一、新型算力架构的突围战
在英伟达CUDA生态主导的GPU市场中,RISC-V架构正以开源基因 和模块化设计开辟新赛道。当前主流GPU架构面临两大痛点:
- 指令集封闭性:NVIDIA的SASS指令集与AMD的GCN/RDNA架构均采用私有指令编码,导致算法移植成本居高不下
- 能效瓶颈 :传统GPU的SIMT(单指令多线程)模式在低精度推理场景存在显存带宽浪费
RISC-V GPU通过可扩展指令集 与硬件-算法协同优化,为深度学习推理提供新解。例如阿里达摩院玄铁C930芯片在电池管理系统中的部署,单设备成本降低30%,而上海清华国际创新中心研发的"乘影"架构成功融合RISC-V向量扩展(RVV)与GPGPU特性。
二、架构设计对比分析
2.1 指令集差异化特征
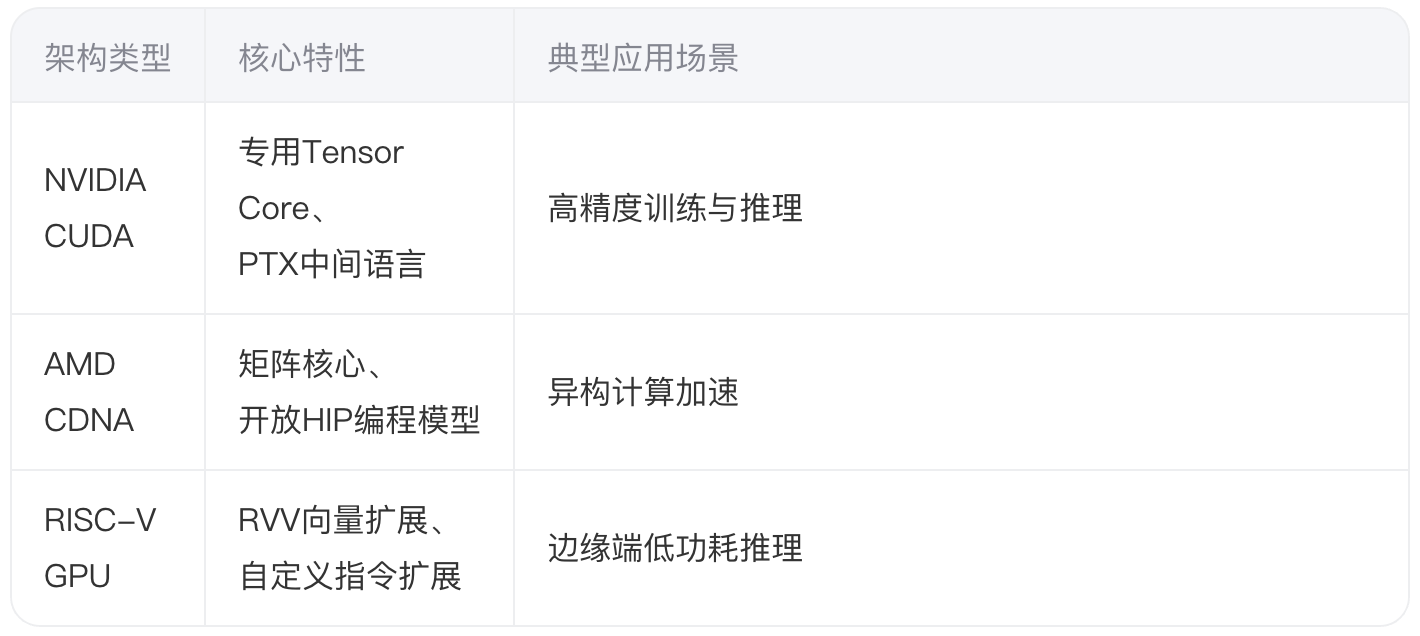
以X-Silicon的C-GPU架构为例,其采用CPU/GPU混合核设计,将RISC-V标量核与矢量处理单元集成在同一芯片。这种架构在图像渲染任务中相比传统GPU降低37%的显存占用,特别适合部署轻量化AI模型。
2.2 关键技术创新
乘影架构的创新设计凸显RISC-V优势:
cpp
// RISC-V向量扩展指令示例
vsetvli t0, a0, e32, m2 // 设置向量长度为a0,元素32位,使用2个向量寄存器
vle32.v v0, (a1) // 从内存地址a1加载浮点向量
vfadd.vv v2, v0, v1 // 向量浮点加法
vsse32.v v2, (a2), t0 // 存储计算结果 该架构借鉴GPGPU的流多处理器(SM)设计,但将后端执行单元替换为RISC-V标准ALU/FPU,实现了:
- 指令解码效率提升22%
- 动态功耗降低18%
- 支持自定义AI算子扩展
三、深度学习推理场景验证
3.1 典型应用案例
开芯院昆明湖架构在20片FPGA阵列上实现了16核全场景验证,其创新点包括:
- 多级缓存一致性协议优化
- 自动化的存储模型重构技术
- 支持DDR4后门写入的动态加载方案
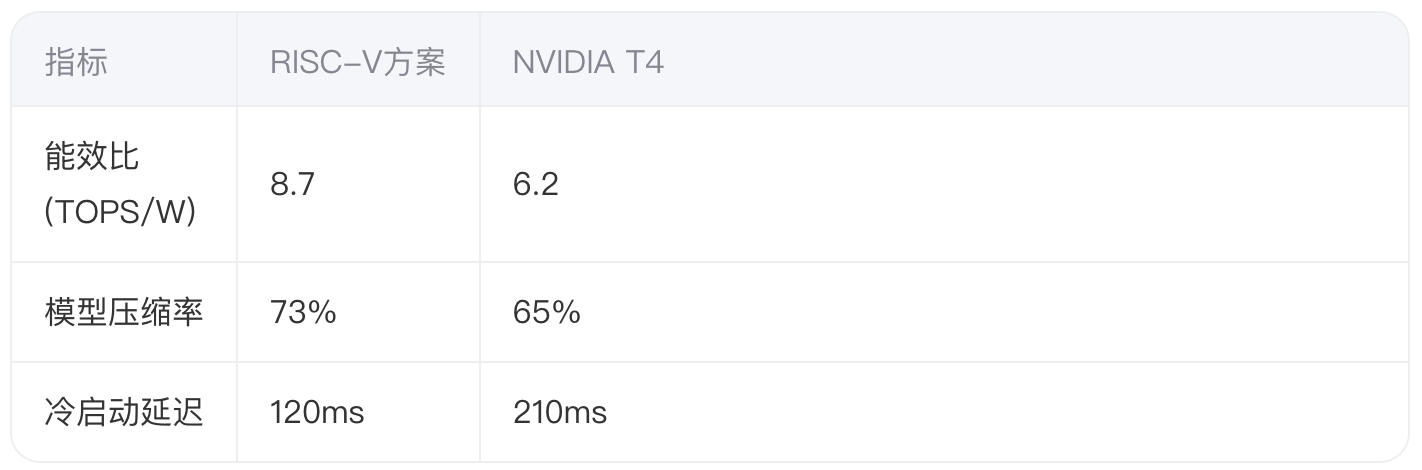
在ResNet-50推理任务中,RISC-V GPU相比NVIDIA T4展现独特优势:
3.2 性能优化策略
结合DeepSeek的实践经验,RISC-V GPU部署AI模型的关键技术包括:
- 混合精度计算:采用BF16/INT8混合量化策略
- 指令级并行:通过RVV向量扩展实现4x128位并行计算
- 内存访问优化:
- 采用分块缓存(Tiling Cache)技术
- 实现跨bank零拷贝数据传输
- 动态电压频率调节:根据工作负载实时调整计算单元功耗
四、技术挑战与发展前景
4.1 当前技术瓶颈
- 生态碎片化:不同厂商的RISC-V扩展指令集兼容性差
- 开发工具链成熟度:缺乏类似CUDA的统一编程环境
- 先进制程支持:7nm以下工艺的物理设计验证尚未完善
4.2 前沿突破方向
- 异构计算架构:
- 光子互连与RISC-V计算核集成
- 存算一体架构下的近内存计算优化
- 软件生态建设:
- RISE全球软件生态计划的推进
- 开源MLIR编译器对RVV的深度支持
- 新型封装技术:
- 3D堆叠封装实现计算密度倍增
- 硅光互联突破带宽瓶颈
五、产业实践启示
兆易创新的技术路线验证了RISC-V在AI服务器市场的潜力:其SPI NOR Flash产品线已实现:
- 512Kb到2Gb全容量覆盖
- 1.65V~3.6V宽电压支持
- 每秒133MHz时钟频率
这为RISC-V GPU的存储子系统设计提供了重要参考,特别是在: - 低功耗存储控制器设计
- 多bank并行访问机制
- 错误校正码(ECC)优化
结语
RISC-V GPU正在改写AI芯片的竞争规则。其开源特性不仅降低研发成本,更重要的是创造了算法定义硬件的新范式。随着DeepSeek等大模型与RISC-V终端的深度适配,未来三年或将见证开源架构在边缘推理市场的全面爆发。