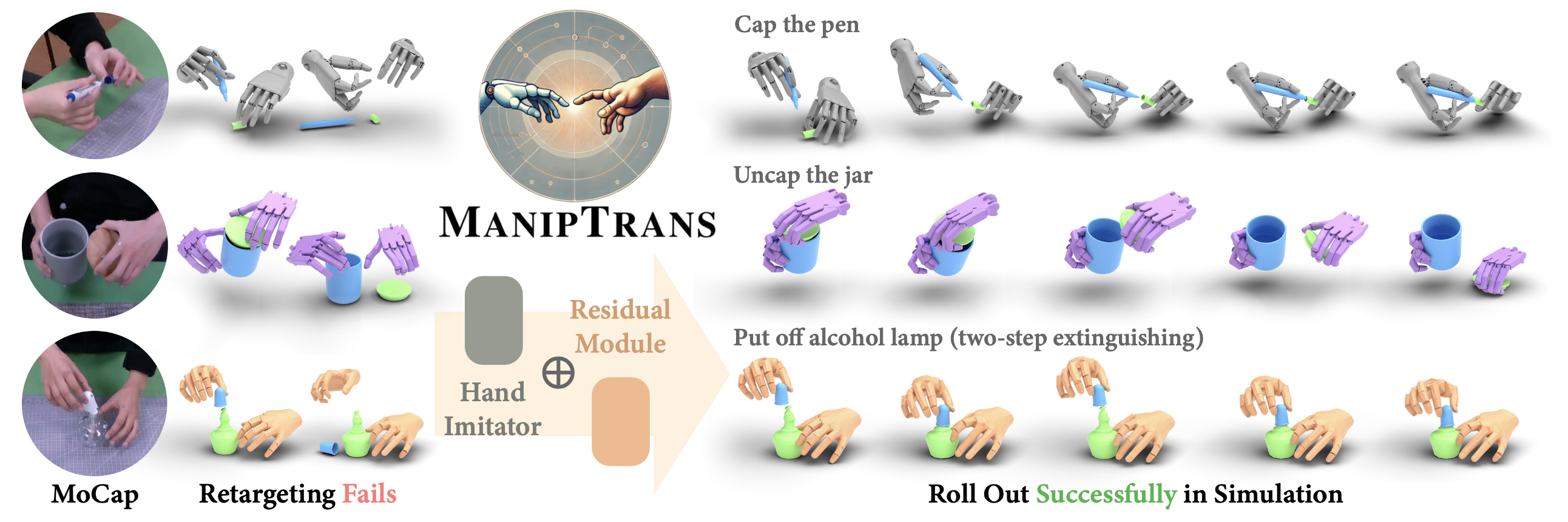
25年3月来自北京通用 AI 国家重点实验室、清华大学和北大的论文"ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning"。
人手在交互中起着核心作用,推动着灵巧机器人操作研究的不断深入。数据驱动的具身智能算法需要精确、大规模、类似人类的操作序列,而这通过传统的强化学习或现实世界的遥操作难以实现。为了解决这个问题,引入 MANIPTRANS,一种两阶段方法,用于在模拟中将人类的双手技能有效地迁移到灵巧的机械手上。MANIPTRANS 首先预训练一个通才轨迹模拟器来模仿手部运动,然后在交互约束下微调特定的残差模块,从而实现高效学习和复杂双手任务的准确执行。实验表明,MANIPTRANS 在成功率、保真度和效率方面均超越最先进的方法。利用 MANIPTRANS,将多个手-目标数据集迁移到机械手,创建 DEXMANIPNET 大型数据集,其中包含一些此前从未探索过的任务,例如盖笔帽(pen capping)和拧开瓶子(bottle unscrewing)。DEXMANIPNET 包含 3.3K 个机器人操作场景,易于扩展,有助于进一步训练灵巧手的策略,并实现实际部署。
近年来,具身人工智能 (EAI) 发展迅速,人们致力于使人工智能驱动的具身能够与物理或虚拟环境交互。正如人手在交互中至关重要一样,EAI 领域的许多研究也聚焦于灵巧机器人手操作 4, 16-- 22, 41, 46, 52, 58, 59, 63, 65, 66, 68, 70, 72, 75, 77, 81, 82, 104, 113, 115, 118, 130, 131。在复杂的双手任务中达到类似人类的熟练程度具有重要的研究价值,对于通用人工智能的进步至关重要。
因此,快速获取精确、大规模、类人灵巧操作序列,用于数据驱动的具身智体训练 11, 12, 25, 83, 133 变得越来越紧迫。一些研究使用强化学习 (RL) 54, 99 来探索和生成灵巧的手部动作 27, 69, 77, 111, 121, 135, 136,而另一些研究则通过遥操作收集人-机配对数据 26, 44, 45, 82, 103, 113, 128。这两种方法都有局限性:传统的 RL 需要精心设计、针对特定任务的奖励函数 78, 135,这限制可扩展性和任务复杂性;而遥操作则是劳动密集型且成本高昂的,只能产生特定于具身智体的数据集。一个有前景的解决方案是通过模仿学习 71, 80, 93, 112, 139 将人类操作动作迁移到模拟环境中的灵巧机械手上。这种方法有几个优点。首先,模仿人类操作轨迹可以创建自然的手部与目标的交互,从而实现更流畅、更像人类的动作。其次,丰富的动作捕捉 (MoCap) 数据集 10, 14, 32, 37, 39, 57, 62, 73, 74, 107, 119, 125, 134 和手势估计技术 13, 43, 67, 87, 108, 120, 122--124, 126 使得从人类演示中提取操作知识变得容易 93, 102。第三,模拟提供一种经济高效的验证方法,为现实世界的机器人部署提供捷径 41, 44, 51。
然而,实现精确高效的迁移并非易事。如图所示,人手和机械手之间的形态差异导致直接的姿态重定向效果不佳。此外,尽管 MoCap 数据相对准确,但在执行高精度任务时,误差累积仍然可能导致严重故障。此外,双手操作引入高维动作空间,显著增加高效策略学习的难度。因此,大多数开创性工作通常停留在单手抓和举的任务 27, 111, 121, 135,而诸如拧开瓶子(bottle unscrewing)或盖笔帽(pen capping)等复杂的双手活动则基本未被探索。
通过人类演示实现灵巧操作。从人类演示中学习操作技能,为将人类能力迁移给机器人提供一种直观有效的方法 6, 31, 129, 132。模仿学习在实现这种迁移方面已显示出巨大的潜力 7, 23, 64, 71, 80, 89, 90, 109, 112, 139, 142。近期研究重点关注学习由目标轨迹引导的强化学习策略 21, 22, 72, 77, 142。QuasiSim 72 通过参数化的准物理模拟器将参考手部动作直接迁移到机械手,从而改进这种方法。然而,这些方法仅限于较简单的任务,并且计算量巨大。最近,针对诸如双手扭开盖子之类的挑战性任务,已经开发出使用特定任务奖励函数的定制解决方案 68, 70。
灵巧手数据集。目标操作是具身智体的基础。目前已有许多基于 MANO 的 96 手-目标交互数据集 9, 10, 14, 28, 32, 36, 37, 39, 40, 42, 55, 57, 60--62, 73, 74, 93, 100, 107, 119, 125, 134, 141, 143。然而,这些数据集通常优先考虑与二维图像的姿态对齐,而忽略物理约束,从而限制它们在机器人训练中的适用性。遥操作方法 26, 44, 45, 92, 113, 117, 128, 140 使用 AR/VR 系统 15, 24, 30, 52, 86 或基于视觉的动作捕捉 (MoCap) 94, 113, 114 在线收集人-机的手匹配数据,以便在人类参与的情况下进行实时数据采集和校正。然而,遥操作劳动密集且耗时,而且缺乏触觉反馈常常会导致动作僵硬、不自然,阻碍精细的操作。
残差学习。由于强化学习训练的样本效率低下和耗时,残差策略学习 53, 98, 106(一种逐步改进动作控制的方法)被广泛采用,以提高效率和稳定性。在灵巧手操作领域,多项研究探索针对特定任务的残差策略 5, 21, 29, 38, 98, 118, 138, 139。例如,38 在残差策略训练期间集成用户输入,而 51 从人类示范中学习纠正动作。GraspGF 118 采用预训练的基于分数生成模型作为基础,21 将模仿任务分解为手腕跟随和手指运动控制,并集成残差手腕控制策略。此外,48 利用残差学习构建一个混合专家系统 49,而 DexH2R 139 将残差学习直接应用于重定向的机器人手动作。
本文提出一种简单但有效的方法,MANIPTRANS,有助于将手部操作技能(尤其是双手动作)迁移到模拟中的灵巧机械手,从而能够准确跟踪参考运动。利用 MANIPTRANS 将多个具有代表性的手-目标操作数据集 62, 134 迁移到 Isaac Gym 模拟器 79 中的灵巧机械手,其构建 DEXMANIPNET 数据集,在运动保真度和顺应性方面取得显著提升。目前,DEXMANIPNET 包含 3.3K 个事件和 134 万帧的机械手操作数据,涵盖此前未曾探索过的任务,例如盖笔帽(pen capping)、拧开瓶盖(bottle unscrewing)和化学实验。
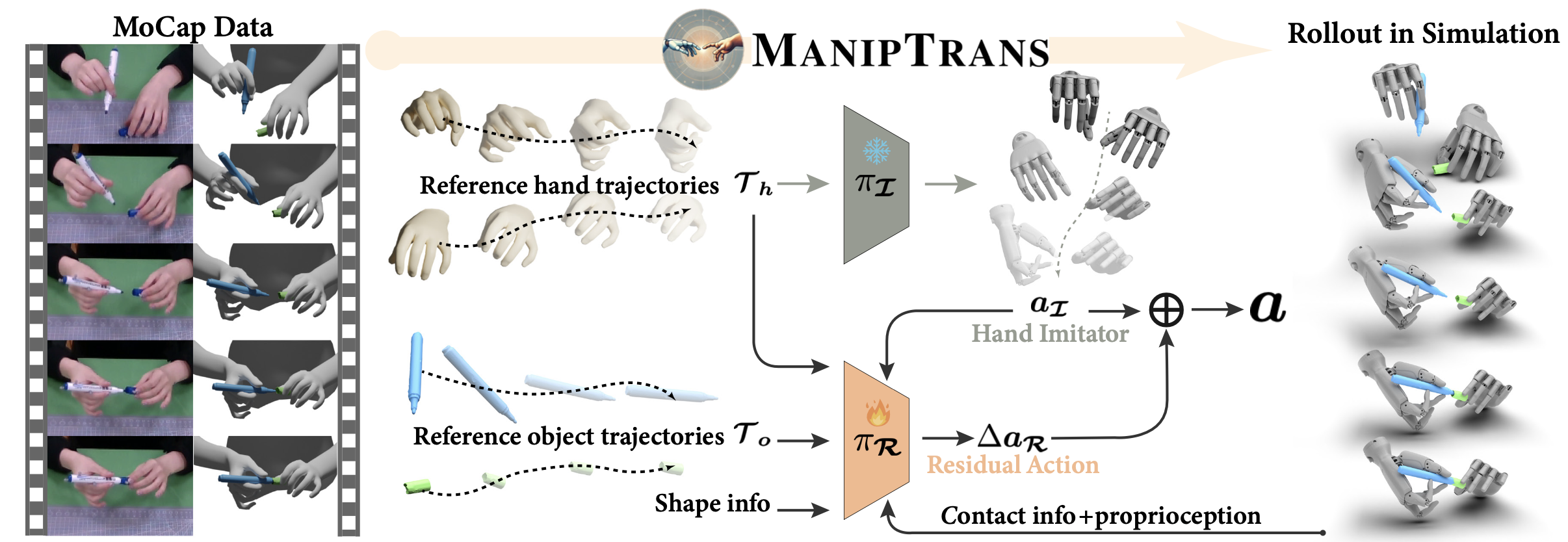
如图所示概述本文方法。给定参考的人手-目标交互轨迹,目标是学习一种策略,使灵巧的机械手能够在模拟中精确复制这些轨迹,同时满足任务的语义操作约束。为此,提出一个两阶段框架:第一阶段训练通用的手部轨迹模仿模型;第二阶段采用残差模型将初始粗略运动细化为符合任务要求的动作。
准备工作
为了不失一般性,在一个复杂的双手环境中构建操作迁移问题。其中左右灵巧手 d = {d_l, d_r} 旨在模拟人手 h = {h_l, h_r} 的行为。人手 h = {h_l, h_r} 与两个目标 o = {o_l, o_r} 以协作的方式进行交互(例如,在笔帽任务中,一只手握住笔帽,另一只手握住笔身)。来自人类演示的参考轨迹定义为 T_h = {τt_h} 和 T_o = {τ^t_o},其中 T 表示总帧数。每只手的轨迹 τ_h 包括手腕的 6-DoF 姿态 w_h、线速度和角速度 w ̇_h = {v_h, u_h},以及由 MANO 96 定义的手指关节位置 j ̇_h,以及它们各自的速度 j ̇_h = {v_j, u_j};这里,F 表示手部关键点的数量,包括指尖。类似地,每个目标的目标轨迹 τ_o 包括其 6-DoF 姿态 p_o 以及相应的线速度和角速度 p ̇_o = {v_o, u_o}。为了降低空间复杂度,对所有相对于灵巧手手腕位置的平移进行归一化,同时保留原始旋转以保持正确的重力方向。
将该问题建模为隐式马尔可夫决策过程 (MDP) M = ⟨S, A, T, R, γ⟩,其中 S 表示状态空间,A 表示动作空间,T 表示转换动力学,R 表示奖励函数,γ 表示折扣因子。每个灵巧手在时间 t 的动作记为 a_t,包括用于比例-微分 (PD) 控制的每个灵巧手关节 at_q 的目标位置(target position),以及施加于机器人手腕的 6-DoF 力 at_w,类似于先前的研究 48, 111, 121,其中 K 表示机器人手旋转关节的总数(即 DoF)。本文方法将迁移过程分为两个阶段:1)预训练的纯手轨迹模仿模型 I;2)残差模块 R,用于微调粗略动作以确保任务合规性。每个阶段在时间 t 的状态分别定义为 st_I 和 st_R,对应的奖励函数分别为 rt_I = R(st_I, at_I) 和 rt_R = R(st_R, a^t_R)。对于这两个阶段,都采用近端策略优化 (PPO) 99 来最大化折扣奖励,这也借鉴先前的方法 19, 89。
手部轨迹模仿
在此阶段,目标是学习一个通用的手部轨迹模仿模型 I,使其能够精确复制人类手指的精细运动。每个灵巧手在时间 t 的状态定义为 st_I = {τt_h, st_prop},其中包括目标手部轨迹 τt_h 和当前本体感觉 st_prop = {qt_d, q ̇t_d, wt_d, w ̇t_d}。其中,qt_d 和 wt_d 分别表示关节角度和手腕姿势,以及它们对应的速度。目标是使用强化学习训练策略 π_I (at | st_I, at−1),以确定动作 a^t_I。
奖励函数。奖励函数 rt_I 旨在鼓励灵巧手跟踪参考手轨迹 τt_h,同时确保稳定性和平滑度。它包含三个部分:1)腕部跟踪奖励 rt_wrist:此奖励最小化差异 wt_d ⊖ wt_h 和 w ̇t_d − w ̇t_h,⊖ 表示 SE(3) 空间中的差异。2)手指模仿奖励 rt_finger:此组件鼓励灵巧手紧密跟随参考手指关节位置。手动选择与 MANO 模型相对应的灵巧手上 F 个手指关键点,表示为 j_d。权重 w_f 和衰减率 λ_f 根据经验设置,以强调指尖,特别是拇指、食指和中指的指尖。这种设计有助于减轻人手和机器手之间形态差异的影响。3) 平滑度奖励 rt_smooth:为了缓解运动不顺畅的问题,引入平滑度奖励,惩罚施加在每个关节上的力,其定义为关节速度和力矩的逐元乘积,类似于 76 中的方法。总奖励定义为:rt_I = w_wrist · rt_wrist + w_finger · rt_finger + w_smooth · r^t_smooth。
训练策略。将手的模仿与目标交互分离,提供额外的优势;具体来说,π_I 不需要难以获取的操作数据。使用纯手数据集训练该策略,包括现有的手动作集合 14, 36, 62, 107, 134, 137, 144 和通过插值生成的合成数据 105。为了平衡左右手之间的训练数据,将这些数据集镜像。为了提高效率,采用参考状态初始化 (RSI) 和提前终止 88, 89 的技术。如果灵巧手关键点 j_d 的偏差超过阈值 ε_finger,则该回合将提前终止并重置为随机采样的 MoCap 状态。还利用课程学习 8,逐渐降低 ε_finger 以鼓励广泛的探索,然后专注于细粒度的手指控制。
残差学习在交互中的应用
基于预训练的π_I,使用残差模块 R 来细化粗略动作并满足特定任务的约束。
状态空间扩展在交互中的应用。为了解释灵巧手与目标之间的交互,通过合并与交互相关的其他信息,将状态空间扩展到手相关状态st_I之外。首先,从 MoCap 数据中计算物体网格 o 的凸包116,以在模拟环境中生成可碰撞目标 oˆ。为了沿着参考轨迹 T_o 操纵目标,引入目标的位置 p_oˆ(相对于手腕位置 w_d)和速度 p ̇_oˆ、质心m_oˆ 和重力矢量 G_oˆ。为了更好地编码目标的形状,利用 BPS 表征91。此外,为了增强感知,使用距离度量 D(j^t_d, p^t_oˆ) 来编码双手与目标之间的空间关系,该度量测量灵巧手关键点与目标位置之间的平方欧氏距离。此外,还明确包含从模拟中获得的接触力 C,以捕捉指尖与目标表面之间的相互作用。这种触觉反馈对于稳定的抓握和操控至关重要,可确保在复杂任务中实现精确控制。
残差动作组合策略。给定组合状态 st_R = st_I ∪ st_interact,目标是学习残差动作 ∆at_R,以改进初始模仿动作 at_I,确保符合任务要求。在操作过程的每个步骤中,首先采样模仿动作 at_I ∼ π_I (at |st_I, at−1)。在此动作的条件下,再采样残差校正 ∆at_R ∼ π_R (∆at |st_R, at_I, at−1)。最终动作计算为:at = at_I + ∆at_R,其中残差动作逐元素相加。然后对得到的动作 a^t 进行裁剪,使其符合灵巧手的关节极限。在训练开始时,由于灵巧手动作已经近似于参考手轨迹,因此残差动作预计接近于零。这种初始化有助于防止模型崩溃并加速收敛。通过使用零均值高斯分布初始化残差模块,并采用预热策略逐步激活其训练,来实现这一点。
奖励函数。目标是以与任务无关的方式将人类的双手操作技能高效地迁移到灵巧的机械手上。为此,避免针对特定任务的奖励工程,尽管这有利于单个任务,但可能会限制泛化。因此,奖励设计保持简单且通用。除了手模仿奖励 rt_I 之外,还引入两个附加组件:1) 目标跟踪奖励 rt_object:最小化模拟目标与其参考轨迹之间的位置和速度差异,具体而言,pt_oˆ ⊖ pt_o 和 p ̇t_oˆ − p ̇t_o。 2) 接触力奖励 rt_contact:当 MoCap 数据集中手与目标之间的距离低于指定阈值 ξ_c 时,鼓励施加适当的接触力。该奖励取决于 D(jt_h_f, pt_o · o),即指尖 h_f 与变换后的目标表面之间最小距离,和 Ct_d_f,即指尖处的接触力。残差阶段的总奖励定义为 rt_R = rt_I + w_object · rt_object + w_contact · r^t_contact。
训练策略。受先前研究 72, 84, 85 的启发,该研究利用准物理模拟器在训练过程中放松约束并避免局部最小值,在残差学习阶段引入一种放松机制。与采用自定义模拟的 72 不同,其直接在 Isaac Gym 环境 79 中调整物理约束,以提高训练效率。具体来说,最初将引力常数 G 设置为零,并将摩擦系数 F 设置为一个较高的值。这种设置使机械手在训练早期能够牢固地抓握目标并有效地与参考轨迹对齐。随着训练的进展,逐渐将 G 恢复到其真实值,并将 F 降低到合适的值,以近似真实的交互。与模仿阶段类似,采用 RSI、提前终止和课程学习策略。每个episode 都通过从预处理轨迹中随机选择一个非碰撞的近目标状态来初始化机械手。在训练期间,如果目标的姿态 pt_oˆ 偏离预定义阈值 ε_object,则 episode 会提前终止。逐步降低 ε_object 以鼓励更精确的目标操作。此外,引入接触终止条件:如果 MoCap 数据显示人手牢牢抓握(即 D(jt_h_f, pt_o · o) < ξ_t,其中 ξ_t 为终止阈值),则接触力 C^t_d_f 必须非零。不满足此条件则会导致提前终止。此机制确保智体学习控制接触力,从而实现稳定的目标操控。
DEXMANIPNET 数据集
使用 MANIPTRANS 生成 DEXMANIPNET 数据集,该数据集源自两个具有代表性的大规模手-目标交互数据集:FAVOR 62 和 OakInk-V2 134。FAVOR 采用基于 VR 的遥操作技术,并结合人-在-环校正,专注于目标重排列等基础任务。相比之下,OakInk-V2 采用基于光学追踪的动作捕捉技术,专注于更复杂的交互,例如盖笔帽和拧开瓶子。
由于灵巧机械手缺乏标准化,采用 Inspire Hand 3 作为主要平台,因为它具有高灵活性、稳定性、成本效益以及广泛的先前应用 24, 35, 52。为了解决双手任务的复杂性,采用模拟的 12 自由度 Inspire Hand 配置,与现实世界的 6 自由度机制相比,其灵活性更高。
DEXMANIPNET 涵盖 134 中定义的 61 个多样化且具有挑战性的任务,包括 3.3K 个机械手操作场景,涉及 1.2K 个目标,总计 134 万帧,其中包括 ∼ 600 个涉及复杂双手任务的序列。每个场景在 Isaac Gym 模拟中执行精确 79。相比之下,最近通过自动增强生成的数据集 52 仅包含 9 个任务的 60 个来源人类演示。
在 MANIPTRANS 中,对每个灵巧机械手,手动选择 F = 21 个关键点,分别对应人手的指尖、手掌和指骨位置,以减轻形态差异。对于训练,用课程学习策略。初始阈值 ε_finger 设置为 6 厘米,然后衰减到 4 厘米。目标对齐阈值 ε_object 起始于 90° 和 6 厘米(用于旋转和平移),逐渐减小到 30° 和 2 厘米。用 Actor-Critic PPO 算法 99 训练模仿模块 I 和残差模块 R,训练范围为 32 帧,小批量大小为 1024,折扣因子 γ = 0.99。优化采用 Adam 56,初始学习率为 5 × 10^−4,并采用衰减调度程序。所有实验均在 Isaac Gym 79 中进行,在配备 NVIDIA RTX 4090 GPU 和 Intel i9-13900KF CPU 的个人计算机上以 1/60 秒的时间步长模拟 4096 个环境。
如图所示,使用两个 7 自由度 Realman 机械臂 95 和一对升级版 Inspire 机械手(配置相同,但增加触觉传感器)进行实验。为了弥补模拟的 12 自由度机械手与 6 自由度真实硬件之间的差距,采用一种基于拟合的方法,优化真实机器人的关节角度 q_d ̃(表示为 ̃·)以实现指尖对齐,并额外增加时间平滑度损失。通过求解逆运动学来控制机械臂,使机械臂的凸缘(flange)与灵巧手的手腕 w_d 对齐。在回放过程中,不会强制执行严格的时间对齐,因为真实机器人的操作速度并不总是像人手那样快。
