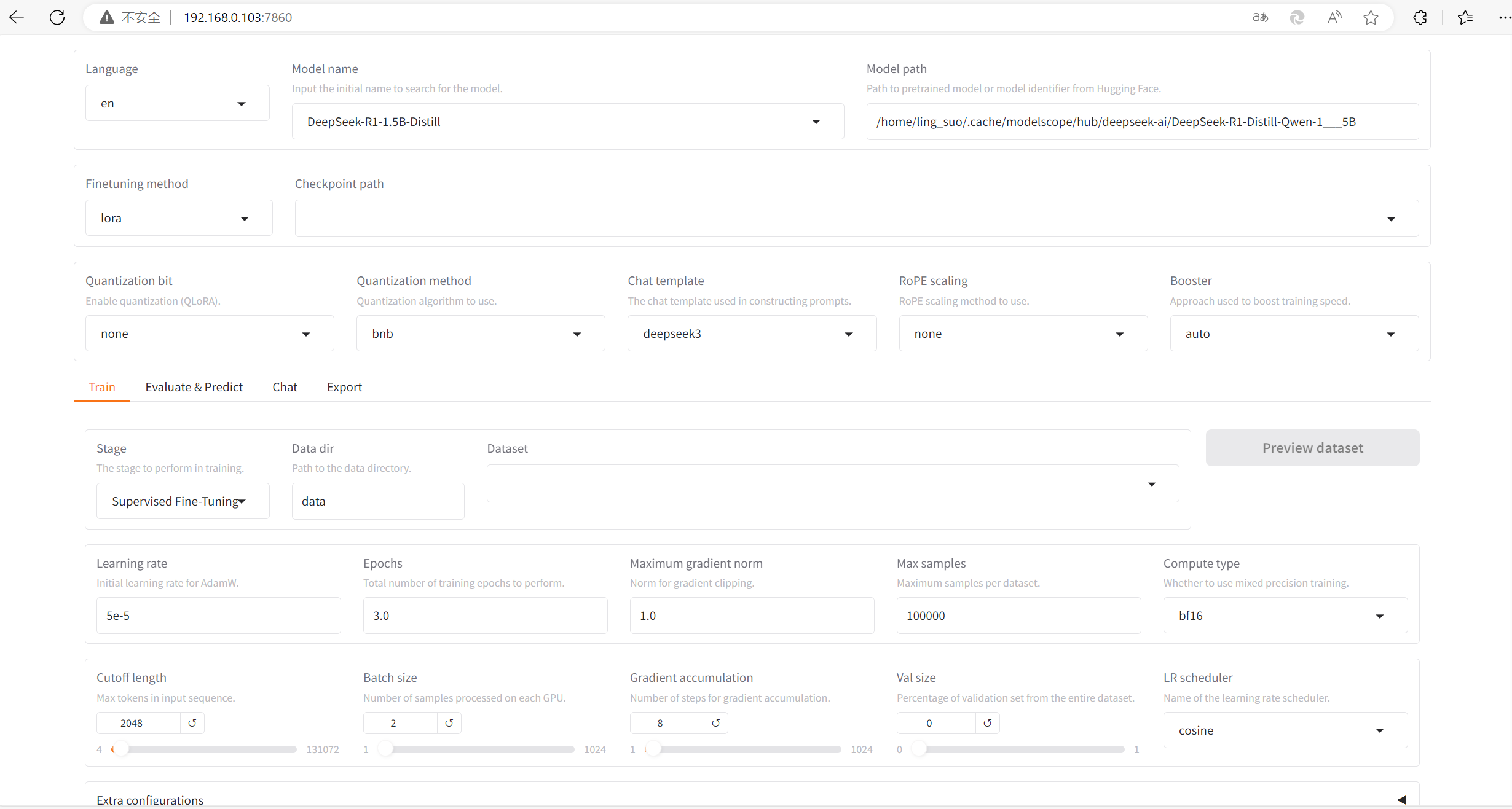
准备模型
这里如果本地没有模型文件的话,可以从魔塔社区上进行下载 模型库首页 · 魔搭社区
有条件话可以通过科学上网从huggingface上拉取模型文件 https://huggingface.co/
不过注意尽量是国内大模型
同时还要注意根据你的电脑性能进行选择,我这里为了方便演示选择deepseek-r1-1.5b
魔塔社区拉取模型示例
bash
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B准备数据集
LLaMA-Factory已经内置了许多数据集,我这里给大家演示如何使用自己的数据集
同样从魔塔社区下载,不过注意LLaMA-Factory的数据集有格式要求,需要符合prompt、input、output的格式,这里我已经整理好了一份甄嬛对话数据集,绑定到了文章,大家可以直接使用
1.导入数据集
将准备好的数据集复制到LLaMa-Factory目录下的data文件夹中
2.修改配置文件
复制完成后,需要手动修改配置文件,使其能够发现该数据集
可以使用vim编辑器或者其他自带的编辑器,打开data目录下的dataset_info.json文件,在最后加上该内容
Matlab
"huanhuan_imporve":{
"file_name": "huanhuan_imporve.json"
}huanhuan_improve为你的数据集名称,huanhuan_improve.json是文件夹下数据集的名称
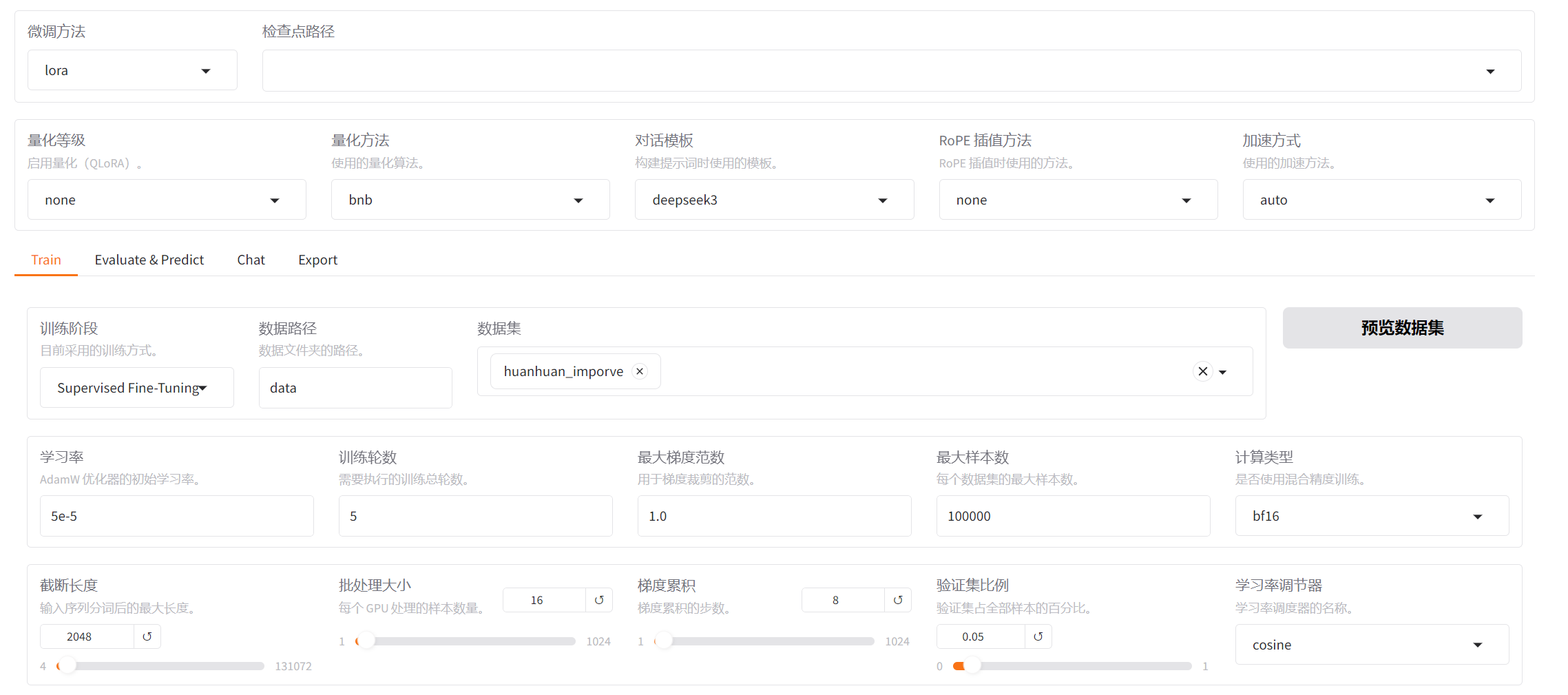
训练模型
1.打开UI界面
修改左上角language为zh,使其变为中文显示
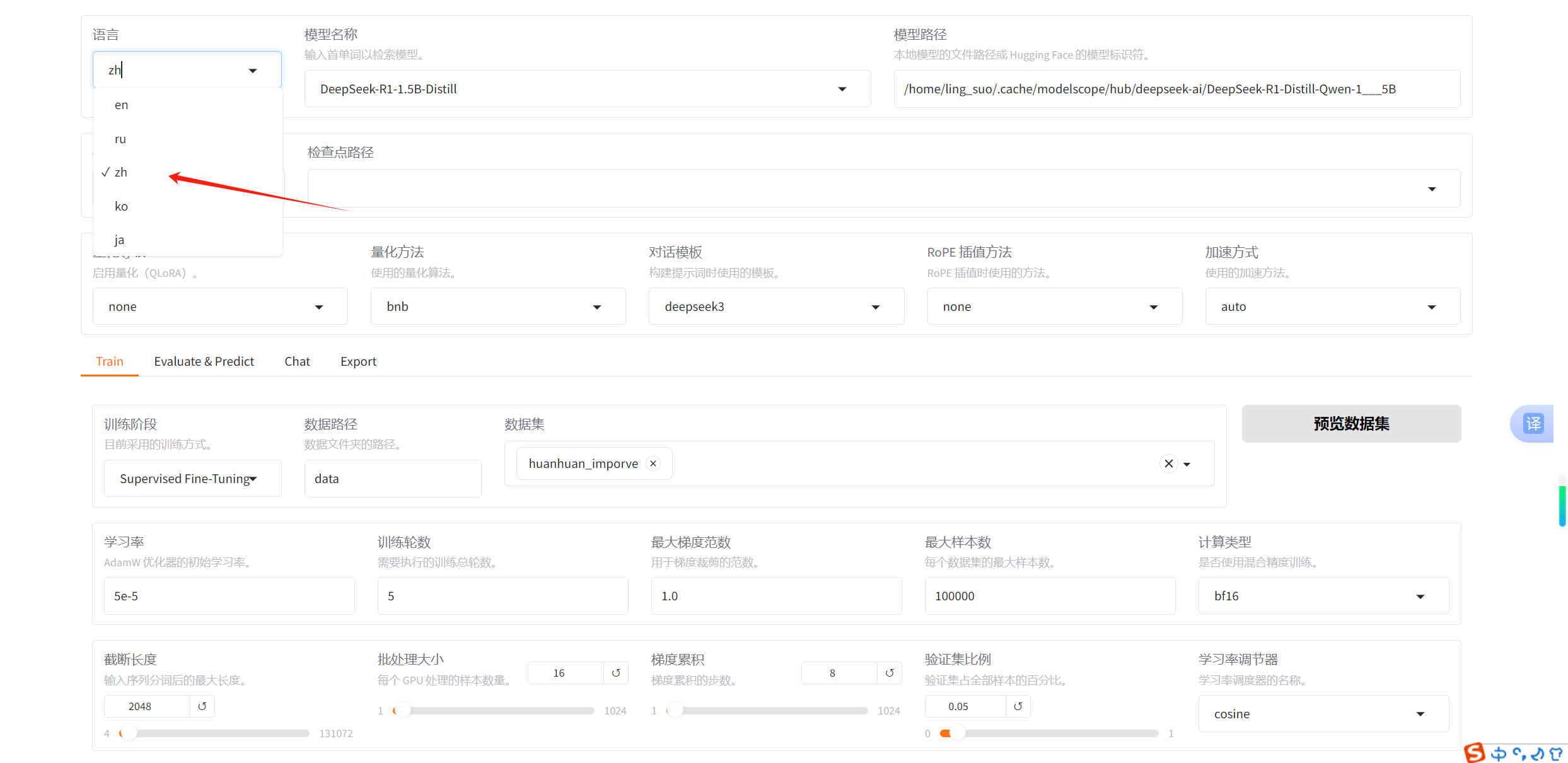
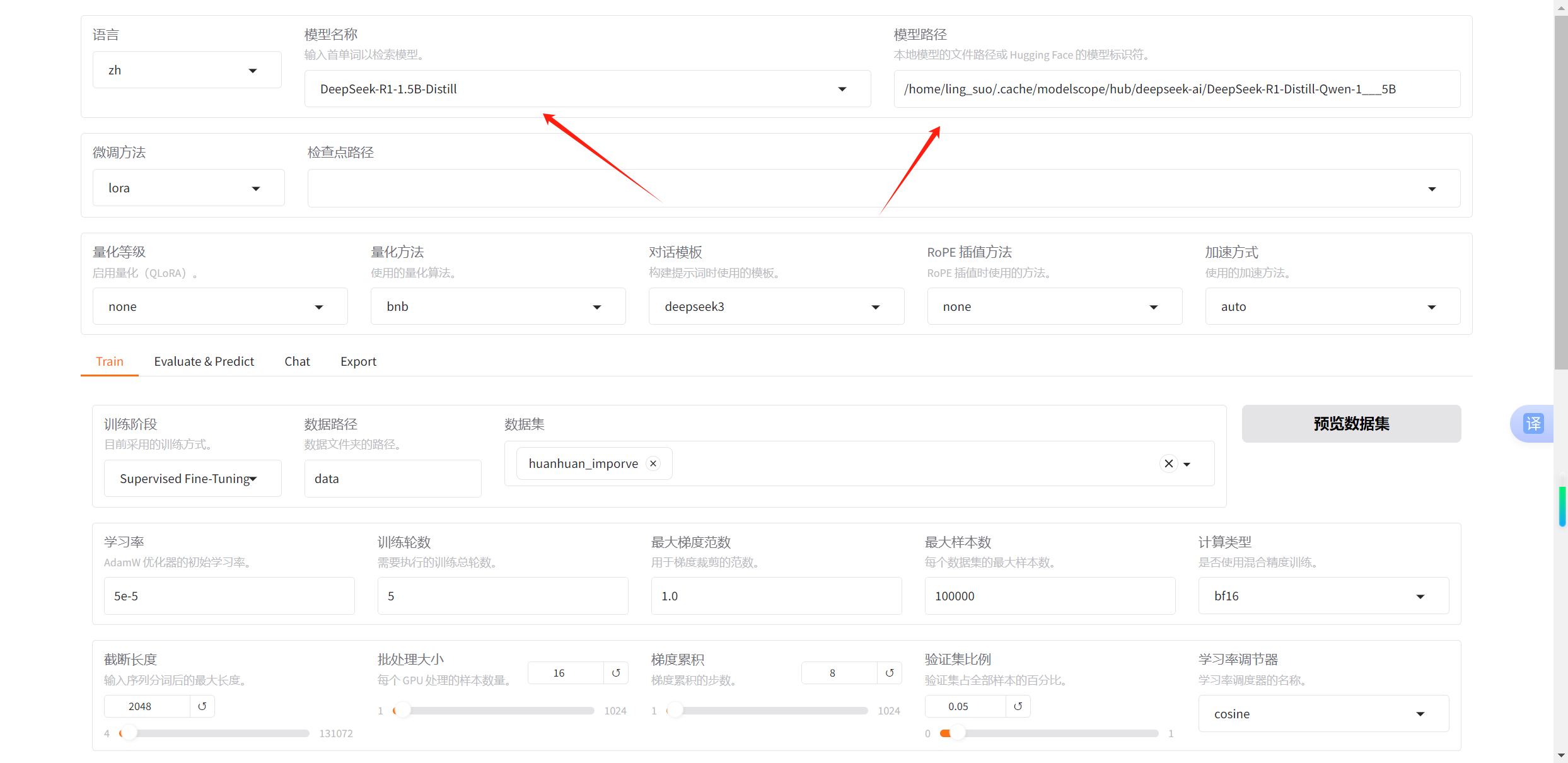
2.指定模型
首先在右侧模型路径选择你下载到本地的模型文件的路径地址
再到中间的模型名称栏选择对应的模型种类
 3.指定训练集
3.指定训练集
在中间部分选择Train,并在旁边"数据集"下拉栏中选择刚刚的新添加数据集。
4.微调方法
微调方法指定lora即可
5.调整参数
学习率:学习率在第一次训练的时候初始温度调整的高一些 5e-5,后续相近类型的训练流程逐步降低温度(如果在训练的过程中出现了损失过高的情况,可以降低温度,比如1e-5,并逐步寻找合适的温度)并配合学习率调度器(cosine/linear)进行训练
训练轮数:如果你的数据集过小,那么训练起来是没什么意义的,很难有效果,数据集偏小的情况,可以将训练轮数调大一些,比如5轮、10轮,数据集很大的情况3轮训练就可以出效果,对于我们选择的数据集我这里建议可以调整为5~7轮
批处理大小:如果你的显存小于24G(4090),那么建议将批处理大小调整为更稳定的16
最大样本数:最大样本数就是你的数据集最大大小,先保持不变
截断长度:截断长度需要根据任务类型和数据集类型进行调整,截断长度越大占用计算资源(显存)就越高,但是可以更好的理解上下文,能捕捉长距离依赖。针对我们这次训练的任务为对话类型,将截断长度调整为2048。如果是一些短文本分类等的任务,可以降低到512。
最大梯度范数:最大梯度范数(梯度裁剪)是为了防止训练过程中梯度爆炸,可在0.5~2.0之间进行调整,若训练过程中出现NaN导致的概率张量异常,可以下降至0.5。
梯度累计:梯度累积保持当前值不变
验证集比例:验证集比例一般在5%~20%,如果数据集很大,则取小值。这里我调整为0.1
学习率调节器:学习率调节器选择consine
计算类型:计算类型根据显存大小,我这里选择bf16,如果显存稍大,可以换为fp16。(但是好像
并没有全精度训练)
当然,如果你有CUDA的话,训练速度会更快
其他的一些参数目前先不用调整(我也得去学习尝试一下)
6.开始训练
模型、数据集、参数都准备完成后,就可以点击下面的"开始"进行训练
验证结果
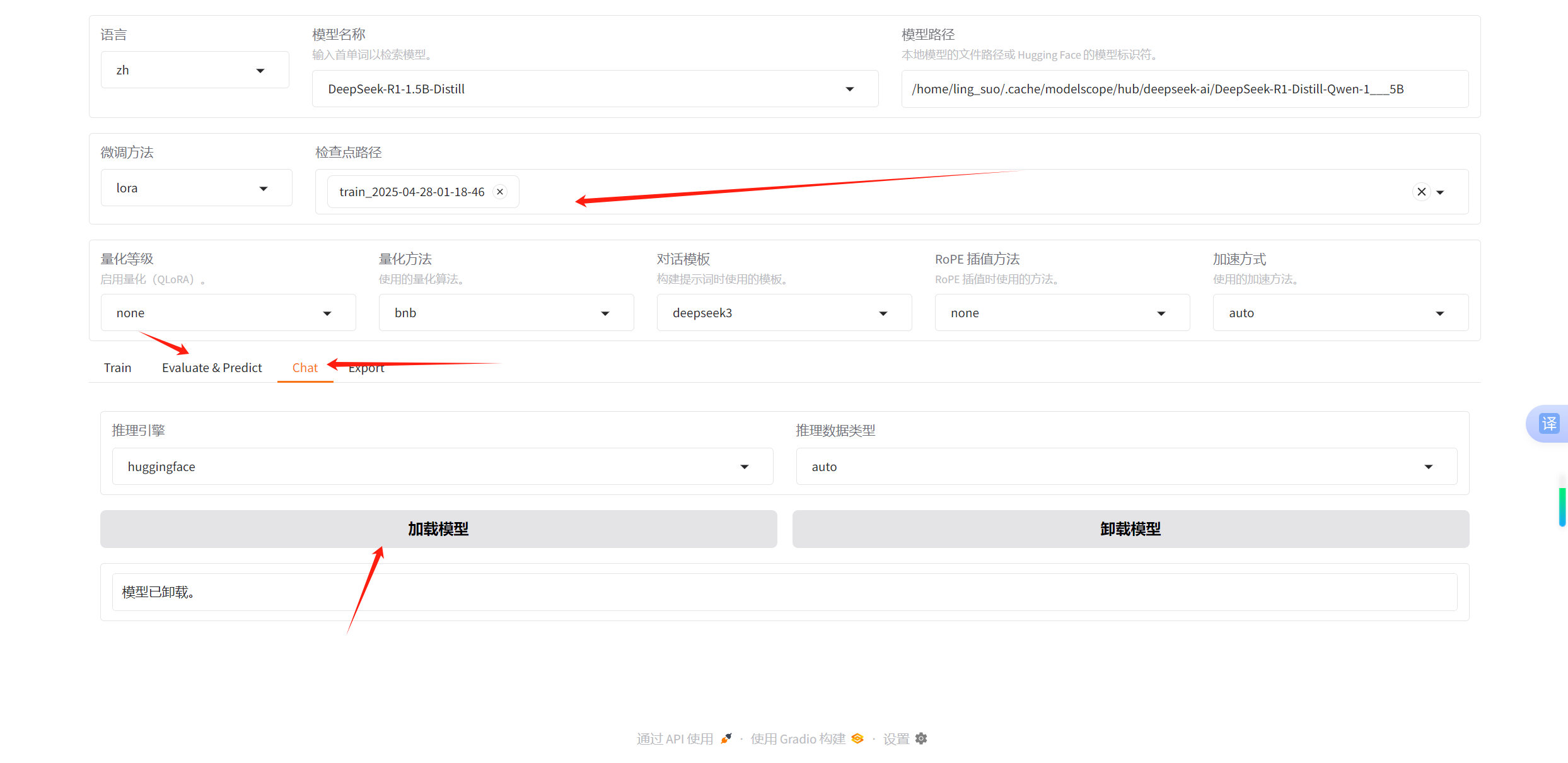
训练完成后,会自动保存一个检查点,其中包括训练之后的参数,所以首先要选择检查点
我们要验证训练的成果可以选择它上面的Evaluate&predict,但是为了简单的测试一下,我们选择Chat进行对话测试
点击Chat,点击加载模型,加载完成后可以开始对话
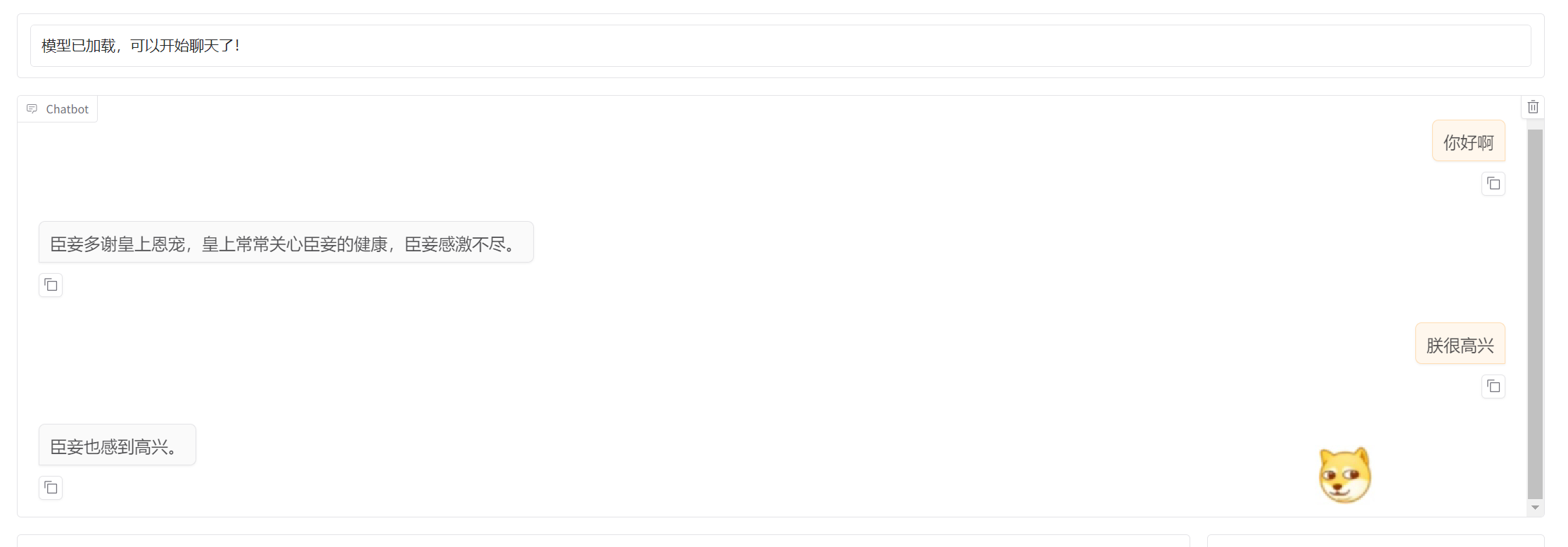
以下是对话效果
通过以上步骤可以实现LLaMA-Factory训练大模型的需求,同样的训练完成后的的模型也可以进行导出,并更灵活的使用,关于这个我将在后续的文章中讲解