
1.消费者协调器和组协调器
如果消费者客户端中配置了多个分配策略,则多消费者的分区分配交由消费者协调器和组协调器来完成,他们之间使用一套组协调协议进行交互。
1.1.在均衡原理
将全部消费者分成多个子集,每个消费者组的子集在服务中对应一个GroupCoordinator对起进行管理,GroupCoordinator是kafka服务端中用于管理消费组的组件。而消费者客户端中的ConsumerCoordinator组件负责与GroupCoordinator进行交互。
GroupCoordinator+ConsumerCoordinator组重要的职责就是负责执行消费者在均衡操作。
1.1.1.触发在均衡情形
- 有新的消费者加入消费组
- 有消费者宏机下线
- 有消费者主动退出消费组
- 消费组对应的ConsumerCoordinator节点发生了变更
- 消费组内所订阅的任意主题或主题的分区数发生变化
1.1.2.在均衡操作的主要内容
-
第一阶段:
FINO_COORDINATOR消费者需要确认它所属的消费组对应的
GroupCoordinator所在的broker,并创建与该broker相互通信的网络连接。如消费者已经保存了与消费者组对应的GroupCoordinator节点的信息,并且与他的网络连接是正常的,那么可进入第二阶段。否则就要想集群中的某个节点(负载最小的节点)发送FindCoordinatorRequest请求来查找对应的GroupCoordinator。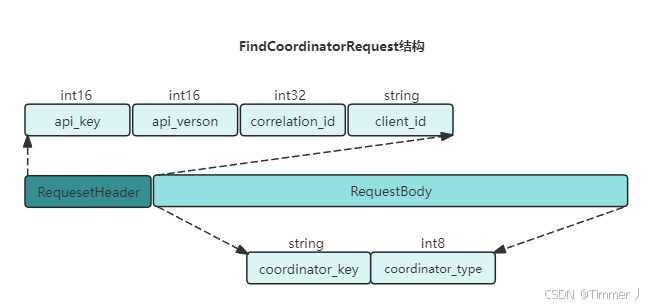
- coordinator_key:在这里就是消费组的名称,即groupId
- coordinator_type:置为0
kafka在收到FindCoordinatorRequest请求后会根据coordinator_key查找对应的GroupCoordinator节点,如果找到对应的GroupCoordinator则会返回其相对应的node_id、host和port信息。
具体查找GroupCoordinator的方式:
- 先根据消费组groupId的哈希值计算
_consumer_offfsets中的分区编号,具体算法:Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCountgroupMetadataTopicPartitionCount为主题_consumer_offsets的分区个数,可以通过broker端参数offsets.topic.num.partitions来配置,默认为50. - 然后根据
_consumer_offsets对应的分区寻找此分区leader副本所在的broker节点,该borker节点即为这个groupId对应的GroupCoordinator节点 消费者groupId最终的分区分配方案计组内消费者所提交的消费位移信息都会发送给此分区leader副本所在的broker节点,让此broker节点即扮演GroupCoordinator的角色,有扮演保存分区分配方案和组内消费者位移的角色,以此可省去很多不必要的中间轮转所带来的消耗。
-
第二阶段:
JOIN_GROUP在成功找到消费组所对应的GroupCoordinator之后就进入加入消费组的阶段,在此阶段的消费者会向GroupCoordinator发送JoinGroupRequest请求并处理响应。
选举消费组的leader:GroupCoordinator需要为消费组内的消费者选举出一个leader,选举算法分为两种情况。
- 消费组内无leader,则第一个加入的为leader
- 如果某一时刻leader消费者由于某些原因退出了消费组,则会重新选举一个新的leader,方法为随机选举
选举分区分配策略:
每个消费者都可以设置自己的分区分配策略,则组内最终选举的分配策略基本上可以看作被各个消费者支持的最多的策略,具体过程如下
- 收集各个消费者支持的所有分配策略组成候选集candidates
- 每个消费者从候选集candidates中找出第一个自身支持的策略,为每个策略投上一票
- 计算候选集中各个策略的选票数,选票最多的策略即为当前消费组的分配策略
如有消费者不支持选出的分配策略,则抛出异常
-
第三阶段:
SYNC_GROUPleader消费者根据在第二阶段中选举出来的分区分配策略来实施具体的分区分配。在此之后需将分配的方案同步给各个消费者,此时leader消费者并不是直接和其余的普通消费者同步分配方案,而是通过
GroupCoordinator这个"中间人"来负责转发同步分配方案的。在第三阶段,也就是同步阶段,各个消费者会向GroupCoordinator发送SyncGroupRequest请求来同步分配方案。
SyncGroupRequest具体结构: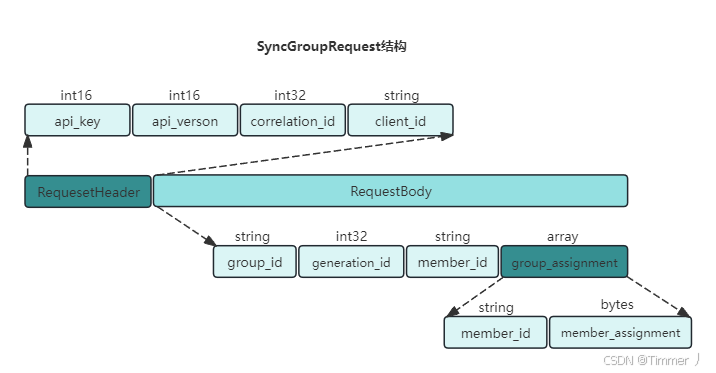
group_assignment是一个数组类型,其中包含了各个消费者对应的具体分配方案:member_id表示消费者的唯一标识,member_assignment是与消费者对应的分配方案,还可以做更具体的划分。member_assignment结构图:
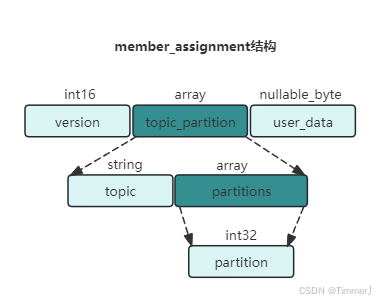
服务端在接受到消费者发送的
SyncGroupRequest请求后会交给GroupCoordinator来负责具体的的逻辑处理。GroupCoordinator处理逻辑:
- 对
SyncGroupRequest请求做合法性校验 - 提取leader消费者发送过来的分配方案并连同整个消费组的元数据信息一起存入Kafka的
_consumer_offsets主题中 - 最后发送响应(
SyncGroupResponse)给各个消费者以提供个各个消费者各自所属的分配方案
- 对
-
第四阶段:
HEARTBEAT进入这个阶段后,消费组中的所有消费者就会处于正常工作状态。在正式消费之前,消费者还需要确定拉取信息的起始位置 (上次提交的位置)。
消费者通过向
GroupCoordinator发送心跳来维持它们与消费组的从属关系,以及它们对分区的所有权关系心跳线程是一个独立的线程,可以在轮询消息的空挡发送心跳。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区中的消息。
心跳间隔时间由参数
heartbeaat.interval.ms指定,默认值为3000(3秒)。这个时间必须比
session.timeout.ms参数设定的值要小 ,一般设定不能超过其1/3,也可以设定的更小,以控制正常重新平衡的逾期时间。max.poll.interval.ms参数用来指定消费者组管理时poll()方法调用之间的最大延迟,也就是消费者在获取更多消息之前可以空闲的时间上限。如果此超时时间期满之前poll()没有调用,则消费者被认为失败,并且分组将重新平衡,以便将分区重新分配给别的成员。
LeaveGroupRequest请求可以主动退出消费组,如客户端调用unsubscrible()方法取消对某些主题的订阅。
2._consumer_offsets剖析
_consumer_offsets是Kafka的内部主题,用于存储消费者组的偏移量(offset)信息,是Kafka实现消息可靠传递的关键组件。
一般情况下,当集群中第一次有消费者消费消息时会自动创建主题__consumer_offsets,其副本因子 还受
offsets.topic.num.partitions.factor参数的约束,此参数默认为3,分区数 可以通过offsets.topic.num.partitons参数设置,默认为50。
- 作用和背景
- 偏移量管理:消费者需要记录消费进度(即分区中已处理的最新消息位置),__consumer_offsets负责持久化这些信息,确保消费者重启或故障后能恢复进度。
- 替代ZooKeeper:早期Kafka版本将偏移量存储在ZooKeeper中,但随消费者规模增长,ZooKeeper的写入瓶颈显现。从Kafka 0.9版本起,偏移量迁移至__consumer_offsets,利用Kafka自身的高吞吐和分区能力提升扩展性。
2.1.OffsetCommitRequest
客户端提交消费位移是使用OffsetCommitRequest请求实现的,其UML图如下:
contains contains (topics) contains (partitions) OffsetCommitRequest +int16 apiKey = 0x0008 +int16 apiVersion +int32 correlationId +string clientId +RequestBody requestBody RequestBody +string groupId +int32 generationId +string memberId +int64 retentionTime +List<TopicData> topics TopicData +string topic +List<PartitionData> partitions PartitionData +int32 partition +int64 offset +int32 leaderEpoch +string metadata +int64 timestamp
-
类关系:
OffsetCommitRequest包含一个RequestBody。RequestBody包含多个TopicData(通过 topics 字段)。- 每个
TopicData包含多个PartitionData(通过 partitions 字段)。
-
字段类型:
- 基本类型(如 int32, string)直接标注。
- 集合类型用 ListT 表示(例如 ListTopicData)。
-
关键字段:
- 公共头部字段
API Key: 固定为0x0008,标识这是一个OffsetCommit请求。
API Version: 决定请求的格式兼容性(不同版本的Kafka可能扩展字段)。
Correlation ID: 客户端生成的唯一ID,用于跟踪请求与响应的对应关系。
Client ID: 客户端的逻辑标识,用于服务端日志监控。 - 请求体字段
group_id: 消费者组唯一标识,对应group.id配置。
generation_id: 消费者组的"年代号",在Rebalance操作后递增。用于防止已退组的消费者提交过期偏移量。
member_id: 消费者在组内的唯一ID,由Broker分配。
retention_time: 旧版本(如v0, v1)中用于指定偏移量保留时间,新版本中由Broker配置决定。
topics: 待提交偏移量的主题列表,每个主题包含多个分区的偏移量数据。 - PartitionData字段
partition: 目标分区编号。
offset: 消费者提交的当前消费进度(即下一条待处理消息的位置)。
leader_epoch: 用于处理副本故障恢复时的数据一致性(Kafka 0.11+引入)。
metadata: 可选的附加信息(如提交者的客户端版本)。
timestamp: 旧版本中用于指定偏移量时间戳,新版本由Broker自动填充。
- 公共头部字段
不同版本的OffsetCommitRequest可能有字段变化:
版本 重要变化 v0 基础版本,无leader_epoch字段 v1 新增retention_time字段 v2 引入leader_epoch,删除timestamp字段 v3+ 优化字段编码,支持更严格的校验
2.2.请求流程
-
消费者提交偏移量
消费者调用
commitSync()或commitAsync()时,构造OffsetCommitRequest,按上述格式编码为二进制数据,发送给Broker。 -
Broker处理逻辑
Broker 将偏移量写入内部主题__consumer_offsets,并根据请求中的generation_id和member_id验证提交合法性。 -
响应返回客户端
Broker 返回OffsetCommitResponse,包含每个分区的提交结果(成功或错误码)。