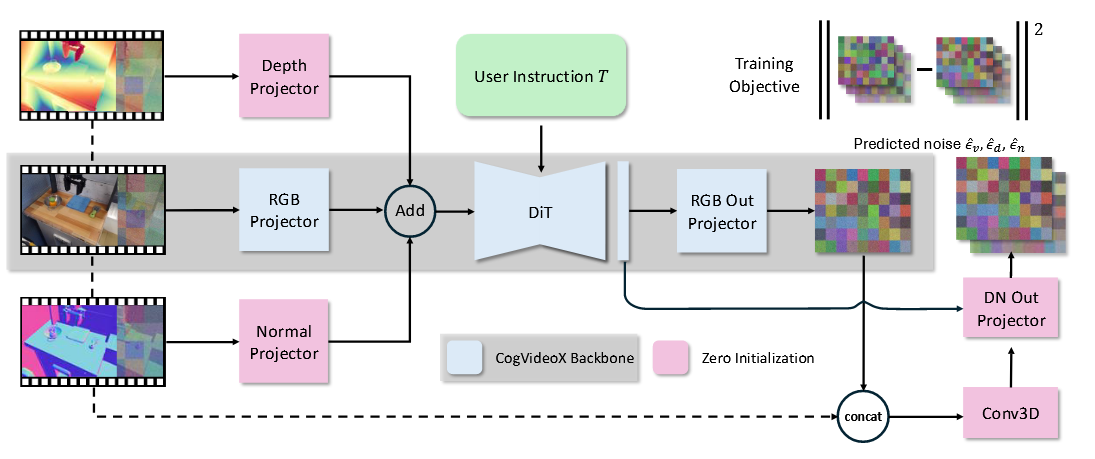
采用RGB-DN(RGB+深度+法线) 作为 4D 场景中间表示,由此建模 4D 场景,比纯 2D 视频更准确地建模 3D 几何结构。相比现有的 4D 视频生成,优化速度快,收敛好,且首次从当前帧和文本描述的具身智能体动作直接预测4D场景。
建模分布为 p ( v , d , n ∣ v 0 , d 0 , n 0 , T ) p(v,d,n|v^0,d^0,n^0,T) p(v,d,n∣v0,d0,n0,T) 其中 v, d, n 表示预测的未来 RGB、深度图和法线图的潜在序列, v 0 v^0 v0、 d 0 d^0 d0、 n 0 n^0 n0 是 RGB 图像、深度和法线图的潜在表示以及具身智能体的文本动作。
q ( z t ∣ z t − 1 ) = N ( z t ; α t z t − 1 , ( 1 − α t ) I ) p θ ( x t − 1 ∣ x t , x 0 , T ) = N ( x t − 1 ; μ θ ( x t , t , x 0 , T ) , Σ θ ( x t , t ) ) \begin{aligned}q(\mathbf{z}t|\mathbf{z}{t-1})=\mathcal{N}\left(\mathbf{z}t;\sqrt{\alpha_t}\mathbf{z}{t-1},(1-\alpha_t)\mathbf{I}\right)\\p_\theta(\mathbf{x}{t-1}|\mathbf{x}t,\mathbf{x}^0,\mathcal{T})=\mathcal{N}\left(\mathbf{x}{t-1};\mu\theta(\mathbf{x}t,t,\mathbf{x}^0,\mathcal{T}),\Sigma\theta(\mathbf{x}_t,t)\right)\end{aligned} q(zt∣zt−1)=N(zt;αt zt−1,(1−αt)I)pθ(xt−1∣xt,x0,T)=N(xt−1;μθ(xt,t,x0,T),Σθ(xt,t))
通过法线积分优化深度:
在第 i 帧的 2D 图像坐标系中,像素位置 u = ( u , v ) T ∈ V i u =(u,v)^T\in\boldsymbol{V}^i u=(u,v)T∈Vi,其对应的深度标量、法向量为 d ∈ D i , n = ( n x , n y , n z ) ∈ N 2 d\in D^i, \quad n=(n_x,n_y,n_z)\in N^2 d∈Di,n=(nx,ny,nz)∈N2。在焦距为 f,主点为 ( c u , c v ) T (c_u,c_v)^T (cu,cv)T 的透视相机假设下,对数深度 d ~ = l o g ( d ) \tilde{d}=log(d) d~=log(d) 应满足一下方程: n ~ z ∂ v d ~ + n x = 0 \tilde{n}_z\partial_v\tilde{d}+n_x=0 n~z∂vd~+nx=0 和 n ~ z ∂ v d ~ + n y = 0 \tilde{n}z\partial_v\tilde{d}+n_y=0 n~z∂vd~+ny=0,其中 n ~ = n x ( u − c x ) + n y ( v − c y ) + n z f \tilde{n}=n_x(u-c_x)+n_y(v-c_y)+n_zf n~=nx(u−cx)+ny(v−cy)+nzf。由此得到:
min d ∬ Ω ( n ~ z ∂ u d ~ + n x ) 2 + ( n ~ z ∂ u d ~ + n y ) 2 d u d v . \min_d\iint\Omega(\tilde{n}_z\partial_u\tilde{d}+n_x)^2+(\tilde{n}_z\partial_u\tilde{d}+n_y)^2\mathrm{d}u\mathrm{d}v. dmin∬Ω(n~z∂ud~+nx)2+(n~z∂ud~+ny)2dudv.
转化为迭代预测得到:
d ~ t + 1 = arg min d ~ ( A d ~ − b ) T W ( d ~ t ) ( A d ~ − b ) = d e f arg min D ~ L s ( D ~ , N i ) \tilde{d}{t+1}=\arg\min{\tilde{d}}(A\tilde{d}-b)^TW(\tilde{d}t)(A\tilde{d}-b)\overset{\mathsf{def}}{\operatorname*{=}}\arg\min{\tilde{\mathcal{D}}}\mathcal{L}_s(\tilde{\mathcal{D}},\mathcal{N}^i) d~t+1=argd~min(Ad~−b)TW(d~t)(Ad~−b)=defargD~minLs(D~,Ni)
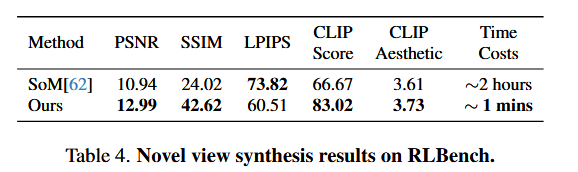
- 数据集:从 RLBench 中选择 20 个难度较高的任务,为每个任务从 4 个不同视角生成 1000 个实例,共生成 80k 个合成 4D 具身视频。虽然模拟器提供了度量深度信息,但缺乏表面法线数据,我们使用DSINE中的depth2normal 函数估计法线,并采用场景随机化技术增强泛化性。合成数据的多样性有限,与现实场景存在差距。纳入了现实世界视频数据集,利用 RollingDepth 为其标注仿射不变深度,使用 Temporal-Consistent Marigold-LCM-normal1 标注法线图。我们还选择了 OpenX 中的 Fractal data 和 Bridge 数据集,并纳入了人类 - 物体交互数据集 Something Something V2,以增加指令的多样性。
- 模型 :使用 CogVideoX 中的 3D VAE 分别对 RGB、深度和法线视频进行编码,不额外微调 VAE。输入设计上,为每个模态引入三个单独的投影仪提取嵌入: f z = I n p u t P r o j ( z t , z 0 ) f_z=InputProj(z_t,z_0) fz=InputProj(zt,z0)。DiT 以这些嵌入的和为输入,结合文本输入 T 和去噪步骤 t,得到隐藏状态 h = D i T ( ∑ f z , t , T ) h=DiT(\sum f_z,t,T) h=DiT(∑fz,t,T)。输出方面,保留原始 RGB 输出方法,同时为深度和法线预测引入额外模块,通过Conv3D层编码输入潜在和预测的RGB去噪输出的连接,与DiT骨干网络产生的隐藏状态结合,经过输出投影仪得到深度和法线的去噪预测。 L = E v 0 , T , t , ϵ ∥ \[ ϵ v , ϵ d , ϵ n − ϵ θ ( x t , t , x 0 , T ) ∥ 2 ] L=\mathbb{E}_{\mathbf{v}0,\mathcal{T},t,\epsilon}\left\\left\\\|\[\\epsilon_\\mathbf{v},\\epsilon_\\mathbf{d},\\epsilon_\\mathbf{n}-\epsilon\theta(\mathbf{x}_t,t,\mathbf{x}^0,\mathcal{T})\right\|^2\right] L=Ev0,T,t,ϵ \[ϵv,ϵd,ϵn−ϵθ(xt,t,x0,T) 2]
- 4D 场景重建 :输入深度图 D i D_i Di 是归一化的绝对值(0,1),无法直接用于 3D 重建;之前方法假设固定尺度或预测绝对深度,但重建结果粗糙;采用法线图 N i N_i Ni 通过法线积分 优化深度,得到初步深度图 D ^ \hat{D} D^,并加空间一致性损失 c s c_s cs。单纯逐帧优化会导致动态场景的深度抖动,因此引入 光流(Optical Flow) 约束跨帧一致性:
- 静态/动态区域分割 :计算相邻帧光流 F = R A F T ( V ) F=RAFT(V) F=RAFT(V);静态区域掩码 M i s M_i^s Mis------ ∣ ∣ F i ∣ ∣ ≤ c ||F_i||≤c ∣∣Fi∣∣≤c;动态区域掩码 M i d M_i^d Mid------剩余部分, M i s M_i^s Mis 的剩余部分;背景区域掩码 M i b M_i^b Mib------动态掩码与静态掩码的交集;
- 跨帧传播 : D i → ( i − 1 ) ( u , v ) = D i − 1 ( u − Δ u , v − Δ − v ) D_{i→(i-1)}(u,v)=D_{i-1}(u-\Delta u,v-\Delta -v) Di→(i−1)(u,v)=Di−1(u−Δu,v−Δ−v)
- 时间一致性损失 :根据光流,可以从先前帧检索当前帧对应位置的深度,以施加一致性约束。强制动态区域和背景区域的深度与前一帧对齐: L c = λ c d ∥ D ~ i ∘ M i d − D i → ( i − 1 ) ∘ M i d ∥ 2 + λ c b ∥ D ~ i ∘ M i b − D i → ( i − 1 ) ∘ M i b ∥ 2 \mathcal{L}c=\lambda{cd}\|\tilde{D}i\circ M_i^d-D{i\to(i-1)}\circ M_i^d\|^2+\lambda_{cb}\|\tilde{D}i\circ M_i^b-D{i\to(i-1)}\circ M_i^b\|^2 Lc=λcd∥D~i∘Mid−Di→(i−1)∘Mid∥2+λcb∥D~i∘Mib−Di→(i−1)∘Mib∥2
- 深度正则化损失 :防止优化后的深度 D ~ i \tilde{D}i D~i 过度偏离初始预测 D i D_i Di: L r = λ r d ∥ D ~ i ∘ M i d − D i ∘ M i d ∥ 2 + λ r b ∥ D ~ i ∘ M i b − D i ∘ M i b ∥ 2 \mathcal{L}r=\lambda{rd}\|\tilde{D}i\circ M_i^d-D_i\circ M_i^d\|^2+\lambda{rb}\|\tilde{D}i\circ M_i^b-D_i\circ M_i^b\|^2 Lr=λrd∥D~i∘Mid−Di∘Mid∥2+λrb∥D~i∘Mib−Di∘Mib∥2 arg min D ~ L s ( D ~ , N i ) ⏟ 法线约束 + L c ( D ~ , D ^ i − 1 , F i , F i − 1 ) ⏟ 时间约束 + L r ( D ~ , D i ) ⏟ 正则化 \arg\min{\tilde{D}}\underbrace{\mathcal{L}s(\tilde{D},N_i)}{\text{法线约束}}+\underbrace{\mathcal{L}c(\tilde{D},\hat{D}{i-1},F_i,F{i-1})}_{\text{时间约束}}+\underbrace{\mathcal{L}r(\tilde{D},D_i)}{\text{正则化}} argD~min法线约束 Ls(D~,Ni)+时间约束 Lc(D~,D^i−1,Fi,Fi−1)+正则化 Lr(D~,Di)
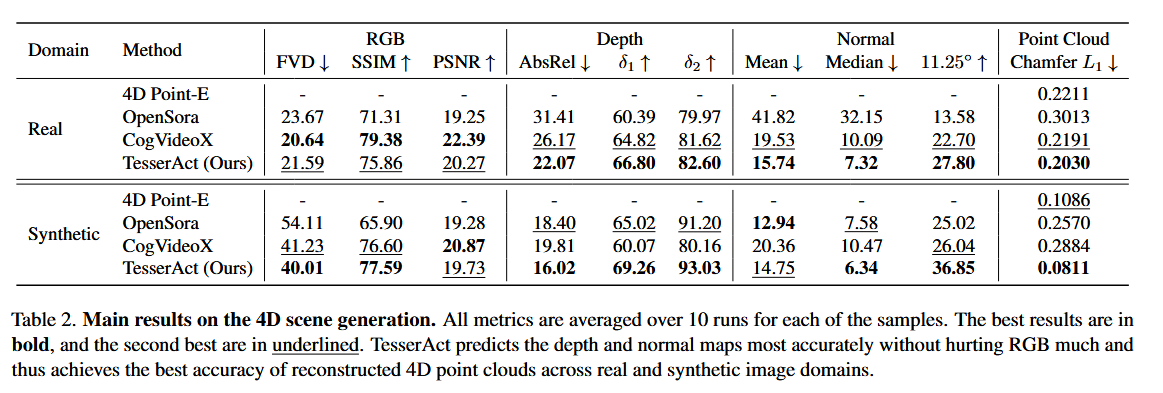
实验结果
凭借更好的深度和法线图,方法重建的4D点云在真实和合成数据集上均实现了最低的Chamfer距离。4D Point-E方法在RLBench上的表现优于视频扩散模型,但仍落后于我们的方法。此外,直接使用点云进行训练计算成本高昂,限制了所用的帧数。相比之下,我们的模型利用RGB-DN视频的高效表示生成更精确的4D场景,尤其在捕捉动态场景的细粒度细节方面表现出色。