摘要 :
本文深入解析机器学习中的学习率及其衰减方法,涵盖学习率的作用、常用衰减参数及七种主流衰减策略(分段常数、指数、自然指数、多项式、余弦、线性余弦、噪声线性余弦)。通过公式推导与图示对比,揭示不同衰减方式的适用场景与性能差异,并结合实际训练需求指导超参数调优。关键词:学习率、衰减方法、梯度下降、超参数优化、模型收敛。
关键词:学习率 衰减方法 梯度下降 超参数优化 模型收敛
1. 学习率的作用
在梯度下降算法中,学习率(Learning Rate)是控制模型参数更新步长的关键超参数。其核心作用可总结为:
- 前期加速收敛:较大的学习率能快速逼近最优解区域。
- 后期精细调优:逐步减小学习率避免震荡,提升模型收敛精度。
数学表达为:
w t + 1 = w t − η ⋅ ∇ J ( w t ) w_{t+1} = w_t - \eta \cdot \nabla J(w_t) wt+1=wt−η⋅∇J(wt)
其中, η \eta η 为学习率, ∇ J ( w t ) \nabla J(w_t) ∇J(wt) 为损失函数梯度。
2. 学习率衰减的常用参数
表1总结了学习率衰减的核心参数及其作用:
| 参数名称 | 说明 |
|---|---|
learning_rate |
初始学习率,决定优化起点速度。 |
global_step |
全局训练步数,非负整数,用于动态计算衰减系数。 |
decay_steps |
衰减周期步数,控制学习率下降频率。 |
decay_rate |
衰减率,指数衰减中调整速度的关键因子。 |
end_learningrate |
最小学习率下限,避免更新步长过小导致训练停滞。 |
cycle |
布尔值,决定是否在衰减后重新升高学习率(如多项式衰减)。 |
3. 七种学习率衰减方法详解
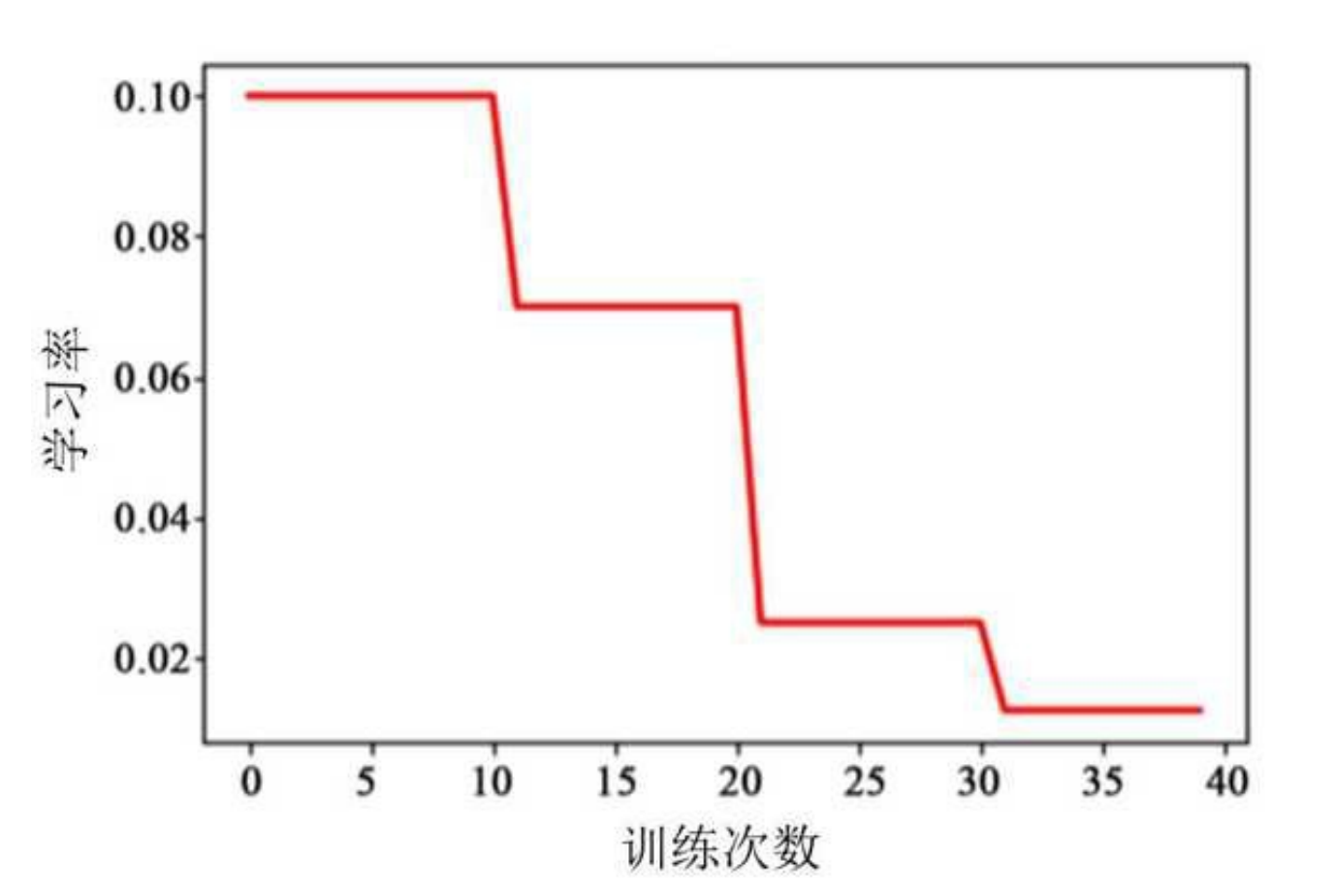
3.1 分段常数衰减
原理 :预设训练阶段区间,每个区间固定学习率。
适用场景 :经验性调整,需人工划分阶段。
示例代码:
python
boundaries = [1000, 2000] # 区间边界
values = [0.1, 0.01, 0.001] # 对应学习率
lr = tf.train.piecewise_constant(global_step, boundaries, values)图示 :
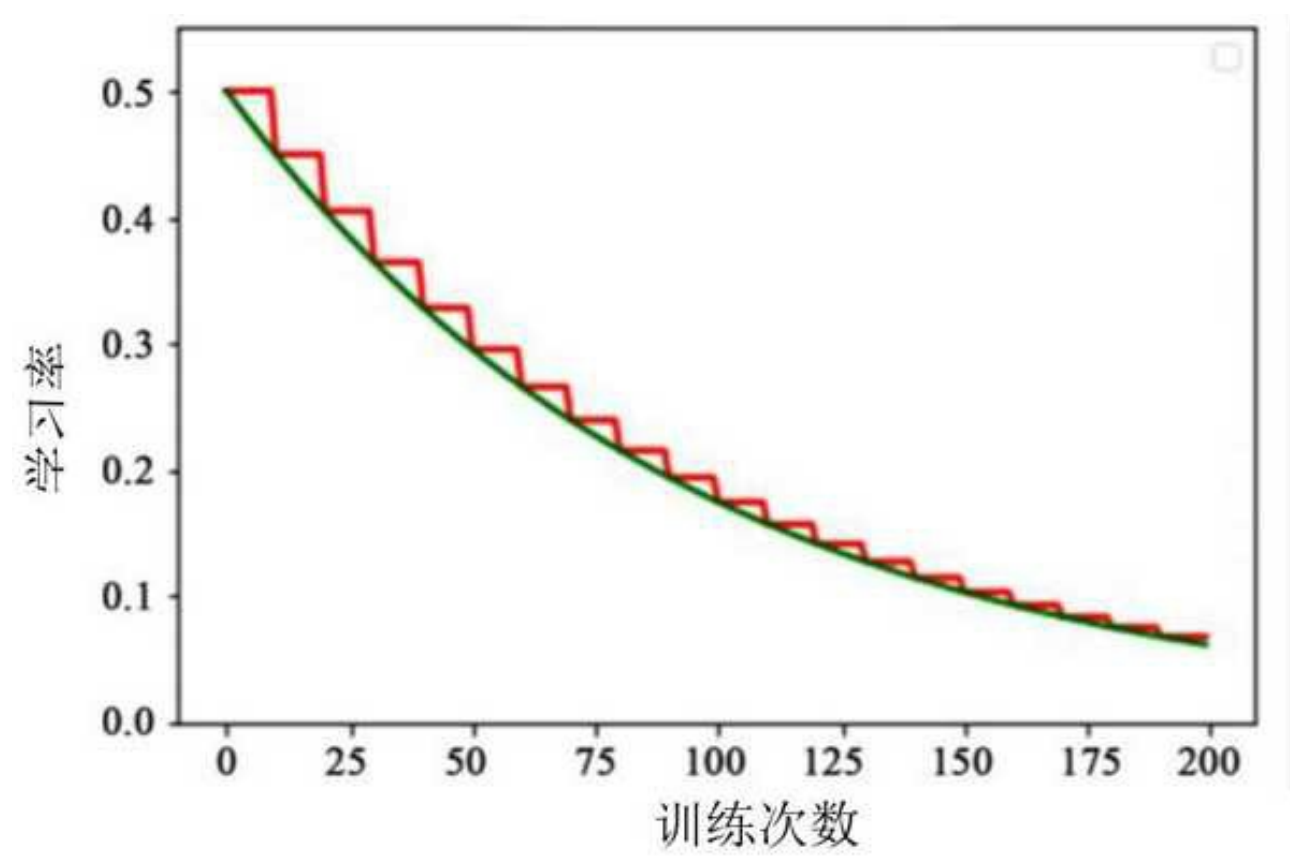
3.2 指数衰减
公式 :
η t = η 0 ⋅ decay_rate t / decay_steps \eta_t = \eta_0 \cdot \text{decay\_rate}^{t / \text{decay\_steps}} ηt=η0⋅decay_ratet/decay_steps
特点 :平滑下降,收敛速度快。
曲线对比 :
3.3 自然指数衰减
公式 :
η t = η 0 ⋅ e − k ⋅ t \eta_t = \eta_0 \cdot e^{-k \cdot t} ηt=η0⋅e−k⋅t
优势:衰减速度更快,适合简单任务快速收敛。
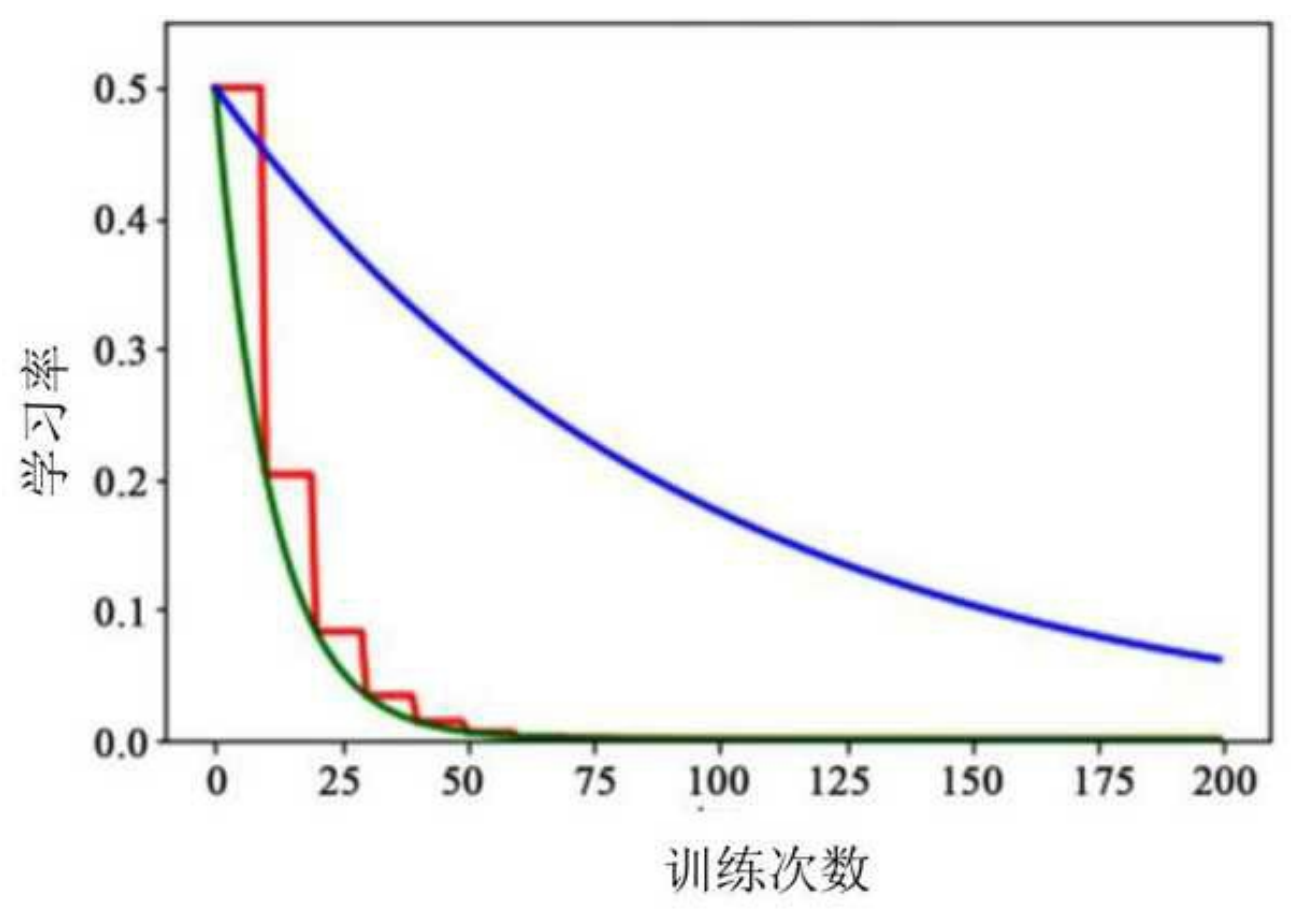
3.4 多项式衰减
公式 :
η t = ( η 0 − η end ) ⋅ ( 1 − t decay_steps ) p + η end \eta_t = (\eta_0 - \eta_{\text{end}}) \cdot \left(1 - \frac{t}{\text{decay\steps}}\right)^p + \eta{\text{end}} ηt=(η0−ηend)⋅(1−decay_stepst)p+ηend
模式 :支持线性( p = 1 p=1 p=1)或循环震荡衰减。
图示 :
3.5 余弦衰减
公式 :
η t = η 0 ⋅ 1 + cos ( π ⋅ t / decay_steps ) 2 \eta_t = \eta_0 \cdot \frac{1 + \cos(\pi \cdot t / \text{decay\_steps})}{2} ηt=η0⋅21+cos(π⋅t/decay_steps)
特点:平滑周期变化,适合精细调优。
3.6 线性余弦衰减
改进公式 :
η t = η 0 ⋅ α + ( 1 − α ) ⋅ 1 + cos ( π ⋅ t / decay_steps ) 2 \eta_t = \eta_0 \cdot \left\\alpha + (1-\\alpha) \\cdot \\frac{1 + \\cos(\\pi \\cdot t / \\text{decay\\_steps})}{2}\\right ηt=η0⋅α+(1−α)⋅21+cos(π⋅t/decay_steps)
优势:结合线性下降与余弦周期,平衡稳定性与灵活性。
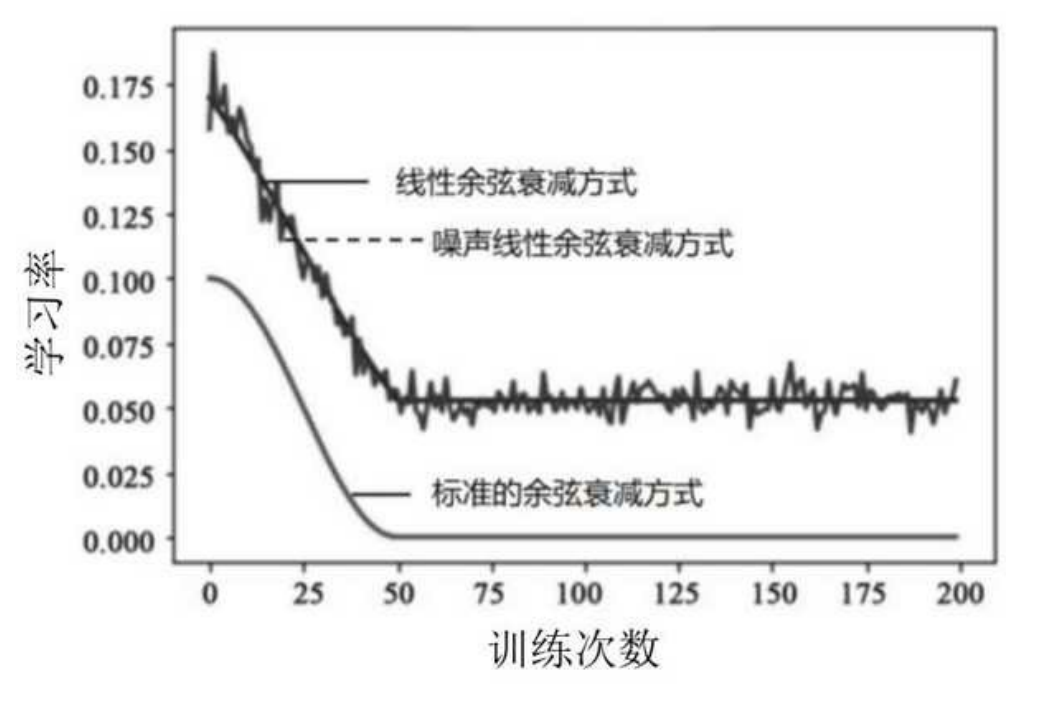
3.7 噪声线性余弦衰减
改进点 :在衰减过程中添加随机噪声,增强跳出局部最优能力。
曲线对比 :
4. 方法对比与选择建议
| 方法 | 收敛速度 | 稳定性 | 适用场景 |
|---|---|---|---|
| 分段常数 | 中 | 高 | 经验丰富的超参数调优 |
| 指数衰减 | 快 | 中 | 大多数分类/回归任务 |
| 自然指数 | 极快 | 低 | 简单模型或初期快速下降 |
| 余弦衰减 | 慢 | 高 | 精细调优阶段 |
选择原则:
- 数据量大且分布均匀 → 余弦衰减
- 追求快速原型验证 → 自然指数衰减
- 需平衡速度与精度 → 多项式衰减
5. 总结
学习率衰减是优化模型性能的重要手段,需根据任务复杂度、数据规模及训练阶段动态调整。本文系统梳理了七种衰减方法的核心公式与实战场景,为超参数调优提供理论依据与实践指导。