贝叶斯算法实战:从原理到鸢尾花数据集分类
在机器学习的广阔领域中,贝叶斯算法以其基于概率推理的独特优势,成为数据分类和预测的重要工具。今天,我们将通过一段Python代码,深入探讨贝叶斯算法在鸢尾花数据集分类任务中的应用,从算法原理到代码实现,一步步揭开贝叶斯算法的神秘面纱。
一、贝叶斯算法原理简介
贝叶斯算法基于贝叶斯定理,该定理描述了在已知某些条件下,某事件发生的概率。其核心公式为:
P(A\|B) = \\frac{P(B\|A) \\times P(A)}{P(B)}
其中, P ( A ∣ B ) P(A|B) P(A∣B) 是在事件 B B B 发生的条件下事件 A A A 发生的后验概率; P ( B ∣ A ) P(B|A) P(B∣A) 是在事件 A A A 发生的条件下事件 B B B 发生的似然概率; P ( A ) P(A) P(A) 是事件 A A A 发生的先验概率; P ( B ) P(B) P(B) 是事件 B B B 发生的概率。
在分类任务中,我们可以将类别看作事件 A A A,特征看作事件 B B B。通过计算每个类别在给定特征下的后验概率,选择后验概率最大的类别作为预测结果。朴素贝叶斯算法作为贝叶斯算法的一种常见形式,假设特征之间相互独立,大大简化了计算过程,使其在实际应用中更加高效。
二、代码实现详解
1. 数据准备
python
import pandas as pd
data = pd.read_csv("iris.csv",header=None)
data = data.drop(0,axis = 1)
X_whole = data.drop(5,axis = 1)
y_whole = data[5]上述代码首先使用 pandas 库读取鸢尾花数据集文件(假设文件名为 iris.csv),由于数据集中第一列可能是无关的行索引,我们通过 drop(0,axis = 1) 将其删除。然后,将数据集划分为特征矩阵 X_whole 和标签向量 y_whole,其中特征矩阵包含了鸢尾花的各种属性数据,标签向量则表示鸢尾花的类别。
2. 数据集划分
python
from sklearn.model_selection import train_test_split
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(X_whole, y_whole, test_size=0.2, random_state=0)这里使用 sklearn 库中的 train_test_split 函数,将原始数据集按照 8:2 的比例划分为训练集和测试集。test_size=0.2 表示测试集占总数据集的 20%,random_state=0 用于设置随机种子,确保每次运行代码时数据集的划分结果一致,方便结果的复现和对比。
3. 模型训练与预测
python
from sklearn.naive_bayes import MultinomialNB#导入朴素贝叶斯分类器
#实例化贝叶斯分类器
classifier =MultinomialNB(alpha=1)
classifier.fit(x_train_w,y_train_w)我们导入 MultinomialNB 类,它是用于多项式分布数据的朴素贝叶斯分类器。通过 MultinomialNB(alpha=1) 实例化一个分类器对象,其中 alpha 参数是平滑参数,用于防止出现概率为 0 的情况,这里设置为 1。接着使用 fit 方法,将训练集的特征矩阵 x_train_w 和标签向量 y_train_w 输入模型,进行模型的训练。
python
'''训练集预测'''
train_pred = classifier.predict(x_train_w)
cm_plot(y_train_w,train_pred).show()
'''测试集预测'''
test_pred = classifier.predict(x_test_w)
cm_plot(y_test_w,test_pred).show()模型训练完成后,分别使用 predict 方法对训练集和测试集进行预测,得到训练集预测结果 train_pred 和测试集预测结果 test_pred。同时,通过自定义的 cm_plot 函数(用于绘制混淆矩阵),可视化模型在训练集和测试集上的分类结果,直观展示模型预测的准确性和错误类型。
4. 模型评估
python
from sklearn import metrics
print(metrics.classification_report(y_train_w, train_pred))
score = classifier.score(x_train_w, y_train_w)
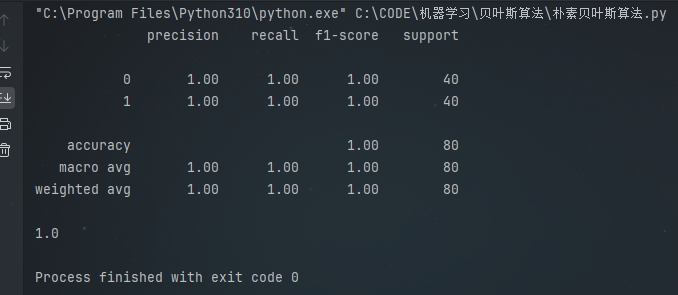
print(score)使用 sklearn 库中的 metrics 模块,通过 classification_report 函数生成训练集的分类报告,报告中包含了精确率、召回率、F1 值等重要评估指标,帮助我们全面了解模型在各个类别上的分类性能。此外,通过 classifier.score 方法计算模型在训练集上的准确率,进一步量化模型的性能表现。运行结果如下
三、结果分析
通过运行上述代码,我们可以得到模型在训练集和测试集上的分类结果以及相应的评估指标。从混淆矩阵中,我们可以直观地看到模型正确分类和错误分类的样本数量,分析模型容易出现错误的类别。分类报告和准确率则为我们提供了更具体的量化评估,帮助我们判断模型的优劣。
如果模型在训练集上表现良好,但在测试集上效果不佳,可能存在过拟合问题;反之,如果在训练集和测试集上表现都不理想,则需要考虑调整模型参数、增加数据量或尝试其他算法等方法进行改进。
四、总结
通过本次对贝叶斯算法在鸢尾花数据集分类任务中的实战演练,我们不仅深入理解了贝叶斯算法的原理,还掌握了其在 Python 中的具体实现和模型评估方法。贝叶斯算法凭借其简单高效、对小规模数据友好等特点,在文本分类、垃圾邮件过滤、疾病诊断等众多领域都有着广泛的应用。希望本文能为你进一步探索贝叶斯算法及其他机器学习算法提供帮助,后续可以尝试调整参数、更换数据集,不断优化模型性能,挖掘贝叶斯算法的更多潜力。