获取数据、数据处理、特征工程后,就可以交给预估器进行机器学习,流程和常用API如下。
1.实例化预估器(估计器)对象(estimator), 预估器对象很多,都是estimator的子类
(1)用于分类的预估器
sklearn.neighbors.KNeighborsClassifier k-近邻
sklearn.naive_bayes.MultinomialNB 贝叶斯
sklearn.linear_model.LogisticRegressioon 逻辑回归
sklearn.tree.DecisionTreeClassifier 决策树
sklearn.ensemble.RandomForestClassifier 随机森林
(2)用于回归的预估器
sklearn.linear_model.LinearRegression线性回归
sklearn.linear_model.Ridge岭回归
(3)用于无监督学习的预估器
sklearn.cluster.KMeans 聚类
2.进行训练,训练结束后生成模型
estimator.fit(x_train, y_train)
3.模型评估
(1)方式1,直接对比
y_predict = estimator.predict(x_test)
y_test == y_predict
(2)方式2, 计算准确率
accuracy = estimator.score(x_test, y_test)
4.使用模型(预测)
y_predict = estimator.predict(x_true)六 KNN算法-分类
1 样本距离判断
明可夫斯基距离
欧式距离,明可夫斯基距离的特殊情况
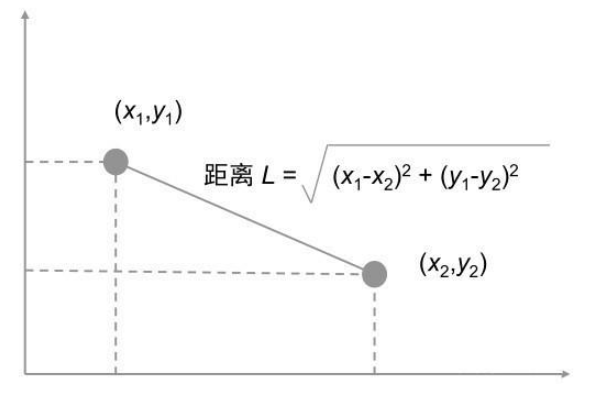
曼哈顿距离,明可夫斯基距离的特殊情况 两个样本的距离公式可以通过如下公式进行计算,又称为欧式距离。
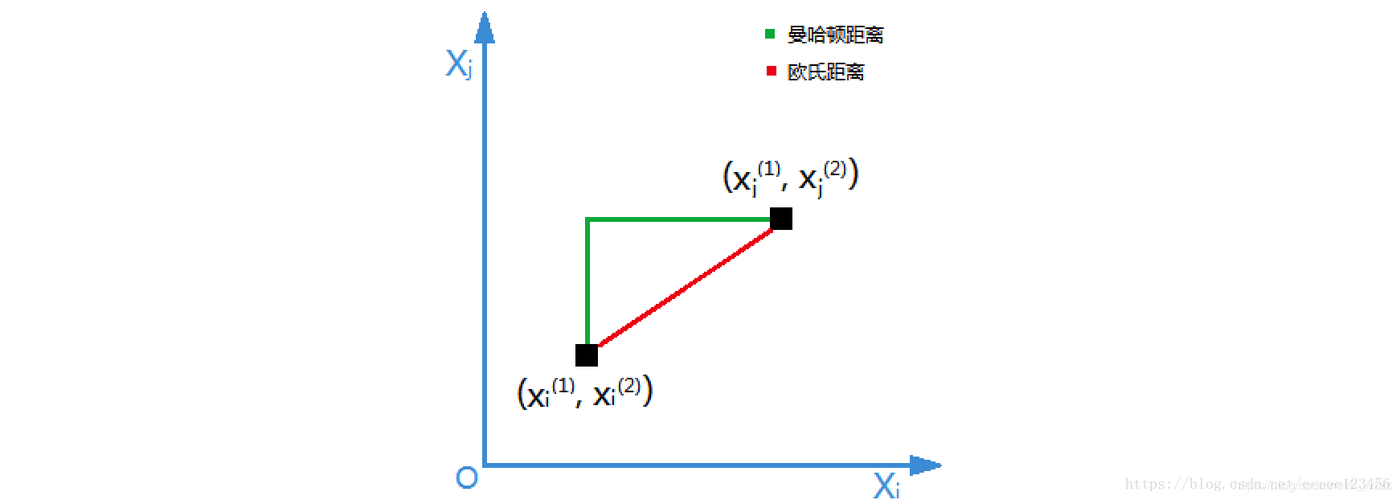
(1)欧式距离
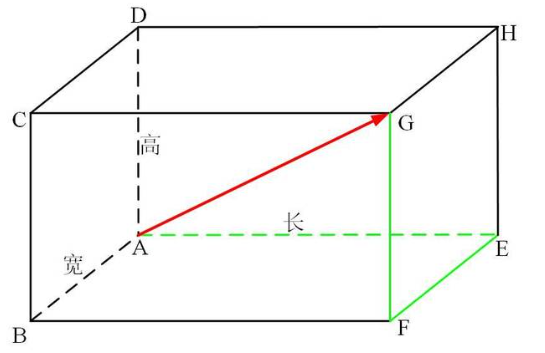
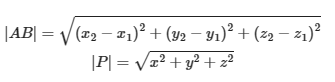
(2)曼哈顿距离
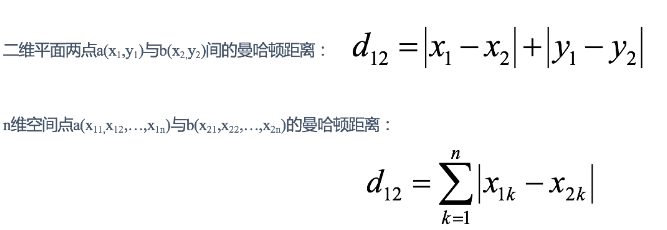
2 KNN 算法原理
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;
如果一个样本在特征空间中的k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别
比如: 有10000个样本,选出7个到样本A的距离最近的,然后这7个样本中假设:类别1有2个,类别2有3个,类别3有2个.那么就认为A样本属于类别2,因为它的7个邻居中 类别2最多(近朱者赤近墨者黑)
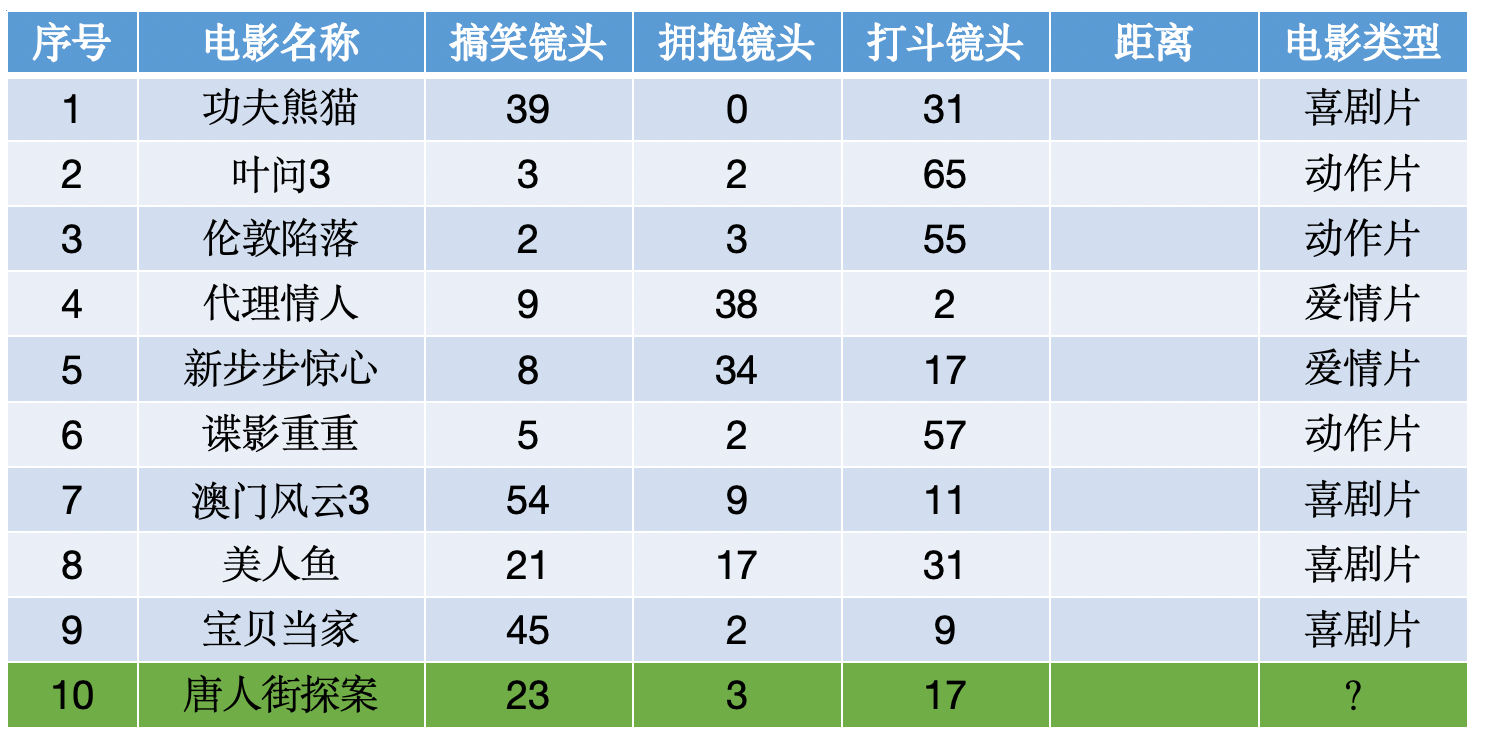
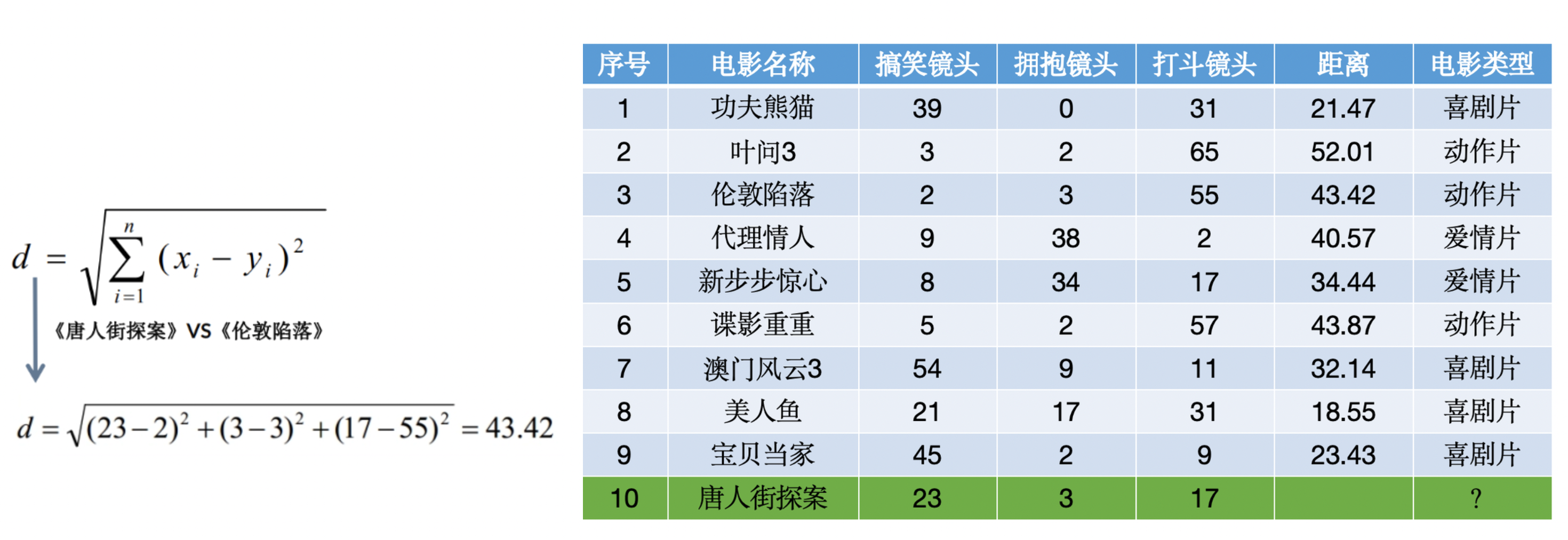
使用KNN算法预测《唐人街探案》电影属于哪种类型?分别计算每个电影和预测电影的距离然后求解:
3 KNN缺点
对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
对于高维数据,距离度量可能变得不那么有意义,这就是所谓的"维度灾难"
需要选择合适的k值和距离度量,这可能需要一些实验和调整
4 API
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
参数:
(1)n_neighbors:
int, default=5, 默认情况下用于kneighbors查询的近邻数,就是K
(2)algorithm:
{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, default=’auto’。找到近邻的方式,注意不是计算距离 的方式,与机器学习算法没有什么关系,开发中请使用默认值'auto'
方法:
(1) fit(x, y)
使用X作为训练数据和y作为目标数据
(2) predict(X) 预测提供的数据,得到预测数据 5 sklearn 实现KNN示例
用KNN算法对鸢尾花进行分类
# 用KNN算法对鸢尾花进行分类
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1)获取数据
iris = load_iris()
# 只有4个特征, 150个样本
print(iris.data.shape) #(150,4)
# 4个特征的描述 ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
print(iris.feature_names)
# 150个目标,对应150个样本的类别
print(iris.target.shape) #(150,)
# 目标值只有0 1 2这三种值,说明150个样本属于三类中的其中一种
print(iris.target) #[0 0 0...1 1 1 ...2 2 2]
# 目标值三种值代表的三种类型的描述。
print(iris.target_names) #['setosa' 'versicolor' 'virginica']
# 2)划分数据集
# x_train训练特征,y_train训练目标, x_test测试特征,y_test测试目标
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# print(x_train.shape, x_test.shape, y_train.shape, y_test.shape) #(112, 4) (38, 4) (112,) (38,)
# 3)特征工程:标准化, 只有4个特征
transfer = StandardScaler()
# 对训练特征做标准化, 对测试特征做相同的标准化,因为fit_transform中已经有fit进行计算了,所以对x_test只需要做transform了
# 训练用的什么数据,模式就只能识别什么样的数据。
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN算法预估器, k=7表示找7个邻近来判断自身类型.
estimator = KNeighborsClassifier(n_neighbors=7)
estimator.fit(x_train, y_train)#该步骤就是estimator根据训练特征和训练目标在自己学习,让它自己变聪敏
# 5)模型评估 测试一下聪敏的estimator能力
# 方法1:直接比对真实值和预测值,
y_predict = estimator.predict(x_test) #y_predict预测的目标结果
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率,
score = estimator.score(x_test, y_test)
print("准确率为:\n", score) #0.9473684210526315(150, 4)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
(150,)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
['setosa' 'versicolor' 'virginica']
y_predict:
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2 0 0 1 1 1 0 0
0]
直接比对真实值和预测值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True True True True True True True True
True True]
准确率为:
0.94736842105263156 模型保存与加载
python
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
import joblib
def train():
# 加载鸢尾花的数据集
iris = load_iris()
# 鸢尾花的特征数据
X = iris.data
# 鸢尾花的标签数据
y = iris.target
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
# 把训练数据进行标准化
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
# 创建knn算法的模型
knn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
# 使用训练集训练模型
knn.fit(X_train_std, y_train)
# 使用测试集数据对模型进行评估
x_test_std = sc.transform(X_test)
# 模型自带的评估方法
score = knn.score(x_test_std, y_test)
# 自己些评估方法
y_predict = knn.predict(x_test_std)
score1 = np.sum(y_predict == y_test) / len(y_test)
if score >0.9:
joblib.dump(knn, './src/knn.pkl')
joblib.dump(sc, './src/sc.pkl')
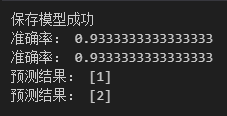
print("保存模型成功")
else:
print("保存模型失败")
print("准确率:", score)
print("准确率:", score1)
x_new = [[1, 2, 3, 4]]
x_new = sc.transform(x_new)
y_new = knn.predict(x_new)
print("预测结果:", y_new)
train()
# 推理函数
def detect():
# jiald模型加载
knn = joblib.load('./src/knn.pkl')
x_new = [[3, 4, 5, 6]]
# 新数据的处理
cs = joblib.load('./src/sc.pkl')
y_new = cs.transform(x_new)
y_new = knn.predict(y_new)
print("预测结果:", y_new)
detect()