这段代码定义了一个用于时间序列数据处理的 TimeMoEDataset 类,支持多种数据格式和归一化方法。
1. 类定义与初始化 (__init__)
python
class TimeMoEDataset(TimeSeriesDataset):
def __init__(self, data_folder, normalization_method=None):
self.data_folder = data_folder
self.normalization_method = normalization_method
self.datasets = [] # 存储子数据集(BinaryDataset/GeneralDataset)
self.num_tokens = None # 总时间点数量
# 处理归一化方法
if normalization_method is None:
self.normalization_method = None
elif isinstance(normalization_method, str):
if normalization_method.lower() == 'max':
self.normalization_method = max_scaler # 最大值归一化
elif normalization_method.lower() == 'zero':
self.normalization_method = zero_scaler # 标准化(Z-score)
else:
raise ValueError(f'未知归一化方法: {normalization_method}')
else:
self.normalization_method = normalization_method # 自定义归一化函数
# 加载数据:支持二进制文件或普通文件/文件夹
if BinaryDataset.is_valid_path(self.data_folder):
ds = BinaryDataset(self.data_folder)
if len(ds) > 0:
self.datasets.append(ds)
elif GeneralDataset.is_valid_path(self.data_folder):
ds = GeneralDataset(self.data_folder)
if len(ds) > 0:
self.datasets.append(ds)
else:
# 递归遍历文件夹,加载所有有效文件
for root, dirs, files in os.walk(self.data_folder):
for file in files:
fn_path = os.path.join(root, file)
# 跳过二进制元数据文件,加载普通数据集
if file != BinaryDataset.meta_file_name and GeneralDataset.is_valid_path(fn_path):
ds = GeneralDataset(fn_path)
if len(ds) > 0:
self.datasets.append(ds)
for sub_folder in dirs:
folder_path = os.path.join(root, sub_folder)
# 检查子文件夹是否为二进制数据集
if BinaryDataset.is_valid_path(folder_path):
ds = BinaryDataset(folder_path)
if len(ds) > 0:
self.datasets.append(ds)
# 计算累计长度数组,用于快速定位子数据集
self.cumsum_lengths = [0]
for ds in self.datasets:
self.cumsum_lengths.append(self.cumsum_lengths[-1] + len(ds))
self.num_sequences = self.cumsum_lengths[-1] # 总序列数- 数据加载 :
- 支持两种数据集类型:
BinaryDataset(二进制格式)和GeneralDataset(普通文本 / CSV 等)。 - 通过
os.walk递归遍历文件夹,自动识别有效数据文件,避免手动指定每个文件路径。
- 支持两种数据集类型:
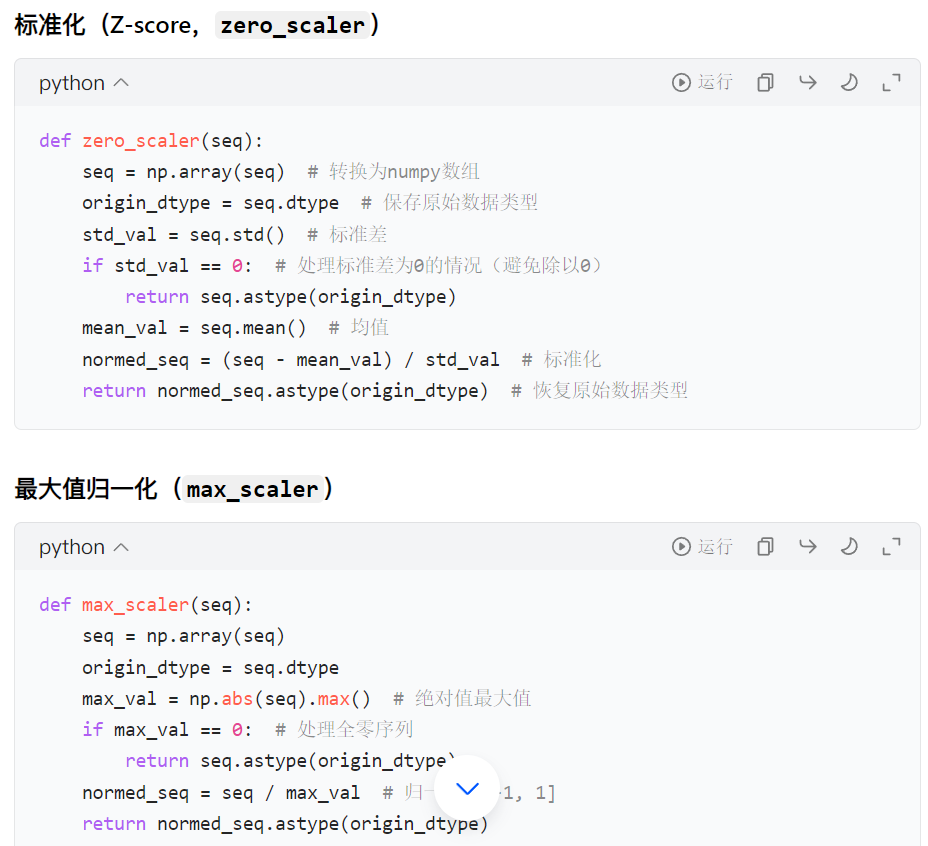
- 归一化处理 :
- 内置两种归一化方法:
max_scaler(最大值归一化)和zero_scaler(Z-score 标准化)。 - 支持自定义归一化函数,通过
normalization_method参数传入。
- 内置两种归一化方法:
- 子数据集管理 :
cumsum_lengths数组记录每个子数据集的起始索引(类似前缀和),例如cumsum_lengths = [0, 100, 300]表示第一个子数据集有 100 条序列,第二个有 200 条。
2. 序列索引与获取 (__getitem__)
python
def __getitem__(self, seq_idx):
if seq_idx >= self.cumsum_lengths[-1] or seq_idx < 0:
raise ValueError(f'索引越界: {seq_idx}')
# 二分查找确定子数据集索引和偏移量
dataset_idx = binary_search(self.cumsum_lengths, seq_idx)
dataset_offset = seq_idx - self.cumsum_lengths[dataset_idx]
seq = self.datasets[dataset_idx][dataset_offset] # 获取原始序列
# 应用归一化
if self.normalization_method is not None:
seq = self.normalization_method(seq)
return seq- 二分查找 :通过
binary_search函数在cumsum_lengths中快速定位序列所属的子数据集(时间复杂度为 \(O(\log N)\))。 - 归一化应用 :对获取的序列调用
normalization_method函数,返回归一化后的数据(numpy 数组)。
3. 辅助方法
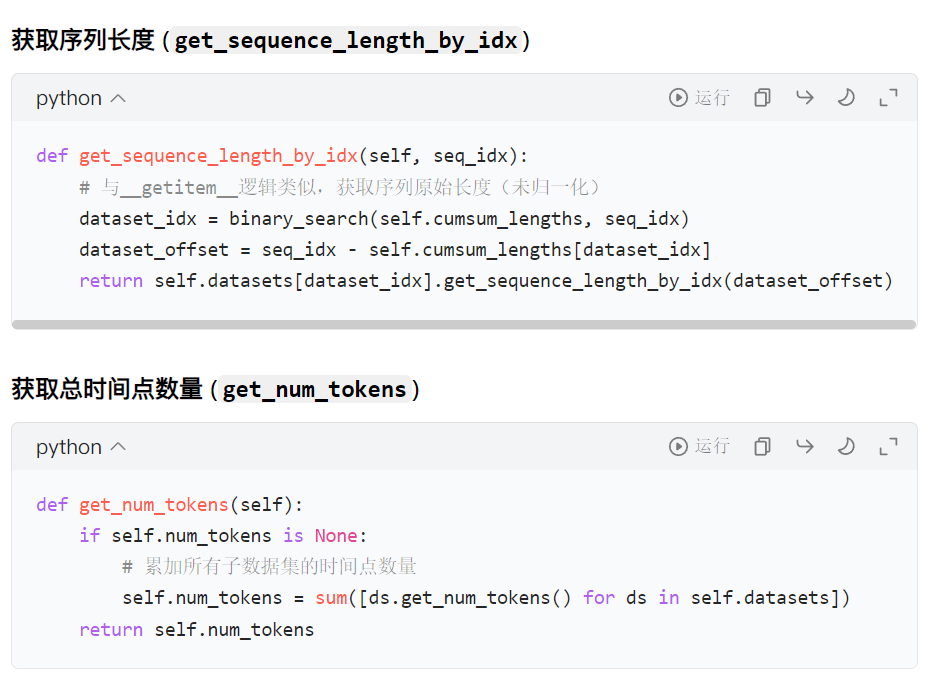
4. 归一化函数实现
5. 二分查找函数 (binary_search)
python
def binary_search(sorted_list, value):
low, high = 0, len(sorted_list) - 1
best_index = -1
while low <= high:
mid = (low + high) // 2
if sorted_list[mid] <= value: # 寻找最大的不超过value的索引
best_index = mid
low = mid + 1
else:
high = mid - 1
return best_index- 在有序数组
sorted_list(即cumsum_lengths)中查找value所属的区间,返回子数据集索引。例如,若cumsum_lengths = [0, 100, 300],value=150会被定位到索引 1(第二个子数据集,偏移量 50)。
6. 总结
TimeMoEDataset 是一个高效、鲁棒的时间序列数据集加载器,核心功能包括:
- 多格式数据加载:自动识别二进制和普通文件,支持递归遍历文件夹。
- 灵活归一化:内置两种常用归一化方法,支持自定义函数,处理边界情况。
- 高效索引:通过前缀和数组和二分查找,快速定位子数据集,适合大规模数据。
该类为后续模型训练(如 TimeMoeTrainer)提供了统一的数据接口,确保数据预处理的标准化和高效性。