Scrapyd
Scrapyd 是一个用于部署和运行 Scrapy 爬虫的服务器。
1.安装
Scrapyd服务端:pip install scrapyd
Scrapyd客户端:pip install scrapyd-client
运行scrapyd
浏览器输入http://127.0.0.1:6800/
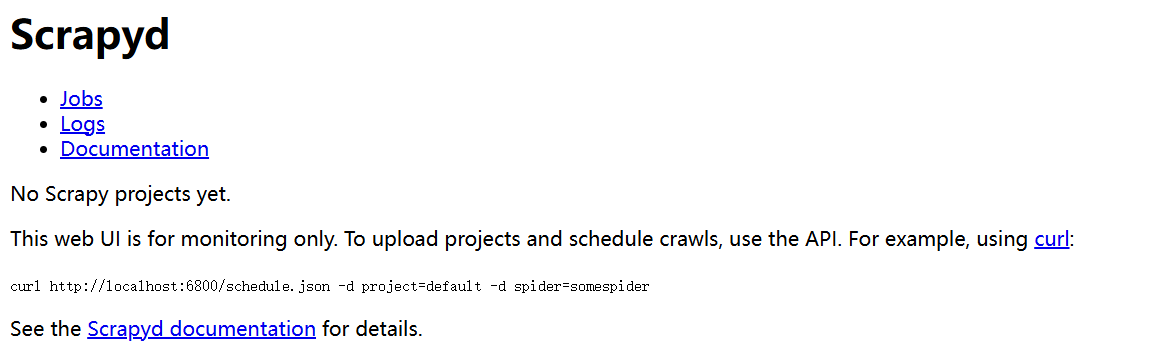
2.配置
安装完成后,需要对 Scrapyd 进行配置。通常需要创建一个scrapyd.conf配置文件,该文件用于设置 Scrapyd 的各种参数,如监听端口、日志文件路径、项目存储路径等。
官方配置文件:https://scrapyd.readthedocs.io/en/stable/config.html
bash
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 4
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root在上述配置中,指定了项目 egg 文件存储目录、日志文件目录、绑定的 IP 地址和端口等信息。你可以根据实际需求对这些配置进行修改。
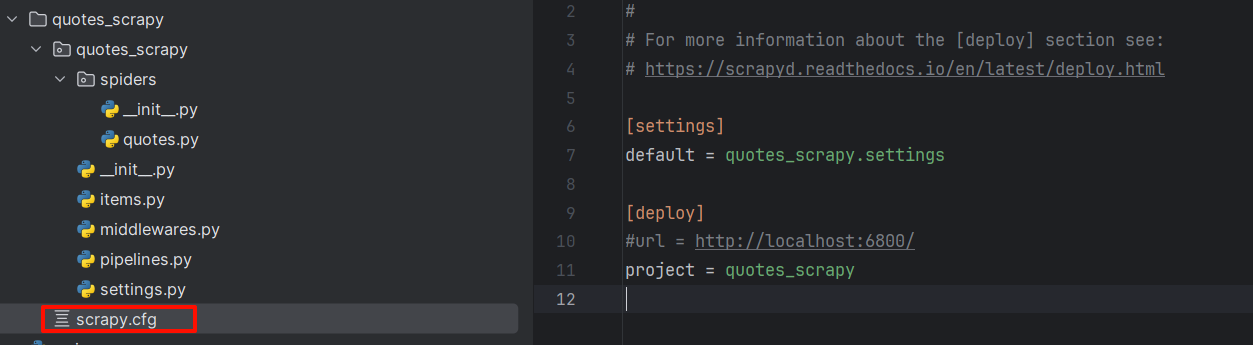
打开scrapy项目里面的scrapy.cfg,修改一下
python
[settings]
default = quotes_scrapy.settings
[deploy:Quotes] # deploy冒号后面写部署名
url = http://localhost:6800/
project = quotes_scrapy3.部署项目
爬虫代码
python
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class QuotesSpider(CrawlSpider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["http://quotes.toscrape.com/"]
rules = (
Rule(LinkExtractor(allow=r'^http://quotes.toscrape.com/tag/[a-z]+/$'), callback='parse_tag', follow=True),
)
def parse_tag(self, response):
# 打印当前页面的URL
tag_url = response.url
self.logger.info(f"Extracted tag URL: {tag_url}")
# 提取名言和作者
quotes = response.css('div.quote')
for quote in quotes:
text = quote.css('span.text::text').get()
author = quote.css('small.author::text').get()
self.logger.info(f"text: {text}, author: {author}")然后执行部署命令:scrapyd-deploy Quotes,代码变了就需要重新运行命令重新部署

打包生成了一个版本号(这里是 1746626862)。然后生成了这些文件夹,1746626862.egg就是打包文件
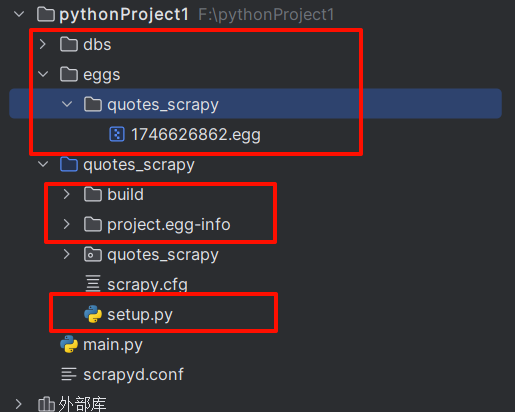
部署完成,http://localhost:6800/就多了scrapy项目
4.运行爬虫
部署完成后,可以通过向 Scrapyd 服务器发送 HTTP POST 请求告知 Scrapyd 服务器启动 quotes_scrapy 项目里名为 quotes 的爬虫
python
curl http://localhost:6800/schedule.json -d project=quotes_scrapy -d spider=quotes也可以通过 Python 代码来调用 Scrapyd 的接口启动爬虫,示例代码如下:
python
import requests
url = 'http://localhost:6800/schedule.json'
data = {
'project': 'quotes_scrapy ',
'spider': 'quotes'
}
response = requests.post(url, data=data)
print(response.json())运行爬虫会有一个jobid

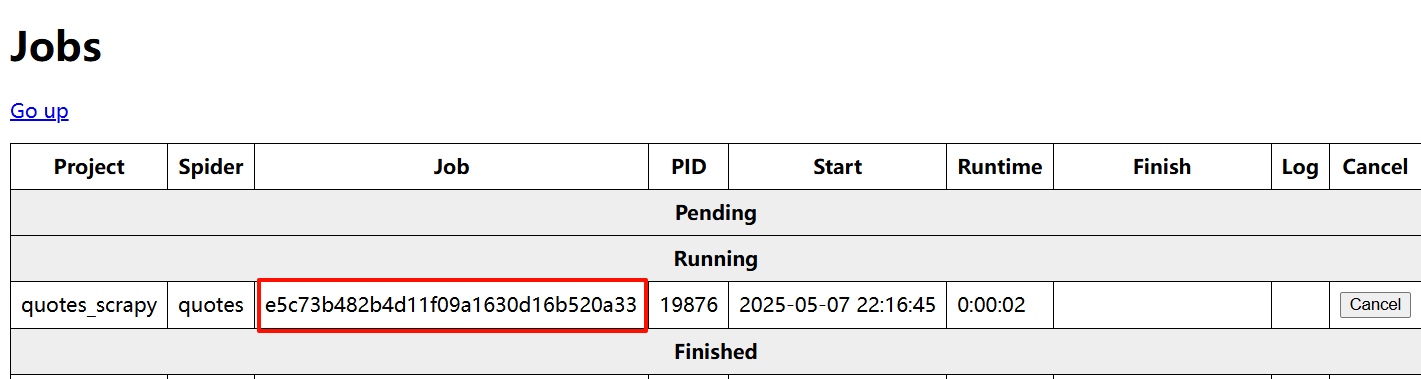
运行完爬虫会出现logs日志文件
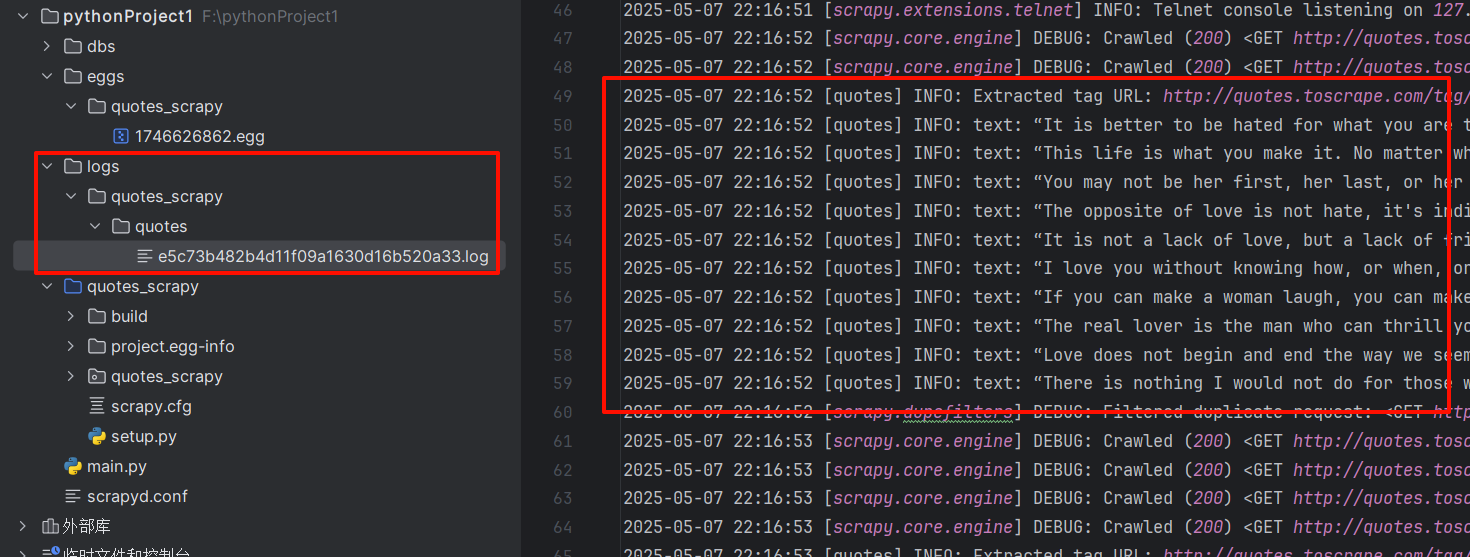
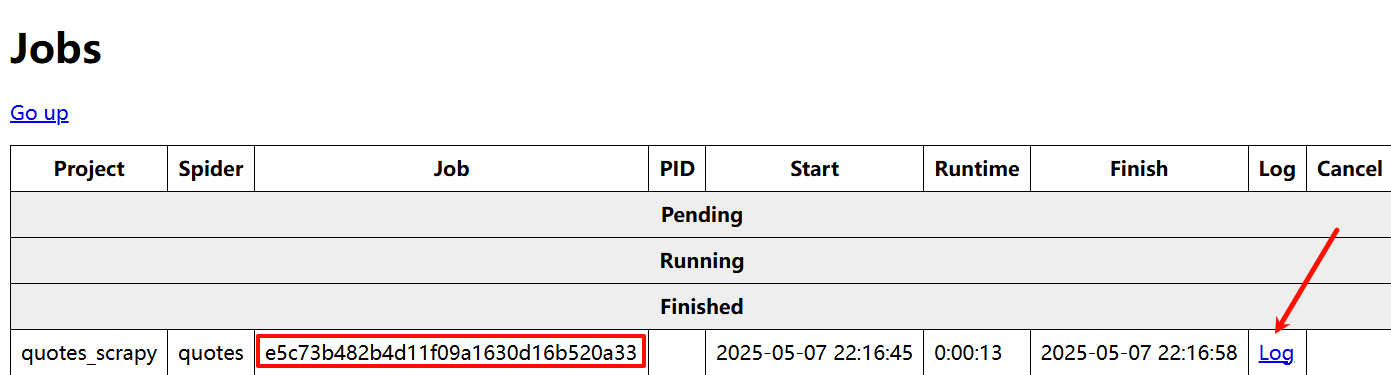

但是页面上会有一些乱码。
5.管理爬虫
- 暂停爬虫 :可以发送 POST 请求到
http://localhost:6800/pause.json接口来暂停正在运行的爬虫,请求参数与启动爬虫类似,需要指定project和spider名称。 - 恢复爬虫 :通过发送 POST 请求到
http://localhost:6800/resume.json接口来恢复暂停的爬虫。 - 停止爬虫 :发送 POST 请求到
http://localhost:6800/cancel.json接口可以停止正在运行的爬虫。
6.查看状态和日志
- 查看项目列表 :发送 GET 请求到
http://localhost:6800/listprojects.json接口可以获取已部署的项目列表。 - 查看爬虫列表 :通过 GET 请求
http://localhost:6800/listspiders.json?project=my_scrapy_project可以查看指定项目中的爬虫列表。 - 查看日志 :Scrapyd 会将爬虫的日志存储在配置文件中指定的
logs_dir目录下。可以通过访问该目录下的日志文件来查看爬虫的运行日志,了解爬虫的执行情况、错误信息等
Gerapy
Gerapy 是一个基于 Python 和 Django 开发的分布式爬虫管理框架,它为 Scrapy 爬虫的管理提供了可视化的界面,能够和 Scrapyd 协同工作。Gerapy 可以实现 Scrapy 项目的部署、调度、监控等功能,大大提升了爬虫管理的效率,适合用于管理大规模的分布式爬虫任务。
1.安装 Gerapy
python
pip install gerapy2.初始化 Gerapy 项目
安装完成后,需要初始化 Gerapy 项目。在命令行中执行以下命令:
python
gerapy init
cd gerapy
gerapy migrate-
gerapy init:该命令会创建一个 Gerapy 项目的基础结构。
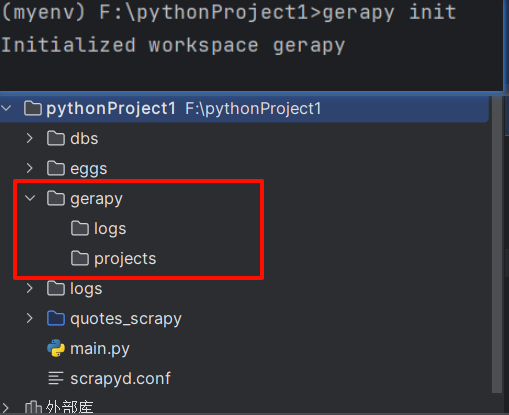
-
cd gerapy:进入到创建好的项目目录。 -
gerapy migrate:执行数据库迁移操作,创建必要的数据库表。
3.创建管理员用户
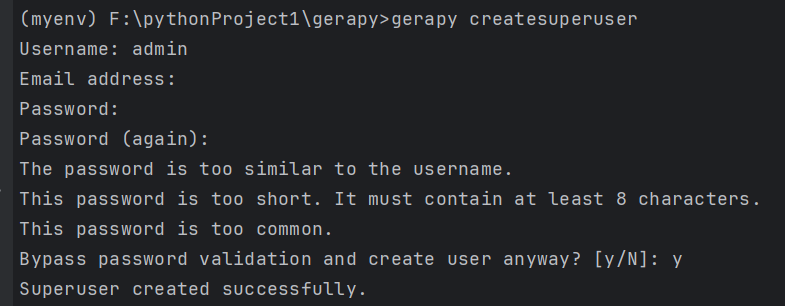
要使用 Gerapy 的管理界面,需要创建一个管理员用户
python
gerapy createsuperuser按照提示输入用户名、邮箱和密码。这里用户名和密码都是admin,邮箱不填
4.启动 Gerapy 服务
python
gerapy runserver
默认情况下,Gerapy 会在http://127.0.0.1:8000上启动服务。在浏览器中访问该地址,使用之前创建的管理员账号登录,即可进入 Gerapy 的管理界面。

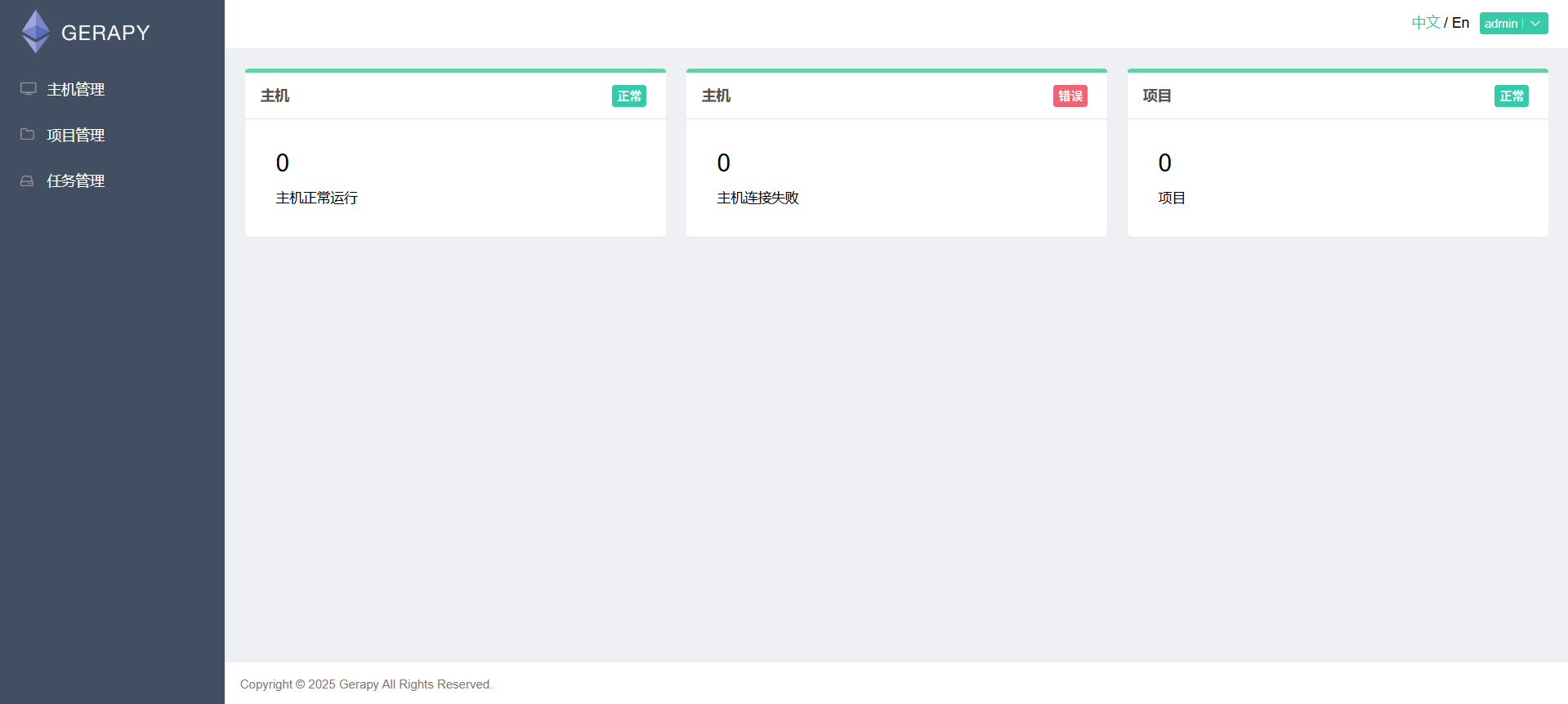
5.添加服务器
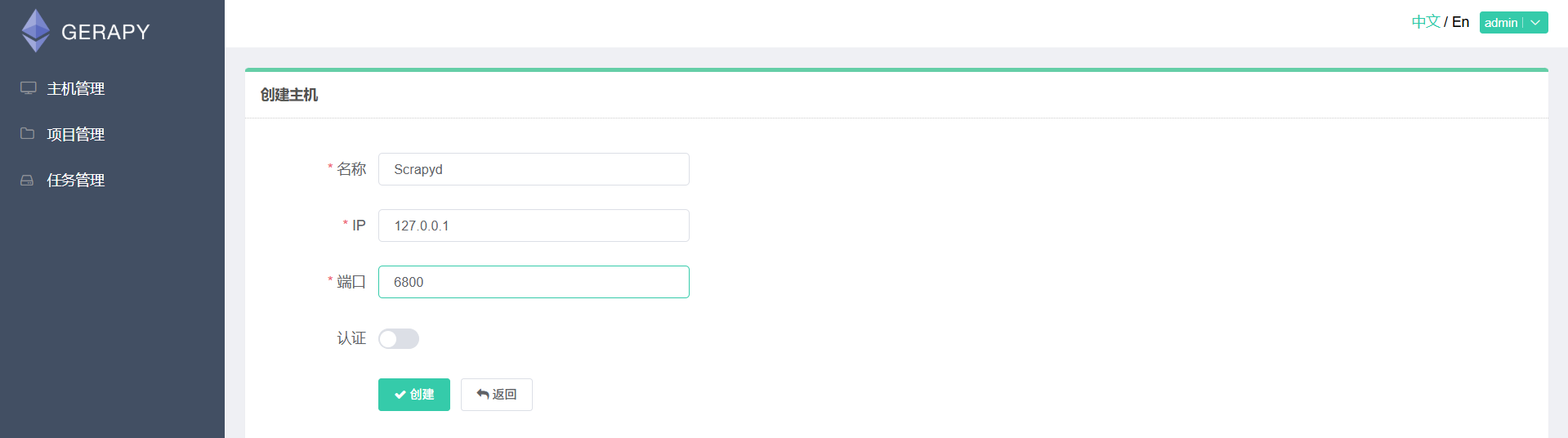
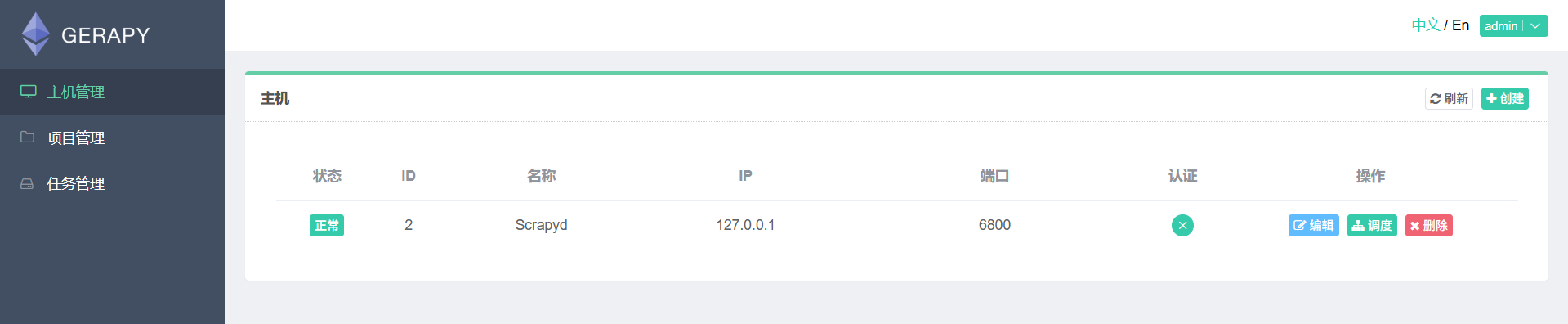
在 Gerapy 中,你需要添加 Scrapyd 服务器,以便管理和调度这些服务器上的爬虫项目。前提是要运行scrapyd

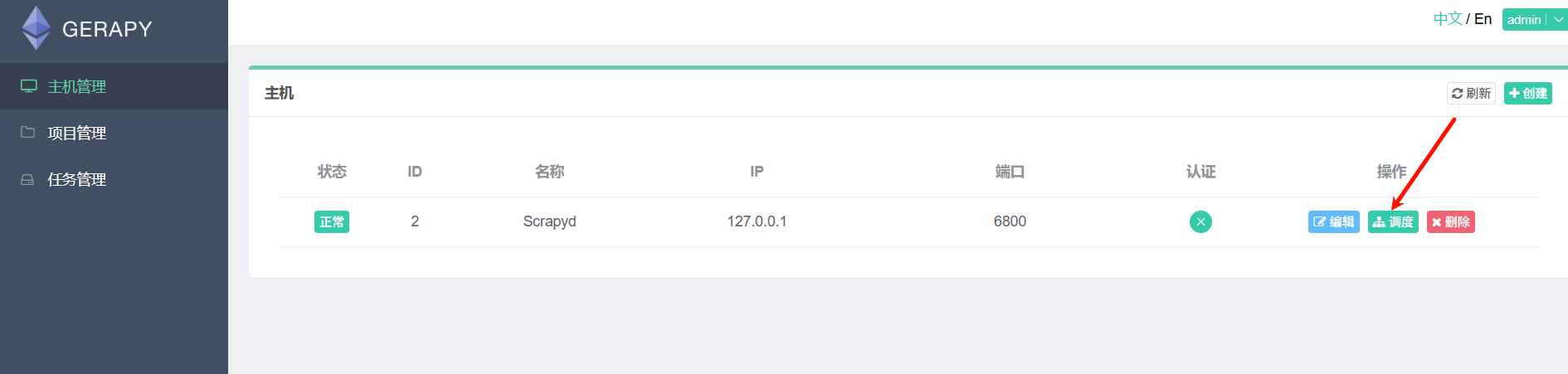
6.调度爬虫
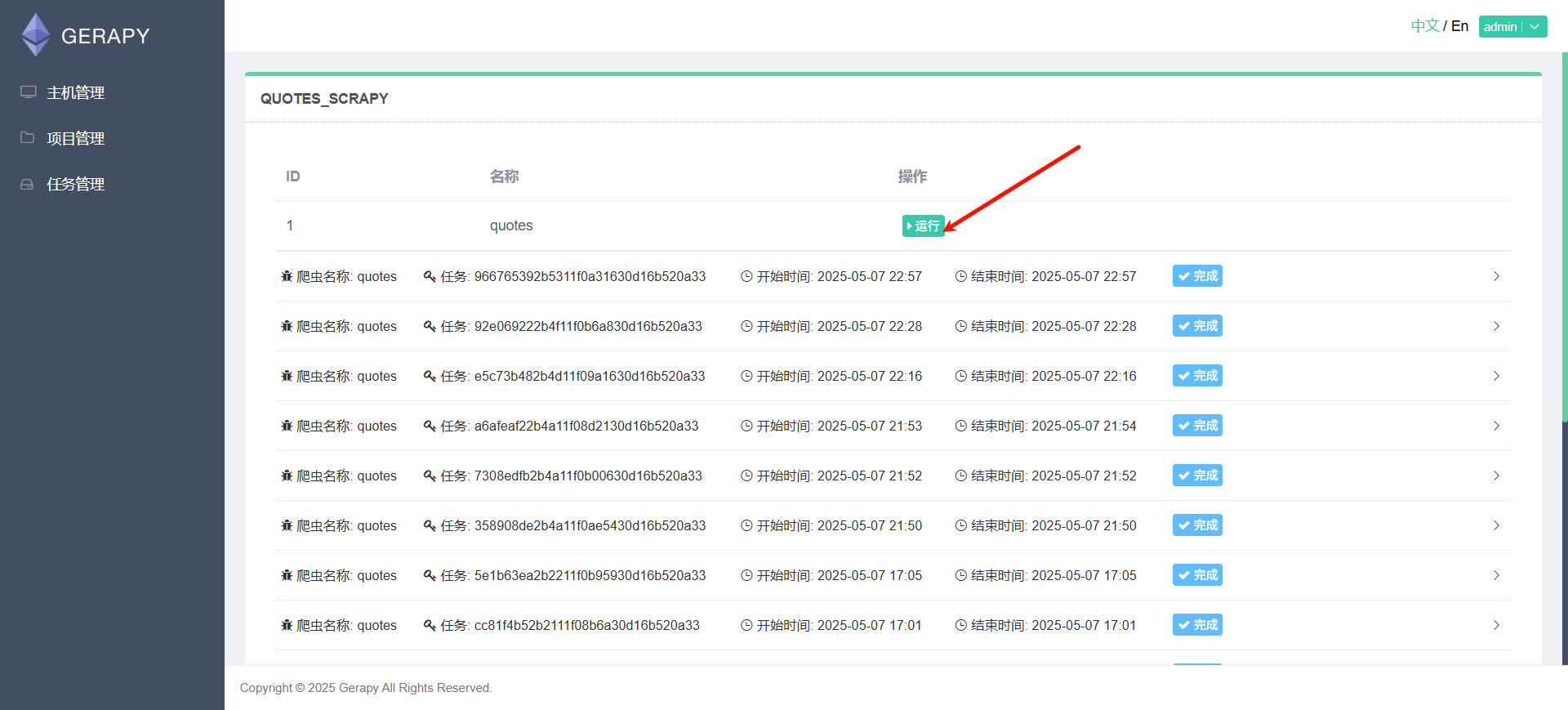
7.项目管理
可以对已部署的项目进行更新、删除等操作。

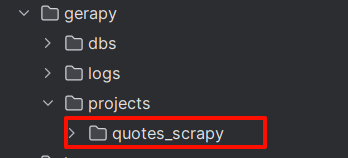
直接将scrapy项目放在gerapy/projects目录下

可以看到多了一个quotes_scrapy项目
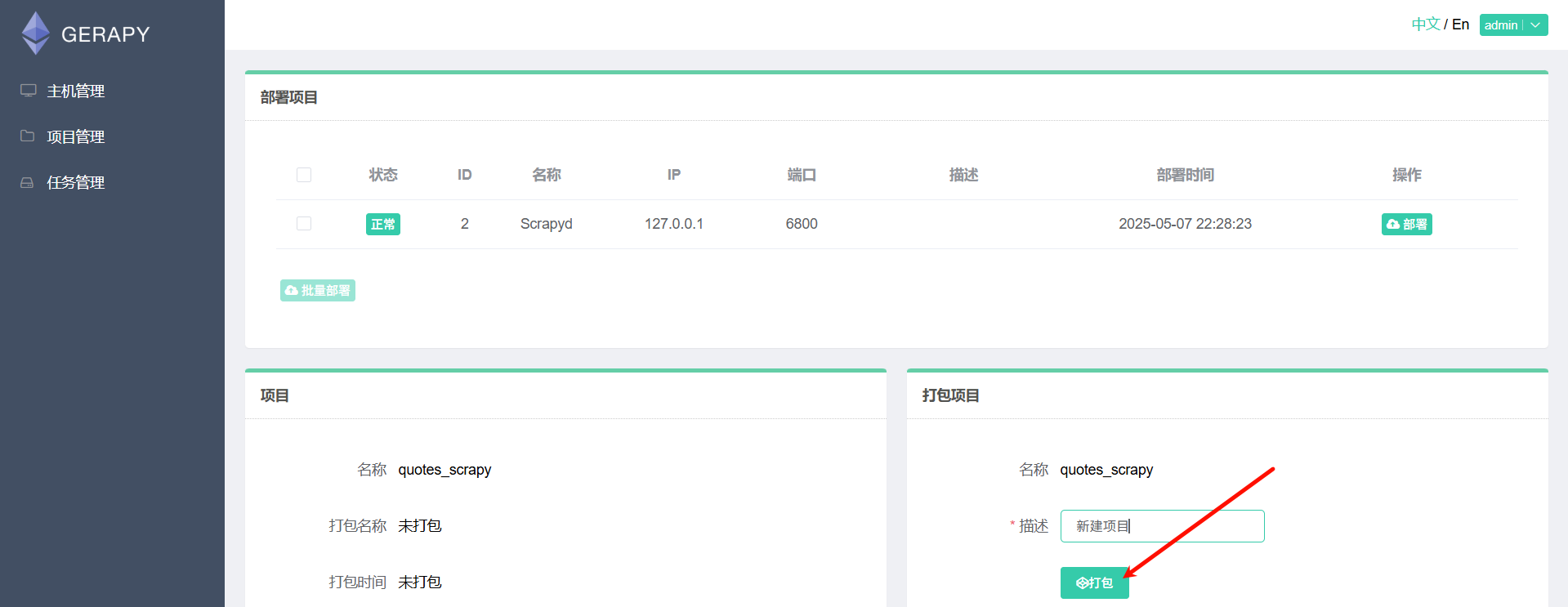
然后打包项目,点击"部署",然后添加描述,再点击"打包"

监控爬虫
在 Gerapy 管理界面的 "任务" 选项中,可以查看所有爬虫任务的执行状态,包括正在运行、已完成、失败等状态。