更多AI大模型应用开发学习内容,尽在聚客AI学院。
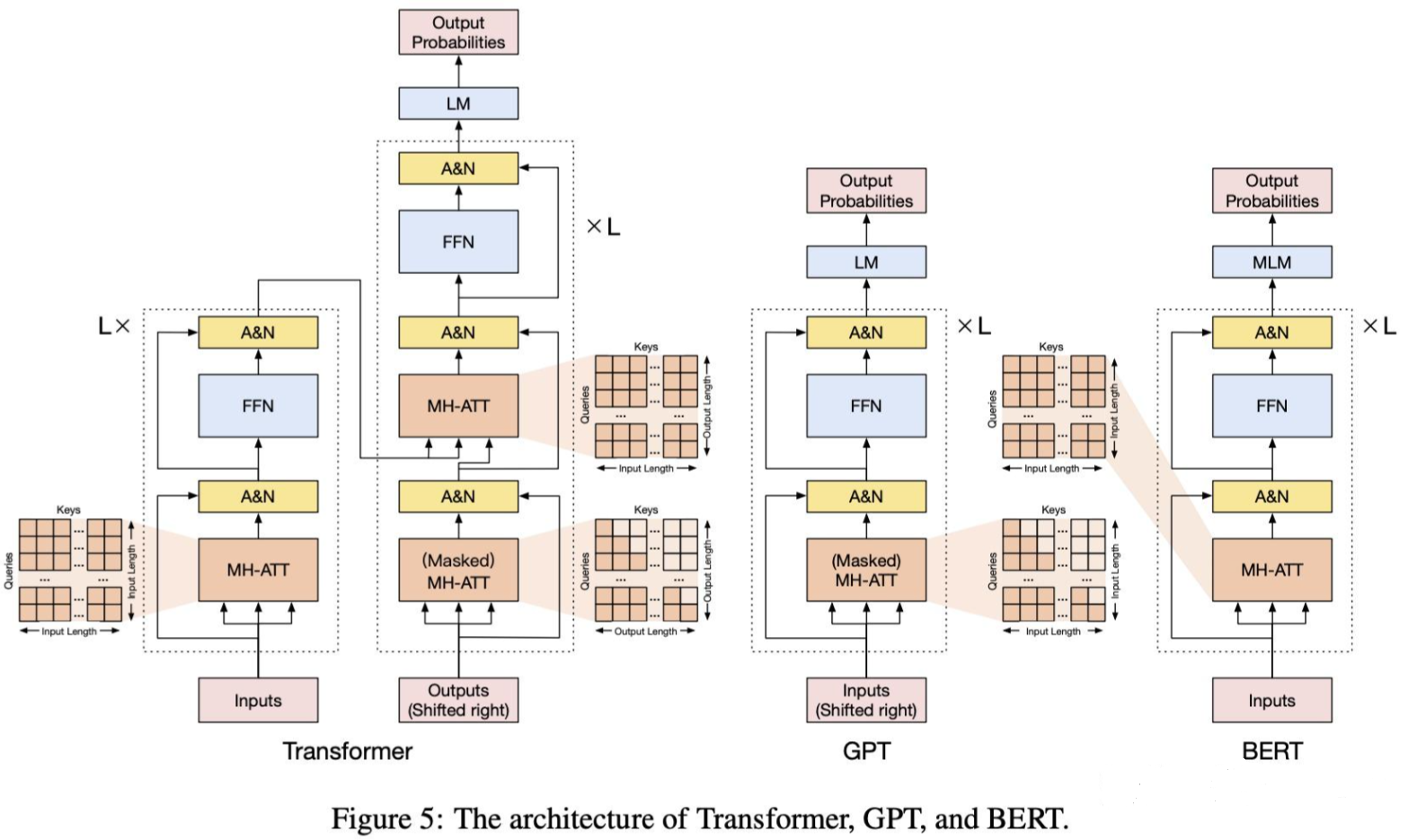
一. 预训练模型(PTM)核心概念
1.1 什么是预训练模型?
预训练模型(Pre-trained Model, PTM)是在大规模通用数据上预先训练的模型,通过自监督学习掌握基础语义理解能力,可迁移到下游任务。典型代表:
-
BERT(双向Transformer):文本掩码预测
-
GPT(自回归Transformer):文本生成
-
ViT(Vision Transformer):图像分类
技术价值:
-
知识蒸馏:从海量数据中提取通用模式
-
迁移潜能:参数携带跨任务可复用知识
二. 迁移学习(Transfer Learning)技术解析
2.1 迁移学习范式
XML
源领域(大数据) → 知识迁移 → 目标领域(小数据)典型场景:
-
跨任务迁移:BERT用于情感分析/命名实体识别
-
跨模态迁移:CLIP实现图文互搜
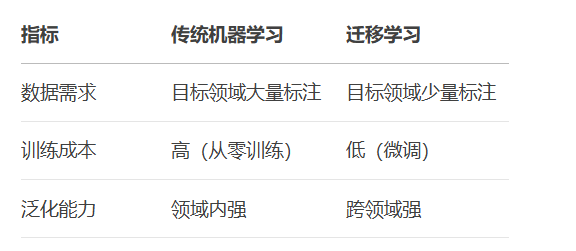
2.2 与传统学习的对比
三. 为什么需要预训练?
3.1 传统方法的局限
-
数据依赖:标注成本高(如医学图像标注需专家参与)
-
冷启动难题:小数据集易过拟合
-
知识孤立:每个任务独立建模,无法复用
3.2 预训练的核心优势
-
参数效率:ImageNet预训练的ResNet在CIFAR-10仅需微调1%参数即可达90%+准确率
-
知识泛化:GPT-3通过提示工程(Prompting)实现零样本学习
四. 预训练模型的下游任务适配策略
4.1 特征提取器固定(Feature Extraction)
冻结PTM参数,仅训练顶层分类器:
代码示例:BERT固定特征提取
python
from transformers import BertModel, BertTokenizer
import torch
# 加载预训练模型
model = BertModel.from_pretrained("bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 冻结参数
for param in model.parameters():
param.requires_grad = False
# 提取特征
inputs = tokenizer("Hello world!", return_tensors="pt")
outputs = model(**inputs)
features = outputs.last_hidden_state[:, 0, :] # 取[CLS]向量
# 添加分类层
classifier = torch.nn.Linear(768, 2)
logits = classifier(features)4.2 微调(Fine-Tuning)
解冻全部或部分参数进行端到端训练:
代码示例:GPT-2微调
python
from transformers import GPT2LMHeadModel, GPT2Tokenizer, Trainer, TrainingArguments
model = GPT2LMHeadModel.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 准备训练数据
train_texts = ["AI is changing...", "Machine learning..."]
train_encodings = tokenizer(train_texts, truncation=True, padding=True)
# 微调配置
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=4,
learning_rate=5e-5
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_encodings
)
trainer.train()4.3 参数高效微调(PEFT)
-
LoRA:低秩矩阵注入
-
Adapter:插入小型适配模块
-
Prefix-Tuning:优化提示向量
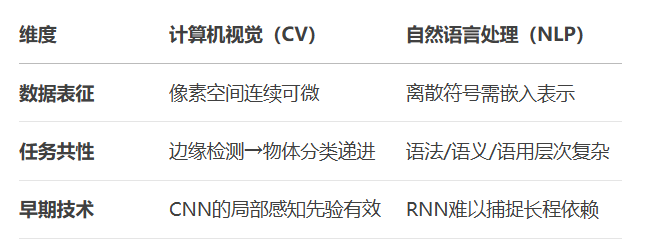
五. NLP预训练为何滞后于CV?
5.1 历史瓶颈分析
5.2 突破关键
-
Transformer架构:自注意力机制解决长程依赖
-
无监督目标:MLM(掩码语言建模)实现双向编码
-
大规模语料:Common Crawl等数据集提供万亿级token
注:本文代码需安装以下依赖:
bash
pip install transformers torch datasets更多AI大模型应用开发学习内容,尽在聚客AI学院。