目录
1.冒泡排序
1.1 基本概念
冒泡排序(Bubble Sort) 是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元
素,如果它们的顺序错误就把它们交换过来。这个算法的名字由来是因为越小(或越大)的元素会
经由交换慢慢"浮"到数列的顶端 。
如果概念比较抽象的话,我们可以举个例子理解一下:
假设有5个小朋友排队,身高从矮到高排才算整齐。老师像冒泡排序程序,每次从队头开始,让相
邻小朋友比身高,高的往后站。第一轮,最高的小朋友像大泡泡浮到队尾;第二轮,第二高的小朋
友再浮到倒数第二位置,依此类推,经过4轮,小朋友们就按身高排好队啦。
1.2 算法原理
冒泡排序的核心思想是通过重复遍历待排序的数组,比较相邻元素的大小,若逆序则交换它们的位
置。这样,每次遍历都会将未排序序列中最大(或最小)的元素"冒泡"到序列的尾部(或头部)。
随着遍历次数的增加,需要排序的元素逐渐减少,直至完成排序。
1.3 代码示例
cs
1 //方法1
2 void bubble_sort(int arr[], int sz)//参数接收数组元素个数
3 {
4 int i = 0;
5 for(i=0; i<sz-1; i++)
6 {
7 int j = 0;
8 for(j=0; j<sz-i-1; j++)
9 {
10 if(arr[j] > arr[j+1])
11 {
12 int tmp = arr[j];
13 arr[j] = arr[j+1];
14 arr[j+1] = tmp;
15 }
16 }
17 }
18 }
19
20 int main()
21 {
22 int arr[] = {3,1,7,5,8,9,0,2,4,6};
23 int sz = sizeof(arr)/sizeof(arr[0]);
24 bubble_sort(arr, sz);
25 int i = 0;
26 for(i=0; i<sz; i++)
27 {
28 printf("%d ", arr[i]);
29 }
30 return 0;
31 }
32
33
34 //方法2 - 优化
35 void bubble_sort(int arr[], int sz)//参数接收数组元素个数
36 {
37 int i = 0;
38 for(i=0; i<sz-1; i++)
39 {
40 int flag = 1;//假设这一趟已经有序了
41 int j = 0;
42 for(j=0; j<sz-i-1; j++)
43 {
44 if(arr[j] > arr[j+1])
45 {
46 flag = 0;//发生交换就说明,无序
47 int tmp = arr[j];
48 arr[j] = arr[j+1];
49 arr[j+1] = tmp;
50 }
51 }
52 if(flag == 1)//这一趟没交换就说明已经有序,后续无序排序了
53 break;
54 }
55 }
56
57 int main()
58 {
59 int arr[] = {3,1,7,5,8,9,0,2,4,6};
60 int sz = sizeof(arr)/sizeof(arr[0]);
61 bubble_sort(arr, sz);
62 int i = 0;
63 for(i=0; i<sz; i++)
64 {
65 printf("%d ", arr[i]);
66 }
67 return 0;
68 }1.4 代码原理
方法1
-
函数定义: bubble_sort 函数接收整型数组 arr 和数组元素个数 sz ,实现冒泡排序。
-
外层循环: for(i = 0; i < sz - 1; i++) 控制排序轮数, sz 个元素需 sz - 1 轮 。
-
内层循环: for(j = 0; j < sz - i - 1; j++) 进行每轮元素比较,每轮把最大元素"冒泡"到末尾。
-
比较交换: if(arrj > arrj + 1) 判断相邻元素大小,若逆序则借助 tmp 交换。
-
主函数:定义数组 arr ,计算元素个数 sz ,调用 bubble_sort 排序,再遍历打印排序后数组。
方法2(优化)
-
函数定义:同方法1的 bubble_sort 函数功能。
-
外层循环:与方法1类似控制轮数。
-
内层循环:逻辑同方法1,新增 flag 变量。初始设 flag = 1 (假设有序 ,发生交换时 flag= 0 (说明无序 )。
-
提前结束:内层循环后 if(flag == 1) 判断,若没交换说明已排好序, break 提前结束排序。
-
主函数:和方法1主函数类似,定义数组、计算元素个数、调用排序函数并打印结果。
2. 二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里?
这就是 二级指针 。
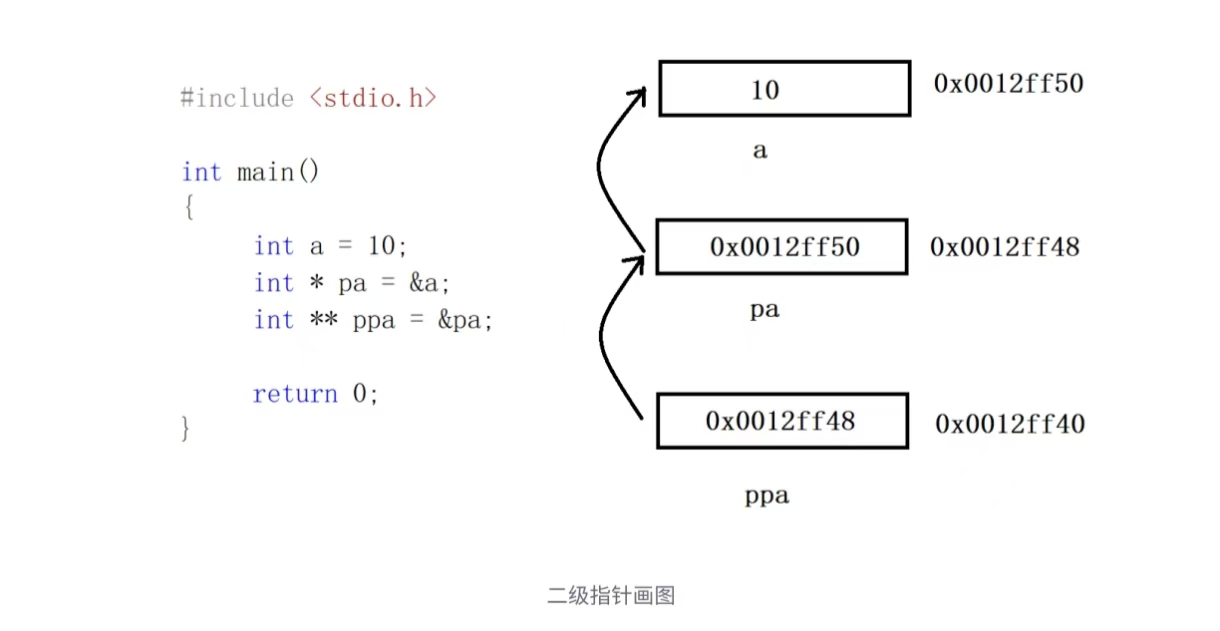
对于二级指针的运算有:
*ppa 通过对 ppa 中的地址进行解引用,这样找到的是 pa , *ppa 其实访问的就是 pa
cs
int b = 20;
*ppa = &b; //等价于 pa = &b;**ppa 先通过 *ppa 找到 pa ,然后对 pa 进行解引用操作: *pa ,那找到的是 a 。
cs
**ppa = 30;
//等价于*pa = 30;
//等价于a = 30;3. 指针数组
指针数组是指针还是数组?
我们类比一下,整型数组,是存放整型的数组,字符数组是存放字符的数组。
那指针数组呢?是存放指针的数组。
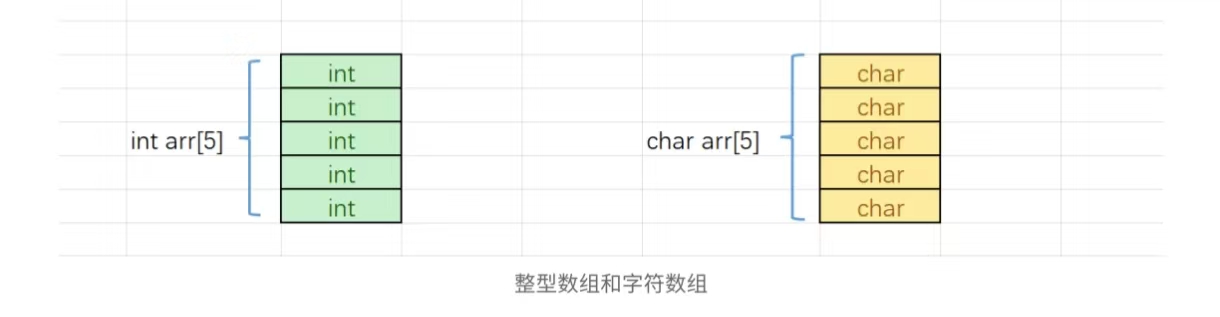
指针数组的每个元素都是用来存放地址(指针)的。
如下图:

指针数组的每个元素是地址,又可以指向一块区域。
4. 数组指针模拟二维数组
cs
#include <stdio.h>
int main()
{
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
//数组名是数组首元素的地址,类型是int*的,就可以存放在parr数组中
int* parr[3] = {arr1, arr2, arr3};
int i = 0;
int j = 0;
for(i=0; i<3; i++)
{
for(j=0; j<5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}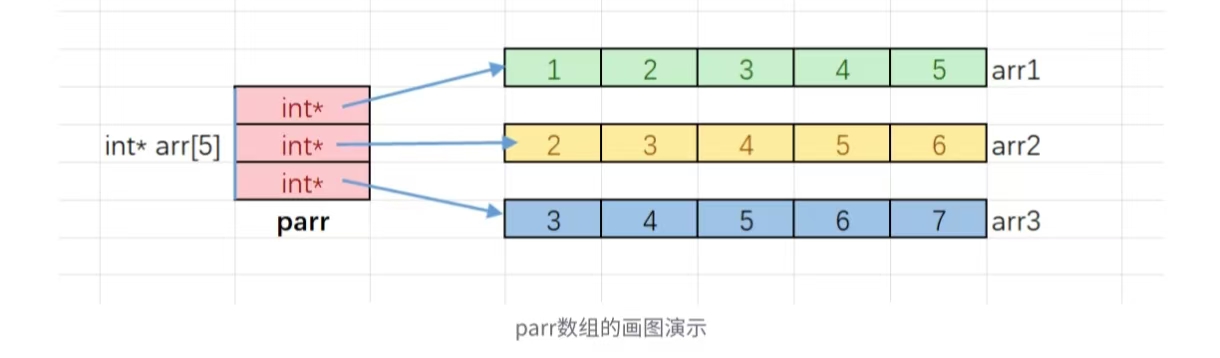
parri是访问parr数组的元素,parri找到的数组元素指向了整型一维数组,parrij 就是整型一
维数组中的元素。
上述的代码模拟出二维数组的效果,实际上并非完全是二维数组,因为每一行并非是连续的。
感谢大家的观看,本期内容到此结束,希望大家对冒泡排序多多理解!