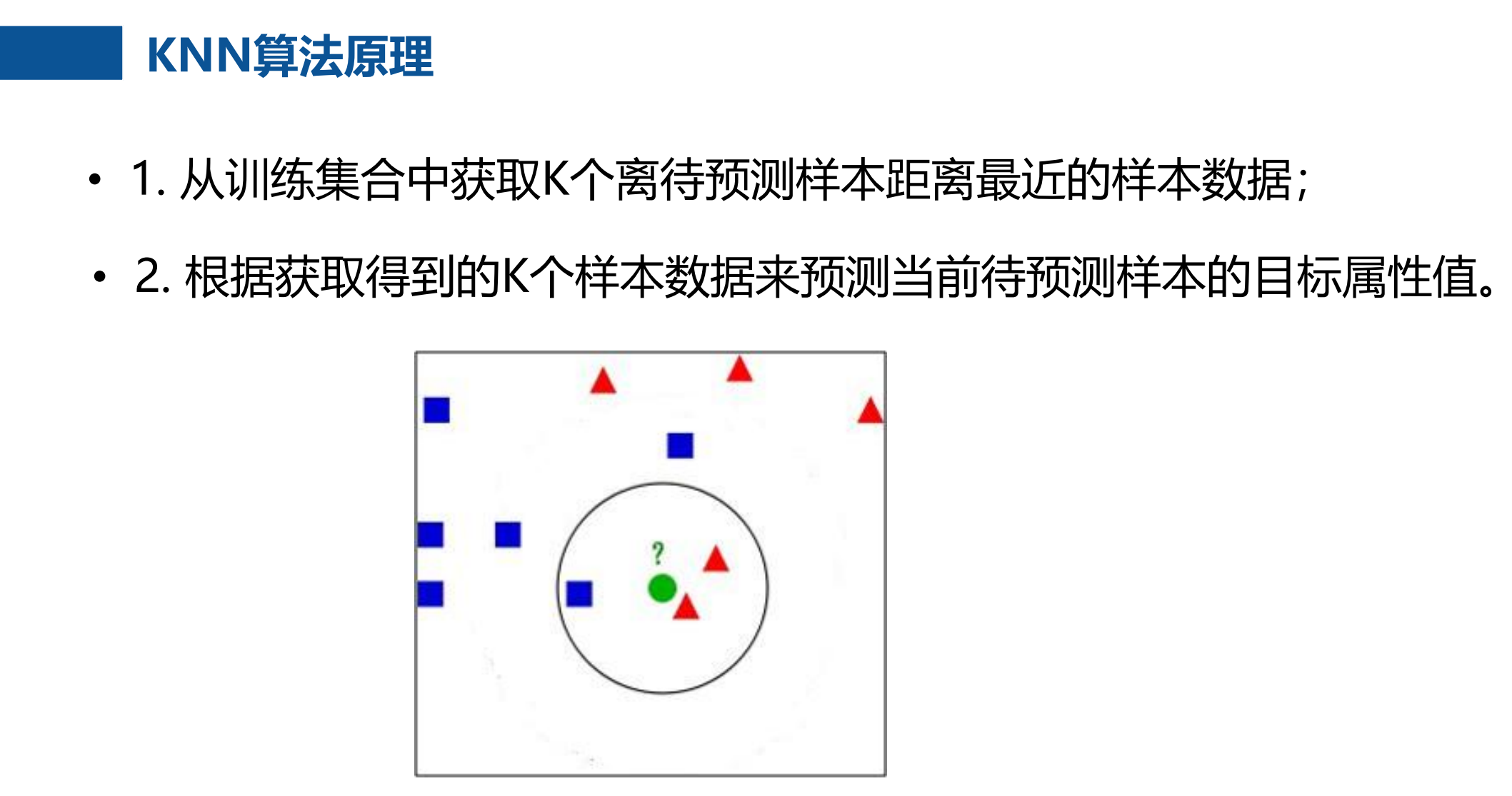
K近邻(K-nearst neighbors, KNN)是一种基本的机器学习算法,所谓k
近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的
k个邻居来代表。比如:判断一个人的人品,只需要观察与他来往最密切
的几个人的人品好坏就可以得出,即"近朱者赤,近墨者黑";KNN算
法既可以应用于分类应用中,也可以应用在回归应用中。
KNN在做回归和分类的主要区别在于最后做预测的时候的决策方式不同。
KNN在分类预测时,一般采用多数表决法;而在做回归预测时,一般采
用平均值法。
在KNN算法中,非常重要的主要是三个因素:
• K值的选择:对于K值的选择,一般根据样本分布选择一个较小的值,然后
通过交叉验证来选择一个比较合适的最终值;当选择比较小的K值的时候,
表示使用较小领域中的样本进行预测,训练误差会减小,但是会导致模型变
得复杂,容易过拟合;当选择较大的K值的时候,表示使用较大领域中的样
本进行预测,训练误差会增大,同时会使模型变得简单,容易导致欠拟合;
• 距离的度量:一般使用欧氏距离(欧几里得距离);
• 决策规则:在分类模型中,主要使用多数表决法或者加权多数表决法;在
回归模型中,主要使用平均值法或者加权平均值法。


KNN算法的重点在于找出K个最邻近的点,主要方式有以下几种:
• 蛮力实现(brute):计算预测样本到所有训练集样本的距离,然后选择
最小的k个距离即可得到K个最邻近点。缺点在于当特征数比较多、样本
数比较多的时候,算法的执行效率比较低;
• KD树(kd_tree):KD树算法中,首先是对训练数据进行建模,构建KD
树,然后再根据建好的模型来获取邻近样本数据。
• 除此之外,还有一些从KD_Tree修改后的求解最邻近点的算法,
比如:Ball Tree、BBF Tree、MVP Tree等。
KNN暴力写法
python
import numpy as np
import pandas as pd
# 初始化数据
T = [[3, 104, -1],
[2, 100, -1],
[1, 81, -1],
[101, 10, 1],
[99, 5, 1],
[98, 2, 1]]
# 初始化待测样本
x = [18, 90]
# 初始化邻居数
K = 5
# 初始化存储距离列表 [[距离 1,标签 1], [距离 2,标签 2]....]
list_distance = []
# 循环每一个数据点,把计算结果放入 dis
# i 是每条电影的数据
for i in T:
# print(np.array(i[:-1])) # [ 3 104]
# diff = np.array(i[:-1]) - np.array(x)
# print(diff) # [-15 14]
# squr = (np.array(i[:-1]) - np.array(x)) ** 2 # numpy 数组求平方
# print(squr) # [225 196]
# dis = np.sum((np.array(i[:-1]) - np.array(x)) ** 2) ** 0.5 # 欧式距离(1)
dis = np.linalg.norm(np.array(i[:-1], dtype=np.float32) - np.array(x, dtype=np.float32)) # 推荐
list_distance.append([dis, i[-1]])
print("排序前列表:\n", list_distance)
# 对 dis 按照距离排序
list_distance.sort()
print("排序后列表:\n", list_distance)
# 将前 K 个票放入投票箱
# print(list_distance[:K])
arr = np.array(list_distance[:K])[:, -1]
print("K个最近的邻居的投票:", arr)
# 产生结果
a = pd.Series(arr).value_counts() # 计算各个唯一值的频数
print("统计投票:\n", a, sep='')
print("预测值:", a.idxmax()) # 返回具有最大值的元素的索引、
#加权的写法
values = [1 / i[0] * i[1] for i in list_distance[:K]]
pre = -1 if sum(values) < 0 else 1 # 投票值之和 < 0,说明投票 -1 的权重更多
print(pre)KNN调包写法
python
import numpy as np
import pandas as pd
from sklearn import neighbors
# 初始化数据
T = [[3, 104, 98],
[2, 100, 93],
[1, 81, 95],
[101, 10, 16],
[99, 5, 8],
[98, 2, 7]]
# 初始化待测样本
x = [[18, 90]]
# x =[[50, 50]]
# 初始化邻居数
K = 5
data = pd.DataFrame(T, columns=['A', 'B', 'label'])
# print(data)
X_train = data.iloc[:, :-1]
# print(X_train)
Y_train = data.iloc[:, -1]
# print(Y_train)
x = pd.DataFrame(x, columns=['A', 'B'])
# 实例化 KNN 回归模型
KNN03 = neighbors.KNeighborsRegressor(n_neighbors=K)
KNN03.fit(X_train, Y_train)
y_predict = KNN03.predict(x)
print("等权回归:", y_predict)
# 实例化 KNN 回归模型
# weights='distance': 使用距离的倒数作为权重
KNN04 = neighbors.KNeighborsRegressor(n_neighbors=K, weights='distance')
KNN04.fit(X_train, Y_train)
y_predict = KNN04.predict(x)
print("加权回归:", y_predict)